云环境下应用感知的动态重复数据删除机制
2018-10-15贺秦禄边根庆邵必林贾雷刚
贺秦禄,边根庆,邵必林,贾雷刚
(1.西安建筑科技大学信息与控制工程学院,710055,西安;2.西安建筑科技大学管理学院,710055,西安)
重复数据删除技术是将数据分解成块,使用数据块的哈希指纹来检测和删除重复块以节省存储空间。重删技术在备份及归档系统中得到广泛应用[1-2]。根据重复数据删除执行的方式可分为两类:在线重复数据删除[3]和离线重复数据删除[4-5]。前者在I/O写请求路径上执行重复数据删除,以立即检测和删除重复数据,而后者在后台进行重删,以避免对I/O性能的影响。然而,这两种方式都存在效率不高的问题。
对于在线重复数据删除,指纹查找是主要的性能瓶颈,因为指纹索引表通常超过内存的大小,只能部分存储在内存,剩余部分存储在磁盘,虽然备份系统可以容忍基于磁盘指纹查找的延迟,但是在云存储系统上可以采用缓存来解决应用程序的延迟问题。iDedup[6]和POD[7]机制进行选择性在线重删。iDedup机制实现了在不同阈值下I/O性能、空间效率和资源消耗之间的均衡;POD机制采用恒定阈值长度为3进行分析验证。本文根据数据流的特征动态调整阈值,以提高系统重删的性能。
离线重复数据删除技术存在两个缺点:第一,在重删之前将所有的数据块写入磁盘,这对于采用SSD作为缓存介质的系统,重删将影响SSD的使用寿命[8];第二,当需要进行大量的重复数据删除时,离线重删技术存在着与其他应用竞争系统资源的问题,影响整个系统的性能。AA-Dedupe机制[9]是应用源端感知的重删方法,基于不同的分块和哈希方案将整个索引划分为更小的子集进行重删指纹匹配。与AA-Dedupe机制不同,本文机制根据应用类型将整个索引分为不同的子集进行数据重删,并利用空间位置来解决读取放大问题。
将在线和离线处理融合在一起可以使每个阶段相互补充并解决单独处理的局限性。在线阶段可以删除具有良好时间局部性的重复块,而将其余重复块保留到离线阶段进行精确重删[10]。在这种方式下,负载的指纹缓存扮演着重要的角色,在线阶段高效的缓存机制能够识别大量的重复块,减少写入磁盘的数据量[11],从而提高I/O性能并减少离线重删阶段的工作量。
1 Hy-Dedup机制的设计
传统的在线或离线处理重复数据删除难以满足云存储系统对的重删率和延迟要求。本文提出了Hy-Dedup机制,结合在线重删和离线重删的两种方式,能够实现系统I/O性能和重删率之间的平衡,这对云存储系统的在线重删是至关重要的。

图1 Hy-Dedup机制系统架构
1.1 Hy-Dedup机制系统架构
图1给出了Hy-Dedup机制系统架构。Hy-Dedup机制部署在存储节点上,数据流的I/O读写操作通过与文件系统接口进行交互,可以兼容任何类型存储系统并进行性能优化。此外,与全文重复数据删除的iDedup[6]和POD[7]机制相比,Hy-Dedup机制又独立于文件系统,具有较好的灵活性和可扩展性。Hy-Dedup机制也可以部署在虚拟机管理程序中,例如VDI、XEN等。虚拟机镜像中存在大量重复数据块,对于在同一主机上运行的多个容器,可以在块设备上部署Hy-Dedup机制,进行重复数据删除。
在线重删阶段首先根据应用类型对写数据流中的数据块的指纹索引进行聚类分组,之后定期评估不同数据流的时间局部性,优先考虑将缓存分配给具有良好时间局部性的数据流。通过这样的方式,在线重删阶段可以有效地减少写入数据量,实时更新指纹索引,保证数据一致性,减少存储和查询哈希索引表所引起的内存和CPU开销,同时减少离线重删阶段的工作量。其次,离线重删阶段仅处理在线重删阶段中未检测出的重复块,采用延迟触发的思想进行设计,当重复数据块达到设定的阈值时才会进行离线重删,根据重删结果置换内存中相应的索引项。与单纯离线处理的重删系统相比,高效的在线重删流程大大降低了对存储容量和系统资源的占用。此外,Hy-Dedup机制根据数据流特征动态调整阈值的策略,不仅可以保证重删率,同时也减少了数据碎片的产生,不影响后续数据恢复的性能。
