跨数据源论文集成
2018-10-19张帆进顾晓韬姚沛然
张帆进,顾晓韬,姚沛然,唐 杰
(清华大学 计算机科学与技术系,北京 100084)
0 引言
在大数据时代,有很多实体分布在不同的数据源中。比如,很多学者分布在不同的研究者社交网络中,如 Google Scholar、MAG 等;同一论文可能分布在不同的数据源中,如DBLP、arXiv等。由此,一个自然的问题是: 如何把不同数据源中的数据集成起来?
具体地,本文研究异构数据源的论文集成问题,旨在利用论文的不同属性,将不同数据源中的同一实体匹配起来。集成不同数据源的数据有很大的应用价值,如可以扩充数据库或者进一步地将数据集成的结果应用于问答系统或信息检索等应用中。
然而,该研究面临着以下几方面挑战:
•数据异构[1]。由于论文数据分布在不同数据源,可能面临数据异构的问题。比如论文作者可能存在不同的格式,如Quoc Le和Le,Quoc。
•同名消歧问题[2-4]。同一名字可以表示多个实体,这也给数据集成带来了很大困难。不同论文可能有相同的题目,如Data、data everywhere可对应多篇文章。
•数据规模大。由于数据爆炸式增长,也要求数据集成能够有比较快的速度。以学术出版物为例,著名的出版集团Elsevier在过去的150年出版了大量学术刊物。据他们在数据库Scopus上的统计,从1996年至2014年,学术出版物的数量实现了翻倍,由此可见数据的快速增长。在大规模数据集成任务中,从外来数据源输入一个实体,要求能够在线匹配到可能的结果,同时还要保持较高的匹配准确率。
尽管现在已经有很多关于数据集成的工作,但是由于数据集成面临各种挑战,集成的准确率和速度仍然有很大的提升的空间。本文中我们对论文集成问题设计了针对性的算法来达到较高的准确率或速度。此外,我们设计了一个用于大规模论文匹配的原型系统。本文的贡献总结如下:
(1) 提出了两个论文匹配算法MHash和MCNN。MHash利用哈希算法将论文映射到低维的汉明空间,能够快速实现论文匹配。在结合论文的各种属性后,MHash能够达到较高的匹配准确率(93%+)。而MCNN把论文匹配问题看成计算两个文本相似度的问题,首先构造了基于词语相似度的相似矩阵,然后利用卷积神经网络来计算精细的匹配模式,最终得到相似度。MCNN可以达到非常高的匹配准确率(98%+)。
(2) 探讨了大规模论文匹配的问题。我们设计了一个基于论文题目的异步搜索框架。实验结果表示: 该框架可以在15天内完成64 639 608篇论文的匹配。
本文的剩余部分组织如下,第一节调研数据集成的相关工作。第二节提出论文集成的问题定义。第三节和第四节介绍两个论文匹配算法。第五节展示上述论文匹配算法的方法评测和实验结果。接着,第六节介绍论文数据集成的实际应用,包括我们设计的适用于大规模论文匹配的原型系统和公开数据集介绍。最后,第七节总结全文。
1 相关工作
本节介绍数据集成方面的相关工作。数据集成是数据挖掘领域的一个经典问题,它与实体匹配、数据库去重、同名消歧等问题密切相关。数据集成从根本上来讲是实体匹配问题,是要判断不同数据源中两个实体是否本质上是同一个实体。关于数据集成的综述可以参见文献[5-6]。下面,我们分类介绍数据集成方法。
