一种网页访问目的分类方法
2018-10-18张雁刘才铭
张雁,刘才铭
(乐山师范学院计算机科学学院,乐山 614000)
网页访问;访问目的;访问活动;类型编码;类型特征
0 引言
网页是一种包含了丰富内容的互联网信息表达形式,其包含的内容既可以是文本、图片、语音等静态性的信息,也可以是能够被浏览器解析执行的脚本源代码程序、嵌入的其他网页或组件等动态性内容。当浏览器端根据访问地址向Web服务器请求网页内容时,Web服务器直接将静态的HTML文件或者通过解析后生成的HTML文件响应给上网用户的浏览器端。无论Web服务器以何种方式生成网页内容,其都在应用层采用HTTP协议向浏览器端返回以HTML格式编写的网页文件。
互联网用户浏览网页也称为访问网页,由于基于浏览器的简单操作就可以实现网页访问,所以网页不再是简单地提供静态信息,而是可以提供丰富的基于Web的应用程序功能。近年来,各种基于Web的应用技术陆续推出,使得人们访问网页的目的不再局限于被动地接收静态信息,而是可以通过与Web服务器及其附加组件进行交互,实现基于C/S架构能够处理的数据处理功能,例如:OA(办公自动化)、游戏、购物、网银、视频、电子邮件等。
随着网页功能的日益丰富,人们访问网页的目的也逐渐多样化,如何识别网页访问目的的类型,并对其进行分析,以便达到分类的目的,已经成为网络管理的一项重要工作。通过对网页访问目的进行分类,可以识别用户的上网习惯,还能够综合分析网络流量的分布情况,因此具有较好的应用价值。已有的研究主要集中在针对网页的分类[1],这些研究既有采用网页内容特征进行分类的技术,也有针对URL模式进行分类的技术,例如,文献[2]介绍了一种结合网页结构特征进行分类的方法,文献[3]基于网页的URL信息进行分类,文献[4]综合分析URL、主机信息和网页内容的特征信息对网页进行分类。但是,针对网页访问目的进行分类的研究还不多,部分文献结合用户行为特征和网页内容特征,对用户访问的网页进行分类[5],但这还不是严格意义的针对网页访问目的的分类。为了对网页访问目的进行可行的分类,本文设计了一种对网页访问目的进行分类的方法,以期为复杂多变的网页访问目的提供一种有效的分类途径。
1 分类方法
本文构建访问目的类型编码库、访问目的类型特征库,将监视到的网络访问活动信息,通过特征扫描方法与访问目的类型的特征记录进行匹配,一旦扫描到符合匹配条件的特征记录,则将访问活动判断为该特征记录映射的访问目的类型。同时,为了识别出网页访问目的的新类型,本文还考虑了网页访问目的类型及其特征的动态扩充。具体地,本文设计的网页访问目的的分类方法的关键技术如下所述。
(1)访问目的类型编码库
构建访问目的类型编码库数据表,用于存储用户访问网页的主观目的的类型,其表结构如表1所示。该表含有三个字段,分表存储访问目的类型编号(整型数据类型)、类型名称(可变长度字符类型)、备注信息(可变长度字符类型)。

表1 访问目的类型编码库数据表结构
《第33次中国互联网络发展状况统计报告》[6]将网络用户的上网目的在宏观上主要分为搜索引擎、社交网站、电商应用、网络视频、网络游戏、移动互联网共六个方面[7],网页访问活动与传统意义的上网活动还有具有较大的区别,虽然网站系统的应用已发展到相当高的技术水平,但是,由于其实现技术的特殊性,目前其达到的目的还受到了一定的限制。根据当前基于浏览器的网页访问可以实现的功能,可以将网页访问目的的类型归纳为以下几种:信息查询、新闻浏览、网络视频、网络购物、网络游戏、网络银行、网上办公、文件下载等。