1.2 在线重复数据删除阶段
在线重删阶段,Hy-Dedup机制维护一个数据块指纹缓存和物理块地址(PBA)映射,以避免指纹表检索的磁盘瓶颈,同时也建立数据块的逻辑块地址(LBA)和PBA之间的映射关系。此外,具有相同内容和局部一致性的I/O请求仅在映射表中记录一项,这将减少实际应用中的内存开销。首先,计算数据流中的数据块哈希值,在重删引擎的缓存中查询块指纹进行匹配;其次,数据流局部一致性估计器负责监视和估计来自不同应用数据流的时间和空间局部一致性。时间局部一致性估计用于优化缓存的命中率,而空间局部一致性用于估计动态调整数据流的重删阈值以减少磁盘碎片。
当缓存命中了输入数据块指纹、这个数据块不存在于映射表时,则将创建LBA和对应的PBA项,并将其添加到LBA映射表中;若缓存中没有命中数据块指纹,则将数据块直接写入底层存储,该数据块相关联的数据块指纹、LBA和PBA映射以及引用计数的对应元数据在3个表中同步更新。缓存未命中的数据块将在离线阶段再次进行重删。
1.2.1 数据流的时间局部一致性估计 重复块的时间局部一致性特征表示在数据流中重复块可能达到系统的时间。良好的时间局部一致性表示重复块通常彼此接近,而弱局部一致性表示重复块通常彼此远离或数据流中几乎不存在重复块。为了计算重复块的时间局部一致性,本文引入局部重复集合的度量(LDS,定义为L)表示数据流在给定时间之前多个连续数据块中重复块的数量,根据缓存分配情况,通过L预测在未来即将到达数据流中重复块。常见的方法是使用历史L来进行预测,为了从数据流中获得历史L,通常是对数据流中所有的指纹及其在估计间隔内出现的次数进行计数,然而,记录所有的数据指纹将产生很高的内存开销。为了解决这个问题,数据流局部一致性估计器使用存储采样算法[12]从数据流中采样指纹,然后使用不可见的估计算法[13]对样本进行L估计。
假设系统处理M个数据流,估计间隔大小为a,时间局部一致性估计的目标是从最近m个写请求中收集k个指纹样本,每个数据流基于指纹样本计算其对应的L。在采样之后,用Ni表示在估计区间内来自i数据流写请求的数量,估计在数据流中最后t个写请求中可实际写入的数量。通过空间局部一致性估算Li的过程如下:首先定义指纹采样函数(FFH)设为F,用来估算数据流i的Li;用Hi′表示样本的采样结果,H表示数据流i在整个估计间隔的F,计算任意一项在特定时间间隔内被采样的概率。采样数据块预期结果Hi′可以通过Hi′=MH/(T+H)计算得到,之后通过计算Hi和Hi′之间的距离平均值得到H,进而代入计算就可以得到数据流的Li。对于在估计间隔期间只有少量写请求的情况,不需要通过上述过程来估计L,只需要将L设置为一个较小的定值即可。
1.2.2 数据流的空间局部一致性估计 为解决数据流重删后引起数据碎片问题,Hy-Dedup机制定义两个变量Vw和Vr。Vw记录连续重复块最大长度值出现的次数,Vr记录顺序读的长度值出现的次数。例如,Vw[3]=100,表示存在长度为3的100个连续重复块;如果Vr[3]=100,则表示有100次长度为3顺序读请求。初始阶段阈值定义为z0,初值设定为20,两个变量在请求到达时收集数据。当阈值更新被触发时,阈值Z的计算公式为
(4)在砂土中进行静压沉桩时,桩-土界面土体与桩体共同下沉约0.2 mm即开始脱离桩体逐步稳定,因此桩体受到的桩侧摩阻力主要来自桩与土的摩擦力.
