利用准私密社交网络文本数据检测抑郁用户的可行性分析
2018-10-19刘德喜邱家洪万常选刘喜平钟敏娟郭海峰
刘德喜,邱家洪,万常选,刘喜平,钟敏娟,郭海峰,邓 松
(1. 江西财经大学 信息管理学院,江西 南昌 330013;2. 江西财经大学 江西省高校数据与知识工程重点实验室,江西 南昌 330013;3. 江西财经大学 学生工作处,江西 南昌 330013;4. 江西财经大学 软件与通信工程学院,江西 南昌 330013)
0 引言
世界健康组织(WHO)在2012年的研究表明,全世界约有3.5亿人患有抑郁症,严重的抑郁可以导致自杀[1]。由于缺少心理健康知识以及心理疾病显著区别于身体疾病的无疼痛感,导致许多人身患抑郁而不知或是由于抑郁羞耻感而不敢主动寻找专业人士帮助。心理学上通过抑郁自评量表检测的方法属于侵入型检测方法,在适时性和自评频率方面存在不足,导致不能及时检测出抑郁症患者,延误治疗。随着互联网和信息技术的发展,Twitter、微博、微信等社交媒体已经成为人们互相交流必不可少的工具,形成与物理空间相对等的网络社区,用户网络行为信息也记录在社交网络中,为检测用户抑郁症等心理健康疾病提供了一种新的途径。
目前,已有较多利用用户在社交网络上的行为和发布的文本进行用户心理健康分析的相关研究工作,所选取的社交网络平台大都是Twitter、微博、人人网等公开社交网络。公开社交网络支持单向关注的特点使得用户隐私权无法得到有效的保障。因此,用户在公开社交网络上更倾向于表达话题性观点,大部分用户仅仅是在热点话题上表现活跃。
与公开社交网络相比,QQ、微信等社交网络因为朋友圈的划分和有限的用户访问权限设置等,更能保障用户隐私不被泄露,私密性更强,更加受到用户的青睐。本文称这种信息只在好友圈可见的社交网络为准私密社交网络,准私密社交网络越来越成为人们日常生活不可分割的一部分。直观上,相比公开社交网络数据,准私密社交网络数据能够更有效地反映出用户的生活状态与心理状态,更能反映用户的抑郁等心理健康问题。
已有的研究工作大部分是基于公开社交网络的,鲜有文献分析准私密社交网络数据是否可用于分析用户的抑郁倾向,以及如何利用这些数据分析用户的抑郁倾向。本文从训练样本选择、特征量化方法、分类模型的选择、文本内容特征四个角度考察利用准私密社交网络文本检测抑郁用户的可行性,并与基于公开社交网络数据进行抑郁检测的相关文献进行比较。论文的结构安排如下: 首先介绍研究背景,然后介绍利用社交网络数据分析用户心理健康的研究现状,接下来介绍数据采集与预处理、候选特征抽取与量化、训练样本选择、相关性分析、检测模型选择,并通过实验考察样本选择、特征量化方法对抑郁用户检测模型的影响,分析不同的文本特征在检测模型上的表现,最后对全文进行总结。
1 相关研究
利用社交网络数据分析用户心理健康状态具有实时性、高效性、无侵入性等特点,对心理健康状况欠佳人员的及时检测、辅导和诊疗具有重要意义,得到心理学领域和计算机科学领域研究者的关注。已有的研究工作通常把利用社交网络数据分析用户心理健康状态视为一个分类问题,通过样本训练分类模型,将社交网络用户的自杀倾向、抑郁等心理健康问题分类为“有”“无”两大类。下面主要从社交网络数据与抑郁的相关性分析、数据源选择、特征选择和量化、训练样本选择、分类模型五个方面对研究现状进行描述。
