基于融合策略的机器翻译自动评价方法
2018-10-19马青松张金超
马青松,张金超,刘 群
(1. 中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190; 2. 中国科学院大学,北京 100049; 3. 腾讯科技(北京)有限公司,北京 100080; 4. 都柏林城市大学,都柏林 爱尔兰)
0 引言
机器翻译自动评价旨在为机器翻译系统提供快速、可靠的质量评估。近些年来,随着机器翻译技术的发展,自动评价也受到越来越广泛的关注。机器翻译自动评价方法通常通过计算机器译文和参考译文的相似度来衡量机器译文质量,不同的自动评价方法从不同的角度计算二者之间的相似度。比如,基于词汇的自动评价方法中,BLEU[1]和NIST[2]统计机器译文和参考译文的共现N元组,Meteor[3]和GTM[4]捕捉机器译文和参考译文之间的词对齐信息,WER[5]、PER[6]和TER[7]计算从机器译文到参考译文的编辑距离。基于句法的自动评价方法主要比较机器译文和参考译文在浅层语法结构[8]、依存句法结构[9]或成分句法结构[10]上的相似度。
虽然各个评价方法都不尽完美,但它们都各自从不同的角度衡量机器译文和参考译文的相似度,反映机器译文在不同评价角度上的质量。那么,多角度的评价将会更全面地反映机器译文的真实质量。一个直接又有效的方法,就是利用各个评价方法的评分,把它们融合成一个新的评价方法。各评价方法的评分代表对机器译文在不同角度上的评价,融合后新的评价方法是对机器译文的多角度综合评价。
文献[11]提出寻找最优组合的方法,各个评价方法按照与人工评价的相关度降序排列,依次尝试加到最优集合里,如果能提高最优集合的性能则加入;否则不加入。这是一种无参数的组合方法。另外,也可以采用有参数的组合方法,最直观的就是线性组合,基本形式如式(1)所示。
(1)
其中,wi表示第i个评价方法xi的权重。
文献[11]中的无参数组合方式是一种贪心算法,可能会得到局部最优的组合。为了避免这种情况的发生,我们提出有参数的融合自动评价方法,采用机器学习算法进行训练,并进行多方面的实验探索,主要包括以下几个方面。
(1) 根据人工评价方法的不同,我们提出两种融合自动评价方法,分别是DPMFcomb和Blend,实验表明Blend性能更好;
(2) 在Blend上,对比使用支持向量机(SVM)[12]和全连接神经网络(FFNN)两种机器学习算法的性能,实验发现在当前数据集上,使用SVM效果更好。
(3) 进而在SVM基础上,探索融合不同的评价方法对Blend的影响,为Blend寻找在性能和效率上的平衡。
(4) 把Blend推广应用到其他语言对上,验证了它的稳定性及通用性。
后续组织结构如下: 第一节介绍模型方法,第二节介绍实验,第三节介绍Blend参加WMT17评测的结果,第四节进行总结。
1 基于融合策略的自动评价方法
我们首先介绍两种人工评价方法,相对排序(relative ranking,RR)和直接评估(direct assessment,DA);然后介绍分别使用RR 和DA指导训练的两种融合自动评价方法: DPMFcomb和Blend。
1.1 两种人工评价方法
在WMT评测任务的发展过程中,先后使用两种人工评价方法,分别是相对排序(RR)和直接评估(DA)。本节中我们将分别介绍这两种人工评价方法。
相对排序的人工评价方法,让评价者对同一个源端句子的五个不同机器译文进行1~5排名,从1到5表示机器译文质量依次下降,并且允许并列排名。表1是RR评价结果的一个示例,它表示对编号为103的句子,评价者给五个机器译文(MTsys1-5)的排名结果。
直接评估(DA)[13]给出对机器译文绝对的评分,在给定一个机器译文和一个相应的参考译文情况下,评价者通过衡量机器译文在多大程度上充分表达了参考译文的含义,拖动表征机器译文质量的取值范围为1~100的滑动条给出评分。每个评价者的评分都要通过严格的质量控制,并做归一化处理。最后,每个机器译文的评分Score是多个评价者评分(归一化后的评分)的平均值。表2表示评价者使用DA方法对不同编号句子的机器译文的评分。