Z=∑(RLd+(1-r)Lr)/N
(1)
式中:Ld和Lr分别是重复序列的平均长度和平均读取长度;Z是读和写延迟的平衡点;r是所有请求之间的写比率;N为估算间隔。Ld和Lr分别根据在Vw和Vr中收集的数据进行计算,为了应对每个数据流重复模式的变化,自上一个阈值更新以来重删率减少超过50%时,两个变量将全被重置为0。
1.3 离线重复数据删除阶段
在离线重删阶段,通过匹配磁盘上存储的指纹索引表进行数据块重删。与传统离线重删不同,Hy-Dedup机制以延迟方式运行,只有当重复数据块达到设定的阈值时,才会触发重删操作。这种策略为读请求节省空间,对于延迟敏感云存储负载有利。首先,对于在线阶段没有缓存命中的数据块在索引表中创建一个新条目,属性包含数据块ID、哈希值和块大小,当新增加的条目数达到预设值时,离线重删模块会生成一个名为Targets[]的列表,同时,离线重删模块会将每个数据块的LBA和最后访问时间戳(LAT)插入到其相应的条目中。其次,根据重删优先级来重新分配最近访问的数据块的次序,当缓存区存储的指纹数大于设定的阈值时,重删模块才允许完全遍历Targets[]中所有的目标;否则仅处理Targets[]中的一半项即可。最后,按照哈希值的匹配进行数据重删。
2 Hy-Dedup机制的实验分析
首先描述实验参数和方法,然后通过实验来验证Hy-Dedup机制的性能。
2.1 实验环境
在ADMAD平台[14]的基础上实现了Hy-Dedup机制原型。Hy-Dedup机制是云存储环境中应用感知的重复数据删除机制,通过聚类应用中的数据指纹索引以实现高重删效率,它适用于不同的分块算法,如变长分块(CDC)、静态分块(SC)、整个文件分块(WFC)以及不同类型文件和应用的哈希函数,如SHA-1、MD5和Rabin哈希。Hy-Dedup机制是在Lessfs系统[15]上进行搭建,在实验中使用真实数据集重放来验证Hy-Dedup机制的缓存命中率和重删率。具体实验环境由10个节点组成,每个节点配置信息见表1。
表1 实验环境配置信息
表2给出了3个实际应用数据集(VM镜像[16]、Firefox安装镜像[17]和Linux内核源码[18])的存储数据大小和当数据块大小为16 KB时数据集的内部重复率。

表2 3种数据集的数据特征
