维吾尔语三音素决策树的欠拟合调优
2018-10-23阿依先木卡得尔邱自成
阿依先木·卡得尔 邱自成
(1塔里木大学人文学院,新疆 阿拉尔 843300)(2塔里木大学信息工程学院,新疆 阿拉尔 843300)
得益于一批优秀开源平台[1]的支持,维吾尔语语音识别研究已经取得一系列成果。大词汇量连续语音识别系统的性能逐步提高,词错误率(Word Error Rate, WER)逐步下降。目前,HTK[2]和Kaldi[3]是这些开源平台中的主流。基于HTK和Kaldi,许多研究工作以开源平台提供的基线系统为基础,以维吾尔语语音识别系统的整体性能优化为焦点,研究新的单元技术,扩展识别系统的功能,降低词错误率[4-11]。吾守尔·斯拉木的研究团队[4-6]较早开展基于HTK的维吾尔语语音识别工作。文献[4]基于HTK构建了维吾尔语的上下文相关的三音素隐马尔柯夫声学模型,结合二元语法,实现了一个维吾尔语非特定人大词汇量连续语音识别系统。文献[5]基于HTK构建隐马尔柯夫模型(Hidden Markov Models,HMM)的声学模型,通过决策树、三音子绑定、修补哑音和增加高斯混合分量的方法提高识别精度。文献[6]针对维吾尔语作为黏着语在识别过程中OOV (Out Of Vocabulary,未登录词)突出的问题,分别将子词、词首词尾和组合识别单元代替单词作为语言模型的建模单元,基于HTK构建维吾尔语语音识别系统验证三种识别单元对识别性能的提升。李晓的研究团队[7]也较早基于HTK开展维吾尔语语音识别研究。文献[7]搭建以HTK为平台的维吾尔语语音识别基线系统,针对方言口语发音变异的问题,构建和田方言多发音字典,提高系统对方言口音的识别性能。
基于上述开源平台,深层神经网络在语音识别中广泛应用,识别系统的词错误率显著下降[8]。与此同时,Kaldi作为一个支持深度学习技术的开发平台[3]在语音识别社区中迅速发展,也受到维吾尔语语音识别研究者的青睐。文献[9]基于Kaldi训练了一个含4隐层的神经网络,构建DNN-HMM (Deep Neural Networks-Hidden Markov Models)声学模型,借助于GPU (Graphics Processing Unit)的强大计算能力,使识别系统性能得到大幅度提升。为了促进维吾尔语语音识别技术的发展,文献[10]发布了一个完全免费的维吾尔语连续语音数据库THUYG-2.0,同时基于Kaldi平台,提供了一整套构建基线系统所需的音素集、词表、文本数据、语言模型和结果可重现的脚本文件等资源。基于THUYG-2.0语音数据库和Kaldi研究平台,文献[11]通过引入CNN (Convolutional Neural Networks)构建声学模型,在获得与DNN相当的识别性能的同时,降低训练参数的规模,缓解过拟合的问题。
另一方面,语音数据库是语音识别研究的重要基础资源。THUYG-2.0免费语音数据库的发布为维吾尔语语音识别研究的发展进一步推波助澜[10,11]。虽然深层神经网络相比于高斯混合模型(Gaussian Mixture Model, GMM)能够更高精度地对三音素状态的似然概率建模,但是深层神经网络并不能代替整个HMM技术框架。目前,世界上最先进的商业系统所采用的方案,普遍以HMM框架下混合多种深层网络为特点[12]。换言之,HMM技术框架仍旧是现有语音识别技术的主体。