基于知识蒸馏方法的行人属性识别研究
2018-10-24凌弘毅
凌 弘 毅
(南京大学计算机科学与技术系 江苏 南京 201203)
0 引 言
由于在智能商业和视频监控等领域的巨大潜力,学习识别诸如性别、年龄、体型、衣服类型等人类属性在计算机视觉的研究中受到越来越多的关注。属性识别已被用于人类检测、人类再识别、人脸识别等领域,并且已被证明可以极大地改进其与视觉相关的任务,但在实际监控环境下仍然是一个巨大的挑战。这是因为在真实的监控视频中,由于监控摄像头与行人之间的距离,几乎没有关于行人脸部或身体区域的清晰照片。同时,由于行人的数量以及监控摄像头的位置等因素,用于识别的照片中往往会出现行人身体的部分区域被遮挡的现象。所以,行人属性识别会在一个缺少关键面部信息以及部分视觉信息缺失的情况下进行。
在面对这个问题的时候,传统的方法是直接将多余的属性信息丢弃,仅仅处理需要识别的属性。这样的做法会将一些有用的信息直接丢弃,无法有效地利用数据集中的所有信息。本文旨在利用这些多余的属性信息,挖掘出属性之间隐藏的知识,使得属性识别的准确率能够进一步提升。
1 方法描述
关于属性识别的研究方法大体分为两类:
(1) 传统的机器学习方法。支持向量机SVM算法、k最邻近分类算法(kNN)和 AdaBoost算法作为分类算法被大量地使用以及优化。文献[1]从重叠的patch中提取出HOG特征与Adaboost分类器一起完成了性别的属性识别。文献[2]提取LBG以及HOG特征来训练ADAboost和kNN分类器,从而完成了属性分类。文献[3]提出了利用性别、头发长度等二元属性来描述一个人的外观方法。