表3给出了这3种应用数据之间的冗余特性,每个单元格表示共享重复率,由垂直应用和水平应用之间的冗余数据除以水平应用的总数据计算得到。如果单元格中的两个应用相同,则表示应用程序中的数据冗余。从表3可以看出,任何两种不同的应用之间,只有少于1%数据块是重复块。因此,当这3种负载根据请求到达时间的顺序进行排序和合并时,生成的数据集与原始数据集具有相同的I/O模式,这表明对于从相同数据源生成的数据集,设置内容随机重复率为0~36%,将代表用户使用的典型负载类型。
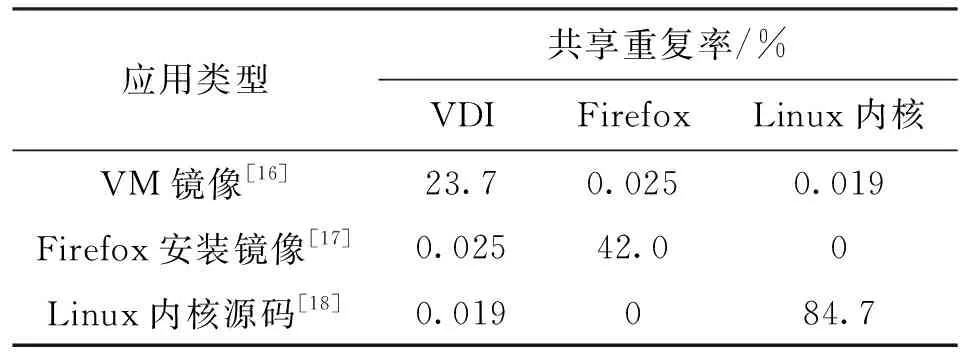
表3 3种不同应用的数据局部一致性
通过上述结果表明,不同应用之间共享的冗余数据量可以忽略不计,原因是不同应用具有不同的数据内容和数据格式,因此可以将相同应用的指纹索引有效地组合在一起,并根据应用类型将整个指纹索引进行聚类分组。
实验的整体思路如下:在初始状态下,后端存储是基于HDD的RAID10,包括具有128 MB缓存和16 KB数据块大小的4个HDD。通过在iDedup和Hy-Dedup机制中重放3个数据集来验证系统吞吐量,同时通过改变缓存和负载的局部性比率来验证重删机制的性能敏感度。
2.2 写性能对比
在由4个HDD组成的RAID10系统上设置不同大小的缓存分别进行实验。图2给出了Hy-Dedup、iDedup和POD机制随着缓存的增加对系统写吞吐量的影响。与iDedup和POD机制相比,Hy-Dedup机制将写吞吐量最高提高了6.9倍,写吞量平均提高了3.2倍,这表明Hy-Dedup机制的写吞吐量对缓存不太敏感,由于Hy-Dedup机制所需的索引缓存小,在云储存环境下应用Hy-Dedup机制时将会获得更好的可扩展性。O分析原因有两个方面:①iDedup和POD机制写吞吐量由指纹索引缓存中数据冗余度决定,虽然iDedup机制将相同分块方案的指纹分组在一起,但索引缓存仍然太大,无法存储在内存中,后端存储和内存之间的页面置换将影响系统性能;②由于Hy-Dedup机制只将应用聚类分组后的指纹索引加载到内存中,重删时所需的缓存和查询大小都减少了,即使使用较小的索引缓存,写吞吐量也呈线性增长。
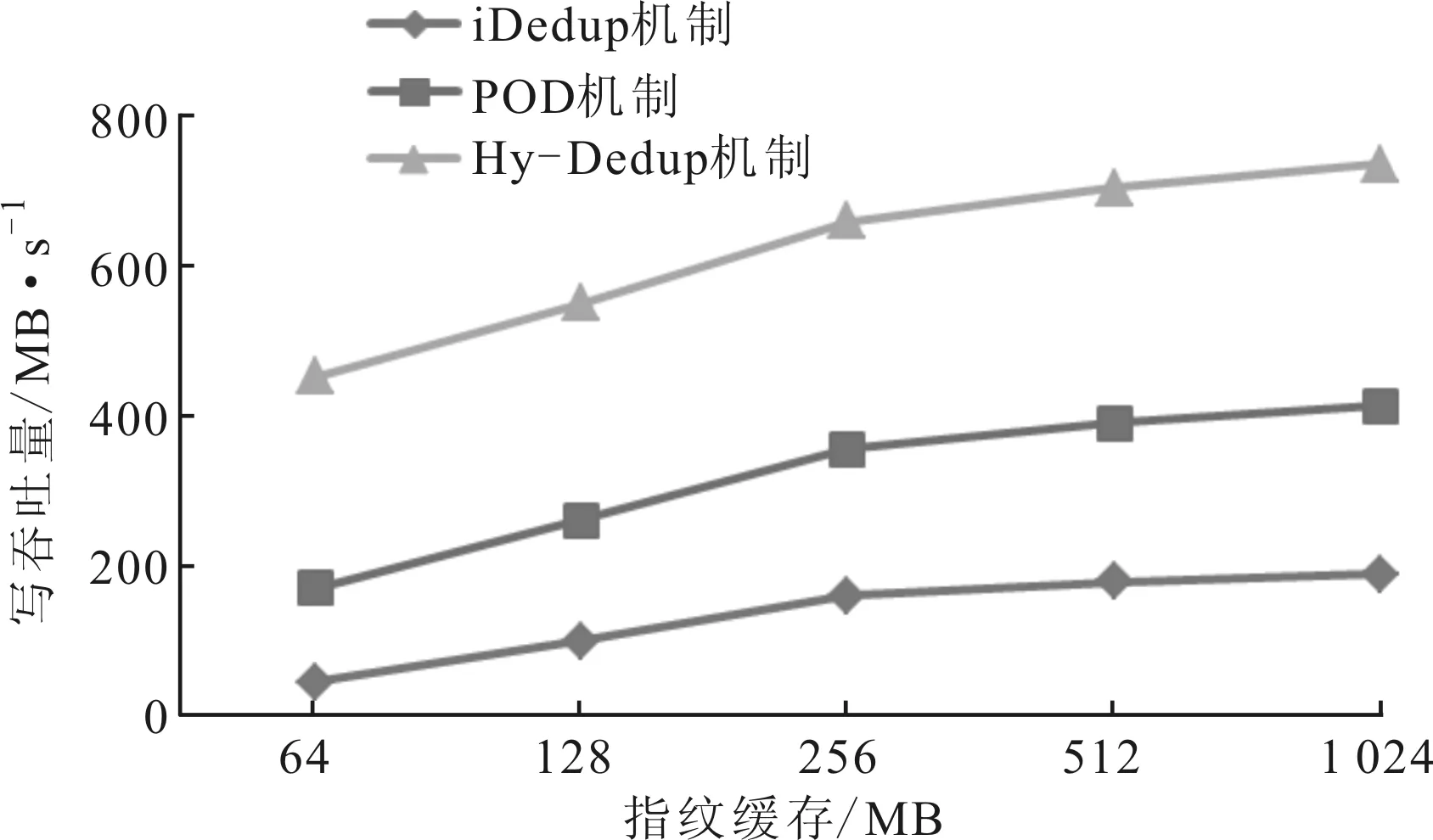
图2 3种方法写吞吐量随缓存的变化
2.3 在线重删缓存命中率比较
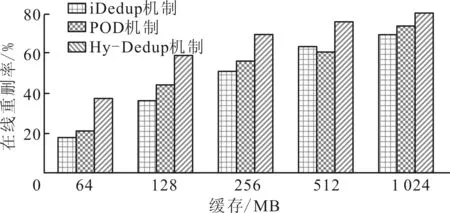
图3给出了Hy-Dedup、iDedup和POD机制在线重删率与缓存的关系。对于每种类型数据流都存在不同的缓存替换策略,文献[5]实验分析得出,LRU算法是iDedup和POD机制较好的缓存替换方法,因此Hy-Dedup机制也使用LRU算法作为缓存替换方法,方便进行实验对比。对于负载A、B和C,具有良好局部性分部(G)和弱局部性能部分(N)之间的数据大小比例分别为3∶1、1∶1和1∶3。