1.1 基于规则的方法
基于规则的匹配方法是指: 根据人类专家设计或训练数据生成的多条匹配规则,对其进行组合(如逻辑操作、优先级设定等),来构造复杂的匹配条件,根据匹配条件得到最终的结果。
举一个简单的例子,下面的伪代码展示了根据姓名(name)和机构(aff)两种规则匹配专家的方法。

FORALL(e1,e2)in EXPERTS IF e1.name=e2. name AND e1.aff is similar to e2. aff THEN r1 matches r2 ELSE r1 doesnt match r2
Li等人[7]用基于规则的方法来解决实体识别的问题。他们认为,用基于相似度的方法来判别两个实体是否为同一个实体在实际应用中不一定奏效,由于数据异构等问题,实际上为同一个实体的两个实体不一定能计算出比较高的相似度。因此,他们采用基于规则的方法并且提出了一个高效的规则发现算法。
人工参与规则设计和规则组合需要较高的人力成本,因此,更加实用且可扩展性强的方式是采用由数据生成的匹配规则,然后自动调整为合适的规则组合方式。
1.2 监督/半监督学习方法
监督学习方法要求训练数据集中的数据为有标注数据,即已知哪些实体是匹配的,哪些实体是不匹配的,如Tang等人[8]将实体匹配问题转化为最小化贝叶斯决策风险的问题,能够得到一对一或者一对多的匹配结果。
然而,实际应用中难以找到大量的标注数据,因此,有些方法同时利用了训练数据集中的标注数据和未标注数据,采用半监督学习方法来学习匹配模型。如,Rong等人[9]把实体匹配问题转化为实体对的二分类问题。他们还利用了迁移学习的方法,充分利用已有的匹配好的实体对,来减少需要标注的数据。具体方法如下: ①预匹配: 采用关键词过滤一些不可能匹配的实体对,得到待匹配的实体对。②计算相似度向量: 计算实体对各属性之间的相似度,相似度向量中包含了不直接对应的属性之间的相似度,捕捉了它们语义上可能的相似性。③训练分类器:利用迁移学习的方法,对相似度向量训练分类器进行预测。
1.3 无监督学习方法
无监督学习方法不需要对数据集中实体是否匹配进行标注,往往可以适应更多的数据集成场景。如Liu等人[10]巧妙地利用人名的唯一性度量函数作为弱监督信息,将用户属性、用户生成的文档,以及用户在不同网络中的活动集成到一个学习框架中,提出了一个跨网络实体匹配的无监督算法。
1.4 利用神经网络的方法
近来,有一些实体匹配的工作利用了神经网络来提升匹配效果[11-12]。Sun等人[13]利用神经网络来研究实体消歧问题,他们将描述实体的变长字符串编码在一个连续的向量空间中。Hu等人[14]研究两个句子语义上的匹配问题。他们利用了卷积神经网络来建模两个句子的相似性。该模型可以表示出句子的语法结构,以及尽可能捕捉到句子间丰富的匹配模式。
2 问题定义
令G1={V1,R1},G2={V2,R2}表示两个不同数据源的论文网络(比如DBLP和ACM Digital Library)其中,V1={v1,v2,…,vN1}和V2={u1,u2,…,uN2} 代表论文集合。R1和R2代表论文的属性矩阵,包括论文题目、作者列表等属性。
