监督式强化学习在路径规划中的应用研究
2018-10-24曾纪钧梁哲恒
曾纪钧 梁哲恒
(广东电网有限责任公司信息中心 广东 广州 510080)(中国南方电网公司信息化评测重点实验室 广东 广州 510080)
0 引 言
机器学习算法可以分为监督学习、非监督学习和强化学习[1]。作为一种新兴的机器学习算法,强化学习由于其具有无监督的自适应能力[2]、自我学习的特性,引起了学者的极大兴趣。传统的强化学习算法有:Q学习算法、SARSA算法、Q(λ)、SARSA(λ)等[3-5]。
强化学习的训练过程可以看成是智能体为实现目标的探索过程,也是环境对智能体动作的评价过程[3,6]。Agent根据自身策略以及状态选择动作,环境根据智能体的行为进行评价,反馈给Agent奖惩值。Agent根据奖惩值优化更新自身的知识库,并根据累计奖励值最大化的原则继续选择动作,最终实现目标[3]。由此可见,Agent的训练是一个“动作—评价—动作”探索的过程,其为实现目标必须要付出较大的计算代价,会带来训练收敛速度慢等系列问题。
相对而言,监督式强化学习算法是一种结合导师监督评价和强化学习主动探索的方法。它结合了监督学习和强化学习的优点,通过导师指导(监督式学习)降低Agent在前期学习探索过程的难度,通过强化学习的主动探测不断丰富Agent 的经验,最终实现系统的最优控制,这就是监督式强化学习的思想[7-8]。
