智能车间系统下面向加工深度分析的聚类应用
2018-10-18毅2毕筱雪刘劲松
郭 安,于 东,胡 毅2,3,,毕筱雪,刘劲松,李 浩
(1.中国科学院大学,北京 100049;2.中国科学院 沈阳计算技术研究所高档数控国家工程研究中心,辽宁 沈阳 110171;3.沈阳高精数控智能技术股份有限公司,辽宁 沈阳 110171;4.中国科学院 沈阳计算技术研究所,辽宁 沈阳 110171)
1 问题的提出
近年来,随着工业4.0和中国制造2025计划的提出,制造业向信息化、智能化方向发展。工业4.0以信息—物理融合系统(Cyber-Physical Systems, CPS)为基础,其核心思想是通过高带宽的时间敏感网络(Time Sensitive Network, TSN)将具有高可靠性的传感器、执行器与服务器互联,形成传感器网络。应用程序通过服务器与传感器、执行器实时交互,实现以应用程序为代表的计算信息与以传感器所表征的外部环境的深度融合[1]。现阶段与智能制造研究课题相关的理论建模与形式化验证等工作多以大数据为驱动,以生产应用为导向,围绕产品完整生命周期展开。智能工厂(intelligent factory)、健康管理预警系统(Prognostics and Health Management, PHM)[2]、智能故障诊断系统(intelligent fault diagnosis system)是智能制造下的核心应用。姚锡凡等[3]通过对当前制造业信息化相关主流理念的分析、总结与提炼,分别提出智慧制造与智慧工厂的制造模式与参考模型,探讨了实现智能制造模式的途径与架构。
以上研究成果对智能车间工程应用有重要借鉴价值,但在智能车间的实践化过程中尚需考虑以下因素:
(1)“智能”概念的侧重点 “智能化”涵盖整个产品的生命周期:从原料进入工厂开始到产品最终送达客户,包括质量管控、生产调度、状态监控、生产统计/数据分析与工艺指导、产品配送等。某些特殊制造业甚至可以把智能化周期延伸到产品寿命的终结:美国航空工业引入“数字孪生”概念,将飞机零件实体与信息模型永久同步[5-6]。然而对某一特定制造行业,实现整个产品周期的“智能化”代价高昂且冗余,针对不同制造业特点,“智能”所处的环节应有所侧重。
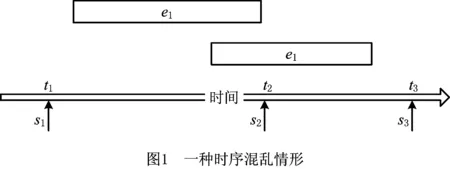
(2)理论模型与现实环境差异 智能应用所采用的模型精细,往往需要精确的时序数据作为其输入,对数据缺失、时序错误等问题抗性差,而由于系统本身的局限性或加工环境的干扰,数据不可避免会产生以上问题。图1所示为由于传感器采样频率不足而导致的数据时序混乱。
在图1中,e1、e2为系统中待测事件,矩形长度表示事件持续时间,左右边对应的时间点分别表示起止时间。s1、s2表示与e1、e2对应的传感器采样点,假设采样是瞬时的。s1于t1时刻采样,但并未探测到e1的发生;s2于t2时刻采样,探测到e2的发生。系统会根据传感器采样结果,错误地认为e2先于e1发生,这是有悖于事实的。
综上所述,智能车间的工程实践应以行业需求为导向,力求实现产品生命周期中的某些重要环节,算法与模型应考虑加工环境和平台的限制,以较低的代价达到合适的性能。本文以某离散制造业智能车间改造项目为背景,提出一种侧重于生产监控与数据分析的智能车间系统,重点阐述数据传输层、采集层的实现,结合系统特点及所处加工环境特点提出一种系统应用开发模式,依照该模式开发一种面向铣床加工深度的聚类算法应用,使用实验型精密加速度传感器在理想环境下采集原始数据,探究应用理论模型性能,对原始数据进行处理,探究应用性能随传感器参数的变化趋势,根据实验结果,在合理范围内调整平台参数,最后在本文提出的智能车间架构下验证了算法性能。