如图3所示,随着局部一致性差的负载量增加,iDedup、POD和Hy-Dedup机制之间的重删率的差距增加,Hy-Dedup机制显著地提高在线重删率。对于负载A,Hy-Dedup机制比POD和iDedup机制重删率提高了7.14%~22.18%;对于负载B,提高了8.32%~23.9%;对于负载C,提高了16.7%~35.9%。随着非本地负载量的增加(从负载A到C),负载的弱局部一致性导致在线重删率较低。Hy-Dedup机制利用局部一致性估计算法,并结合重复块指纹索引聚类动态分配缓存,可以提高云存储中多个应用重删的整体缓存命中率。

(a)负载A(G∶N=3∶1)

(b)负载B(G∶N=2∶2)
(c)负载C(G∶N=1∶3)图3 3种机制重删率随缓存的变化
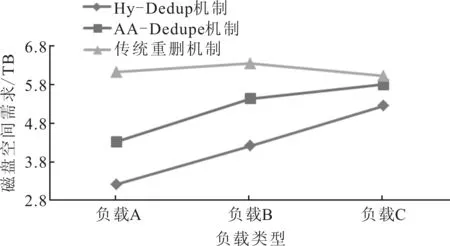
图4 3种机制磁盘空间需求随不同负载类型的变化
2.4 磁盘空间需求分析
如图4所示,对比Hy-Dedup、AA-Dedupe机制和传统重删机制在重删过程中对磁盘空间的需求。在实验中,Hy-Dedup机制在线重删的缓存设置为200 MB,使用LRU算法作为缓存替换方法。
由图4可以看出,针对不同负载Hy-Dedup机制明显降低了磁盘空间需求,与AA-Dedupe机制相比,磁盘空间需求分别下降了41.36%、27.88%和11.95%。结果表明,负载的局部性越好,通过Hy-Dedup机制两阶段的重删可以发现更多的重复块,同时减少数据块的写入量。Hy-Dedup机制这种混合重删架构,只需要维护200 MB的指纹索引缓存就可以减少数百GB的数据写入。
2.5 系统开销分析
2.5.1 计算的开销 Hy-Dedup机制的计算开销主要来自时间局部性估算,包含两部分:指纹生成函数Y的时间和时间局部性估计算法执行时间。为了计算Y,需扫描采样缓冲区并计算指纹发生的情况,时间复杂度是O(n),其中n是样本数。如图5所示,当采样率为20%时1 000个数据块的估计间隔计算时间少于2 ms;对于每个估计间隔,每个数据流时间局部性估计大约需要17 ms。该进程在后台执行并且不影响系统写性能,因此这样的计算开销是可接受的。

图5 Hy-Dedup机制计算开销