监督式强化学习有三种途径实现导师监督:(1) 塑造成型(Shaping)。其主要思想是导师给出辅助回报函数,参与强化学习模型中环境给予Agent的汇报。(2) 标称控制(Nominal control)。其主要思想是导师直接给出明确的控制信息。(3) 探索(Exploration),其主要思想是导师暗示那种控制可能是有效的[3,8-10]。
本文介绍了强化学习模型和算法,提出了监督式强化学习算法模型和算法,并将该算法应用到机器人路径规划问题当中。通过实验对比分析显示,监督式强化学习能有效降低系统的训练次数,提高机器人路径规划的智能化水平。
1 监督式强化学习算法
1.1 强化学习模型
强化学习的模型如图1所示[3]。Agent与环境互动并获得环境奖惩,根据环境给予的奖励不断调整自身的策略,并最终学习到最优策略。

图1 强化学习模型
其典型的交互步骤如下所示:
1) Agent在控制决策时,根据自己的环境(状态st)以及自身的控制策略π,采取相应的动作at。
2) 由于Agent的动作,其所属的状态发生了转移,即实现st→st+1。
3) Agent根据自身的状态转移,从外界获得其动作的评价(奖惩rt+1)。
4) Agent根据外界环境的评价,更新自己的知识库(Q表),为自己的下一步动作做准备。
5) 回到第1步,Agent继续做出决策,直到实现目标。
以上步骤为Agent的强化探索过程,当知识库(Q表)收敛时,Agent将学习到完成任务的最优策略π*。
为实现Agent知识库的可量化以及安全策略的可计算,定义“回报变量”Rt,用它来估算所有回报值和评价当前动作的好坏。回报变量是指Agent从t时刻开始所有获得的所有奖惩之和,其计算公式如下:
(1)
式中:0≤γ≤1,称为折扣系数。
由于Agent在同一状态有多个动作可以选择,通过定义变量“状态值函数”Vπ(s)代表Agent处于状态s时的期望回报值:
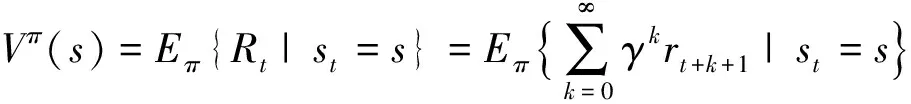
(2)
因此,可以通过期望的“回报变量”Vπ(s)表示Agent处于状态s的好坏程度。
同理,可以定义“状态-动作值函数”Qπ(s,a),表示在状态s,采取动作a后所期望的回报值:
Qπ(s,a)=Eπ{Rt|st=s,at=a}=
(3)
Vπ(s)、Qπ(s,a)和策略π紧密相关,Agent根据它们的数值评价其所处状态s或(s,a)的好坏,继而选择动作a。Agent的典型选择策略为:动作a的选择让Agent在t时刻获得“状态-动作值函数”Qπ(s,a)最大。
由于强化学习离散模型的马尔科夫性,容易得到:
(4)
由于式(4)对模型要求很高,需要根据模型的转移概率才能计算出期望的状态“回报值”Vπ(s),我们希望得到一个与模型无关的算法。利用平均的“回报值”来逼近Vπ(s):设第k-1次训练中,状态的“回报值”为Rk-1,那么在第k次训练中,状态s的“值函数”为:
(5)
根据式(5),得到相应的对应的“动作-状态值函数”:
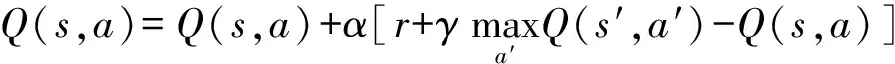
(6)

1.2 监督式强化学习算法