(2)访问目的类型特征库
构建访问目的类型特征库数据表,用于存储访问目的类型表达出的访问活动特征信息,其表结构如表2所示。该表的字段包括特征编号、访问目的类型编号(映射到上一小节中的访问目的类型编码库数据表)、访问时间、访问地址、访问网页名称、访问网页的标题、备注信息,其中,访问目的类型编号通过外键关联到访问目的类型编码库数据表的类型编号字段,通过访问目的类型编号,可以查到一条特征记录对应的访问目的类型的名称,多条特征记录可以对应到同一个访问目的类型。
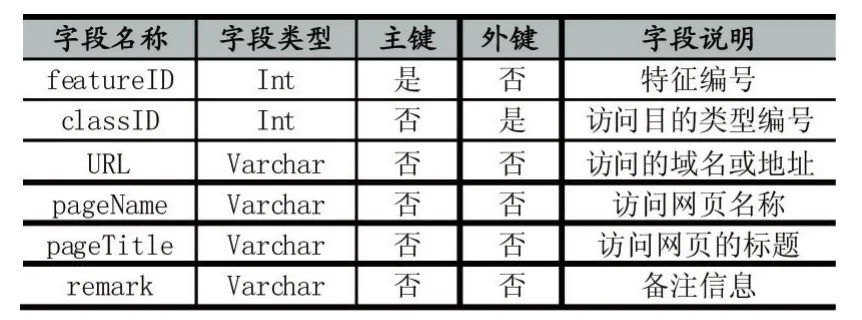
表2 访问目的类型特征库数据表结构
(3)网页访问活动的监视
为了识别用户访问网页的目的,需要监视网页访问活动,并从访问活动中提取出能够反映用户浏览网页目的的关键特征信息,这些信息包括:访问时间、域名或URL地址、网页文件名称、网页标题。
监视网页访问活动的方法可以根据实际需求来确定,总体来说可以分为实时监视方法和离线监视方法。实时监视方法主要有以下两种:(1)在操作系统层面监视用户访问网页的操作行为,当用户访问网页时,从浏览器地址栏或网页文件中提取网页访问活动的特征信息;(2)捕获实时的网络数据流,筛选出传输网页的网络数据包,以分析网页数据包的特征信息作为网页访问活动的特征信息。离线监视方法主要是从网站服务器或用户计算机的日志信息里分析用户的网页访问记录,并从这些记录中提取网页访问活动的特征信息。
(4)网页访问目的类型的特征扫描
当监视到网页访问活动后,构建出该活动的基本信息,设为a=<activityID,访问时间,地址,网页文件名称,网页标题>,并将其在访问目的类型特征库中进行扫描。为了判断活动a属于何种访问目的类型,需要采用一定的扫描方法,取出访问目的类型特征库的特征记录f,计算a与f的匹配程度,如果其达到了设定的阈值,则表示活动a符合特征f映射的访问目的类型编码库中的访问目的类型。
按照表 2中的定义,得到f=<featureID,classID,URL,pageName,pageTitle,remark>。设 a与 f的匹配方法为Match()、匹配阈值为δ,如果访问目的类型特征库中存在一条f满足Match(a,f)≥δ,则网页访问活动a访问类型即为f.classID外键关联的访问目的类型编码库的purposeClass字段表示的访问目的类型。
(5)网页访问目的类型及其特征的动态扩充
访问目的类型编码库表中存储经典的和已经明确的网页访问目的的类型信息,随着基于B/S(浏览器/服务器)架构技术的不断发展,用户通过网页将实现越来越多的功能,因此网页访问目的的类型也将与日俱增。为了表达出访问目的类型的变化,需要定义出新的访问目的类型的信息,并将其添加至访问目的类型编码表中,对访问目的类型进行扩充。同时,也需要动态扩充访问目的类型的特征,先将新构建的特征映射到访问目的类型编码库表,再将其添加至访问目的类型特征数据表。
2 结语
网络用户带着一定的主观倾向去访问网页,其访问网页的目的种类繁多,通过对网页访问目的进行分类,可以促进网络管理和网站应用设计的优化。本文通过监视网页访问活动,并将获得的网页访问活动信息与访问目的类型特征进行匹配,同时考虑到了网页访问目的类型及其特征的动态扩充问题,这种分类方法具有一定的准确性,为复杂多变的网页访问目的提供了一种有效的分类方法。