表2 直接评估(DA)结果的示例
相对排序从2008年WMT自动评价任务开始时使用,一直到2016年,积累了多年的数据。相对排序能在一定程度上反映机器译文的质量,但它有两个明显的缺点。首先,相对排序只提供五个给定机器译文的相对排名,这只反映它们之间的相对质量高低,不能反映它们各自的整体质量。其次,相对排序存在人工评价者间的一致性较低的问题[14],这降低了相对排序的可靠性。与相对排序相比,直接评估能给出机器译文的绝对评分,且设计一系列措施保证其可靠性。因此在WMT17评测任务中,直接评估已经取代相对排序,成为唯一的人工评价方法。
1.2 DPMFcomb: 相对排序(RR)指导训练的融合自动评价方法
DPMFcomb使用RR人工评价数据,以各个评价方法的评分为特征,使用SVM进行训练,是一个与人工评价一致性很高的自动评价方法。DPMFcomb融合的评价方法,包含Asiya[15][注]http://asiya.lsi.upc.edu/工具中目标端为英语的默认评价方法,包括55个基于词汇、句法和语义的自动评价方法(如BLEU,NIST等),以及另外三个自动评价方法,分别是ENTF[16],REDp[17][注]DPMFcomb在WMT15评测中融入REDp,在WMT16评测中没有融入REDp。下文实验使用DPMFcomb在WMT16评测中的配置。和DPMF[18]。
若把RR给出的 1 到 5 的排名看作五个不同的类别,那么DPMFcomb的训练过程就可以看作是多分类问题,因此可以用SVM[12]进行训练。SVM是Vapnik等人于1995年提出的一种学习器,可以用于分类和回归分析。以线性分类问题为例,SVM可以从训练数据中学习找到一个最优超平面(图1的中间一条直线),实现线性分类。对于线性不可分问题,SVM通过引入核函数对当前空间进行非线性变换,在高维空间实现线性分类。

图1 SVM寻找最优超平面
具体的,DPMFcomb使用SVMrank,训练数据如表3所示,第一列是目标类别,即RR排名;第二列表示句子编号;从第三列开始,每列代表一个特征,即为融入的各个评价方法的评分。