基于Kaldi平台的THUYG-2.0语音数据库[10]虽然提供了一套基线系统,然而没有研究表明其中的GMM-HMM部分已经是最优状态,也没有研究表明该HMM框架在整合深层神经网络时,能够将深层神经网络的性能发挥到最优。实际上,不同性能的基线系统配备先进的深层神经网络模型后,能够得到的性能提升不尽相同,即以HMM框架为核心的基线系统仍旧是制约语音识别技术发展的一个主要因素。为语音研究界所公知,一个大词汇量连续语音识别系统包括大量、相互关系复杂的可调参数,这些参数增加了系统的复杂性和不确定性,使系统在调参的过程中难以避免多种经验上有效却不容易解释清楚的小技巧。另一方面,HTK和Kaldi广泛应用于英语和汉语相关的语音识别研究,维吾尔语作为小语种,并不是开源平台开发者的主要关注对象,此种情况进一步限制了基于开源平台的维吾尔语语音识别基线系统的性能。
本文以Kaldi为平台搭建维吾尔语语音识别基线系统,研究基线系统内部的三音素决策树模型[13]。基于Kaldi现有的三音素决策树模型实现方案[3],针对其超参数的欠拟合设置,优化提高其性能。三音素决策树是模拟协同发音的重要模块单元,与GMM或DNN结合成为声学模型的核心,其性能的优化也将有效降低基线系统的词错误率。
1 基于Kaldi的维吾尔语语音识别基线系统
1.1 基线系统的主要结构
基于Kaldi[3]开源工具包构建维吾尔语语音识别基线系统。作为语音识别技术的研究平台,Kaldi具备一个由加权有限状态转换器(Weighted Finite State Transducer,WFST)统一实现的以静态解码为特点的系统框架结构。在Kaldi中,大词汇量连续语音识别中所需要的各种语音学和语言学知识均用WFST统一表征并解码。用状态序列对发音单元建模的隐马尔科夫模型,模拟协同发音现象的上下文相关音素(Context-Dependent Phone, CD Phone)决策树,在转换成WFST后通过合成算法得到声学模型,然后合成已经转换成WFST表征的发音字典(Lexicon)和N元文法(N-gram)语言模型,最终得到静态解码网络。本文所构建的维吾尔语语音识别基线系统自然继承了Kaldi平台的上述基本特征。
已经发布的THUYG-2.0语音数据库选择基于DNN-HMM(Deep Neural Network-Hidden Markov Model)框架的声学模型和3-Gram语言模型构建基线系统[10]。虽然DNN-HMM相对于传统的GMM-HMM(Gaussian Mixture Model- Hidden Markov Model)声学模型在性能上有大幅度的提高,但是目前在Kaldi的开发环境下,完全忽视GMM-HMM的研究价值仍有失偏颇。首先,DNN-HMM的训练需要来自于GMM-HMM的特征和对齐数据,GMM-HMM是DNN-HMM的基础。其次,GMM-HMM相对于DNN-HMM的劣势不仅直观地由词错误率体现;GMM对非线性数据建模能力的不足,HMM的时间独立性假设和分段平稳假设与语音的动态特性之间的不匹配,从ASR(Automatic Speech Recognition)系统设计思想和技术细节上体现了GMM-HMM模型的弱点,为HMM的非线性动态变体扩展的产生[15],进而向完全基于神经网络的端到端系统的演化提供了线索和指引[15,16]。