2 系统架构及应用开发模式
2.1 系统架构的提出
离散制造业生产工艺复杂,生产环节繁多,加工精度要求高,且生产设备参数直接影响产品质量。基于大数据的智能调度算法可通过生产过程中积累的历史数据训练决策网络,并结合实时数据快速响应产品排产需求,合理调整生产设备参数,以保证生产效率与产品质量。上述典型应用同时对数据实时性与海量性提出了要求。本文基于该行业特征与典型应用要求,提出一种面向实时可视化监控、任务调度、大数据分析的智能车间系统架构,其逻辑模型与物理拓扑分别如图2所示。
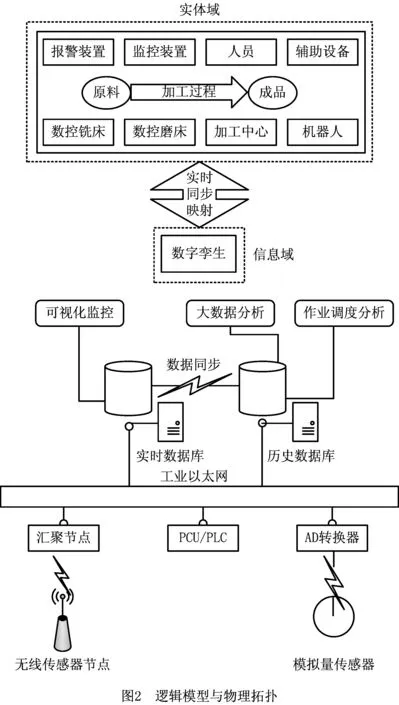
通过“数字孪生”模型实现车间实体域向信息域的完整映射。“数字孪生”是车间信息化模型的拓展,具有如下特点:
(1)实体域与信息域映射的完备性 不同于传统信息化模型,“数字孪生”模型强调车间每个实体及其状态、关系、事件向信息域的一一映射。同时,该模型不仅着眼实体域当前映射,还应记录历史映射状态。
(2)映射的高动态性、高实时性 实体域变化在一定时间限制内反馈到信息域。
(3)模型海量数据特征 由于信息域需记录实体域中大量实体、实体状态及实体关系的变动,会产生海量数据。
“数字孪生”模型与实体域信息交互接口位于智能车间感知层,在物理拓扑图中,包括与服务器连接的汇聚节点(sink node)、计算机单元(Personal Computer Unit, PCU)、可编程逻辑控制器(Programmable Loagic Controller, PLC)、模数转换器(Analog to Digital Converter, ADC)等硬件设备及相应的协议、优化算法等。
机床进给轴编程值、实际值、主轴转速、报警号、剩余量等内部运行参数可从PCU或PLC读取,采样周期范围为1 ms~1 s。机床特定位置加速度、声发射、电流数据需从现场安装的外部传感器读取。根据数据传输信道的不同,外部传感器又分为有线和无线传感器。无线传感器体积小安装方便,芯片选择灵活性强,应用较为广泛,适合于加速度、温湿度等集成电路(Integrated Circuits, IC)封装形式的芯片。霍尔电流传感器、电压传感器不宜做成无线传感节点,可用成品模块连接模数转换器后再接入服务器。
为满足不同应用对系统响应速度与容量的要求,设计实时与历史数据库。实时数据库存放产生于一定时间之内的数据,响应速度快,为实时监控等应用提供良好的支持;陈旧数据被转移至历史数据库,该数据库容量大,但响应速度相对较慢,可为数据分析提供支持。实时与历史数据库都为调度应用提供支持。
2.2 系统数据采集层与传输层的设计与实现
2.2.1 经OPC协议的数据采集方式
OPC基金会于20世纪90年代中期发布第一个用于工业控制的数据存取(Data Access, DA)规范,随后又发布了事件报警(Alarms and Events, AE)和历史数据存取(Historical Data Access, HDA)规范,迅速成为工业领域事实上的标准[7],称为OPC DA规范。随着技术的发展,OPC DA规范弊端日益凸显:平台不可移植性抑制开源操作系统的应用,通信依赖的关键协议分布式组件对象模型(Distributed Component Model, DCOM)报文复杂性使因特网的应用极为困难,DA、AE和HDA服务器各自的独立性弱化了服务器间的协作能力。针对上述缺陷,OPC基金会推出基于统一架构的OPC规范(OPC Unified Architecture, OPC UA)。目前,该规范在先进数控系统中应用广泛,图3所示分别为支持OPC UA的840D SL数控系统和支持OPC DA的PLC。