由于强化学习最初的训练是随机探索,这必然会带来收敛慢的问题。监督式强化学习结合了监督学习导师的指导和强化学习自我学习的特性,在强化学习的基础上引入了导师Supervisor的经验,在Agent的探索过程中加入导师的监督指导,赋予Agent的先验知识,加快Agent寻找最优解的过程。监督式强化学习算法模型如图2所示[8,11]。
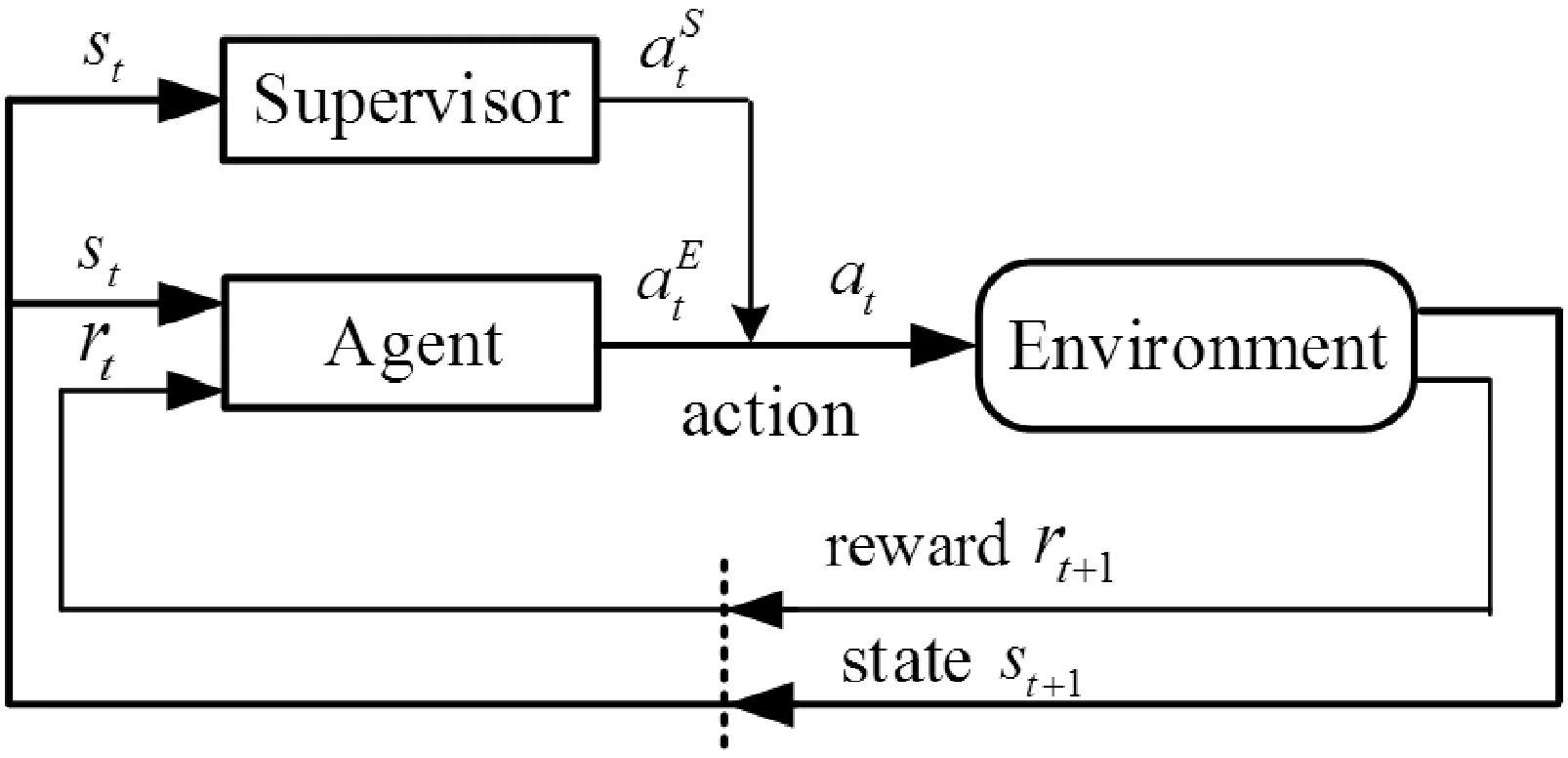
图2 监督式强化学习模型
监督式强化学习的动作更新策略如下所示,
a=kaE+(1-k)aS
(7)
式中:aE代表强化学习选择的动作;aS代表监督学习选择的动作;k为0~1线性增加的权重系数。在初始时刻,aS的权重较大,机器人主要依靠监督学习选择动作。多次训练之后,aS的权重逐渐降低,并最终退出动作a的决策过程,此时机器人依靠强化学习选择动作。监督学习的动作aS可以通过多种方式得到,常用的是PID控制器、决策树、神经网络控制器等[12]。
k的递增方式及递增速度对监督式强化学习的训练过程有较大影响。增长过快,起到的指导作用不明显;增长过慢,在有限次的训练过程当中会对强化学习起到误导作用。
2 实验设计
本文将监督式强化学习算法应用到机器人路径规划当中来说明监督式强化学习的效果。机器人所处的物理环境为40×40的方格地图,如图3所示。
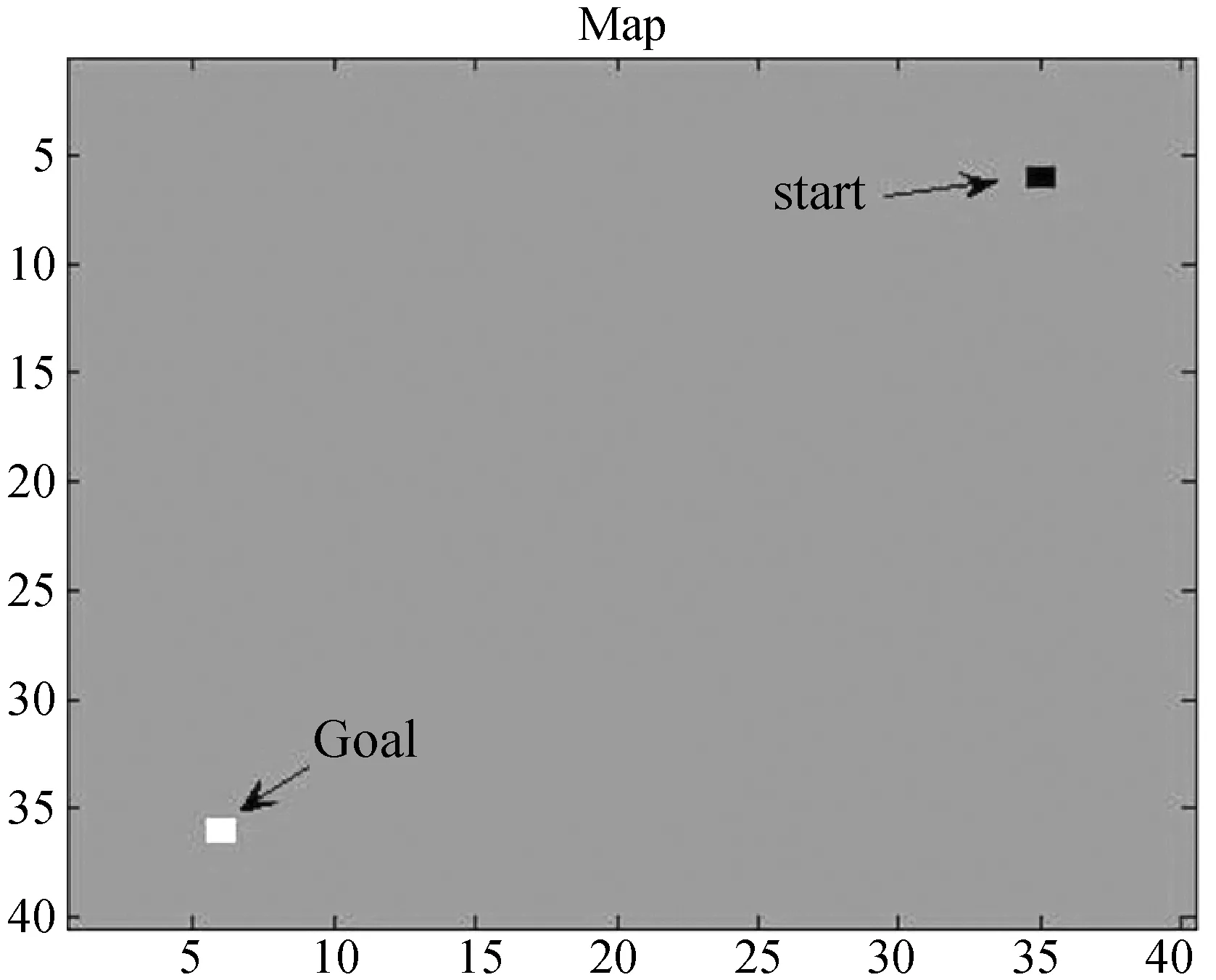
图3 机器人路径规划地图
机器人需要从起点(6,35)走到终点(36,6),每次只能行走一格,方向为东南西北四个方向之一。如何规划机器人行走的路径,让机器人能够以最少的步数达到目标点是监督式强化学习算法需要解决的问题。