大量研究发现可以通过社交网络活动记录对用户的抑郁状态进行检测[1-19],严重的抑郁症患者在社交网络上的行为与正常人存在显著的差异[1]。Choudhury等[3]通过研究Amazon用户的语言风格和网络行为,发现抑郁用户社会活动少,消极情感更为严重,对人际关系和药物的使用更为担心,同时更注重宗教思想的表达。Park等[5]发现抑郁用户使用消极情感词和愤怒词明显较正常用户多,用户在社交网络上不仅表达抑郁情感也会发布一些非常隐私的信息。
数据源方面,大多数相关研究使用了当前比较流行的社交网络平台,如Twitter[2-5,13-15]、Facebook[9-11,19]、论坛[16-17]、新浪微博[1,6-7,18]、人人网[20]等。也有利用用户的其他上网痕迹,如网关记录的网页浏览、搜索行为等[21]。而Hiraga[22]使用了来自Yahoo Japan、Livedoor等多个blog平台的数据。
特征选择方面,被采用较多的特征主要包括语言特征、行为特征、属性特征、社交关系特征等。语言特征是指用户的社交网络用语表现出来的特征,主要有情感词、人称代词、表情符号的使用等[1,5-7,10,16-18]。行为特征主要有点赞数、转发数、原创帖子数等[8],研究者认为不同心理健康状态的用户网络行为表现不同。属性特征是指社交网络用户的属性,主要包括年龄、性别、职业等[2,8,11-12]。社交关系特征是社交网络中错综复杂的社交关系的表现,主要有好友个数、互动频数、亲密度等[7]。由于LIWC词典(Linguistic Inquiry and Word Count)[注]http: //liwc.wpengine.com/.是从心理学的角度描绘用户的用词特点,因此经常被用作心理健康分析的语言特征[5,16-18,23]。除以上几类特征外,也有文献直接利用文本中的n-gram、词性(POS)等信息[22]。
相对其他用户,社交网络上的抑郁用户数量非常少,因此采集的样本通常是极度不平衡的,大量的研究工作采用高底分组的方法构建平衡训练样本。文献[6]采用随机抽取的方式,而文献[24]则采用高低分组的方式,分别抽取了自杀风险最高的和最低的80%的用户构成自杀用户数据集。为了在训练样本中反映抑郁用户和正常用户的真实分布,文献[21]采用非平衡采样的方式,其中449个抑郁用户、279个正常用户。
分类模型的选择方面,线性回归[2,22]、多任务线性回归[18]、SVM[4,22]、朴素贝叶斯[21]、贝叶斯网络[6,22]、神经网络[18,21]、决策树[6,21]、规则决策表[6]等常用的分类模型大都被使用或比较过。
2 分析方法
利用准私密社交网络文本数据进行抑郁用户检测的可行性分析,主要包含六个阶段: 数据采集与预处理,候选特征抽取与量化,训练样本选择,相关性分析,检测模型选择,检测效果评估与分析。本节仅介绍前五个阶段,最后一阶段在下一节介绍。
2.1 数据采集与预处理
2.1.1 数据采集
通过用户填写抑郁自评问卷得到用户抑郁状况,即标签;同时,收集用户的QQ和微信账号并获取数据使用授权,采集得到用户准私密社交网络数据。本研究邀请了江西财经大学6 378位大一新生于2016年10月参与研究,所有参与者完成抑郁测评问卷,同时签署数据保密协议,获取参与者QQ空间和微信朋友圈数据(问卷截止日期前一年内的数据)。为了保证数据质量,采取了一系列措施,包括: 采用CES-D[注]流行学研究中心抑郁量表的缩写.和BDI[注]贝克抑郁量表的缩写.双量表形式设计问卷,舍弃两个量表分值相差过大的用户;去除问卷得分为零分或满分的特殊用户以及问卷完成时间少于4min的用户;去除无法采集到QQ空间及微信朋友圈数据的用户。