OPC UA规范定义服务器和客户端,840D SL的PCU中集成UA服务器,想要获得服务器长期、稳定的数据服务需要购买该数控系统中标注为“My Machine/OPC UA”选项包,否则UA服务器经过一定时间会报错并终止运行。OPC基金会及第三方组织提供开源或闭源的开发包,由开发包可编写客户端程序,实现与服务器数据交换、订阅等功能,也可通过修改基金会提供的客户端原型实现上述功能。
无法通过OPC协议采集的数据项可通过添加客制化传感器获得,下面介绍两种客制化传感器实现方法。
2.2.2 经汇聚节点的数据采集方法
加速度、温湿度传感器可采取无线传感节点与汇聚节点组合传输方案。汇聚节点通过以太网与服务器连接,传输从无线传感器节点汇总来的数据。团队研发的传感器节点与汇聚节点如图4所示。

该汇聚节点包含基于ARM构架的处理器,板载RT-THREAD操作系统。通过改进操作系统中邮箱数据共享算法,引入基于优先级策略的(Quality of Service, QoS)数据传输机制,确保当系统内存缓冲区溢出时,高优先级数据得到有效传输[8]。机床特定部件的加速度数值既可描述该部件运动状态,又可揭示其内部运作机理,常用于形成故障诊断和健康管理系统中模型特征参数。通过对加速度频域的积分、二次积分可以获得待测部件瞬时速率、位移曲线;通过小波包能量特征值提取和模糊聚类,可以进一步挖掘待测部件内部状态。加速度传感器因其广泛的应用,简易可靠的安装方式成为车间监控中一类核心传感器。
2.2.3 经模数转换器的数据采集方式
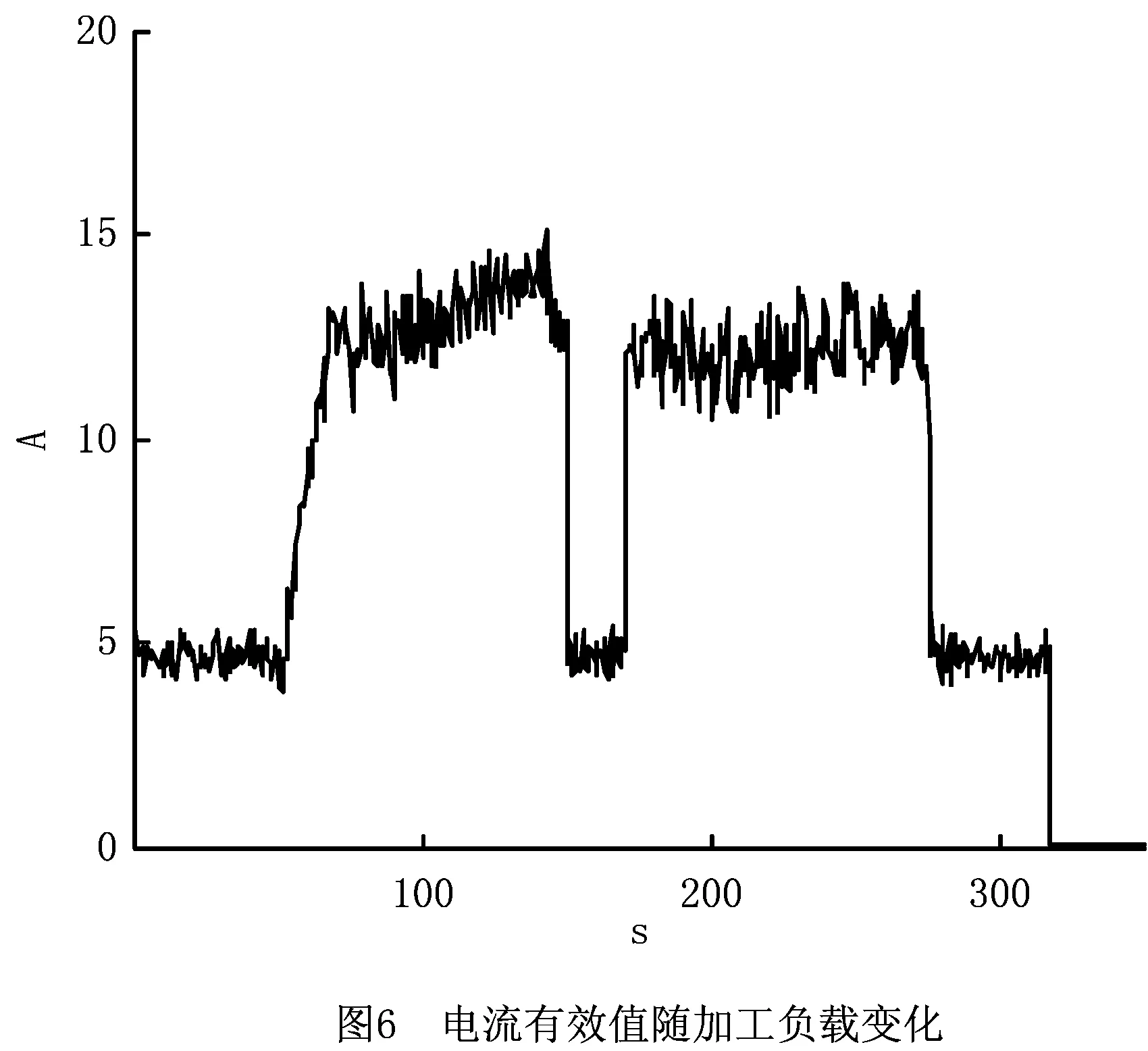
主轴及传动轴电流有效值对于刻画其负载变化有重要意义。霍尔电流传感器基于电磁效应间接测量电流有效值,该类传感器安装不需断开待测导线,易于车间大规模配置,其使用一般采取成品模块与模数转换器搭配的方式,如图5所示。

将霍尔电流传感器环绕三相交流电中的一根动力线,记录主轴从静止状态到空转状态、切削状态最后归于静止的电流变化,电流有效值随时间变化情况如图6所示。
2.3 系统应用开发模式
智能车间的应用开发需经历理论向实践的转化过程,其首要目标是以最小的系统代价换取合适的应用性能。
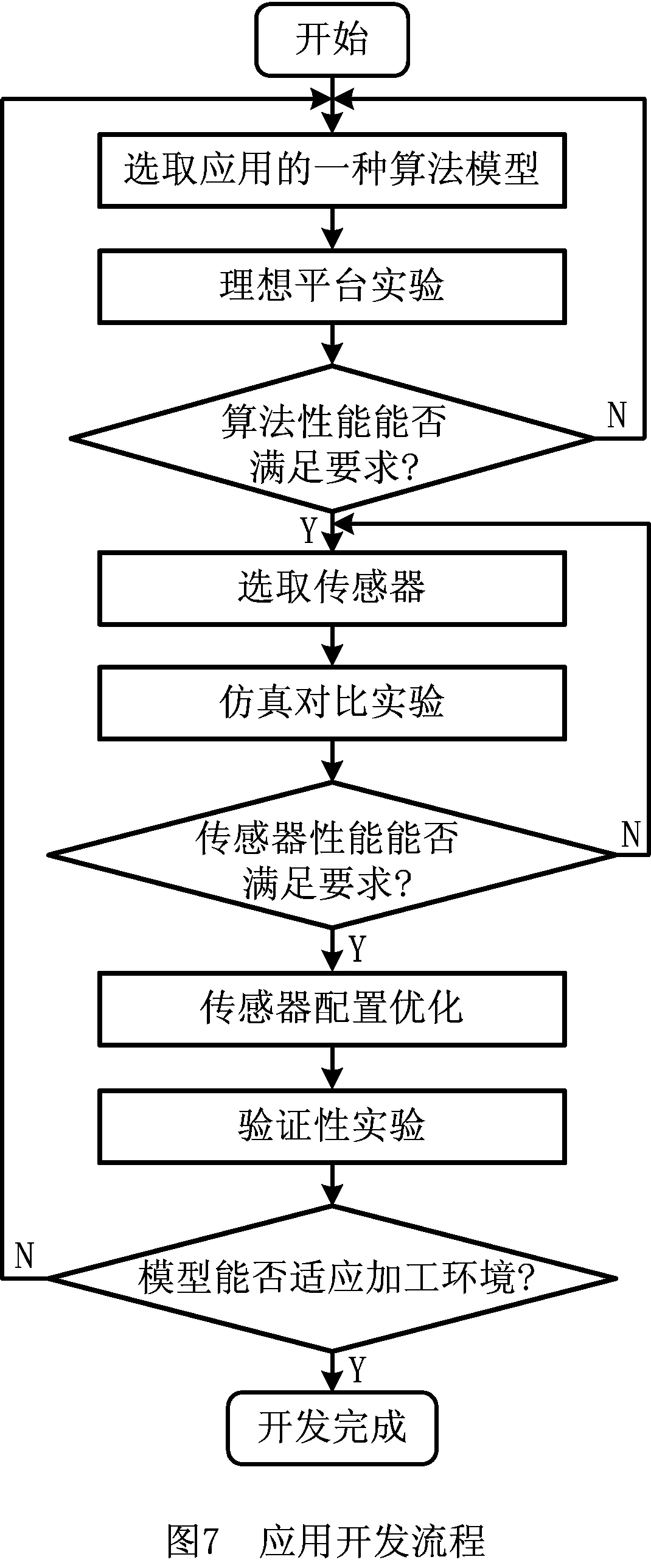
由于应用性能受理论模型本身、传感器性能、加工噪声等系统内因与外因共同作用,如何选择合适的模型及传感器节点以在特定的环境下达到性能要求是一个难题,而较高的传感器性能设定虽有利于提升应用性能,但会占用系统更多的带宽、存储等资源,例如,传感器采样频率越高,频谱分辨率就会越高,但单位时间内数据容量也会相应增大,传输及存储这些数据就要占用更多的系统资源。为解决以上问题,提出一种以理想平台实验、仿真对比实验、验证性实验为核心的ISVE(Ideal-platform, Simulation and Verification Experiments)-应用开发模式,简称ISVE模式,适用于具有如下特征的智能车间数据分析应用开发:
(1)应用有数学模型支撑,但缺乏针对特定问题的成熟解决方案。
(2)应用的实现依托系统中部署的传感器网络,应用性能除受理论模型自身影响外,还受传感器性能的影响,传感器关键性能参数可调。
(3)应用所依赖的传感器中有相应的精密传感器,精密传感器在关键性能指标上远超待部署的传感器。
(4)应用所处环境可能存在电磁辐射、高频噪声、振动等干扰源。
下面结合图7所示的开发流程,着重阐述3个核心实验。
(1)理想平台实验 该实验的主要目的是评估所选取的算法模型本身是否会成为应用性能瓶颈,并为流程中“仿真对比实验”步骤提供相应数据。为避免系统中其他部件及干扰源影响评估结果,该实验需使用精密加速度传感器在无干扰源的加工环境下通过专用数据传输信道获取并记录理论模型所需数据,之后将数据作为算法模型的输入以得到算法的输出,统计实验结果。
(2)仿真对比实验 该实验的目的是评估智能车间系统网络中的传感器节点性能可否满足应用要求,并为流程中“传感器配置优化”步骤提供支持。为节省传感器的实际部署成本,针对选定的传感器性能参数范围,运用数学手段处理“理想平台实验”步骤中记录的数据,模拟以不同参数配置的传感器采集到的数据,将数据按照参数配置分组并分别将同一组内的数据样本作为算法模型的输入,获取应用性能随传感器关键性能参数变化的趋势。若传感器性能可满足应用需求,根据退化趋势在“传感器配置优化”步骤中以合理的参数配置待部署的传感器,实现“以较低的系统代价换取合适的应用性能”。
(3)验证性实验 该实验的目的是评估系统及应用在真实环境下的抗噪性能。加工过程中的干扰不仅可作用于传感器数据采集阶段,降低信号信噪比,如车间设备运行过程中产生的高频噪音和设备启动时的振动可直接作用于声发射、加速度等传感器的数据采集阶段,还可作用于无线传感器的传输阶段,造成数据丢失,如设备产生的电磁干扰作用于无线传感器的传输过程,造成汇聚节点丢失连接。由于加工环境中的噪声具有偶发性和特异性,不宜通过仿真对比实验模拟,在本实验中,将选定的传感器部署在真实加工环境中,评估应用抗噪性能。
3 铣床加工深度聚类算法应用
模糊聚类算法可用于识别滚动轴承性能退化所处阶段:滚动轴承长时间运作会导致轴承内圈、滚珠、外圈损伤形变,进而对轴承本身产生不同频率的冲击,导致轴承不同频率的能量占总能量的比率改变。将处于运行状态的所有轴承样本加速度信号不同频段能量占总能量的比值作为模糊聚类算法输入,当算法收敛后,选取表征轴承退化特征的中心点,可通过每个样本与聚类中心的隶属度判定轴承所处的退化阶段[9]。本文借鉴上述研究成果,提出一种铣床加工深度聚类算法应用。
铣床矩形平面铣削普遍用于零件表面抛光、开槽等工艺,一段时间内不同加工深度的铣削平面数量可间接反映机床加工状态,为车间负载均衡调度提供支撑。假设在一个铣削过程中,没有更换刀具、工件的操作,主轴转速恒定,铣削平面为深度均一的矩形平面,本文提出的聚类算法可在刀具不同进给速度下按一定分辨率批量识别平面铣削深度。
铣刀切削零件时会受到来自零件的反向冲击带动机床整体振动,使铣刀附近加速度频域能量散射到切削频率对应的倍频处,倍频程与机床结构有关,但对于每类机床是固定的。实践表明,切削深度会影响一个完整切削过程中加速度倍频处能量占总体频段能量的比重,而进给速度对其影响很小,进给速度仅会影响切削临界状态刀具振动幅值,而临界状态所处时间较短,对整体能量分布影响微乎其微。因此可将所有样本在铣削过程中加速度频带能量占比分别作为模糊聚类的输入,获得相应加工深度的聚类中心和每个样本关于各聚类中心的隶属度,根据隶属度值实现样本加工深度的识别。该应用由原始数据采集、数据处理、铣削深度识别3部分组成。