表3 DPMFcomb的训练数据格式
在排序任务中,在测试阶段SVM生成的预测值可以转化为对测试集的排序;而在机器翻译评价任务中,自动评价方法通常给出机器译文的质量分数,所以此预测值不必再转化,可直接表示为DPMFcomb对机器译文的评分,如式(2)所示。
(2)
其中,w和b是模型参数,φ表示使用的核函数,xi表示融入的第i个评价方法的评分。
DPMFcomb参加了WMT15-16评测的自动评价任务,连续两年获得目标端为英语的语言对中与人工评价的平均一致性最高的成绩,其设置及结果可以参考文献[19-20]。
1.3 Blend: 直接评估(DA)指导训练的融合自动评价方法
我们提出DA指导训练的融合自动评价方法,命名为Blend,它可以利用任意的自动评价方法的优点,形成一个新的基于融合策略的自动评价方法[注]https://github.com/qingsongma/Blend。
Blend与DPMFcomb的基本思想一致,但二者在训练数据及训练方法上并不相同。Blend分别使用回归支持向量机(SVM regression)和全连接神经网络(FFNN)训练,找到使其性能最优的训练方式。
(1) 使用libsvm[21]中的SVM regression训练时,训练数据如表4所示。
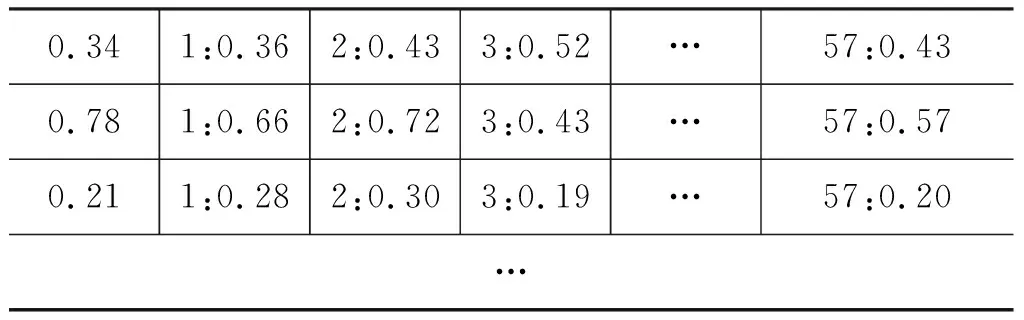
表4 Blend的训练数据格式
其中,第一列表示目标值,即为DA评分;之后每列代表一个特征,即融入的各个评价方法的评分。最终Blend评分如式(3)所示。
(3)
(2) FFNN是由输入层、隐含层(一层或多层)和输出层构成的神经网络模型,其隐含层和输出层的每一个神经元与相邻层的所有神经元连接(即全连接),如图2所示。

图2 全连接神经网络(FFNN)模型图
当Blend采用FFNN的训练时,输入层的每个输入表示各个评价方法的评分,输出层的输出为Blend对机器译文的评分。设输入层有M个输入节点,隐含层有N个节点,输出层是一个节点,则有:
其中,xi表示i个输入节点的输入值,即第i个评价方法的评分;wij表示第i个输入节点到第j个隐含层节点的权重;f(·)表示激励函数;wj表示第j个隐含层到输出层的权重;bj和b表示偏置值;Score是输出层的输出,代表Blend对机器译文的评分。
2 实验
我们进行了四组实验: (1)探索基于相对排序数据的DPMFcomb和基于直接评估数据的Blend在目标端为英语的语言对上的表现,对比两种模型的性能; (2)分别实现基于SVM和FFNN的Blend训练方法,对比二者性能; (3)实验了融合不同种类的自动评价方法,为Blend寻找在性能和效率上的平衡; (4)在其他语言对上验证Blend的有效性。模型评价指标是模型输出与标准人工评价分数的皮尔逊(Pearson)一致性系数。
2.1 实验设置
我们在WMT16评测任务中目标端为英语的各语言对上和英语—俄语语言对上测试。DA评价数据从WMT15-16评测任务中获得,数据量情况如表5所示。因为目前只有少数有限的DA评价数据,当我们测试WMT16中每一个目标端为英语的语言对(560句)时,使用WMT16的其他目标端为英语的语言对和WMT15的所有目标端为英语的语言对数据进行训练(共4 800句)。对于英语—俄语语言对,我们使用WMT15的英语—俄语数据(500句)训练,在WMT16的英语—俄语(560句)上测试。