(2) 将深度学习应用到行人属性分类与识别。从VGG到Inception[4-7]和RESNET,卷积神经网络在图像分类和图像检测等方面取得了巨大的成就和广泛的应用。CNN与传统的机器学习方法最大的区别是其多层结构能够自动学习多个层次的特征:较浅的卷积层感知域较小,可以学习图像的局部特征;较深的卷积层感知域较大,能够学习到更加抽象的特征。这些抽象特征对物体的大小、位置和方向并不敏感,从而有助于提高识别的准确度。上述这些研究虽然都尝试训练一个鲁棒的属性识别模型,但它们都没有探究丢弃的属性信息中是否存在有“价值”的信息。本文认为在这些被丢弃的属性信息中含有大量有用的隐藏信息,并且利用这些隐藏信息可以对原本的属性识别任务有巨大的提升。
1.1 网络结构
为了挖掘多余的属性信息中的有用信息,本文采用了一个教师网络加学生网络的框架,其中:教师网络的作用是学习多余属性信息;学生网络的作用是完成真正的属性识别。首先训练教师网络,让其对多余的属性进行识别。然后用已有教师网络联合数据集中属性数据,指导学生网络的训练,使教师网络的知识能够被学生网络所吸收。为了达到这个目的,采用了知识蒸馏的方法,并提出了一种混合的损失函数(KD Loss)。具体的训练方式如图1所示。
教师网络用于对多余的属性进行识别,它的结构如图2所示。教师网络由一个深度CNN和一个Embedding层组成。输入为图片,输出为一个向量,代表着该图片的属性识别结果。
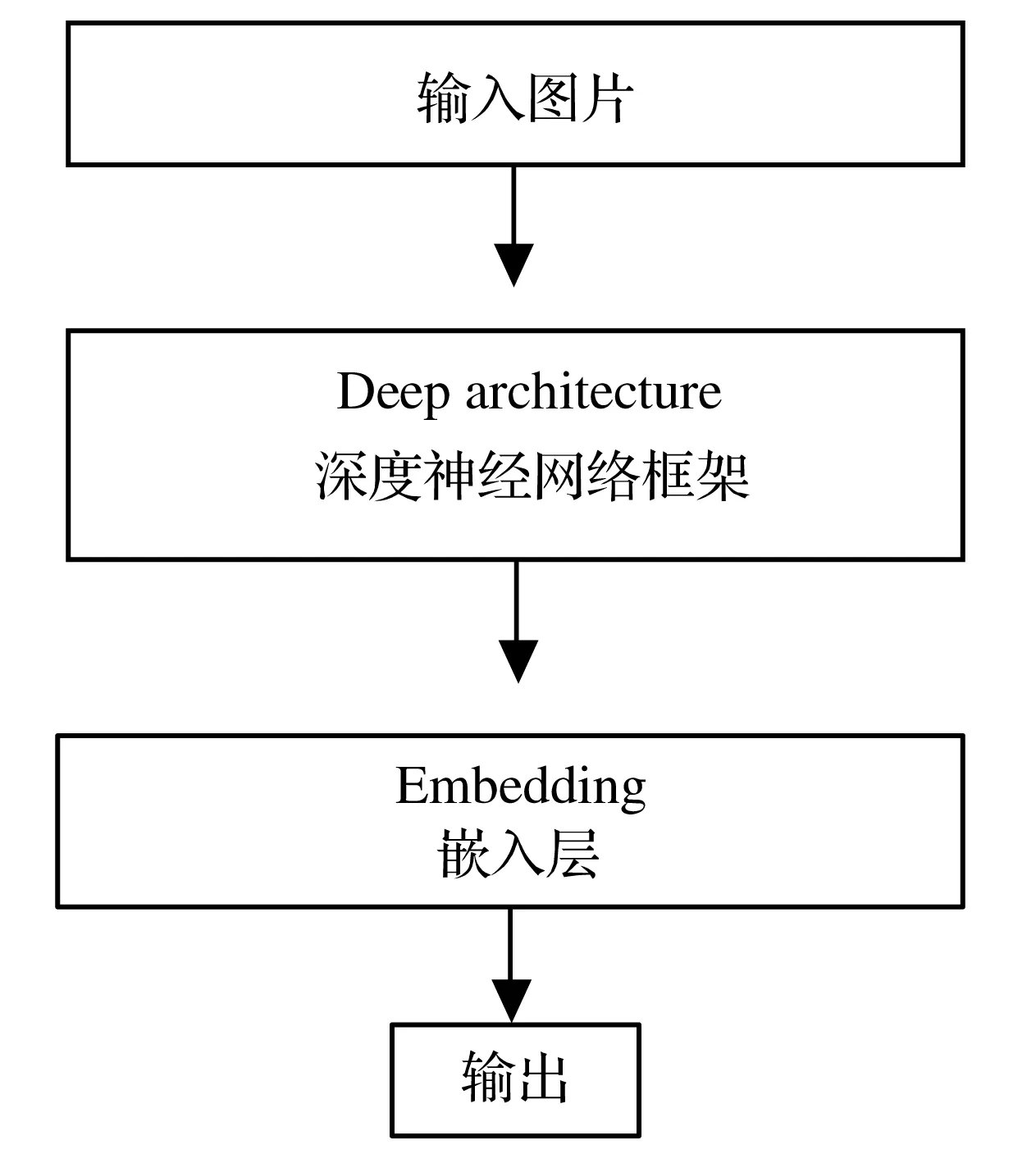
图2 教师网络的结构
完成对教师网络的训练后,会利用教师网络的输出以及数据集中属性数据对学生网络进行训练,让学生网络吸收教师网络的知识。学生网络的结构如图3所示。在学生网络中,深度CNN结构后跟着一个Embedding层。Embedding层的输出是对于所有属性识别的结果,我们将结果分为需要识别的属性(LOGIT1)以及多余属性(LOGIT2)。LOGIT1就作为学生网络在测试时的输出,而LOGIT2则会在学生网络训练时与LOGIT1一起用于计算KD Loss。
