数据挖掘中BP神经网络与决策树技术的应用研究
2018-10-18董明明蒋涛晏婉晨宋伟航谢斌
董明明 蒋涛 晏婉晨 宋伟航 谢斌

摘 要:大数据时代下,处理已知和预测未知数据的数据挖据技术在社会生活的众多方面得到了大量应用。因此,采用数据挖据中BP神经网络算法和决策树技术对毕业生就业偏好进行了预测研究。研究中首先对两种算法流程进行了介绍,其次应用两种算法分别对扬州大学2017年本科毕业生就业情况进行模拟预测研究,并对两种算法优缺点和结果进行了对比分析。通过模拟预测结果得知,两种算法预测数据均与实际吻合,决策树法更适用于数据数量较少的样本,而当数据量较大时,BP神经网络法得到的预测数据将更准确。
关键词:数据挖掘;BP神经网络;决策树;C4.5算法;机器学习
中图分类号:TP183;TP311.13 文献标志码:A 文章编号:1673-291X(2018)20-0186-05
引言
随着信息技术的高速发展,人们日渐依赖计算机技术去解决问题。随着人们对于收集、处理数据的的能力渐渐增强,现时的数据操作技术已不能满足人们的需求,因此数据挖掘就应运而生。目前,对数据挖掘比较公认的定义是W.JFrawley,G.Piatetsky-Shapiro等人提出的[1]。
数据挖掘自发展到现在为止已经产生了很多种方法[2],其中以BP神经网络和决策树算法为代表。神经网络算法是一种应用广泛的数据挖掘办法,因其自身自行处理、分布存储等特性非常适合处理非线性的以及那些以模糊、不完整的知识或数据为特征的问题。BP神经网络即反向传播网络(Back Propation Network)是1986年以Rumelhart为首的专家组提出的一种多层前馈网络。它由大量神经元构成,包括三层结构:输入层、隐含层和输出层[3]。神经网络经过学习训练,通过网络连接权值以及网络函数,建立起数学模型。理论证明含一个隐含层的BP神经网络能以任意精度逼近任何非线性映射关系[4,5]。决策树技术是机器学习中的一种归纳学习技术,它能够从一组毫无规律的的数据样本集合中推断出决策树[6]。历史上人们先后提出了ID3算法、C4.5算法[7]、分类与回归树CART算法[8]、快速可伸缩的分类方法(Supervised Learning In Quest,SLIQ)[9,10]、可伸缩的并行归纳决策树(Scalable PaRallelizable Introduction of decision tree,SPRINT)分类方法[11]、随机映射随机离散化连续型数据(Random Projection Random Discretization Ensembles)的算法[12]。其中,ID3算法和C4.5算法通过信息论的方法来进行分类,而CART算法、SLIQ算法以及SPRINT算法使用的是Gini指数的分类方法。本文将着重向读者介绍C4.5算法。
针对高校毕业生数量增加给高校带来的毕业生信息整理问题,本文采用BP神经网络算法和决策树C4.5算法来得到2017届扬州大学数学科学学院毕业生就业模型,并通过比较BP神经网络模型和C4.5算法得到较为精确的毕业生就业模型,利用模型指导大学生有目标、有选择性的学习。
一、数据挖掘BP神经网络技术
BP神经网络的建立过程包括两个过程:正向传输和反向传输。输入信号经过输入层、隐含层神经元的逐层处理到达输出层,如果输出信号不在预期的误差内,则转向反向传输阶段,通过修改各层神经元之间的权值使得误差减少,再次进入正向传输过程,再三反复直至误差在预期的范围之内。具体算法步骤如下[13,14]:
再轉至步骤4进行,直至每一层的均方差处于设定误差范围。
二、数据挖掘决策树技术
(一)决策树技术的定义和结构
决策树是一种用来预测模型的方法,树结构一般由根节点、中间结点、叶子结点组成,其中决策树中的根节点和中间结点存放数据的属性或者属性集合,叶子节点存放分类的结果。
(二)C4.5算法
在ID3的算法中,决策树分支的决定是由信息增益的大小决定的,因此利用ID3算法进行分类时,结果会倾向于分类结果多的属性。因此,J.R.Quinlan提出了C4.5算法,使用了信息增益率来对决策属性进行选择。
设S是一个包含n个数据样本的集合,该数据集合有l个属性D={d1,d2,…,dl},则C4.5的算法步骤为[15]:
其中,ti是子集中属性值为i的个数,i=1,2,...,b;nw是数据属性为j的个数,并由此推出信息增益率,其定义为Radio(dj)=Gain(dj)/Split(dj),至此选出信息增益最大的属性dj,则dj为这一层的结点。