图1 基于GMM-HMM的维吾尔语语音识别基线系统框架图
本文基于Kaldi开源工具包构建以GMM-HMM为声学模型、以3-Gram为语言模型的维吾尔语语音识别基线系统,其流程框架结构如图1所示,主要包括单音素、三音素、LDA_MLLT、SAT和Tri4b五个阶段。其中,所抽取的梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)特征是39维的帧数据。单音素建模选取上下文无关的音素作为HMM的建模单元。三音素建模选取窗口宽度为3的上下文相关的逻辑音素作为HMM的建模单元,构建三音素决策树。三音素建模之后,在MFCC特征的基础上将上下文窗口宽度为7帧的特征拼接,用线性判别分析(Linear Discriminant Analysis,LDA)降维至40维,在多次迭代之后估计出能使GMM协方差矩阵对角化的最大似然线性变换(Maximum Likelihood Linear Transform,MLLT)矩阵。在7帧宽的MFCC特征拼接数据上执行LDA和MLLT组合后的变换,训练得到基于LDA+MLLT特征的GMM-HMM声学模型。然后,基于说话人无关的LDA+MLLT特征计算特征空间最大似然线性回归(feature-space Maximum Likelihood Linear Regression,fMLLR)的自适应特征,实现说话人自适应(Speaker Adapted Training,SAT)的GMM-HMM声学模型的训练。如图1所示,单音素、三音素、LDA_MLLT和SAT四个阶段均需要计算新特征,然后执行解码和对齐任务。每一次测试解码后都需要对训练数据再一次强制对齐,为下一阶段的训练提供启动条件。
最后,在Tri4b阶段,沿用SAT阶段的LDA+MLLT+fMLLR特征重新构建决策树,重新训练GMM-HMM声学模型参数并执行解码测试,重新对齐训练数据。新获得的训练数据对齐结果,以及准备交叉验证数据的CV(Cross Validation)数据对齐,都是为下一阶段的DNN训练做准备。在基线模型GMM-HMM的基础上,用说话人自适应后的LDA+MLLT+fMLLR特征训练DNN模型,构建DNN-HMM系统,进一步验证GMM-HMM基线系统的欠拟合调优对DNN-HMM性能的影响。
1.2 维吾尔语语音识别的特点

维吾尔语在形态结构上属于黏着语类型,构建语言模型时面临词汇量巨大的问题。在维吾尔语中,一个词根与多个不同词缀构成数目众多的词形变,这导致构造语言模型的词表体积巨大,也使训练数据稀疏的问题恶化,同时还会导致出现大量的未登录词(Out Of Vocabulary,OOV)[6]。因此,基线系统在构造语言模型时,采用基于词素的建模方法[10,19]。首先将候选词作词干和词缀的切分,然后以词素为基元构建4-Gram语言模型[10]。词素切分后,词表规模得到控制,数据稀疏和OOV问题也得到缓解。

表1 维吾尔语发音音素的标注集
续上表

音素英文表示音素英文表示音素英文表示Jk(隔前)vaNl(后连、前后)veOm(后连、前后)viUn(后连、隔前)voao(后连、前连、单立)vubpwcqxdryesz
2 三音素决策树及其超参数的欠拟合调优
2.1 Kaldi中的三音素决策树模型