(1)原始数据采集 将传感器固定于待测机床主轴静止区域,测量并记录每个矩形平面加工样本的加速度数值。
(2)数据处理 对每一个待测样本,其加速度原始数据经处理后形成模糊聚类的输入,进而求出聚类中心。
(3)铣削深度识别 根据先验知识确定每个聚类中心对应的加工深度,将待测样本归入与其欧氏距离最近的聚类中心,求出铣削深度。
数据处理流程如图8所示。
3.1 数据滤波与时域截取
因传感器采集过程中可能受到来自自身或加工环境的噪声影响,使信噪比降低。为提高信噪比,采用已有的自适应数字滤波器对采集到的原始数据进行滤波处理。
对铣刀而言,在一个典型的完整矩形平面铣削过程中其动作流程由空转、进入切削平面、切削、离开切削平面、空转5部分组成,其中进入切削平面、离开切削平面统称为临界状态。图9所示为切削深度0.1 mm,进给速度0.06 mm/齿时(本节其他样本的实验环境参数见表1)完整切削过程主轴加速度时域数值分布。

在图9中,A、B、C、D、E五段分别对应铣刀由启动空转到进入切削平面、切削、离开切削平面再到停止前空转这5个阶段。实验中切削平面长度一致,B、C、D三段长度随进给速度不同而成比例增减。A、E两段长度测量带有主观性,为配合算法要求,本文提出对A、E两段数据预处理,按一定比例截取A、E两段中靠近B、D的点,使对每个进给速度样本都有(A+E)/(B+C+D)=k,其中k为定值。
算法按以下步骤进行:
(1)求取序列总能量E和平均能量e。
(3)记录下集合G中序列下标的最大值Max与最小值Min,最大最小值的差记为p。剔除序列a(tk)中小于最小值Min,且相差d·p以上的元素或大于最大值Max,且相差d·p以上的元素,对序列a(tk)重新排序并按照升序指定下标,下标从整数0开始,间隔为1。新序列记为a′(tk)。
其中km与m、d的经验值标定为100,3.23,0.1。
3.2 特征提取
数据滤波、时域截取等步骤使原始数据平滑、正规化,而特征提取影响模糊聚类的输入。信号的特征提取分人工提取和计算机辅助获取两种,人工提取方式在信号的时频域统计数值基础上结合先验知识对信号特征进行标定,适用于产生机理已知的信号特征提取问题。近年来,随着深度学习算法在人工智能领域日趋成熟,作为人工提取法的扩展,利用深度学习方法提升特征精度、正交性的研究在表情识别[13]、语音识别[14]、故障诊断[15]等领域取得了一系列进展。Gosztolya等[13]提出运用深度学习提升对话冲突强度估计算法的准确率,该方法以语料库中每一帧的特征值作为深度神经网络的输入,以对话人数作为输出和特征值,再运用回归算法对特征值进行处理,得到对话冲突强度的预测值。时培明等[15]提出一种通过深度学习自适应提取故障频域特征的方法,以每个训练样本频谱信号为输入,以相应的故障分类编号为输出与特征值,将自动提取的频域特征与人工提取的时域特征结合,提高了故障诊断的准确率和可靠性。深度神经网络训练代价极大,对每个训练好的网络,其输入输出向量维度固定。在本文的研究案例中,对原始信号的处理会影响频谱分辨率,进而影响深度神经网络的潜在输入向量维度,因此深度学习特征提取方法并不适于本研究案例。本文采用人工提取方法,从数据时频域特征入手分析,将归一化的小波包能量作为模糊聚类的输入向量。图10中子图至上而下分别对应加工深度0.1 mm,进给速度0.06 mm/齿;加工深度0.1 mm,进给速度0.09 mm/齿;加工深度0.3 mm,进给速度0.09 mm/齿3种加工过程的加速度时域特征。