设计机器人在未达到终点时,每一步的转移得到的奖励值r=-1,到达目标点时的奖励值,γ=0.9,α=0.9,机器人训练的次数为step=1 000,监督学习权重增长公式为:
k=k+Δ
(8)
为了比较实验结果,我们让Δ取0.01、0.003 3、0.002 5三个值。
我们通过Q学习算法来得到aE,通过P控制器算法来选择aS。首先将aE和aS单位化,然后采用式(7)以及向量合成法(如图4所示)计算动作a。
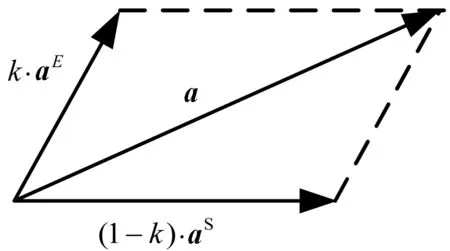
图4 机器人动作选择
由于a的方向未必是东南西北四个方向之一,我们采取就近原则,将其规整到最近的四个方向之一上。
我们定义算法的性能指标函数(平均的搜索步数):

(9)
式中:counter(i)为第i训练时,从起始点到目标点所需要的步数。step为训练的次数。
3 实验结果与分析
强化学习算法和监督式强化学习得出的结果分别如图5、图6所示。机器人均以最优的步数收敛到了目标点。
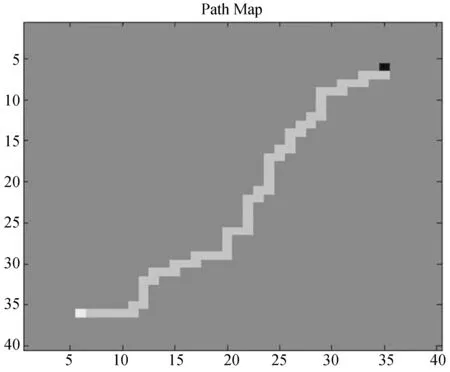
图5 强化学习算法实现的路径规划
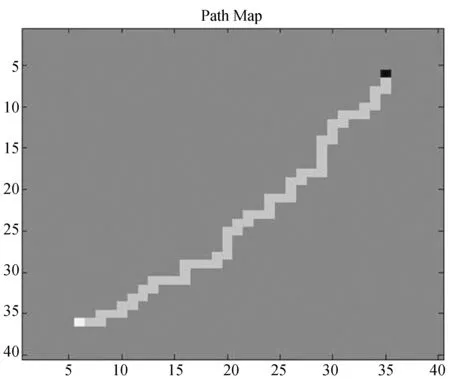
图6 监督式强化学习算法实现的路径规划
强化学习、监督式强化学习迭代的步数,如图7-图10所示。

图7 强化学习算法得到的迭代步数
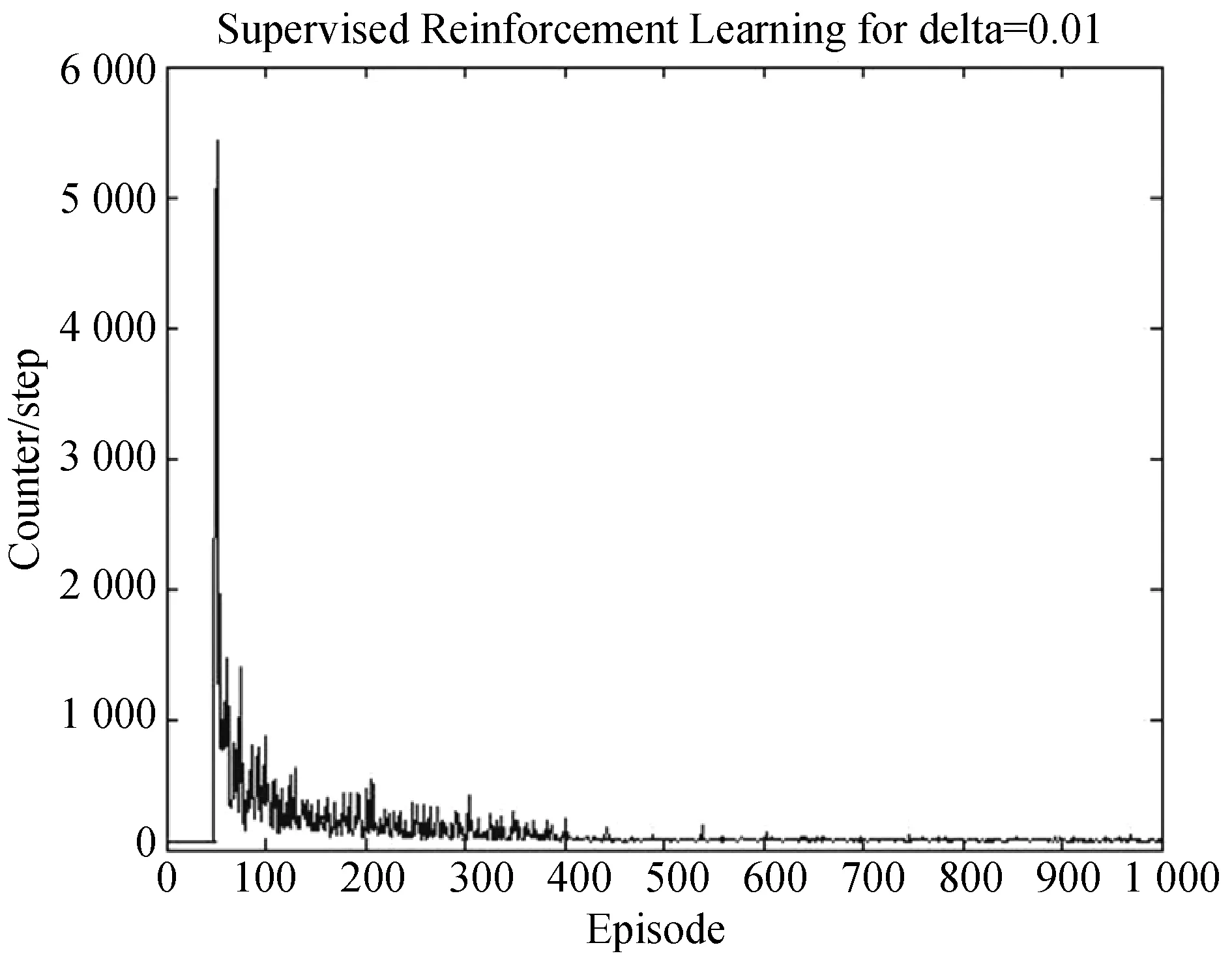
图8 监督式强化学习算法得到的迭代步数(Δ=0.01)