在Kaldi中,通过决策树聚类描述三音素的声学特性,反映处于不同HMM状态的三音素在语音学意义上的相似和相异的程度。自顶向下的贪婪分裂是实现决策树聚类功能的基本算法。文献[13]描述了标准的三音素决策树模型。Kaldi的三音素决策树模型的设计、实现与标准模型大致相似,但保留了一些Kaldi自身的独特之处。这些特点在Kaldi的文档中有粗略的介绍[20],但主要细节都记录在决策树相关的源代码中。
首先,在Kaldi中并不依据语音学知识手动设计问题集,而是应用自顶向下的二叉树聚类算法自动生成问题集。在标准算法中,手动设计的问题集能反映每一类音素的语音学特点,例如元音、清辅音、浊辅音等。然而在Kaldi中,问题集自动生成,其方法更高效简洁。由于二叉树的聚类以局部最优为标准,导致自动生成的问题集对于人类而言没有明确的意义。另外,生成问题集时,处于不同上下文的同一种中间音素被无差别对待,且中间音素聚类生成的问题集将被无差别地应用于针对左侧音素和右侧音素的提问。
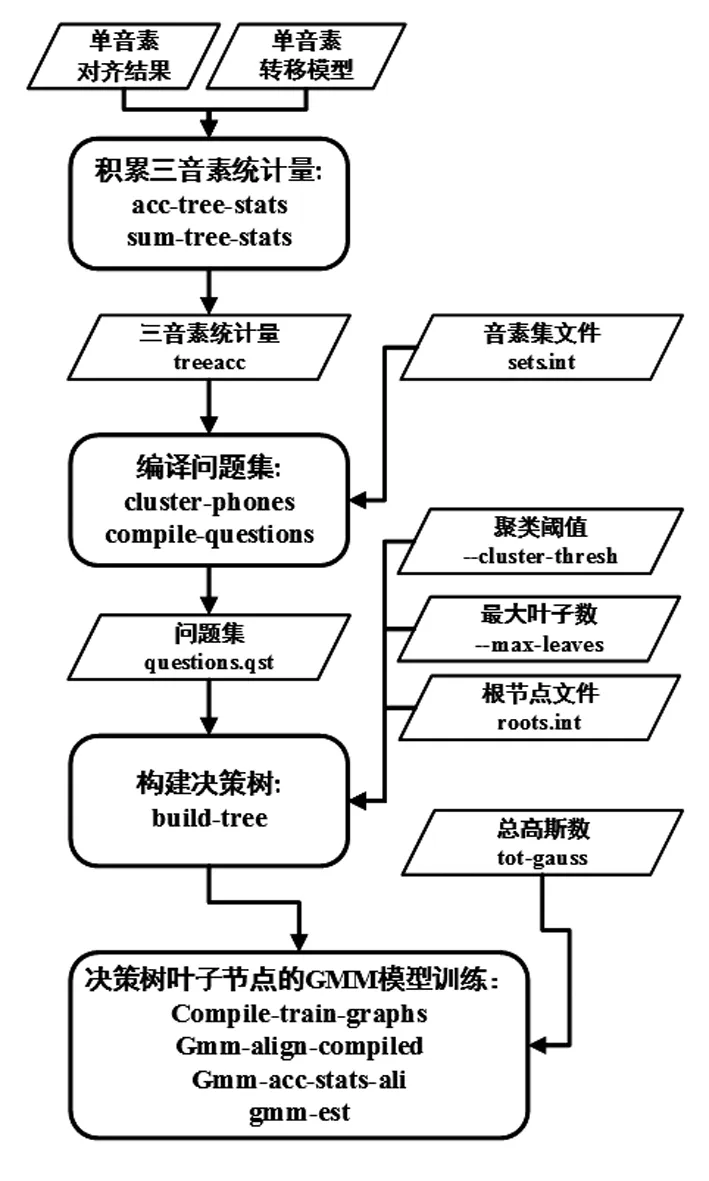
图2 基线系统中三音素决策树模型的构建与训练流程
其次,决策树可以针对中间音素和HMM状态提问。针对中间音素的分裂通过两种机制实现。其一,由根节点配置文件roots.int生成树梢映射(Stub Map),使单个中间音素或多个中间音素构成的子集形成根节点。其二,如果包含多个中间音素的子集构成根节点,在后续的二叉分裂中,Kaldi能够针对中间音素继续提问完成该子集的分裂。Kaldi中专门构建了针对HMM状态的问题集,因此能够按照roots.int文件的配置信息实现对HMM状态的分裂。
与手动设计问题集的标准算法相比,Kaldi所生成的决策树更复杂,由于针对中间音素和HMM状态的灵活配置,其高效的性能也在工程实践中得到了验证[1,3,9-11]。维吾尔语语音识别基线系统的三音素决策树模型的构建与训练流程如图2所示。
2.2 维吾尔语三音素决策树构建算法
在构建一棵三音素决策树时,Kaldi采用最常见的以局部最优为准则的自顶向下贪婪二叉分裂算法获得分裂树,然后采用自底向上的三音素聚类绑定算法获得最终的决策树。算法的行为可以通过灵活的参数配置调整。维吾尔语三音素决策树的构建算法一方面继承了Kaldi的通用算法框架,另一方面在根节点配置上有自己的特点。该算法主要包括树梢根节点映射生成、决策树贪婪分裂和根节点映射受限聚类的三音素绑定三个主要的步骤,如图3所示。

图3 维吾尔语三音素决策树构建算法的主要步骤
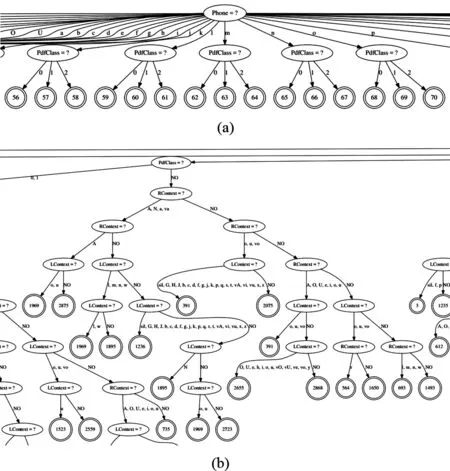
图4 基线系统生成的语音决策树的局部图。
在生成树梢根节点映射时,根据根节点文件对中间音素集的配置情况,分别按照TableEventMap和SplitEventMap两种方式将中间音素集映射为待分裂的根节点。维吾尔语语音识别基线系统的根节点文件中,每个中间音素集只包含一个音素,因此所有的根节点都按照TableEventMap方式映射生成。基于此种配置,在后续的树分裂过程中,将不会再对中间音素继续提问。得到根节点映射后,以目标函数值的局部最大提升为准则,对前期生成的每一个根节点执行二叉分裂。形成分裂方案时,既可以对左侧音素、右侧音素提问,也可以对HMM状态提问。使目标函数值的提升最大的提问方案被选中,且只有目标函数值的提升大于分裂阈值时,才允许执行分裂。最大叶子数设定了决策树叶子节点数目的上限。最后,根据聚类阈值的设定,执行根节点映射受限聚类的三音素绑定,将特征接近的三音素HMM状态自底向上地绑定到一起。在本基线系统中,聚类阈值设定为树分裂时得到的最小目标函数值提升量。通过调用不同的函数,三音素绑定可以受限也可以不受限。在本基线系统中,三音素状态的绑定受限于根节点设置,即拥有不同中间音素的三音素状态不会被绑定到一起。生成聚类树之后,再包裹一层上下文相关的接口,输出三音素决策树文件。