表5 WMT15-16评测任务DA评价数据量
使用SVM regression训练时,训练数据和测试数据的特征都归一化到[-1,1]区间。我们使用epsilon-SVR,选择RBF核函数,epsilon设置为0.1。使用FFNN训练时,训练集与测试集保持与使用SVM regression时一致,并从训练集中随机抽取500句作为开发集,其他设置在下文中详细介绍。
2.2 Blend与DPMFcomb的对比实验
在WMT16评测中,DPMFcomb融合57个自动评价方法,使用SVMrank,从WMT12-WMT14评测任务的所有目标端为英语的语言对中,根据RR评价结果,抽取约445 000的训练数据。为了对比,Blend融合同样的57个自动评价方法,使用SVM regression,从WMT15-WMT16的目标端为英语的语言对上,抽取4 800句训练数据进行训练,训练得到的模型称为Blend.all。
表6和表7分别列出了系统级和句子级的Pearson一致性系数。表6显示Blend.all在WMT16的目标端为英语的语言对中,在系统级上与人工评价的平均一致性(0.951)达到最高,超过了当年评测中表现最好的两个自动评价方法,MPEDA(0.941)和BEER (0.920)。表7列出WMT16评测的目标端为英语的语言对中,Blend.all和另外两个表现最好的自动评价方法DPMFcomb和EMTRICS-F在句子级上的Pearson系数。DPMFcomb在WMT16评测的目标端为英语的语言对上表现最好,说明融合评价方法的有效性。表7显示Blend.all在所有目标端为英语的语言对的平均Pearson系数最高。值得一提的是,虽然Blend.all的训练集远远少于DPMFcomb的训练集,Blend.all的平均Pearson系数(0.641)却高于DPMFcomb(0.633)。
所以,以上结果说明在WMT16评测的目标端为英语的语言对中,DA指导训练的Blend,在性能上优于RR指导训练的DPMFcomb。这在一定程度上是由于DA数据比RR数据可靠: RR数据只反映机器译文间的相对质量,且存在评价者间一致性较低的问题;而DA数据给出机器译文的绝对评分,并且设计一系列措施保证其可靠性。因此,我们后面的实验在Blend上进行。

表6 在WMT16评测数据上各自动评价方法的10K系统级的Pearson系数

表7 在WMT16评测数据上各自动评价方法的句子级Pearson系数
2.3 Blend分别使用SVM regression和FFNN的对比实验
Blend设计分别使用SVM regression和FFNN训练的对比实验,从中选择一个更优的训练方式。首先,我们在捷克语—英语上尝试多组实验,寻找使得Blend在使用FFNN训练时的最优实验参数设置。实验结果如表8所示。
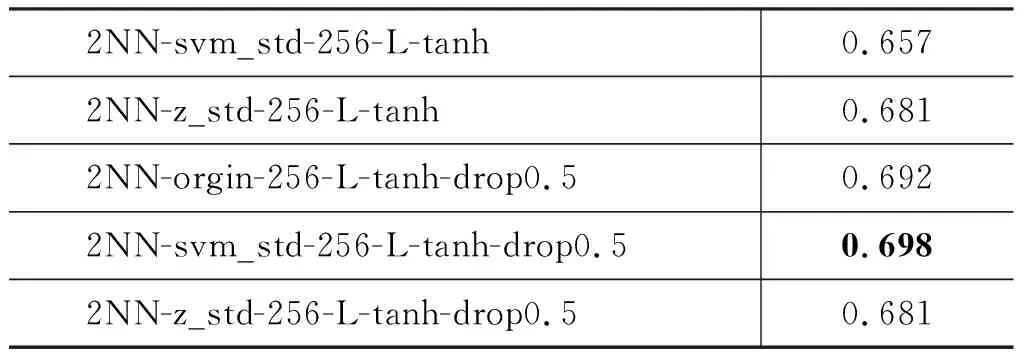
表8(a)探索使用不同的数据形式,即原始数据(各个评价方法的评分)、使用libsvm中的svm_scale(表8中记为svm_std)归一化数据,以及Z值数据。不同的数据形式,分别与一层或两层全连接神经网络组合,其他设置相同,具体如下: 采用SGD优化方法,学习率设为0.01,使用sigmoid激励函数,隐层维度设为57(与输入向量维度一致,即为融入的评价方法的个数)。由表8(a)可知,2NN-orgin,即使用原始数据及两层神经网络的实验设置,与DA人工评价的Pearson一致性系数最高。表8(b)首先在2NN-orgin基础上尝试不同的隐层维度,分别为64、128、256、512和1024。实验发现当隐层维度为256时,Pearson系数相对较高。之后在2NN-orgin-256上增加L1、L2正则项,其Pearson系数有所增加;继而将 sigmoid分别换为tanh和ReLU激活函数,发现使用tanh时效果有明显提升。表8(c)在表8(b)基础上,把三种数据形式与设置为0.5的dropout分别组合,发现当使用svm_scale与dropout组合设置时,Pearson系数再次显著提升。表8(d)尝试不同的dropout值,发现当其设置为0.1时效果最好;继而尝试更深的网络层数,发现效果稍微下降。
所以,我们采用2NN-svm_std-256-L-tanh-drop0.1的实验设置,记作Blend.NN,并采用此设置在其他到英语端的语言对上实验,其结果与使用SVM regression训练得到的模型Blend.all比较,结果如表7所示。由表7可知,在当前数据集上,Blend使用SVM的训练方式(Blend.all,0.641)略优于使用FFNN(0.639),由此可以说明SVM在小数据集上就有较好的表现,我们下文的实验均在SVM regression上进行。