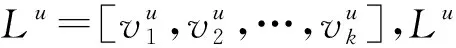
论文匹配算法有两个设计目标: 快速而准确。 在下面两节中,我们提出了两个论文匹配算法,第一个算法MHash利用哈希算法来加速匹配过程,该算法可以适应大规模论文匹配场景;第二个算法MCNN利用卷积神经网络(CNN)来提高匹配准确率,它可以克服不同数据源数据异构的问题。
3 基于哈希学习的论文匹配算法(MHash)
本节介绍一个快速的论文匹配算法(MHash),它可以用于在线匹配论文。该算法是一个无监督算法,它包括两个步骤: 特征构造和哈希算法。算法流程如图1所示。
3.1 特征构造
特征构造的目标是把输入的文本数值化,具体地,我们的目标是将长度变化的文本转化为固定长度的特征向量。同时,这些特征向量要能捕捉到文本的结构和语义信息。为方便起见,在下文中,我们将该步骤构造的特征称之为中间特征。在匹配过程中,我们用到的论文属性有: 论文题目、作者列表、发表会议(或期刊)、发表年份。下面,我们将各属性简称为: 题目、作者列表、会议、年份。表1总结了不同属性的特征构造方法,下面我们依次详细地介绍各属性的特征构造方法。
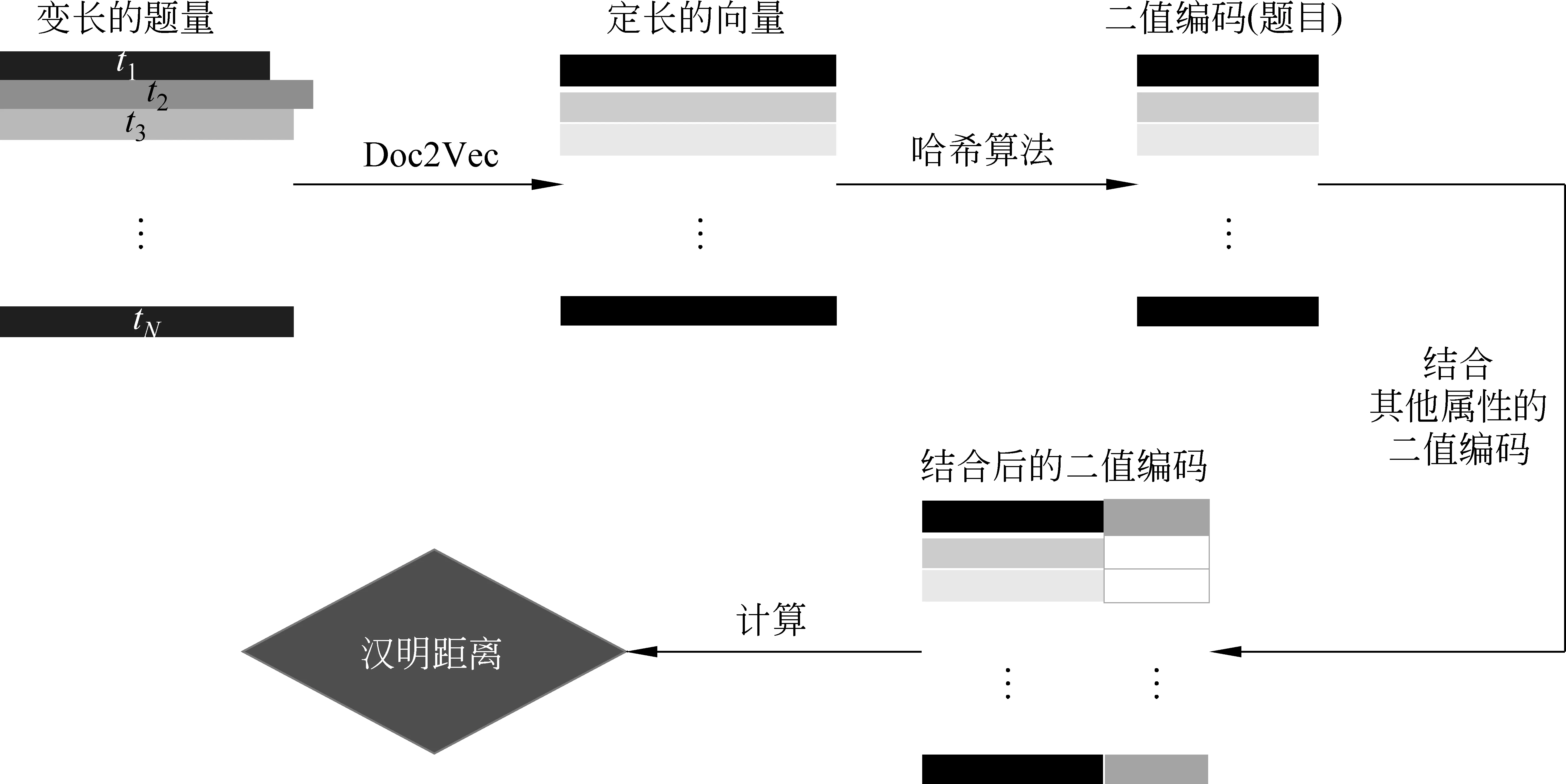
图1 基于哈希学习的论文匹配算法流程图
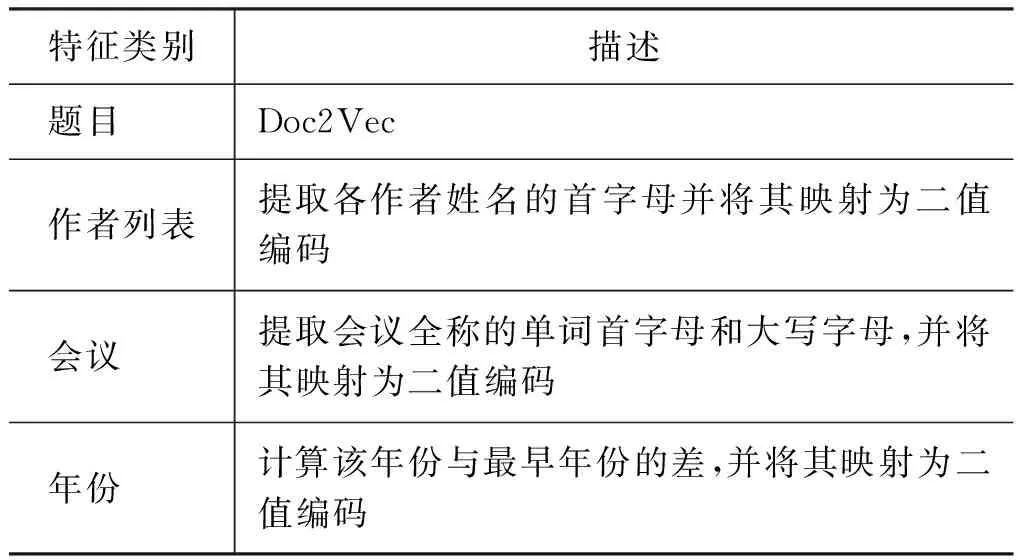
表1 中间特征构造
题目是最富有变化的论文属性,因为它的长度和内容都可以有较大的变化。题目特征的构造采用了Doc2Vec[15]。它可以把变化长度的文本转化为固定长度的向量表示。Doc2Vec是由Word2Vec衍生而来。Word2Vec是一个两层(浅层)的神经网络模型,它利用单词的上下文关系来学习单词的向量表示。因此,语义上相近的两个单词,若它们的上下文通常是相同的单词,则它们的向量表示会很相近。比如,“via”的向量表示可能和“by”相近。在Doc2Vec模型中,每个文档(doc)会额外引入一个“文档向量”。它可以被看作是文档中潜在的一个具有代表性的单词,或者说是文档的主题。“文档向量”和文档中的单词向量被一起输入神经网络。Doc2Vec适合于构造论文题目特征,因为在不同数据源中同一篇论文的题目经常有绝大部分单词是相同的,而Doc2Vec可以捕捉题目中单词的语义信息。在该步骤后,我们用T=[τ1,τ2,…,τN]T∈RN×d1来表示论文题目的中间特征。
对于论文的其他特征,输出的中间特征是二值编码。在表1的第2~3行,二值编码的每一位映射到字母“a”到“z”,若该字母出现过,则对应位置为1,否则为0。在最后一行,所得的差代表二值编码中从右往左连续出现的“1”的个数,二值编码最右端均为1,最左端均为0。这些二值特征忽略了原始文本中单词的顺序,因为文本中单词的顺序是可以改变的。例如,作者姓名有多种不同的表示方式。Tomas Mikolov和Mikolov,T这两种表示即改变了单词顺序。同时,这种提取特征的方法捕捉了属性中最重要的信息,比如,对于会议来说,提取大写字母解决了会议名称缩写带来的数据异构问题。我们用A∈{-1,+1}N×b2,V∈{-1,+1}N×b3y∈{-1,+1}N×b4,来表示作者列表,会议,年份的间特征。