CES-D和BDI是心理学上常用于测量抑郁症的抑郁量表,从多个维度综合考查了用户的抑郁状态,同时也是典型的4点李克特度量量表(每道题有四个选项,得分为0~3,对应抑郁程度由无到严重)。CES-D量表有20道题,得分区间在[0,60],分值分布区间为: “<=10分”为无抑郁,“11~20分”为可能有抑郁,“21~60分”为肯定有抑郁[25];BDI量表有21道题,得分区间在[0,63],“<=15分”为无抑郁,“16~35分”为轻度抑郁或中度抑郁,“36~63分”为重度抑郁[26]。合并两个量表的分值分布区间得到问卷分值分布区间[0,123],本文设置正常用户得分区间为[1,25],轻度抑郁用户得分区间为[26,55],重度抑郁用户得分区间为[56,123]。
经过以上筛选,获取了1 522个有QQ空间数据的有效用户,710个有微信朋友圈数据的有效用户,这些用户心理健康状况分布如表1所示。本文获取的准私密社交网络数据与文献[21]有较大的不同,数据不平衡问题更严重。在QQ空间用户中,抑郁自评量表反映出正常用户占60.5%,轻度抑郁用户占36.7%,重度抑郁用户占2.8%;而微信用户中,正常用户占36.8%,轻度抑郁用户占61.3%,重度抑郁用户占1.9%。导致这种分布差异的可能原因有两个: 一是不同抑郁状态的用户在QQ空间和微信朋友圈的使用上有差异;二是由于部分用户(特别是有重度抑郁倾向的用户)的QQ空间设置了密码无法抓取,导致样本分布的改变。
对微信朋友圈和QQ空间中用户发布的帖子数的统计显示,大部分用户发布帖子数量都在50条以下(截止填写自评量表前一年内)。
2.1.2 数据预处理
数据预处理主要包括去除和转换两个操作。去除内容包括: (1)转义字符,例如,以“ ”和“ ”的形式出现的空格和换行符;(2)偏僻字符,例如,“卐、※、ぷ”等;(3)英文文本,本研究只针对中文文本。
转换操作: (1)将表情符转换为
数据预处理还包括分词,本文选用的分词工具是NLPIR汉语分词系统[注]http://ictclas.nlpir.org/.,它针对微博等数据有优化、有新词识别能力,比较适合微博、微信、QQ空间上的文本。
2.2 候选特征抽取与量化
当前研究对特征的选取主要有两种方法: 一是借助心理学家对抑郁用户社交文本、网络行为、用户属性的统计和分析,归纳出抑郁用户的特征[6,10];二是通过统计用词或行为的频率,根据相关性分析,得出抑郁用户与正常用户在用词或行为上的不同[2]。本文使用了如下候选特征。
(1) 行为特征。行为特征是用户在社交网络上所表现出的行为,包括用户发布帖子、用户之间的互动等,本文考察的网络行为特征主要有: 转载帖子数、原创帖子数、点赞数、用户在凌晨0点到6点之间发布的帖子数、@符号数、帖子评论数等。
(2) 语言特征。本文考察的语言特征主要来自LIWC,包括表情符号、第一人称单复数等71个词类。LIWC中的每个词类被视为一个特征,特征值为样本中包含该类词的帖子数量。
(3) 文本内容特征: 利用用户在准私密社交网络上发布的文本来检测其是否有抑郁倾向的问题,可以视为文本分类的问题,因此用于文本分类的特征可以被借鉴。本文在实验中考察了以下特征:
BagofWords(BOW,或1-gram): 以用户发布的文本中全部的词为特征,以词的TFIDF值为权重。