2.5.2 内存开销分析 Hy-Dedup机制的内存开销主要来自样本采样缓存。利用估算间隔N和采样率p,内存开销q计算如下
q=Np(fsize+csize)
(2)
式中fsize和csize分别是用于存储指纹和发生计数的内存开销。例如,当缓存为200 MB时,将有大约2.8 MB的缓存项。对于20%的采样率,即使选择较大的估计间隔因子(例如负载C,间隔因子为0.6),内存开销只有4.6 MB(缓存为2.89%)。在实验中,对于具有较好的时间局部一致性的数据流,可以将估计间隔因子设置为较小的值,内存开销减少很多(例如负载A为2.13 MB,负载B为2.87 MB),与具有200 MB缓存的两个负载的在线重删率(18.36%~22.51%)相比,Hy-Dedup机制的内存开销是完全可以接受的。
2.6 离线重删阶段的效率
对比Hy-Dedup、AA-Dedupe和iDedup机制不同后端存储的写吞吐量,在由4个HDD(HDD-RAID10)、4个HDD(HDD-RAID5)和4个SSD(SSD-RAID5)分别组成的RAID5和RAID10系统上进行实验,结果如图6所示。

图6 写吞吐量随不同后端存储环境的变化
从图6可以看出,HDD-RAID5写吞吐量高于HDD-RAID10。原因是4个HDD组成的RAID5系统比4个HDD组成的RAID10系统具有更好的访问并行性,因此可提供更高的写吞吐量。SSD-RAID5的写吞吐量是情况最好的,其原因为如下两点:①SSD的性能优于HDD,从而具有较高的性能;②内存和SSD之间的置换操作比内存和HDD之间的置换操作快得多,从而提高了索引存储和查询的效率,文献[4]的研究结果已经证明了这一结论。另一方面,与iDedup、AA-Dedupe机制相比,Hy-Dedup机制在HDD-RAID10、HDD-RAID5和SSD-RAID5上的性能高出1.8~3.6倍。
3 结 论
本文提出了一种混合重删机制(Hy-Dedup),根据应用负载类型对指纹索引进行聚类分组,估计数据流中重复块的局部一致性,使用动态局部一致性估计算法来提高在线缓存命中率,并将没有被缓存命中的相对数量较少的重复块在离线重删阶段进行处理。通过这种方式,Hy-Dedup机制能够在云存储系统中实现精确的重删,提升系统I/O性能,节省存储空间。与现有的在线重删机制相比,Hy-Dedup机制显著地提高在线缓存效率,从而实现了高效在线重删率。未来还需要在以下两个方面展开研究:设计具有高查询效率的兼容性索引结构;利用机器学习实现自适应调整控制参数的策略。