图9 监督式强化学习算法得到的迭代步数(Δ=0.003 3)
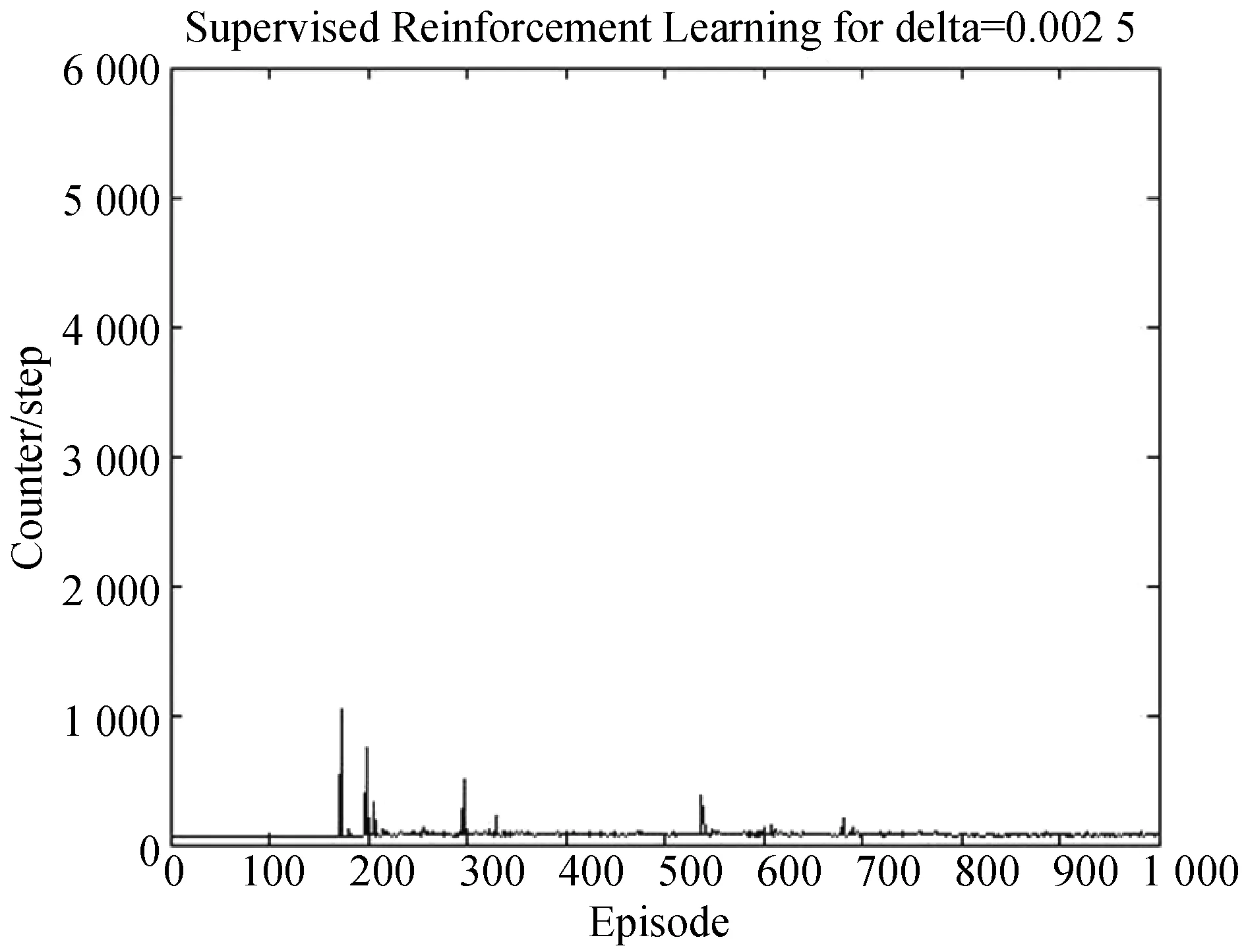
图10 监督式强化学习算法得到的迭代步数(Δ=0.002 5)
可以看出,强化学习在前50次训练当中,Agent需要搜索多次才能找到目标点。经过计算它的平均搜索次数为200.638。当Δ=0.01时,即监督学习只在前100训练当中指导Agent寻找目标,它的平均搜索次数为150.158;Δ=0.003 3时,它的平均搜索次数为98.974;Δ=0.002 5时,它的平均搜索次数为76.064。
从得到的数据来看,监督学习能够极大的提高Agent的搜索效率:强化学习在550次训练之后会以较稳定的步数找到目标点,而在Δ取0.01、0.003 3、0.002 5时,监督强化学习的训练次数分别为:400、250、300。但并不是监督学习加得越多越好,监督学习一旦撤销,强化学习在短时间内会出现短暂的震荡。比如当Δ=0.002 5时,Agent在第300次以及第540次出现了震荡比较大的情况。当Δ=0.003 3时,监督强化学习的收敛性是比较好的。
4 结 语
本文针对机器人的路径规划问题,提出了基于标称控制的监督式强化学习算法。实验结果表明:当监督式强化学习的导师信息正确时,其能显著提高机器人的智能化水平,使机器人快速找到目标点;当导师信息给得太多,也容易出现对Agent的干扰,具体表现为
机器人的搜索目标步骤出现震荡。尽管如此,机器人仍在导师信息弱化时迅速找到实现目标的最优策略。