主题(Topics): 对数据集进行主题分析,以用户发布的文本的主题分布为特征。本文利用Gensim工具[注]http://radimrehurek.com/gensim/.中的LDA模型进行主题分析。
词向量(Word2vect): 将用户发布的文本中的词转换为词向量,并将文本中全部词的词向量平均值作为特征。本文利用Gensim工具,在维基百科数据上进行训练,词向量的维度设置为400。
对行为特征和语言特征采用了三种量化方式,以探讨不同的量化方式对检测效果的影响。根据相关工作中的研究结果,抑郁用户和正常用户在社交网络上的行为和词汇的使用上是有区别的,这种区别可以通过行为或词汇的使用频次、频率的差异来度量。
频次(TF,TermFrequency)。对语言特征,统计某用户发布的全部帖子中包含第j类特征词的帖子总条数。例如,对于第一人称单数,统计包含第一人称单数的帖子总条数。对行为特征,统计用户帖子中包含或具有该行为特征的帖子总条数,例如,统计点赞数不为0(被点赞过)的帖子的总条数,如式(1)所示。
(1)
式(1)中,di是用户发布的第i条帖子,wj是第j类特征词,n是该用户发布的帖子总数量。
归一化频率(NTF,NormalizedTF): 把某用户第j类特征发生的频次转换为频率,即映射到[0,1]之间,如式(2)所示。
式(2)中,TFj是某用户发布的包含第j类特征的帖子数量(频次),n是该用户发布的贴子总数。
Z-Score标准化频率(ZTF,Z-ScorenormalizedTF): 对全部用户某一特征的归一化频率进行Z分值标准化,Z分值标准化如式(3)所示。
式(3)中,NTFj是式(2)所计算的归一化频率,μ和σ是NTFj在全部用户上的平均值和标准差。
2.3 训练样本选择
相对正常用户,社交网络上的抑郁用户数量非常少,因此采集的样本通常是极度不平衡的,如表1所示。大量的研究工作采用随机选择或利用高底分组的方法构建平衡训练样本。本文对是否需要构建以及如何构建平衡样本进行探讨。
在数据采集阶段,用户被分成了三组: 正常组,轻度抑郁组,重度抑郁组。实验阶段采用三种不同的样本选择方式来构建数据集。
(1) 非平衡高低分组样本(UHLSG,unbalance high/low scores grouping): 选取表1中所有的正常用户组和所有的重度抑郁用户组的数据,构成数据集。
(2) 平衡高低分组样本(BHLSG,balance high/low scores grouping): 由于重度抑郁用户数量与正常用户数量差异巨大,因此,为构建平衡样本,根据抑郁问卷得分由低到高(分值越高,抑郁越严重)选取表1中与重度抑郁用户组人数相同的正常用户,与重度抑郁用户组一起构成数据集。
(3)离散化高低分组样本(DHLSG,discretized high/low scores grouping): 参照文献[20]对用户抑郁问卷得分由低到高进行排序,通过式(4)对用户进行离散化:
其中,E(x)代表所有用户抑郁问卷自评得分的平均值,σ(x)代表所有用户问卷得分的标准差。将抑郁问卷分值的区间[1,123]划分为三段,分值介于[1,α]的用户为低分组用户,分值介于[β,123]的用户为高分组用户,数据集由低分组用户与高分组用户构成。式(4)的实质是找分值有显著差异的样本。