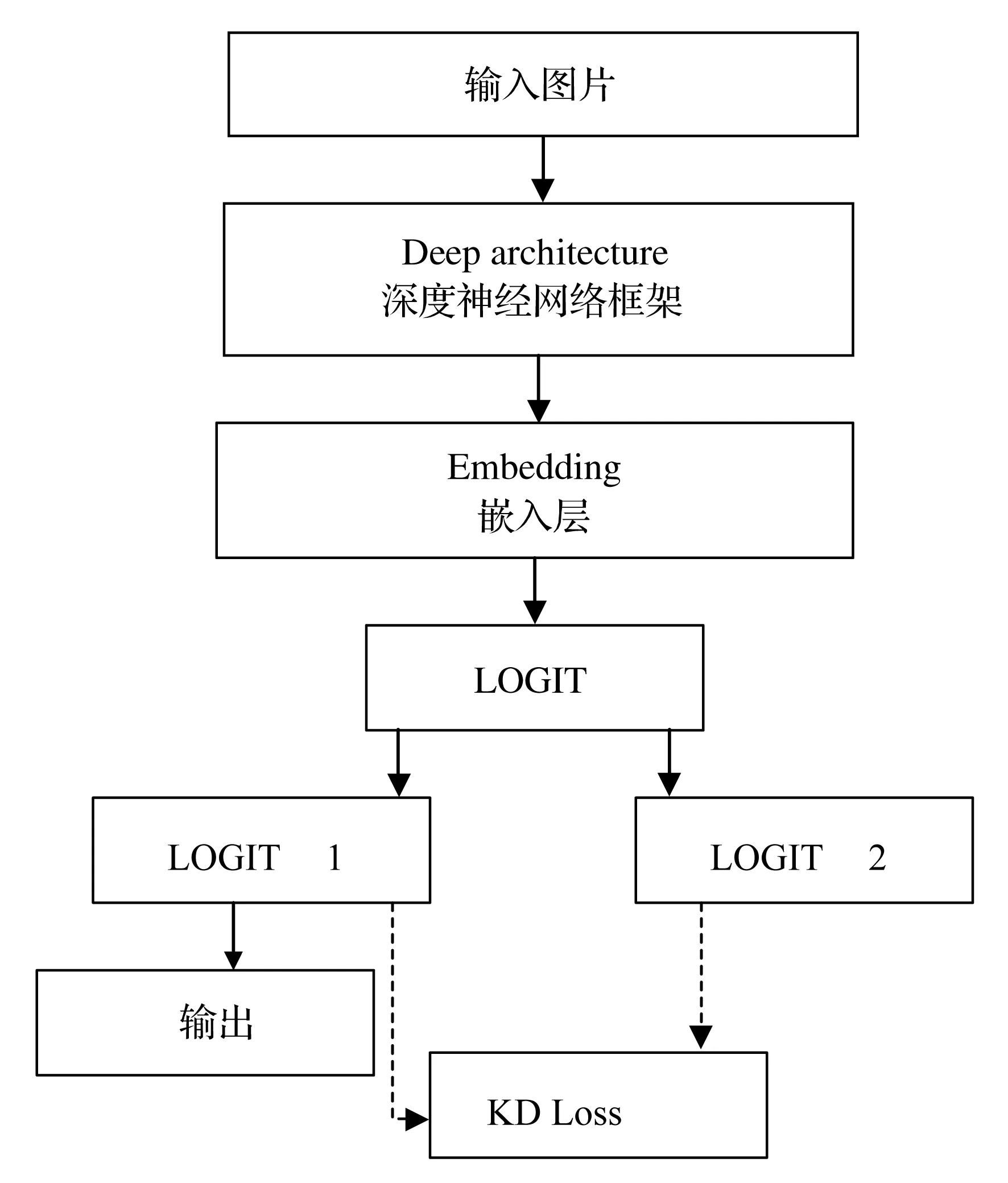
图3 学生网络结构
在对学生网络进行训练的过程中,本文方法最重要的部分在于让学生网络吸收教师网络对多余属性学习的知识从而提高属性识别的准确度,所以提出了一种混合的损失函数KD Loss。在计算该损失函数的过程中会对教师网络进行知识蒸馏,从而让学生网络学习到数据集中的隐藏知识。
1.2 知识蒸馏
传统的知识蒸馏方法的目的是将一个巨大的模型集合压缩为单个模型。利用这个方法,将原本数据集中离散的属性标签变成了连续的概率分布,提取教师网络中的隐藏知识,使得教师网络学习到的知识成为学生网络的一部分,具体的做法如下:
神经网络通常使用“softmax”输出层产生一个分类的概率向量p,该输出层将每个类的logit值zi与其他类的logit值进行比较,从而生成每个类的概率pi:
(1)
知识蒸馏的方法[9]对“softmax”输出层进行了修改,让输出层产生一个被“软化”后的概率向量qi:
(2)
式中:T为温度,当T=1的时候就是常用的softmax输出层。如果T的值使用的较高,会得到一个更平均的概率向量。
在训练学生网络的时候,对训练集上每个情况,使用由教师网络高温蒸馏得到的软目标,作为目标的一部分,隐藏知识就可以从教师网络传递到学生网络。即教师网络的输出zi会经过一个“高温”的“softmax”层得到qi,并将其用于KD Loss的计算。
1.3 损失函数
为了让学生网络吸收教师网络对于多余属性学习的知识,我们将相对熵损失函数和交叉熵损失函数进行了结合。相对熵损失函数用来衡量两个分布之间的相异度,当两个随机分布相同时,它们的相对熵为零;当两个随机分布的差别增大时,它们的相对熵也会增大,可以用于衡量教师网络输出的分布和学生网络输出的分布之间的相异度。交叉熵损失函数往往用来表征真实样本标签和预测概率之间的差值,当预测概率与真实样本标签的差异增大时,它们的交叉熵也会增大,可以用于衡量学生网络预测的概率和真实样本标签的差值。