3.2 哈希算法
题目的中间特征是高维的实值向量。实值向量的缺点有: 计算复杂度高和存储开销大。因此,我们利用哈希算法来把实值向量转化为二值编码,以此来减少计算开销和存储开销。
哈希算法分为两类: 数据独立方法和数据依赖方法(即哈希学习方法)[16]。它们都是把数据从原始的高维空间通过哈希函数映射到低维的汉明空间。对于数据独立方法,哈希函数是随机产生或者手工构造的,所以说哈希函数和数据是独立的。对于数据依赖方法,哈希函数是根据原始数据学习得到的,不同的原始数据可能学习出不同的哈希函数。
局部敏感哈希(LSH)[17]是一种数据独立方法。它已经广泛应用于高效的近似最近邻搜索问题(ANN)中。它所采用的哈希函数是随机产生的,能够保证: 如果两个向量在原始空间是相近的,那么它们有很大概率被映射到同一个二值编码。
LSH可以保持数据在原空间的相似度,我们首先定义度量原空间相似度的方法为余弦相似度(cosine similarity),如式(1)所示。
(1)
研究表明随机投影能够保持向量的余弦相似度[18]。在实验部分5.2节中也会展示这一点: 题目中间特征的相似度可以被LSH保持。我们将哈希函数定义如式(2)所示。
h(τ)=sign(τ·W)
(2)
在这里,W∈Rd1×b1是投影矩阵,矩阵中的每个元素独立从高斯分布中采样得到。经过哈希之后,矩阵T被转换为C=[h(τ1),h(τ2),…,h(τN)]∈{-1,+1}N×b1。此外,我们还可以使用不同的哈希算法,比如数据依赖方法。哈希算法的目标是将中间的实值向量转化为二值编码,并尽可能保持实值向量的相似性,数据独立方法和数据依赖方法都可以达到这个目标。除LSH外,我们还尝试了无监督的数据依赖方法SGH[19]。
下面我们考虑如何结合论文的各个属性。由于我们获得了论文各属性的二值编码,一个直观的办法是将它们拼接起来,作为论文的二值编码。实验证明结合后的论文编码匹配效果优于只使用单个属性的效果。于是,我们得到了基于哈希算法的无监督论文匹配算法。
4 基于卷积神经网络的论文匹配算法(MCNN)
本节介绍基于卷积神经网络的论文匹配算法,设计该算法的目的在于希望获得较高的匹配准确率。该算法的思想是:将论文匹配问题看成是计算成对论文的相似度的问题。因此,可以将论文匹配分为两个步骤: ①预匹配: 过滤得到可能匹配的论文对。②计算论文对之间的相似度,进而得到匹配结果。
该算法需要进行预匹配的原因是: 为了获得较高的匹配准确率,需要更为精细地计算论文相似度。因此,计算每对论文的时间开销较大。如果逐一计算两个数据源中每对论文的相似度,对于平方级别O(|V1||V2|)的复杂度,总计算开销会特别大。因此我们先进行预匹配,过滤掉大量匹配可能性很低的论文对。
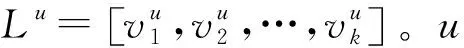