根据本基线系统的根节点文件和配置参数,以维吾尔语发音音素集构建的单音素决策树和三音素决策树如图4所示。三音素决策树的结构充分体现了贪婪二叉分裂算法的特点。
2.3 超参数的欠拟合调优
三音素决策树对声学模型性能的影响主要体现在三个方面。其一,三音素决策树在结构上是否分裂充分,决定了决策树模型对上下文相关音素的协同发音现象能否全面覆盖。前述小节中,最大叶子数(--max-leaves)和分裂阈值(thresh)控制着决策树的分裂充分程度。最大叶子数越大,分裂阈值越低,则对决策树的贪婪二叉分裂越彻底。然而,训练数据总是有限的,叶子节点数过多,会导致数据稀疏的问题。另一方面,决策树二叉分裂的过程,是局部最优聚类的过程,并不能保证一定得到全局最优解。因此,最大叶子数不是越大越好,分裂阈值也不是越小越好。需要注意的是,分裂阈值(thresh)在Kaldi中已被固化在C++源代码里,调整该参数时,需要重新编译对应的C++源程序。
其二,三音素决策树在充分分裂后,能够自底向上充分绑定,有效减少叶子节点总数,是克服训练时的数据稀疏问题的关键。在基线系统中,聚类阈值(--cluster-thresh)被设定为二叉分裂时得到的最小的目标函数值最大提升量。此参数在基线系统中不需要人为设定。
其三,三音素决策树的每一个叶子节点在Kaldi中对应一个pdf-id,相当于一个三音素HMM状态的GMM模型。因此,用于拟合的总高斯数(tot-gauss)越大GMM声学模型的精度就越高。另一方面,总高斯数增大,会导致模型更复杂,计算量也相应增大。
3 实验与结果分析
基于Kaldi提供的开源工具包,THUYG-20语音数据库在发布时,虽然提供了一套DNN-HMM模型的维吾尔语语音识别基线系统,但是并未对GMM-HMM模型作深入详细的讨论[10]。随同THUYG-20发布的GMM-HMM声学模型作为向DNN的过渡,没有仔细调参,性能在一定程度上是欠拟合状态。尤其是对于三音素决策树,几个关键参数的设置不理想,影响了该模型发挥最佳性能。
实验采用THUYG-20语音数据库,其中包含约20小时的语音训练数据和2. 5小时左右的语音测试数据,词汇量总共约4. 5万[10]。基线系统在训练三音素决策树和GMM模型时,采用基于最大似然准则的EM算法。HMM的参数训练则以循环迭代的方式采用Viterbi算法代替常用的Baum-Welch算法。由于维吾尔语的黏着语特性,基线系统采用两种语言模型,一种是基于词的3-Gram语言模型,另一种是基于词素的4-Gram语言模型[10,19]。实验结果将分别报告基于两种语言模型的词错误率。
3.1 实验1:三音素决策树超参数调优
三音素决策树的调优参数主要包括:最大叶子数(--max-leaves)和总高斯数(tot-gauss)。在THUYG-20所提供的原始脚本中[10],三音素阶段,最大叶子数设置为2 000,总高斯数设置为10 000;在LDA-MLLT阶段,最大叶子数设置为2 500,总高斯数则设置为15 000。调整此组参数,分别在三音素训练和LDA_MLLT训练阶段,基于词的语言模型和基于词素的语言模型的词错误率结果如图5所示。