将这两种损失函数进行混合后,就可以同时衡量教师网络输出的分布和学生网络输出的分布之间的相异度以及学生网络预测的概率和真实样本标签的差值。由此,本文使用了一个混合的损失函数KD Loss,表达式如下:
Loss=KL(p2,q)×alpha×T2+
CE(label,p1)×(1-alpha)
(3)
式中:T为温度,KL为相对熵(Kullback-Leibler divergence),CE为交叉熵(cross entropy),q为教师网络输出经过蒸馏后的结果,p1为学生网络中的LOGIT1,p2为学生网络中LOGIT2经过蒸馏后的结果,label为数据集所给的真实标签信息,alpha为KL和CE在KD Loss中的比例参数。当alpha=0的时候,学生网络就相当于一个使用交叉熵作为损失函数的深度卷积神经网络。KD Loss的第一部分旨在让学生网络向一个软化后的分布(即经过知识蒸馏的教师网络的输出)优化,第二部分则如传统的那样让学生网络向真实的标签值进行优化。
2 实验及结果分析
实验主要是为了证明本文提出的框架和损失函数可以有效地利用多余属性信息来提升行人属性识别的准确率,关注点在于新的框架和损失函数对原有网络的提升,而不是为了取得超过现有所有方法的准确率。因此,本文选用了在图像识别上表现较好的卷积神经网络ResNet101作为教师网络以及学生网络中的deep architecture。实验的数据集选用了图片数量巨大、识别难度较高的RAP[10]数据集。通过将学生网络与直接使用ResNet101的结果进行对比,证明本文提出的知识蒸馏方法能够有效地利用多余信息提升属性识别的准确率。
2.1 数据集