对于相似度计算,受文献[12]启发,我们将两篇论文u,v看成两串文本text1,text2,不是直接计算出一个相似度得分,而是先根据两个文本中单词的相似度构造出一个相似度矩阵M,然后利用CNN捕捉文本间相似度的模式,最后输出一个相似度得分。具体地,相似度计算可以分为以下三步。
4.1 构造相似度矩阵
首先,我们需要选择构造相似度矩阵的文本。对于论文来说,可以选择论文题目。同时,为了结合论文的各个属性,可以添加作者列表、会议等属性。在实验部分5.2节可以看到,该算法可以比较容易结合各种属性,利用论文的更多信息来计算出更准确的相似度得分。在本节中,我们以论文题目举例。
我们截取论文题目的前l个单词,设text1={α1,α2,…,αl},text2={β1,β2,…,βl}。定义两个单词之间的相似度如式(3)所示。
sij=αi⊗βj
(3)
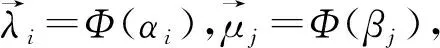

图2 两个文本的相似度矩阵M,网格中的颜色越接近白色,表示相似度值越大
4.2 CNN模型
卷积神经网络(CNN)在图像识别领域已经取得了巨大成功。和图像类似,相似度矩阵也是一个二维矩阵。因此,我们将相似度矩阵M作为CNN模型的输入z0=M。网络的结构设计如下: 第一层对输入矩阵进行卷积操作。第一层的第n个神经元计算过滤器(filter)ω(1,k)和矩阵中各个小区域的卷积。然后将每个卷积得到的值用一个激活函数δ对特征进行非线性映射,如式(4)所示。
(4)
式(4)中,rn表示第n个过滤器的大小,θ(1,n)表示第n个过滤器的偏置项。在该层中,我们使用多个过滤器来捕捉不同模式的相似度。比如,在图3中,过滤器A可以捕捉两个文本中单词顺序的相似度,如“(cat likes dog)-(cat enjoys dog)”,然而过滤器B可以捕捉两个文本中单词乱序的相似度,如“(cat and log)-(dog and cat)”。
第二层对第一层的输出z(1,n)进行池化(pool-ing)操作,用来减少特征表示的大小和参数的数量。池化操作对第一层每个神经元的输出独立进行操作,这里采用的池化操作是最大化操作。形式上,第二层网络的输出z(2,n)可以表示为式(5)。
(5)
式(5)中,rn表示第n个池化过滤器的大小。在经过前两层处理后,我们继续进行多层卷积和池化操作,来捕捉更高阶的特征。
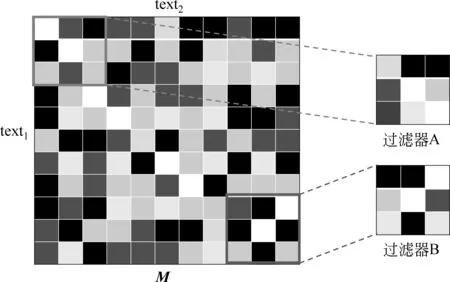
图3 示例
在卷积层利用不同的过滤器(filter),可以捕捉不同模式的相似度。左边的相似矩阵M和图2中的矩阵相同。
(6)
(7)
在式(6)中,ck代表第k层过滤器的个数。
我们使用多层感知机(MLP)来输出最终的相似度得分。具体地,我们使用了两个全连接层来得到相似度向量,如式(8)所示。
(s0,s1)T=W2δ(W1·z+θ1)+θ2
(8)
在这里s0表示不相似度,s1表示相似度。Wi和θi是第i个全连接层的过滤器和偏置项,δ表示激活函数。在实验中,我们采用ReLU[21]作为所有卷积层和全连接层的激活函数。ReLU比sigmoid,tanh等激活函数能产生更准确的结果,而且收敛更快。整个网络的结构可参见图4。
4.3 训练方法