(5)最后,根据该属性将子集再分类,重复步骤2、3、4,直至到达叶子结点即分类结果,由上而下递归下去,则可以得到完整的决策。
三、用人单位对毕业生的偏好研究
为了研究用人单位对毕业生的偏好,本文从2017届扬州大学数学科学院毕业生系统中随机抽取了140份数据样本,数据中包含学生的基本信息、课程成绩信息、综合成绩信息、获奖信息、就业信息;对于数据本文进行预处理,删去了与挖掘结果相关性弱的属性,最终留下性别、专业成绩、英语水平、计算机水平、政治面貌、获奖名称、就业单位名称。
(一)BP神经网络法在用人单位对毕业生的偏好中的研究
使用BP神经网络分析用人单位对毕业生偏好,首先需要将数据进行归一化:对于性别,男为1,女为0;对于获奖情况,有为1,无为0;对于政治面貌,党员为1,非党员为0;对于就业情况:KY、GN、GP、SP、NP分别为0.8、0.7、0.6、0.5、0.4、0.3;对于专业成绩、英语水平、计算机水平,则采用归一化公式:
接着建立BP网络结构。本文将140个样本数据的前100个数据作为学习样本,后40个作为训练样本,并设定该网络结构为三层,输入层有6个节点,输出层一个节点。在三层网络结构中。输入层神经元个数m、输出层神经元个数m和隐含层神经元个数L有以下近似关系:
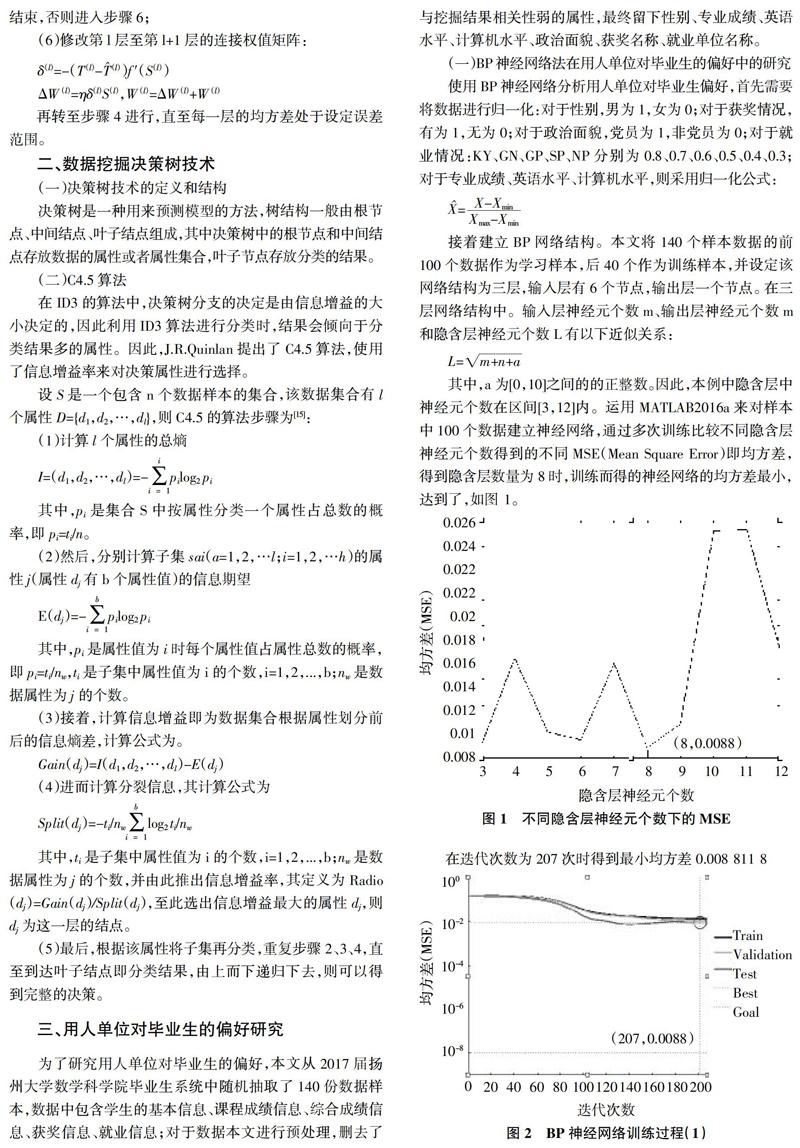
其中,a为[0,10]之间的的正整数。因此,本例中隐含层中神经元个数在区间[3,12]内。运用MATLAB2016a来对样本中100个数据建立神经网络,通过多次训练比较不同隐含层神经元个数得到的不同MSE(Mean Square Error)即均方差,得到隐含层数量为8时,训练而得的神经网络的均方差最小,达到了,如图 1。
在迭代次数为207次时得到最小均方差0.008 811 8
神经网络训练成功后,利用剩下的40个数据对神经网络数据进行预测值检验,从表1可以清楚地看到,预测所得的就业结果与实际结果较为相近,准确率为84.21%。实验结果表明,通过BP神经网络可以对毕业生信息中毕业生就业情况作出较为准确的预测。
(二)决策树法在用人单位对毕业生的偏好中的研究
接下来本文使用C4.5的方法建造就业信息决策树。首先需要将原毕业生信息表中”专业成绩”、”英语水平”、”计算机水平”进行进一步泛化:以70、85为区间划分点,将成绩泛化为优(大于或等于85)、良(大于70小于85)、差(小于70)。“就业单位等级”是类别标识属性,“英语水平”、“性别”、“专业成绩”、“获奖情况”、“计算机水平”、“政治面貌”是决策属性。数据挖掘C4.5决策树算法建造决策树的方法如下。
共有140个样本,GN、GP、SP、BP、DY、KY对应的样本数分别为d1=54,d2=4,d3=23,d4=4,d5=11,d6=44。首先算出总样本的期望信息,接着算出每个决策属性对应的信息增益率。这里以性别的信息增益率为例:性别分成“男”“女”两种,统计男生的就业情况,GN为13人、GP为2人、SP为8人、BP为3人、DY为6人、KY为15人;统计女生的就业情况,GN为41人、GP为2人、SP为15人、BP为1人、DY为5人、KY为29人。则性别是“男”的期望信息为I(d11,d21,d31,d41,d51,d61) = I(13,2,8,3,6,15)=2.299;性别是“女”的期望信息为 I(d12,d22,d32,d42,d52,d62)= I(41,2,15, 1,5,29) =1.885。
下面算出性别的信息期望是E(性别)=47/140×I(c11,c21,c31.c41,c51,c61)+93/140×I(c12,c22,c32,c42,c52,c62)=2.024,因而“性别”对应的信息增益为Gain(性别)=I(d1,d2,d3,d4 d5,d6)-E(性别)=0.040。经划分,性别分裂信息是Split(性别)=0.920,由此得到的性别信息增益率是Ratio(性别)=Gain(性别)/Split(性别)=0.043。
同理,可以得到其他属性对应的信息增益率,专业成绩为 0.198,政治面貌为0.057,英语水平为0.119,计算机水平为0.062,获奖情况为0.064。至此,由于专业成绩最高,为0.198,因此得到决策树的根节点是专业成绩。
同理,经过Matlab编程,可得决策树每一分枝的属性增益率,并根据得到的属性增益率得到决策树,如图4—7所示。
四、结论
运用BP神经网络和决策树算法分别对用人单位对毕业生偏好和于本科生借书偏好进行模拟预测,得到用人单位对毕业生偏好的的神经网络和决策树,通过它们的构成,可以得到如下结论。