本文对QQ空间数据集(简称QD)和微信朋友圈数据集(简称WD)都进行了如上三种样本选择,得到的样本数量如表2所示。其中,低分组或正常组用户被贴上normal或“+”标签,高分组或严重抑郁组用户被贴上depressed或“-”标签。微信数据集因重度抑郁人数只有14人,样本太少,实验中放弃使用相应的平衡高低分组的样本采样方法。
2.4 相关性分析
由于文本内容特征中的主题特征Topics和词向量特征Word2Vect是基于数据集分析的结果,不依赖于某个具体的词或词类,因此,相关性分析只在行为特征和语言特征两类上开展。在QQ空间和微信朋友圈数据集上各得到78个语言和行为特征,但是并不是所有的特征都是与抑郁相关的。因此,本文通过分析各特征值与抑郁自评量表得分之间的相关性,选择相关性较高且显著的特征用于分类模型中。本文假设所有特征的取值服从正态分布,采用皮尔逊相关系数分析特征值与用户抑郁自评量表得分之间的相关性。
2.2节中介绍了对QQ空间数据集和微信朋友圈数据集上的候选特征的三种特征量化方法,本文在三种不同的候选特征量化方法上分别进行相关性分析和显著性分析。相关性分析结果显示,选择频次TF量化方法时,两个数据集上的各候选特征与抑郁自评量表得分的相关性都小于0.1,且相关性不显著(显著水平均远大于0.05)。因此,本文后续实验只考虑除频次TF量化方法以外的其他两种候选特征量化方法。本文选取显著水平小于0.05的特征,即该特征有95%以上的可能性与用户的抑郁自评量表得分是相关的。由于筛选后的特征主要为来自LIWC的语言特征,因此统称它们为LIWC特征。
表3是在QQ空间数据集QD_BHLSG上通过相关性分析筛选得到的特征,特征量化方法为Z-Score方法。包括微信朋友圈数据集在内的不同数据集、不同特征量化方法上的特征选择过程类似,选择结果不再赘述。
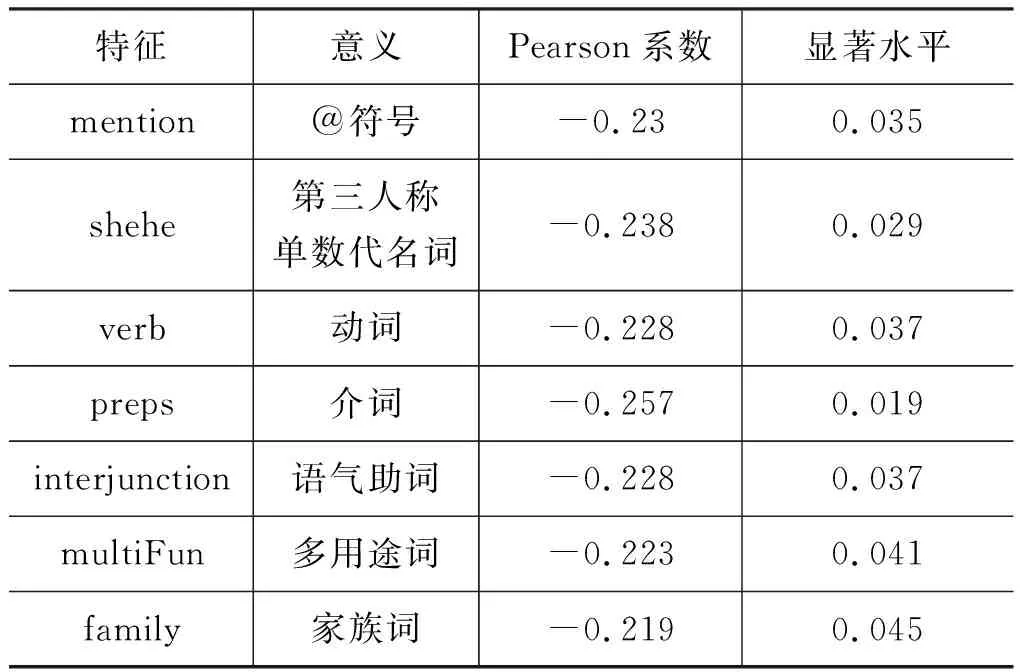
表3 QD_BHLSG数据集上特征选择结果(Z-Score量化)

续表
2.5 检测模型选择
在检测模型上,选择了相关工作中分类效果较好的模型,同时也对比了其他具有代表性的分类模型,包括Naïve Bayes、LibSVM、SMO、Voted Perceptron、SGD(Stochastic Gradient Descent),其中Naïve Bayes、LibSVM、SMO、Voted Perceptron模型来自Weka,SGD (Stochastic Gradient Descent)模型来自Python scikit-learn,模型参数基于网格搜索法进行设置。
3 实验分析
在QQ空间数据和微信朋友圈数据上均进行了同样的实验,限于篇幅,重点对QQ空间数据集上的实验结果进行分析,同时也对微信数据集上的一些有趣的结果进行说明。
选用的评价指标有精确率P、召回率R、F1值,评测得分为十折交叉验证的结果。实验结果中,P-、R-和F-分别表示对抑郁用户分类的精确率、召回率和F1值;P+、R+和F+分别表示对正常用户分类的精确率、召回率和F1值。P±、R±和F±表示相应指标在两类用户上的加权平均,如式(5)所示。
式(5)中,X表示P、R或F,Per+和Per-表示正常用户和抑郁用户的比例。
3.1 样本选择对抑郁用户检测的影响