我们用softmax来表示属于每一类(匹配或不匹配)的概率,以及用交叉熵作为优化的目标函数。因此,优化目标可以写成式(9)。
(9)
式(9)中,y(i)表示第i对训练样本的标签。
我们用反向传播算法(back-propagation)来求解神经网络的参数。训练方法采用了随机梯度下降的变体Adagrad[22]和mini-batch策略。在网络的倒数第二层,我们采用了dropout来避免隐层神经元的互相适应。
图4 CNN模型网络结构图
5 方法评测和实验结果
5.1 实验设置
数据集: 在现实应用中,很难在不同数据源找到大量匹配的(有标记的)论文对。此外,在真实匹配的例子中,大部分论文各属性都比较相似。因此,为了更好地评估我们的方法,我们人工构造了两个数据集,原始论文集和噪声论文集。原始数据集大小为5万篇,从AMiner论文库中收集得到,每篇论文保留了四个属性: 题目、作者列表、会议和年份。噪声数据集是对原始数据集中的每篇论文加噪声生成的。从而,加噪声前后的论文自然形成了一对匹配的论文,避免了人工标注。我们首先统计了已知匹配论文的匹配难点,加噪声的方法是根据统计结果设计的。匹配难点有:论文题目中的多个单词被错误结合成一个单词,作者姓名的格式有全名和缩写姓名等。
对比方法
•Keywords(KeyII)。该方法基于题目的关键词和作者列表相似度找匹配的论文。实现时取论文题目的前w个单词构建倒排索引。根据论文题目索引到关键词相同的论文列表后,将论文列表按照作者的相似度排序。计算作者相似度时,先将作者列表author_list连接为一个字符串str(author_list),然后根据两个字符串中共同出现的字母数量来计算,如式(10)所示。
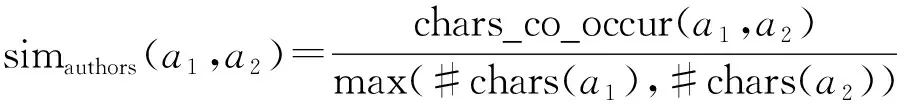
(10)
•Doc2Vec。该方法我们在3.1小节介绍过。使用Doc2Vec时,我们采用Gensim[23]中的doc2vec模型训练大量的论文语料[注]数据集可访问https://aminer.org/citation.。在该方法中,我们使用了“论文题目”一个属性。论文的相似度通过余弦相似度度量。
•MLSH。该方法先用Doc2Vec得到题目中间特征,然后用LSH将中间特征映射为二值编码。论文的相似度通过汉明距离度量。
•MLSH++。该方法在MLSH的基础上,结合了“题目”之外的其他属性。
•MSGH。该方法先用Doc2Vec得到题目中间特征,然后用SGH将中间特征映射为二值编码。
•MSGH++。该方法在MSGH的基础上,结合了“题目”之外的其他属性。
•MCNN。该方法的训练语料和Doc2Vec相同,用Word2Vec模型训练得到单词的向量表示。训练的正例为加噪声前后的论文对,训练的负例从不匹配的论文对中采样生成。采样方法是: 根据各属性(题目、作者等),找到和论文u的某一属性最相似且不匹配的论文u′。在CNN模型中,只利用了论文题目这个属性,取题目的前7个单词(l=7)构造相似度矩阵。
•MCNN++。该方法在MCNN的基础上,增加了“作者列表”属性。取一篇论文的前两个作者,在他们的姓名中取姓和名的首字母作为特征。即构造大小为11×11的相似度矩阵(l=11)。