1.BP神经网络和决策树算法对用人单位对毕业生的偏好和本科生结束偏好预测得到的结论都与实际情况吻合。
2.决策树适用于数据数量较少的样本,当数据数量比较多时,运用BP神经网络得到的结果更为清晰。
3.在处理多个属性的数据样本时,神经网络更具优势,结论也更加直观。
4.决策树可以保持属性的不变性,而神经网络需要将离散属性转换为数值属性。
参考文献:
[1] AGRAWAL R,PSAILA G,WIMMERS EL,et al.·Querying shapes of histories.·In Proc.of the VLDB Conference[M].1995.
[2] 邵峰晶,于忠清.数据挖掘原理与算法[M].北京:中国水利水电出版社.
[3] M OLLER MF.A Scaled Conjugate Gradiential Gorithm for Fast Supervised Learning[J].Neural Networks,1993,(6):525-533.
[4] 王小川,史峰,郁磊,等.MATLAB神经网络43个案例分析[M].北京:北京航天航空大学出版社,2013.
[5] KARDAN A A,SADEGH.H,GHIDARY.S.S,et al.Prediction of student course selection in online higher education institutes using neural network[J].Computer&Education;,2013,65;1-11.DOL;10.1016/j.compedu.2013.001.015.
[6] IQBALl M R A,RAHMAN S,NABILl S I,et al.Knowledge based decision tree construction with feature importance domain knowledge [C].International Conference on Electrical & Computer Engineering.IEEE,2013:659-622.
[7] QUINLAN J.R.Discovering rules by induction from large collections of examples[J].In Expert System in the Micro Electronic Age,1979:27-37.
[8] BREIMAN L,FRIEDMAN J,OLSHEN R A,et al.Classification and regression trees [M].Belmont Wadsworth,1984.
[9] METHA M,RISSANEN J,ARAWAL R.SLIQ:A fast scalable classifier for data mining [A].In EDBT96 Avignon,France [C],1996.
[10] CHANDRA B and PAUL P VALGHESE.Fuzzy SLIQ Decision Tree Algorithm.IEEE Trans on systems,2008,38(5):1294-1301.
[11] SHAFER J,RAWAL R,METHA M.SPRINT:A scalable parallel classifier for Data Mining [A].International Conference on Very Large Data Base [C].1996.
[12] AMIR AHMAD,GAVIN BROWM.Random Projection Random Discretization Ensembles—Ensembles of Linear Multivariate Decision Trees.IEEE Trans on Knowledge and Data Engineering,2014,(5):1225-1275.
[13] 胡月.BP算法并行化及在數据挖掘中的应用研究[D].重庆:重庆大学,2014.
[14] 梁栋,张凤琴,陈大武,等.一种基于决策树和遗传算法——BP神经网络的组合预测模型[J].中国科技论文2015,10(2):170-172.
[15] 瞿花斌.数据挖掘的决策树技术在高校毕业生管理中的应用[D].济南:山东大学,2014.