RAP是一个专门针对行人属性识别的数据集,它收集了一个购物中心监控网络的数据。在该监控网络中选择了26个监控摄像头连续三个月所拍摄的图像信息。该数据集中的部分图像如图4所示。在现实场景中,由于监控摄像头的位置、行人的姿态、行人的面部朝向、行人距离监控摄像头的距离等因素,同一种属性会有很大的变化并对属性识别带来巨大的挑战。

图4 RAP数据集中部分图像的示例
RAP数据集共有41 585张剪裁好的行人图片,分辨率从36×92到344×554,它应该是至今为止最大的行人属性数据集。整个RAP数据集被划分为训练集和测试集两个部分,其中训练集有33 268张图片,占总数的80%;测试集有8 317张图片,占总数的20%。训练集和测试集的比例为4∶1。在RAP数据集给出标记的属性中,选择了54个属性(见表1)作为需要识别的属性,其余66个属性当作多余信息处理。
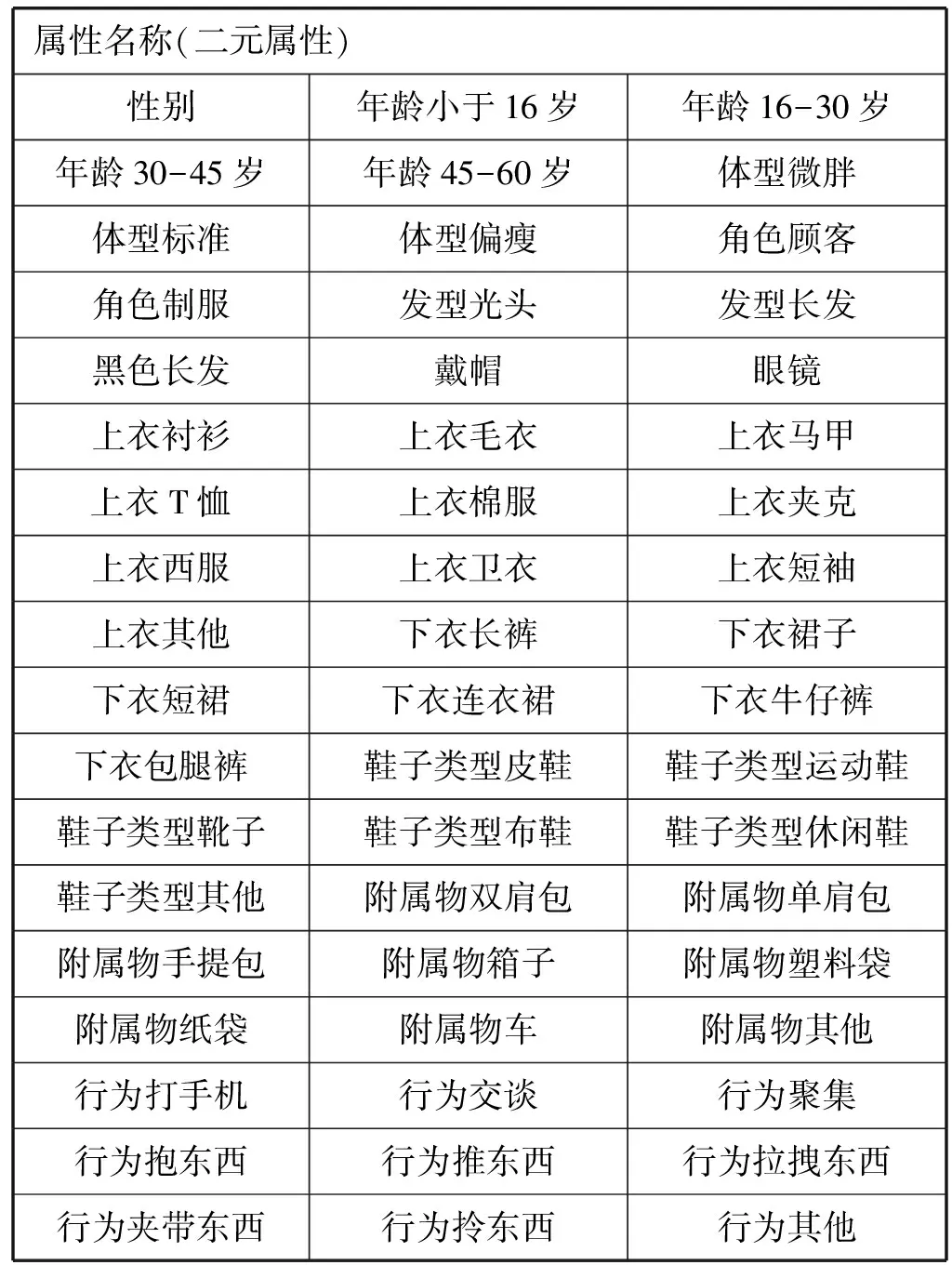
表1 所有需要识别的属性名称
2.2 实验过程与结果
首先使用传统的方式(即将多余的属性信息直接丢弃)进行对照的实验。这里采用了ResNet101的网络结构,Batch Normalization的方式作为抑制过拟合的手段,对于模型的初始参数值采用了随机初始化。对输入的图像做一个变换,使得网络的输入是一个256×128×3的矩阵,并且不再对输入图像做其他的处理。训练完成后将其在测试集上进行测试,得到结果:所有54个属性的平均准确率为92.13%,F1-score为71.94%。
为了进行对比实验,我们使用了本文提出的方法。教师网络同样选用了ResNet101的网络结构,Batch Normalization的方式作为抑制过拟合的手段以及同样的图像处理方式。完成对教师网络的训练后,使用教师网络结合数据集的人工标签对学生网络进行训练。学生网络仍然采用了ResNet101作为深度网络结构,但在损失函数中使用了本文中提到的KD Loss混合损失函数。对于KD Loss中的参数:我们尝试了[1,2,5,10]的温度,[0.1,0.3,0.5]的比例alpha。最后在测试集上得到的具体结果如表2所示。