Z-Score标准化是文献中通常采用的一种特征量化方法[21],也是在本文的实验中表现较好的特征量化方法,因此,在考察样本选择对抑郁用户检测的影响时,采用Z-Score标准化方法(ZTF)对特征进行量化,分类器用到的特征为LIWC特征。表4是不同的样本选择方法在分类器为LibSVM、VotedPerceptron、NaiveBayes、SMO和SGD上的表现。
表4中的实验结果显示: 总体上,非平衡高低分组样本QD_UHLSG效果最差,平衡高低分组样本QD_BHLSG比离散化高低分组样本QD_DHLSG效果要好。在非平衡高低分组样本QD_UHLSG上,P±、R±、F±均达到了0.9以上,然而P-、R-、F-却非常小,表明在QD_UHLSG数据集上构建的模型无法识别抑郁用户,将几乎全部的抑郁用户都识别成了正常用户,原因是QD_UHLSG是一个极度不均衡的数据集,正常用户921个,抑郁用户42个,而本文所选择的模型没有处理样本的不均衡问题。
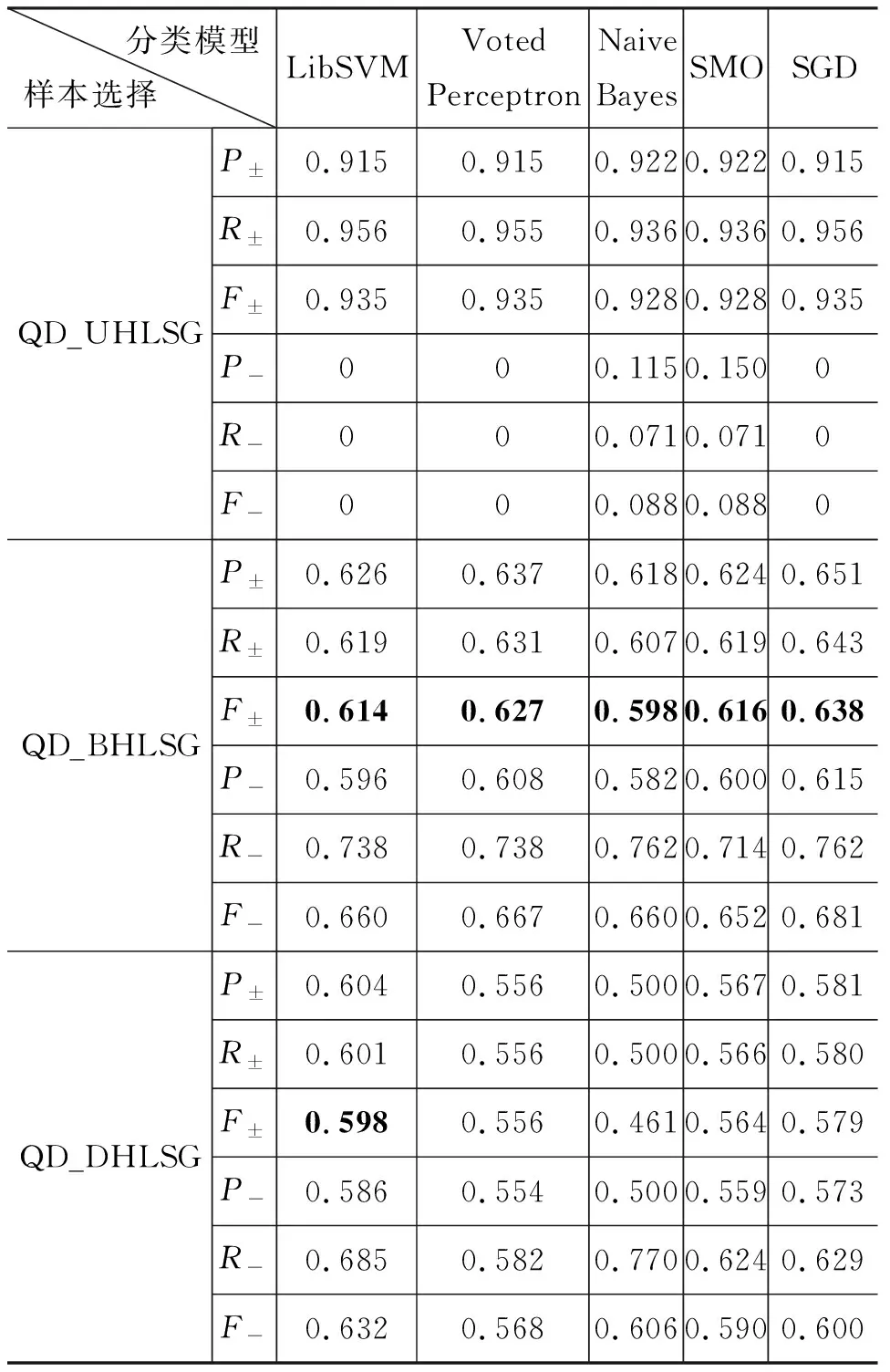
表4 样本选择对抑郁用户检测的影响(特征: LIWC;特征量化方法: ZTF)
在平衡高低分组数据集QD_BHLSG上,大部分模型的评测分值均大于其在离散化高低分组数据集QD_DHLSG上的分值(Naive Bayes分类器上的R-稍小),表明平衡高低分组样本选择效果比离散化高低分组样本选择效果要好。对比QD_BHLSG数据集和DQ_DHLSG数据集上的实验结果,如果仅从高低分组数据集的角度考虑,使用抑郁自评得分越极端的用户,所训练出的模型评测结果越优良。原因是,相对QD_DHLSG数据集(正负样本各213个),QD_BHLSG数据集上样本更少,正负样本各42个,分值分布更极端,用户更集中,抑郁特征更突出、更显著,而离散化高低分组样本的高分组中同时包含严重抑郁用户和轻度抑郁用户。
使用归一化的特征量化方法NTF时,得到的实验结论与ZTF上的结论是一致的。
3.2 特征量化方法对抑郁用户检测的影响
表5显示了在QD_BHLSG数据集上,选择不同的特征量化方法对抑郁用户检测的影响。可以看出,使用Z-Score标准化频率ZTF对特征进行量化比使用归一化频率NTF效果好。使用ZTF特征量化方法时,P±、R±、R-、F±和F-在所有分类模型上均大于或等于NTF方法,特别是LibSVM和VotedPerceptron两个分类模型在R-上表现明显。一个可能的原因是,由于QD_BHLSG数据集样本数量有限,该数据集上的特征值波动较大,且特征值的分布与其实际分布有较大差异,ZTF量化方法降低了这种波动,而NTF却没有。

表5 特征量化方法对抑郁用户检测的影响(特征: LIWC;数据集: QD_BHLSG)
3.3 不同分类模型在抑郁用户检测上的效果
表4和表5列出了五种分类模型在不同数据集和不同特征量化时的表现。总体上看,SGD分类器的性能表现更突出,其在QD_BHLSG数据集和ZTF特征量化时表现达到最佳,F±和F-的值分别为0.638和0.681。但表4和表5同时也显示,在不同的数据集上、采用不同的特征量化方法时,不同的分类模型的表现并不完全一致,例如,在QD_DHLSG数据集上使用ZTF特征量化时,LibSVM较其他模型要好(表4)。
3.4 文本内容特征对抑郁用户检测的影响
以上实验所使用的特征主要是语言学特征,即LIWC特征。本节讨论其他文本特征,包括BOW、Topics、Word2Vect。根据3.3节可知,在QQ空间数据集上,使用平衡高低分组的样本选择方法、Z-score标准化的特征量化方法,以及SGD分类模型,得到的检测效果较好,因此本节的实验延用这些方法。Z-score标准化还可以应对不同类型特征取值范围的差异给检测模型带来的挑战。