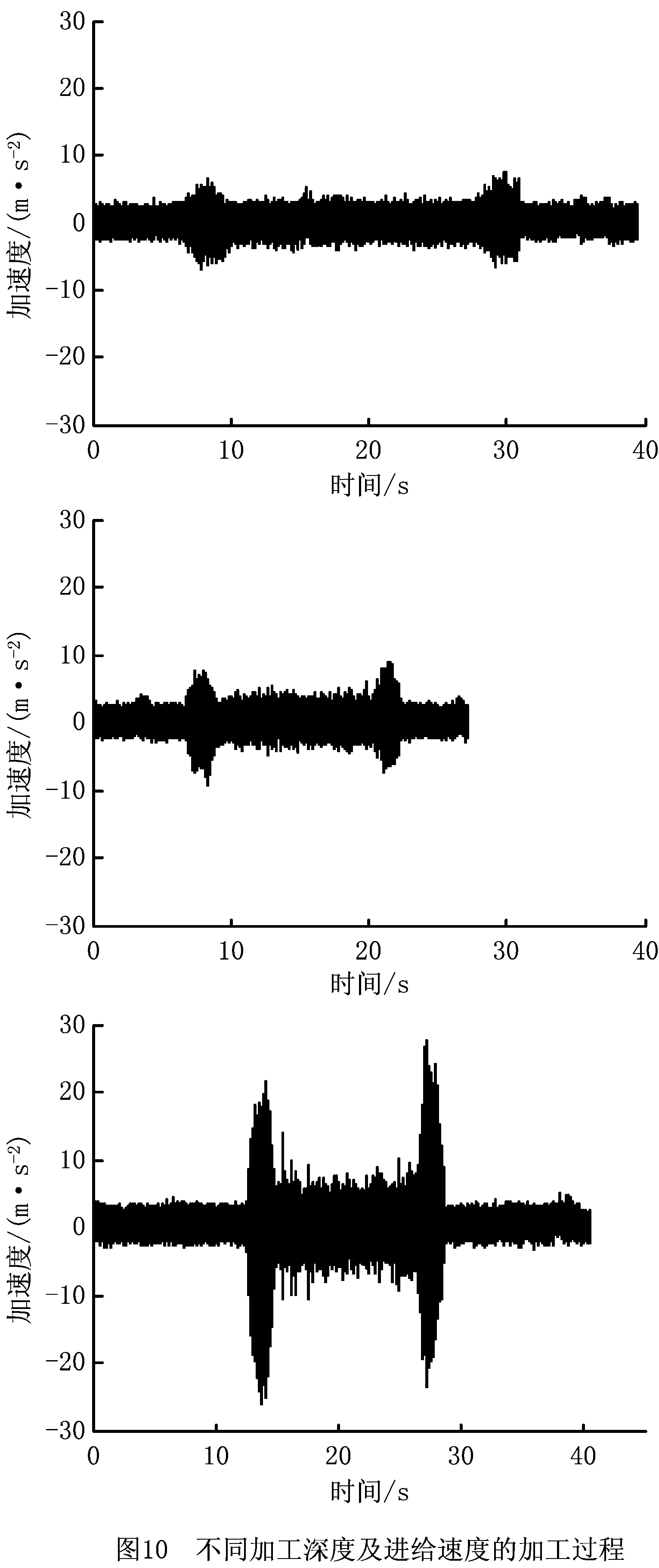
由图10可知:由于主轴转速恒定,空转阶段(A、E两段)3张图幅值基本相同,当加工深度一定时,随着进给速度的增加,临界段(B、D段)幅值明显增大,C段略有增大。当进给速度一定时,随着切削深度增大,B、C、D段增幅明显。
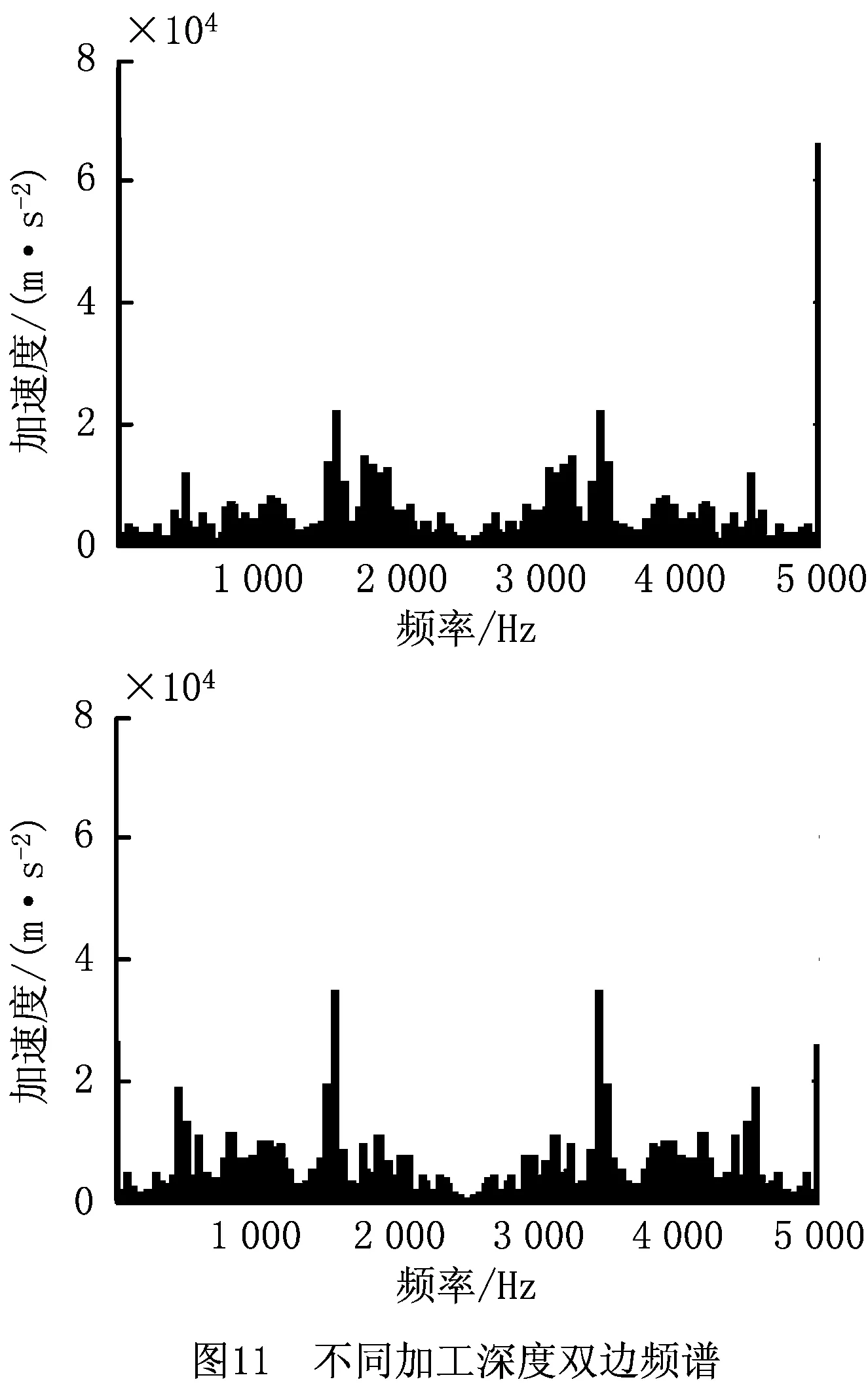
图11分别是加工深度0.3 mm,进给速度0.12 mm/齿与加工深度0.5 mm,进给速度0.12 mm/齿的加速度双边频谱图。传感器采样频率5 000 Hz,由采样定理可知,频谱出现混叠的频率为2 500 Hz。随着加工深度的增大,高频分量所占比重增加,且在500 Hz与1 500 Hz附近出现峰值。运用现有小波包能量谱法提取不同频带能量特征。
小波包分解提供了一种信号时频域多尺度分析(Multiple Resolution Analysis, MRA)的方法。信号经小波包分解后,得到重构信号;求出各个重构信号的能量,再除以总能量,获得各个重构信号能量占总能量的比值,称为归一化小波包能量谱法。小波包能量谱在工业探伤、滚动轴承故障诊断等方面应用广泛。以基于离散小波变换(Discrete Wavelet Transform, DWT)的算法对超大数据集聚类效果评估为起点[16],学术界兴起DWT算法对于大数据的处理策略研究。一方面,DWT算法可通过FPGA(field programmable gate array)等嵌入式芯片实现[17],另一方面DWT算法可通过GPU(graphic processing unit)或分布式计算单元并行实现[19]。以上研究从实时性与并行性两方面保证了DWT算法对于海量数据的处理能力,引入小波包能量谱特征提取法可适应智能车间海量数据特征。以三层小波包分解后重构信号能量谱为例,由低频到高频,8个子频带小波包重构解系数可表示为:
(X0,X1,X2,X3,X4,X5,X6,X7)
重构系数对应的重构信号可表示为:
(S0,S1,S2,S3,S4,S5,S6,S7)
设重构信号Si(i=0,1,…,7)对应的频段能量分别为Ei(i=0,1,…,7),则有
(1)
式中xik(i=0,1,…,7)对应重构信号Si(i=0,1,…,7)离散点幅值,Ni为xi对应数据长度。频带总能量
(2)
最终获得归一化后的特征向量为
[E0/E,E1/E,…,E7/E]。
(3)
3.3 模糊聚类
本文采用已有算法模糊聚类中的隶属度数值作为样本加工深度特征评价指标。模糊k聚类是k-means聚类方法的改进,通过引入隶属度矩阵,实现样本亲疏度建模。理论分析表明,模糊聚类适合呈超球面分布的聚类样本。其原理如下:
设任意待聚类样本对应的高维特征向量为si,则∀i∈{1,2,…,n}均有si∈S且有si∈Rm。即S是容量为n的特征向量集合且si是m维实空间的一个元素。构造隶属度矩阵An×l及聚类中心集合{c1,c2,…,cl}(2≤l≤n,l∈)对集合中任意的元素ci(1≤i≤l,i∈)都有ci∈Rm。隶属度矩阵An×l中的元素aij满足关系:
(4)
算法的目标是在满足式(4)所示条件下通过最小化代价函数式(5)获得相应隶属度矩阵与聚类中心:
m≥1。
(5)
式中:m是平滑参数,其值越大模糊程度越高;矩阵元素aij表征样本si对于聚类中心cj的隶属度。构造欧式距离矩阵Dn×l,其元素dxy(1≤x≤n,1≤y≤l)表征样本sx到聚类中心cy的欧式距离,即
dxy=‖sx-cy‖2,1≤x≤n,1≤y≤l。
(6)
代价函数经迭代运算后更新聚类中心向量与隶属度矩阵、欧式距离矩阵。其中aij可按式(7)更新:
aij=
(7)
4 实验结果与分析
遵循本文提出的ISVE模式开发铣床加工深度聚类算法应用,其中应用的理论模型已在第2章提出,候选传感器为团队研制的集成ADXL345芯片的加速度传感节点,如图4所示。其对应的精密传感器为PCBTM356A16的三轴加速度传感器。下面重点介绍3个核心实验的内容及性能分析。
4.1 理想平台实验
本实验环境参数如表1所示,物理连接图如图12所示。两个加速度传感器通过磁力底座吸附于主轴上方的静止区域,并通过数据线与实验台上的模数转换器连接。笔记本电脑通过网口与模数转换器连接,记录加工数据。为减小电磁及振动干扰,关闭实验机床外的其他机械设备。
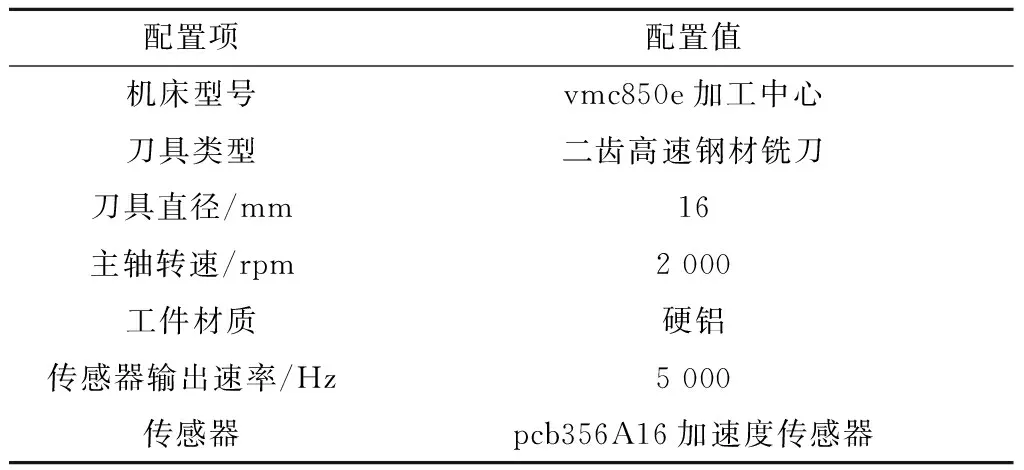
表1 实验环境参数

加工深度设计0.1 mm、0.3 mm、0.5 mm三个不同分组,每组分别由进给速度0.03 mm/齿、0.06 mm/齿、0.09 mm/齿、0.12 mm/齿、0.15 mm/齿5类,每类重复5次,共计75组实验样本。选取“db3”作为母小波,采用Mallat塔式分解算法对样本进行三层小波包分解,得到8个重构信号,模糊聚类中平滑参数取值为1。样本分类效果以其对于自身所属分组类别的隶属度表征。隶属度越接近1,分类效果越好。样本分组以加工深度升序排列,组内类按照进给速度升序排列。图13为验证性实验结果。
在有3个聚类中心的聚类问题中,样本对自身所属类的隶属度大于0.5即可认为聚类结果正确。图13中所有样本对于自身聚类中心的隶属度均大于0.7,聚类正确率为100%,因此判定算法模型本身不构成应用的性能瓶颈,应用开发可推进到下一步。
4.2 仿真对比实验
表2所示为ISVE模式中候选工业传感器及其对应的精密传感器的关键参数性能差异。

表2 传感器参数对比
ADXL345加速度传感器采用阶梯可变的输出速率和量程范围,与PCBTM356A16相比在数据输出速率、传感器量程等性能参数方面存在劣势。该实验通过对理想平台实验中采集的原始数据隔点取样、限制最大值,分别模拟传感器输出速率、量程等性能指标退化引起的应用性能退化,以此评估ADXL345传感器性能是否适合该应用。较高的输出速率和较大的量程会增加汇聚节点的通信代价和历史数据库存储负担,为减小系统负担,本实验同样给出传感器参数配置的参考值,为后续ISVE模式传感器配置优化提供支持。实验环境与理想平台实验相同,实验设置保持一致,但每类不进行重复实验。
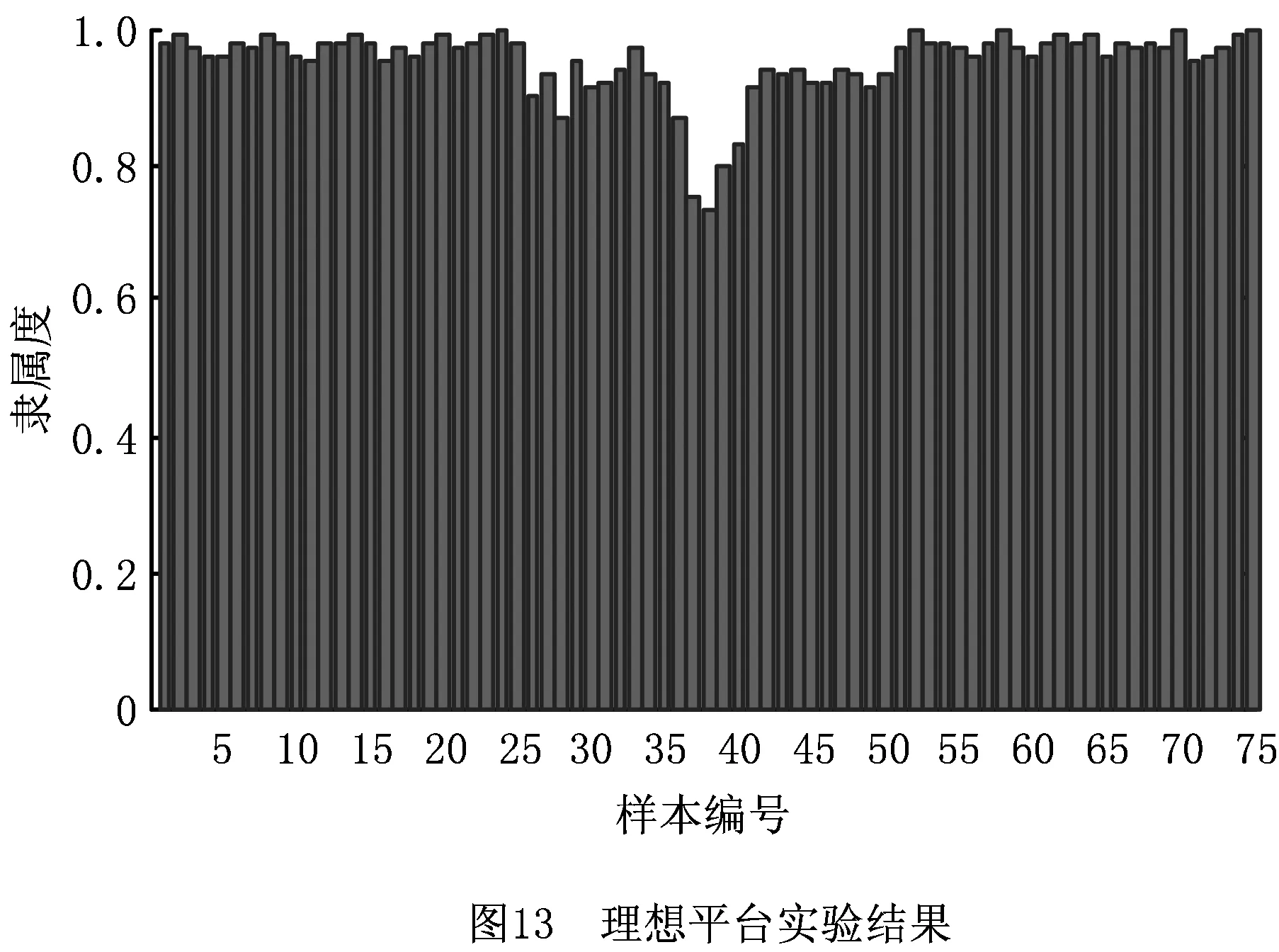
对原始数据分别采取隔2、3、4点取样的方法模拟传感器相应输出速率2 500 Hz、1 667 Hz、1 250 Hz时的加速度曲线,由采样定律可知,相应频谱的混叠频率分别为1 250 Hz、833 Hz、625 Hz。将采样后的数据作为图7数据处理流程中的原始数据并执行聚类流程,聚类结果如图14所示。