表2 三音素阶段的优化结果

表3 LDA_MLLT阶段的优化结果

图5 词错误率随最大叶子数和总高斯数调优时的变化曲线(a)表示三音素阶段的调优情况,(b)表示LDA_MLLT阶段的调优情况。图中word表示采用基于词的3-Gram语言模型,morpheme表示采用基于词素的4-Gram语言模型。
从图5可知,在三音素阶段,最大叶子数为4 000时的词错误率均优于该参数设置为2 000时的情况;在最大叶子数一定的情况下,逐步增大总高斯数,词错误率也随之逐步下降。在LDA_MLLT阶段,最大叶子数为4 500时的词错误率普遍优于该参数设置为2 500时的情况;在最大叶子数一定的情况下,逐步增大总高斯数,词错误率也随之逐步下降。在上述两个阶段,随着总高斯数的持续增加,每增加1 000高斯数带来的词错误率降低越来越小。
权衡模型性能和计算效率之间的平衡,在三音素训练阶段设置最大叶子数为4 000,总高斯数为30 000,在LDA_MLLT训练阶段,设置最大叶子数为4 500,总高斯数为35 000,此时的基线系统词错误率如表2、表3所示。从表2和表3可知,相对于THUYG-20原始脚本中的参数设置结果,调优后,词错误率下降的最大幅度为13. 1%。
3.2 实验2:三音素决策树调优对DNN-HMM性能的影响
为了探讨三音素决策树参数调优对DNN-HMM模型性能的影响,在Tri4b阶段之后,分别基于交叉熵(Cross Entropy,xEnt)和最小音素误差(Minimum Phone Error,MPE)准则训练DNN声学模型,测试结果如表4所示。在表4中,分别给出了各个阶段在三音素决策树参数调优前和调优后的测试结果。
在Kaldi中,DNN模型有三种不同的版本,此处采用Karel的实现版本[21]。三音素决策树调优前,所有参数采用THUYG-20所提供的原始脚本中的参数[10],调优后,按照上一小节的策略增大最大叶子数和总高斯数提高决策树的性能。实验结果表明,相对于调优前,调优后三音素、LDA_MLLT、SAT和Tri4b四个阶段都得到了更低的WER。比较而言,DNN阶段的WER的优化程度相对较弱,说明DNN的强大拟合能力弥补了调优前后决策树性能上的差距。调优后,基于词素语言模型的两个DNN结果是空着的,因为THUYG-20中没有发布对应的解码器[10],这个名为latgen-biglm-faster-mapped的解码器不属于开源的一部分。

表4 三音素决策树调优前后各阶段WER对比
4 总结
三音素决策树是GMM-HMM和DNN-HMM声学模型的关键单元技术,其自顶向下的分裂和自底向上的聚类绑定结果决定了声学模型的建模单元;决策树的分裂是否充分,每个叶子节点的GMM拟合是否精确,直接影响着声学模型的性能。本文通过逐步调优最大叶子数和总高斯数,发现增加最大叶子数能够使决策树分裂更充分,在最大叶子数一定的条件下,逐步提高总高斯数,声学模型性能也逐步提高,词错误率逐步下降,且词错误率的下降幅度越来越小。实验表明,在采用基于词素的4-Gram语言模型时,调优上述参数,三音素和LDA_MLLT阶段的词错误率分别下降了13. 1%和11. 7%。