表6是在QD_BHLSG数据集上,SGD分类器在LIWC、BOW、Topics、Word2Vect上的检测效果。其中Topics特征上,主题数设置为25,主题数对检测效果的影响如图1所示。

图1 主题数对检测模型的影响
实验结果表明,相对于BOW和Word2Vect,LIWC特征的效果较好。原因有两个方面,一是LIWC词典本身是从心理学的角度对文本内容进行统计分析,二是2.4节中通过相关性分析保留了与抑郁自评结果相关性较高的词类,减少了潜在的噪声干扰。在LIWC、BOW和Word2Vect这三类特征中,词袋特征BOW表现最差,这与其在其他文本分类问题中的表现类似。
相对于LIWC、BOW和Word2Vect,主题特征Topics的表现更佳,其F值达到0.753,而对抑郁用户的检测精确率P-达到0.813。主题特征考虑了上下文之间的语义关联,从更深层次挖掘出了文本之间的语义关联性,取得较好的效果。然而图1也让我们也看到,主题个数的选择对于检测模型有较大的影响。
比较意外的是,当在主题特征Topics的基础上增加其他特征时,检测的效果反而下降。但从另一个角度看,在LIWC、BOW和Word2Vect这三类特征的基础上,增加主题特征Topics后,检测效果都有显著提高,这也证明了主题特征在抑郁用户检测中的重要作用。
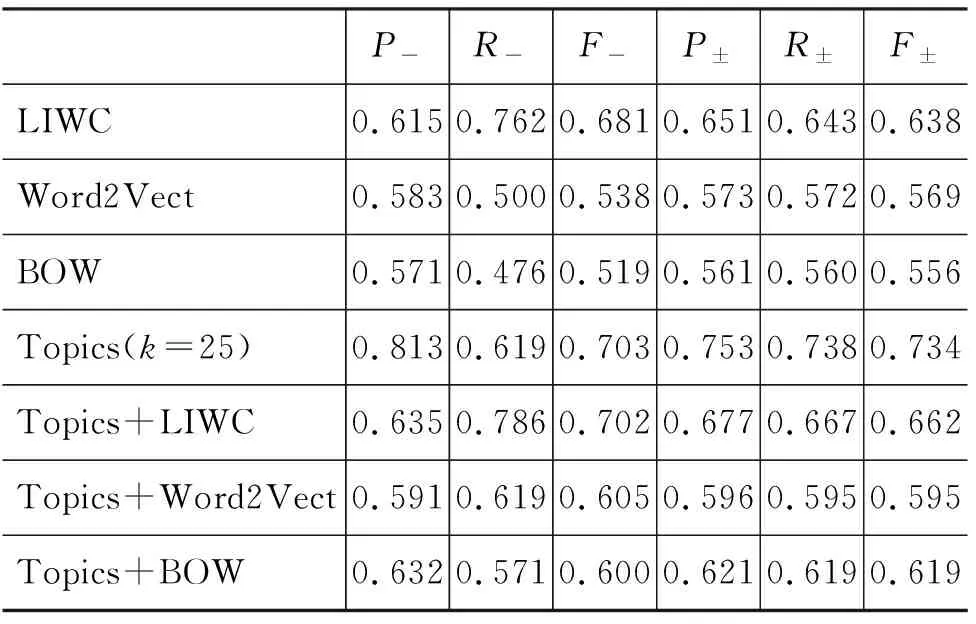
表6 SGD分类器在文本内容特征上的效果(数据集: QD_BHLSG;特征量化方法: ZTF)
3.5 与相关文献的对比分析
为进一步分析在准私密社交网络数据上进行抑郁用户检测的可行性,本节介绍相关文献中利用Twitter、微博、Blog、网关日志等数据检测抑郁用户的效果。
文献[3]以476个用户的Twitter数据作为数据集,其中抑郁用户171个,正常用户305个,定义了六种抑郁行为衡量方法,包括engagement、ego-network、emotion、linguistic style、depression language、demographics,通过相关性分析筛选得到与抑郁最相关的特征,选择SVM为检测模型,得到的最好结果中,精确率和召回率分别为0.742和0.629,显著低于本文的0.753和0.738。
文献[6]以中文新浪微博数据为数据源,在行为特征、交互特征和语言特征的基础上,引入微博的情感特征,并借助心理学家对数据的观察分析结果,利用Bayes、Trees、Rules等几类模型进行抑郁用户检测,在抑郁和正常用户各90个的数据集上,F值的最好效果为0.85。文献[7]是在文献[6]的基础上,考虑社会关系(链接)特征后,检测正确率达到0.95。进一步分析发现,文献[6]和文献[7]取得较好效果主要有以下两个原因。首先,在数据集的采集上,除采用用户自评量表外,还配合访谈的方式进一步确认用户的抑郁倾向,较本文只采用自评量表的方式,采集的数据集质量更高,抑郁用户和正常用户之间的划分更清晰,从而使得特征对数据的区分更强。例如,文献[6]中微博数量特征和情感符数量特征与抑郁自评分值的相关显著水平达0.002和0.003,远低于本文表3中的最低值0.018。其次,使用了情感、社会关系等更丰富的特征,并且通过心理学家辅助特征的筛选。