表8 各模型在WMT16的捷克语—英语上的Pearson系数

(a)
(b)

(c)
(d)
2.4 Blend在性能和效率上的平衡
原则上,为获得与人工评价数据更高的一致性,Blend能够融入更多数量的自动评价方法。然而,是否有些评价方法在性能上没有对Blend起很大的作用,同时还降低了Blend的效率呢?为了探寻这点,我们把Asiya工具中适用于目标端为英语的语言对的默认自动评价方法分为三类,分别是基于词汇、基于句法和基于语义的评价方法。下文中Blend.lex只融合了默认的基于词汇的自动评价方法,Blend.syn和Blend.sem分别表示只融合了基于句法和基于语义的自动评价方法。Blend.lex包含25种自动评价方法,但实际只有九种自动评价方法[注]分别是BLEU,NIST,GTM,METEOR,ROUGE,Ol,WER,TER和PER。,因为其中有些自动评价方法只是一种自动评价方法的不同变种。Blend.syn和Blend.sem分别包含17种和13种自动评价方法,但实际各自对应三种不同的自动评价方法(详见文献[15])。
在WMT16评测的句子级实验结果如表9所示。Blend.all,包含Asiya所有默认的评价方法,在五个目标端为英语的语言对(共6种)上与人工评价的一致性,以及平均一致性达到最高。然而,值得注意的是: Blend.lex在句子级上与人工评价的平均一致性与Blend.all相比仅差0.009,而Blend.syn和Blend.sem的性能远低于Blend.all,甚至低于Blend.lex。基于句法和基于语义的自动评价方法通常比较复杂,耗时较长。经测试,基于词汇、句法和语义的评价方法在服务器上的平均用时为19.3ms/句、85.5ms/句和181.4ms/句[注]CPU: AMD Opteron(TM),8核,8线程;内存: 96GB。Blend.lex的性能与Blend.all相当,所以Blend可以只融合Asiya工具中基于词汇的评价方法,在达到高性能的同时提高效率。
我们又继续增加了四种其他的自动评价方法到Blend.lex中: CharacTer[22], 一种基于字符的自动评价方法;BEER[23],一种融入多角度特征的自动评价方法;DPMF和ENTF(在DPMFcomb的实验中证明了它们的有效性)。新增的四种自动评价方法分别从字符、句法等角度衡量机器译文质量,且都方便使用。表10说明Blend.lex+4(0.640)的性能优于Blend.lex(0.632),并且与表9中的Blend.all(0.641)非常接近,可以作为Blend在性能和效率上的一个很好的平衡。