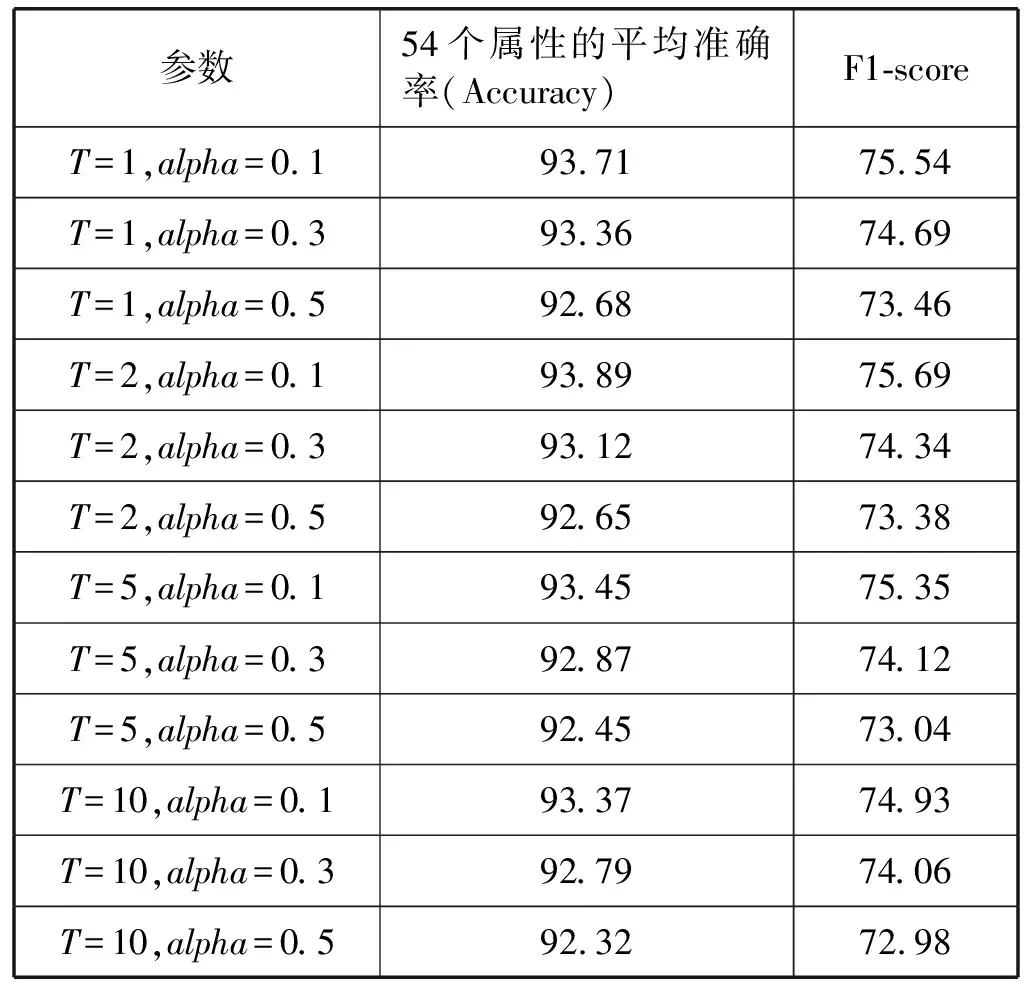
表2 学生网络的属性识别结果 %
2.3 结果分析
通过表2的实验结果可以发现:本文提出的方法对于属性识别有着一定的提升,在T=2,alpha=0.1的情况下提升效果最为明显,对54个属性的平均分类准确率最高提升了1.76%,F1-score最高提高了3.75%。这是在原本ResNet网络准确率已经很高的情况下带来的提升,证明了学生网络吸收教师网络对多余属性学习的知识后,挖掘了被丢弃的属性信息中的隐藏信息,并将其用于对选中的54个属性进行识别。
进一步对属性进行分析后发现了几个问题:在选中的54个属性中关于部分年龄段的识别准确率非常低,关于年龄属于30~45岁还是45~60岁的区分准确率只有70%左右。在识别行人鞋子属于皮鞋还是运动鞋的识别准确率也比较低,在78%左右。这几个属性的识别正确率相较于原本的网络几乎没有提升。
通过对RAP图像的深入分析,发现部分图像中只有行人的背影,行人的脸部并没有出现在图片中。此外,即使是带有行人脸部的图片中,由于行人和监控摄像头的距离原因,行人脸部的图像也很模糊。所以,本文认为缺少关键面部信息以及近距离视觉信息是造成以上两个属性区分准确率很低的主要原因。这些需要在今后的研究中深入探讨。
3 结 语
本文针对神经网络对训练数据中隐藏知识利用不充分的问题以及训练数据中的部分信息没有被利用的问题,研究了一种利用多余属性信息进行数据蒸馏的方法。通过优化网络结构并使用一种混合的损失函数,提高了属性识别的性能。使用最新的大规模行人属性数据集RAP进行实验,证明了本文提出的优化方法能够有效地利用多余信息提升属性识别的性能。