文献[21]以用户的网关日志为数据源,把728个用户分为449个抑郁用户和279个正常用户,组成训练集,通过聚类和离散傅里叶变换分别得到了聚类特征和频率特征,对抑郁用户检测的精确率和召回率最高分别为0.756和0.623,相应的F值为0.683,低于本文的F最高值0.703。
文献[22]针对包括49个抑郁用户和59个正常用户的日语博客数据,利用character n-grams、token n-grams、lemmas(词的原形)、词性等特征,通过特征筛选后,用Naïve Bayes、SVM、Logistic回归等模型分类,得到最优结果的准确率达0.95,而最优结果所采用的特征仅为来自动词和副词两种词性且词干化后的2007个词,分类模型为Naïve Bayes。文献[22]分类效果较好,也与其数据集构建有密切关系,其中抑郁用户和正常用户的识别主要依据用户在博客中是否用了“depression(抑郁”一词并透露了他们是抑郁患者。尽管与“depression”主题相关的博客都在后来的实验中被弃用,但与之相关的词汇仍然会给分类器提供较好的指示。该数据集的不足在于它没有包含那些没在博客中用“depression”一词透露其是抑郁患者的用户,而这部分用户相对更难识别,并且检测出那些潜在的、未被确诊的抑郁患者较确诊的抑郁患者有更重要的意义。
与上述文献相比,本文的优势在于: (1)对抑郁用户和非抑郁用户检测的平均F值达到0.734,而对抑郁用户的检测精确率P-达到0.813,优于文献[3]和文献[21];(2)不需要心理学家参与构建数据集和特征选择,仅使用社会网络用户的自评量表,对数据质量的要求较文献[6-7]和文献[22]更低;(3)数据含盖未确诊的潜在抑郁用户,较文献[22]更接近真实数据。
4 总结
从特征量化、训练样本选择、模型选择、文本内容特征四个角度考察了利用QQ空间这种准私密社交网络数据进行抑郁用户检测的可行性。对比了常用的特征量化方式: 频次、归一化频率、Z-Score标准化;对比了常用的训练样本选择方式: 平衡高低分组方法、非平衡高低分组方法、离散化高低分组方法;对比了LibSVM、Voted Perceptron、Naïve Bayes、SGD等分类模型。实验发现: Z-Score标准化比其他两种特征量化方法要好;平衡高低分组方法较其他样本选择方法要好;检测模型则比较依赖于数据集、样本选择、特征及其量化方法。
实验还分析了在平衡样本上,不同的文本内容特征对抑郁用户检测的影响。结果发现,主题特征对抑郁用户的检测效果最好,其他特征如语言特征LIWC、词袋BOW、词向量Word2Vect等,在加上主题特征后对检测效果有明显改善。最后还对比分析了相关文献中基于Twitter、微博、Blog、网关日志等数据检测抑郁用户的效果,明确了本文的优势,进一步说明了使用准私密社交网络数据检测抑郁用户是可行的。
从实验以及与相关工作的对比可以看出,数据集、特征和检测模型都是基于社会网络数据的抑郁用户检测的关键,不同文献在这几方面的差异也较大,可比性不强。另外,已有工作中各种高达0.8以上的准确率都是在平衡样本上得到的,与抑郁用户的实际分布差异较大,也意味着在实际应用中还会面临诸多挑战。最后,采用自评量表的方式获取的样本受用户填写量表时的心情影响较大,而确诊抑郁等心理问题需要更长期、更专业的观察,因此,样本采集需要结合心理医生的诊断才更为准确。