从图14可看出,传感器输出速率被模拟成2 500 Hz时,除7、8号样本接近临界状态外,剩余样本的加工深度均可被区分出来,而该输出速率小于ADXL345传感器节点的最大输出速率,故传感器数据输出速率不会成为应用性能的瓶颈。
进一步分析表明,随着输出速率的降低,样本对于自身加工深度的隶属度数值退化严重,当输出速率为1 667 Hz、1 250 Hz时,算法已无法准确区分样本加工深度。结合图11不同加工深度下频谱能量分布统计图,样本的特征频率集中在500 Hz~1 500 Hz之间,为使特征频谱不混叠,所选传感器输出速率至少应为3 000 Hz。
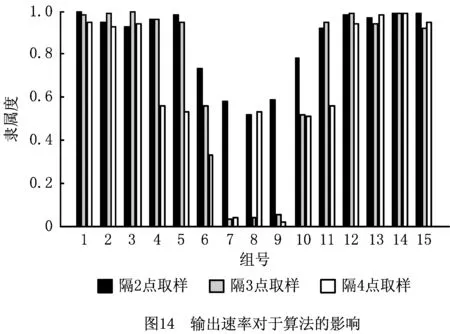
为探究传感器量程对算法性能的影响,结合ADXL345芯片有目的地对原始数据最大值作限制:原始数据中绝对值小于最大值的数值不变,大于最大值的按最大值计,保存符号。原始数据中最大加速度为62.8 m/s2,处于ADXL345芯片的±8 g量程之内,故传感器量程也不会成为应用性能的瓶颈。将原始数据最大值分别限制在39.2 m/s2和19.6 m/s2内,限制后的数据作为图7数据处理流程中的原始数据并执行聚类流程,聚类结果如图15所示。
结果显示,将原始数据范围限制在39.2 m/s2以内时,聚类准确率不变;当限制在19.6 m/s2以内时,会影响进给速度较快的样本聚类准确度。故传感器量程范围至少为±4g。
4.3 验证性实验
本实验选取团队研发的智能车间系统作为实验平台,其架构如图2所示。传感器节点与汇聚节点如图4所示,参照仿真对比实验结论,芯片输出频率设置为3 200 Hz,量程设置为±4 g,开启QoS并设定加速度节点优先级为最高。实验分组及组内样本设置与理想平台实验一致,传感器节点用胶带黏合于主轴上方静止区域,实验数据存放于系统历史数据库中,为模拟真实加工环境,实验机床周边其他设备处于全速运转状态。实验物理连接图如图16所示。

汇聚节点通过CAT5E屏蔽双绞线连接MOXA网关,进而接入MOXA交换机中。实时数据库安装于ThinkServer TD350服务器中,历史数据库安装于x86兼容机,两者通过以太网线接入交换机,实时数据库接收并处理由汇聚节点传来的实时加速度信号,并在一段时间内同步入历史数据库中。将历史数据库中的数据作为图7数据处理流程中的原始数据并执行聚类流程,聚类结果如图17所示。
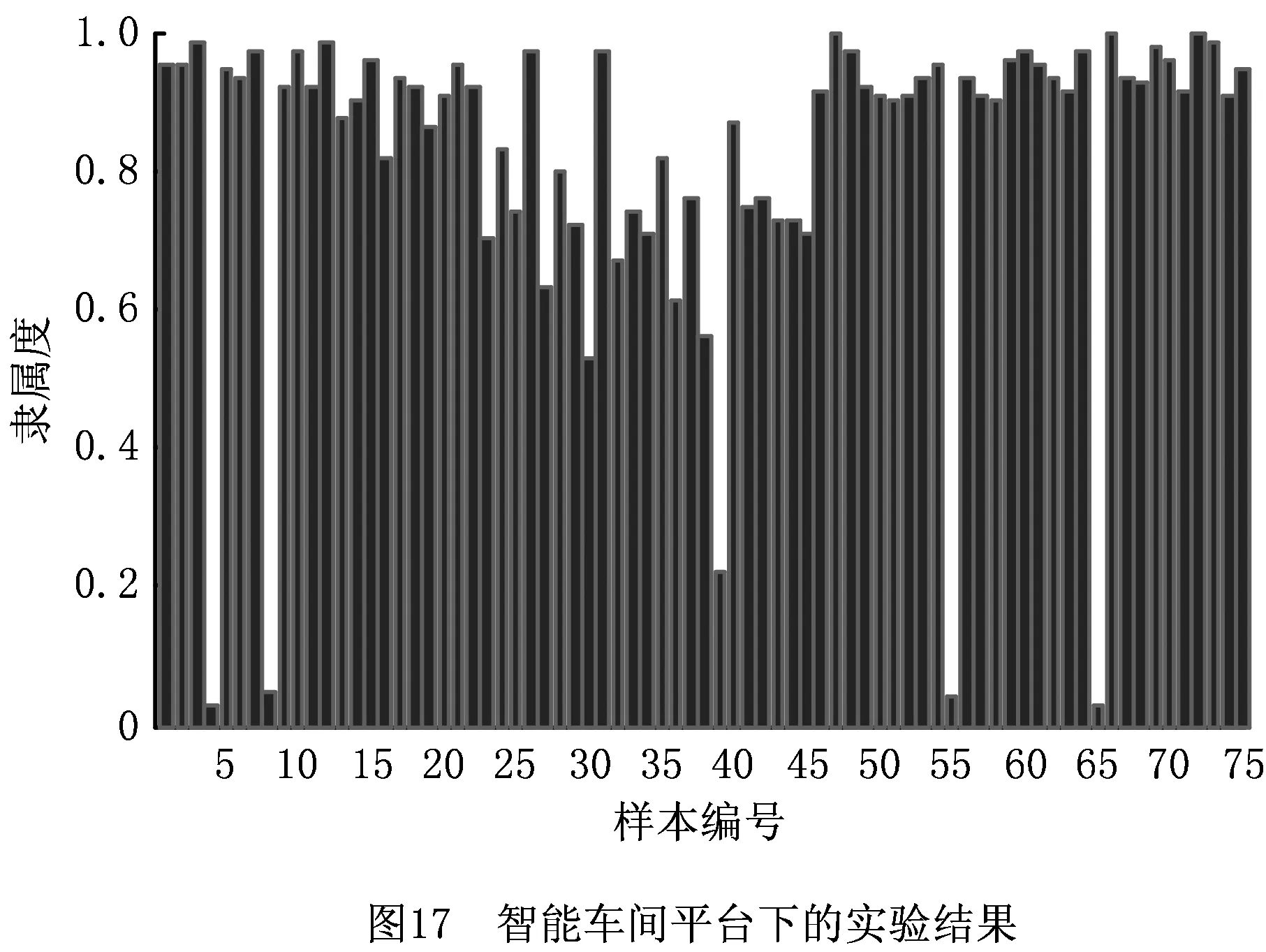
图17中4、8、39、55、65号样本与理想实验出入较大,推测可能是传感器受机械振动或电磁辐射干扰所致。总体来讲,依照ISVE模式开发的聚类算法应用对于铣削深度识别的正确率在90%以上,开发流程结束。
5 结束语
本文以生产需求为导向提出一种面向离散制造业的智能车间架构,并着重阐述了数据传输层设计与实现。提出了一种智能车间应用开发模式——ISVE模式,并遵循该模式,开发出一种面向铣床特定加工参数的聚类算法应用,即使用主轴加速度信号,将加工过程按照加工深度聚类。选择精密加速度传感器在理想加工环境下获取原始数据,探究算法性能,随后对原始数据进行处理,探究传感器关键参数对算法性能的影响。数据显示,在当前实验环境下,能满足算法性能要求的传感器最小输出速率为2 500 Hz,最小量程为±4 g。利用团队所研发设备及平台在真实环境中做验证实验,实验结果显示,除去一些受噪声影响较大样本,该算法对平面的加工深度有着较高的识别率。下一步将继续围绕智能应用的实践化问题进行研究,主要内容包括基于声发射传感器的故障诊断应用等。