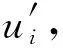
(11)
在式(11)中,‖表示指示函数。
5.2 评估结果
表2比较了各个论文匹配算法的准确率@topK。可以看出,相比于基于题目关键词的方法KeyII,Doc2Vec能更好地、完整地保持题目的语义信息,从而匹配得到更好的结果。基于哈希的匹配算法MLSH,MSGH会损失一些匹配精度,但是可以提高匹配速度。在结合作者列表、会议等属性后,MLSH++,MSGH++能够有比较大的准确率提升。同时,可以发现,MLSH++,MSGH++的准确率非常接近,说明此时题目的重要性已经被弱化,作者列表、会议和年份等属性对匹配起了非常重要的作用。对于Doc2Vec,MLSH,MSGH这几个方法,题目完全相同的论文会被映射成为完全相同的特征,这也是它们比KeyII表现更好的原因之一。
对于基于CNN的匹配算法MCNN和MCNN++,他们的准确率比其他所有方法都高。可见,基于相似矩阵,这两个算法利用CNN捕捉了论文之间更为精细的匹配模式,尤其是结合作者列表后,MCNN++可以得到非常高的准确率。但是基于CNN的方法由于需要构造相似矩阵,经过多层神经网络的计算,计算开销也是所有方法中最大的。
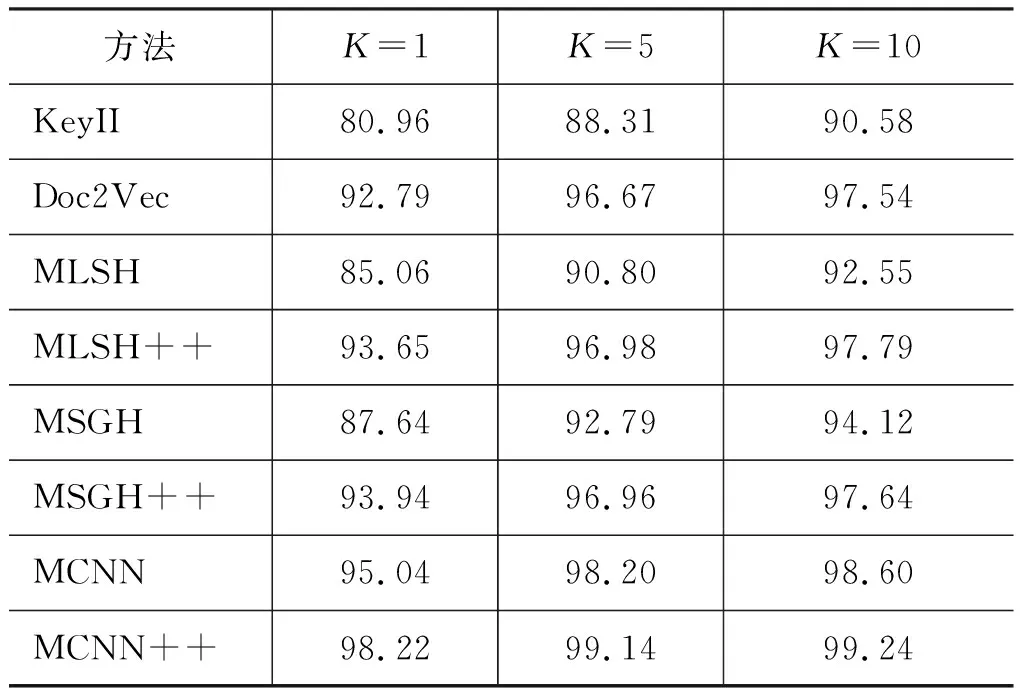
表2 论文匹配的准确率 @topK/%
6 原型系统与公开数据集
本节试图把论文匹配的问题扩展到大规模场 景,在真实场景下匹配两个大规模论文库。
6.1 论文匹配框架
为了较快地获得大量论文的匹配结果,结合实际情况下目前我们对两个论文库所拥有的权限:G1中的论文可以通过API访问,G2中的全部论文可以通过数据库访问,因此,我们设计了一个针对大规模论文匹配的异步搜索框架。下面我们分模块对该框架进行介绍。
•数据库读取: 由于论文总数达到上亿级别,我们成块(batch)从G2中读取论文进行处理,在实验中,每块的数量batch_size=100 000。
•单篇论文搜索: 对于G2中的每篇论文u,我们根据它的题目titleu在G1中用API进行搜索。我们发现G1中搜索论文题目的API有两个,一个专门给用户提供的API服务(称为API-A),另一个用于线上搜索(称为API-B)。他们的性质如下:
使用这两个API 时,我们先去除题目中的特殊字符,根据题目搜索到可能匹配的论文,返回每篇论文的题目、作者列表、会议、年份。由于这两个API各有优劣,在G1中搜索G2的一篇论文时,我们先用API-A进行搜索,它能较快返回匹配结果;在API-A搜不到相应结果时,再用API-B搜索,API-B可以返回比较全的匹配结果。
•多篇论文搜索: 我们对成块读取的论文批量进行搜索。由于对API的请求次数频繁,我们设计了一个代理池,每篇论文用不同的代理进行请求,代理选择方法是随机从代理池中选择。当一个代理失效时,它会从代理池中去除。当代理池中的代理数量小于初始数量的1/10时,更新代理池中代理的数量为初始数量。我们对不同的论文异步进行搜索,这样可以使不同论文的匹配并行进行。