表9 在WMT16评测数据上Blend融合不同类型的评价方法时的句子级Pearson系数

表10 在WMT16评测数据上Blend.lex加入4个不同类型的评价方法时的句子级Pearson系数
2.5 Blend在其他语言对上的实验
Blend可以适用于任何语言对,只要融入的评价方法支持这种语言对。因为目前除了目标端为英语的语言对外,只有英语—俄语的DA评价数据,所以我们在WMT16评测的英语—俄语语言对上实验来说明这一点,其句子级一致性结果如表11所示。
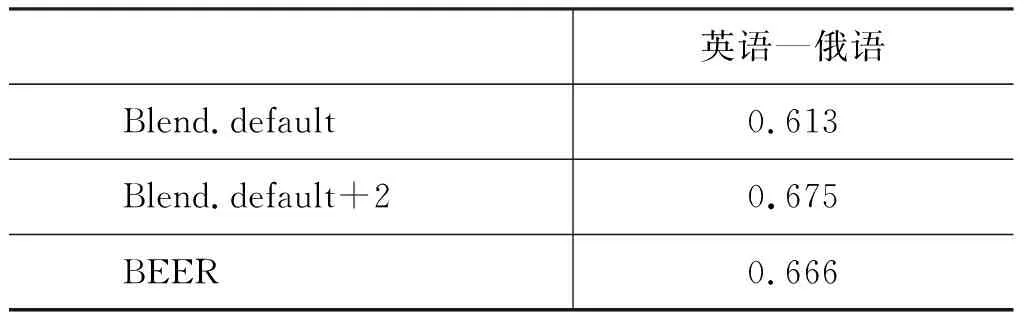
表11 在WMT16评测的英语—俄语语言对中各自动评价方法的句子级Pearson系数
Blend.default融合Asiya提供的适用于英语—俄语的默认自动评价方法,共20个,实质为九种[注]与Blend.lex一样的9种。。模型在500句训练集上训练得到。Blend.default+2在Blend.default基础上,只加入BEER和 CharacTer,在句子级的Pearson系数上取得很大提升,从0.613上升到0.675。BEER是在WMT16评测中英语—俄语的最好的自动评价方法(0.666),此实验结果显示,BEER可以在性能上给Blend带来很大提升,同时Blend可以进一步提升性能已经很好的自动评价方法,再一次说明融合策略的有效性。
3 Blend在WMT17评测上的结果
Blend参加了WMT17评测的自动评价任务。在目标端为英语的语言对中,提交Blend.lex+4,其训练数据包括WMT15和WMT16所有目标端为英语的语言对的数据,共5 360句。在句子级上,Blend在所有七种目标端为英语的语言对中,均获得了第一名的成绩;在系统级上,在六种目标端为英语的语言对(共七种)中取得了第一名的成绩;在10K系统级(10 000个翻译系统)上,在两种目标端为英语的语言对(共七种)中获得了第一名。
此外,Blend参加了英语—俄语语言对的自动评价任务,提交Blend.default+2,训练数据包括WMT15和WMT16两年英语—俄语的数据,共1 060句。Blend在英语—俄语语言对中,取得在句子级上第五(与最高的一致性系数相差0.058)、系统级第一、10K系统级上第二的成绩。WMT17评测结果的详细报告参见文献[24] ,Blend的系统报告参见文献[25]。文献[25]是本文提出的融合评价方法系列探索性工作的一部分,本文相比于文献[25],有更系统的探索、实验和分析。
4 总结
本文提出基于融合策略的自动评价方法,融合多个自动评价方法,以形成一个新的、与人工评价有更高一致性的自动评价方法。根据人工评价方法的不同,我们提出两种融合自动评价方法,分别是DPMFcomb和Blend,实验结果表明: 使用DA指导训练的Blend,即使在较少的训练数据上,其性能也优于DPMFcomb;在Blend上,对比使用SVM和FFNN两种机器学习算法的性能,发现在当前数据集上使用SVM效果略好(此结论仅限于当前数据集);我们进一步探索了在SVM基础上融合不同的评价方法对Blend的影响,为Blend寻找在性能和效率上的平衡;在多个语言对上进行了实验,证明了Blend的稳定性及通用性。该文提出的Blend方法参加了WMT17评测,取得了多项第一的优异成绩。