•匹配策略: 该匹配策略非常严格,目的是产生一批高度匹配的论文对。具体地,我们将请求返回结果中各论文的题目、作者列表、年份和被搜索论文进行比较。当两篇待匹配的论文有非常相似的题目、相同数量的作者、相似的作者名字及相同的发表年份时,认为两者匹配。上述匹配条件中,模糊匹配通过编辑距离[注]https: //en.wikipedia.org/wiki/Levenshtein_distance.来实现。
6.2 方法评测和实验结果
实验设置:G2的论文库来自AMiner经过论文去重后的数据库,在经过简单的预处理后(去除论文库中的噪声),G2中待匹配的论文总数为: 154 771 162篇。G1的论文来自MAG。所有实验用Python实现,实验平台为Intel(R) Xeon(R) CPU E5-4650 0@ 2.70GHz 32 cores and 500GB RAM Linux Server。
实验结果: 实验使用了两个版本的论文匹配框架同时进行匹配,在15天内遍历了G2中论文数据库一趟。得到64 639 608对论文匹配结果。我们随机抽取了100 000对匹配结果进行人工标注,得到匹配正确的论文对有99 699对,匹配准确率为99.70%。同时,我们存储了所有的论文查询结果: 共113 487 083条。实验结果说明: 有57.00%的论文可以通过严格的匹配策略匹配成功。此外,我们还记录了请求有返回结果但是匹配失败的论文: 共38 651 737篇,这些论文的匹配存在三种情况: ①确实在G1中找不到匹配结果; ②请求API时出现异常,返回为空,实际可能存在匹配结果; ③查询结果不为空,但是用当前的策略匹配不到结果,但实际上有匹配的论文。论文匹配结果已作为公开数据集发布。
6.3 公开数据集
该公开数据集[注]https://www.openacademic.ai/oag(https://aminer.org/open-academic-graph)包括来自AMiner和MAG的64 639 608对论文的匹配结果,以及AMiner和MAG的全部论文数据,共约300 000 000篇论文。具体包括154 771 162篇来自AMiner的论文和166 192 182篇来自MAG的论文。匹配数据给出了AMiner和MAG匹配论文ID的对应关系。论文数据涵盖了全面的论文属性,如论文题目、作者列表、摘要、引用关系等。该数据集可用于研究引用关系网络、论文内容挖掘、大规模学术图谱集成等。
7 结论和展望
本文研究异构数据源的论文集成问题。我们提出两个论文匹配算法:第一个算法MHash利用哈希算法来加速论文匹配,第二个算法利用卷积神经网络来提高匹配准确率。实验结果表明:结合论文的各种属性,MHash能够同时得到较快的匹配速度和较高的匹配准确率(93%+),而MCNN能够得到非常高的匹配准确率(98%+)。同时,我们设计了一个大规模论文匹配原型系统:对于论文匹配,该系统在15天内得到了64 639 608对AMiner和MAG论文的匹配结果。匹配结果和AMiner、MAG的全部论文数据已作为公开数据集发布。
致谢本课题承蒙微软亚洲研究院资助。
