云工作流时间延误处理策略综述
2018-10-10王福田
杨 耘,刘 晓,王福田
(1.安徽大学 计算机科学与技术学院,安徽 合肥230601; 2.斯威本科技大学 软件和电子工程学院,澳大利亚 墨尔本 3122;3.迪肯大学 信息技术学院,澳大利亚 墨尔本 3125)
1994年,工作流管理联盟(workflow management coalition,简称WfMC)给出了工作流及工作流管理系统参考模型的定义[1].定义工作流是一个能够整体或部分自动化执行的业务流程,根据业务流程的规则,文本、信息或者是任务能够在不同用户之间传递或执行[2].工作流管理系统参考模型有工作流执行服务(workflow enactment service)、过程定义工具(process definition tools)、工作流客户端应用程序(workflow client applications)、应用程序调用(invoked applications)、其他工作流执行服务(other workflow enactment services)以及管理和监控工具(administration and monitoring tools)6个基本功能组件和系统接口,保障数据在工作流系统中的正常执行[1].工作流管理规范了业务的操作流程,提高了工作效率.许多企业和科研部门都开发了相应的工作流系统,如早期以P2P结构的Triana、Serendipity、SwinDeW以及随后以grid范式开发的Kepler、SwinDeW-G等[3].
随着云计算的快速发展,大量的工作流系统把云计算环境看作是一个无限的计算、存储和网络资源池,相关研究人员开发了基于云计算环境的云工作流系统.例如:Hadoop中开发了WfMS(workflow management system)的核心功能,可以处理大规模的工作流应用程序[4];亚马逊的SWF(shock wave flash)是托管在AWS(Amazon web services)上的工作流处理程序[5];Microsoft的基于.NET framework的Windows Workflow Foundation[6];IBM(international business machines corporation)的基于云的智能业务流程管理软件IBM_BPM[7];SwinDeW-C是一个部署在SwinCloud上的一个P2P的云工作流系统[8];SwinFlow-Cloud是一个部署在亚马逊云上的基于客户端云架构的云工作流系统[9].
这些云工作流系统利用云计算提供的海量的、廉价的计算、存储和网络资源,根据业务的工作量,动态地从云计算服务提供商那里申请所需的软件和硬件资源,而无须自己搭建和维护庞大的基础设施和软件平台[10].云工作流系统的这种资源管理模式,大大降低了企业和政府处理大规模业务流程的资金门槛和技术门槛,为工作流实例的运行提供了理想的系统运行环境[11].例如,天气预报、地震模型、天体物理等计算密集型的科学应用,股票交易、银行交易、电子商务等实例密集型的电子商务应用.这些流程在构建阶段,可以按照工作流的规范对流程结构、功能性需求、非功能性需求等进行建模,在执行阶段可以使用云计算环境的可扩展资源来完成流程的计算和处理.
虽然云工作流系统具有很多优势,但是很多学者和企业内人士都认为云计算环境中的应用性能管理是一个很大的难题[12-13],主要原因是云工作流系统的服务质量(quality of service,简称QoS)常常不能满足用户的需求.在实际应用中,由于这些工作流应用程序大多数都有时间约束,而云计算环境的底层基础设施具有分布式和动态特性,使得工作流实例很难保证在规定的时间内完成,这会降低用户对云工作流系统的满意度以及工作流输出结果的有用性,甚至是导致经济上的损失.因此,需要及时发现工作流实例在执行过程中的时间延误即时序异常情况,并尽可能减少其对最终结果的影响,提高云工作流系统的QoS.
文献[14]给出工作流QoS的主要维度包括时间、成本、保真度、可靠性和安全性.具体来说,时间是性能的基本度量,它指的是在工作流系统中完成工作流实例执行所需的总时间.文献[15]提出一个通用的时间验证框架,它为工作流实例的执行提供一个全生命周期的时间QoS支持.该框架主要由4个基本模块组成:时序约束设置[16]、时序检测点选择[17]、时序验证[18]和时序异常处理[19].由于时序检测点的选择是基于时序验证的,有时把二者合在一起统称为时序检测点选择.时序约束设置主要是在工作流构建阶段设定工作流的局部时间约束和最终完成时间[16].时序检测点选择是根据时序约束,选择工作流活动的子集作为时序一致性的检测点,对该时刻的工作流时序状态进行判断[20].在工作流执行过程中,如果工作流的活动没有在规定的时间内完成,则被认为发生了时间延误也被称为时序异常[21].如果不及时对时序异常进行处理,可能会导致整个工作流实例不能在规定的时间内完成.时序异常处理则是通过云工作流系统的各种恢复处理策略,使工作流实例最终能够在规定的时间内完成.论文从不同的角度对计算密集型的科学工作流和实例密集型的商务工作流的时序一致性建模,时序一致性监测和时序异常处理策略进行讨论和概述.
1 工作流时序一致性模型
工作流时序一致性建模是用数学模型来定义工作流执行过程中的时序一致性,是时间验证框架的基础,为后期的时序检测点的选择提供理论依据.当前流行的两种时序一致性度量标准是响应时间和吞吐量[22-26].响应时间度量的是活动从提交到最终完成所持续的时间量,吞吐量度量的是单位时间内完成的活动的工作量.
1.1 基于响应时间的科学工作流时序一致性模型
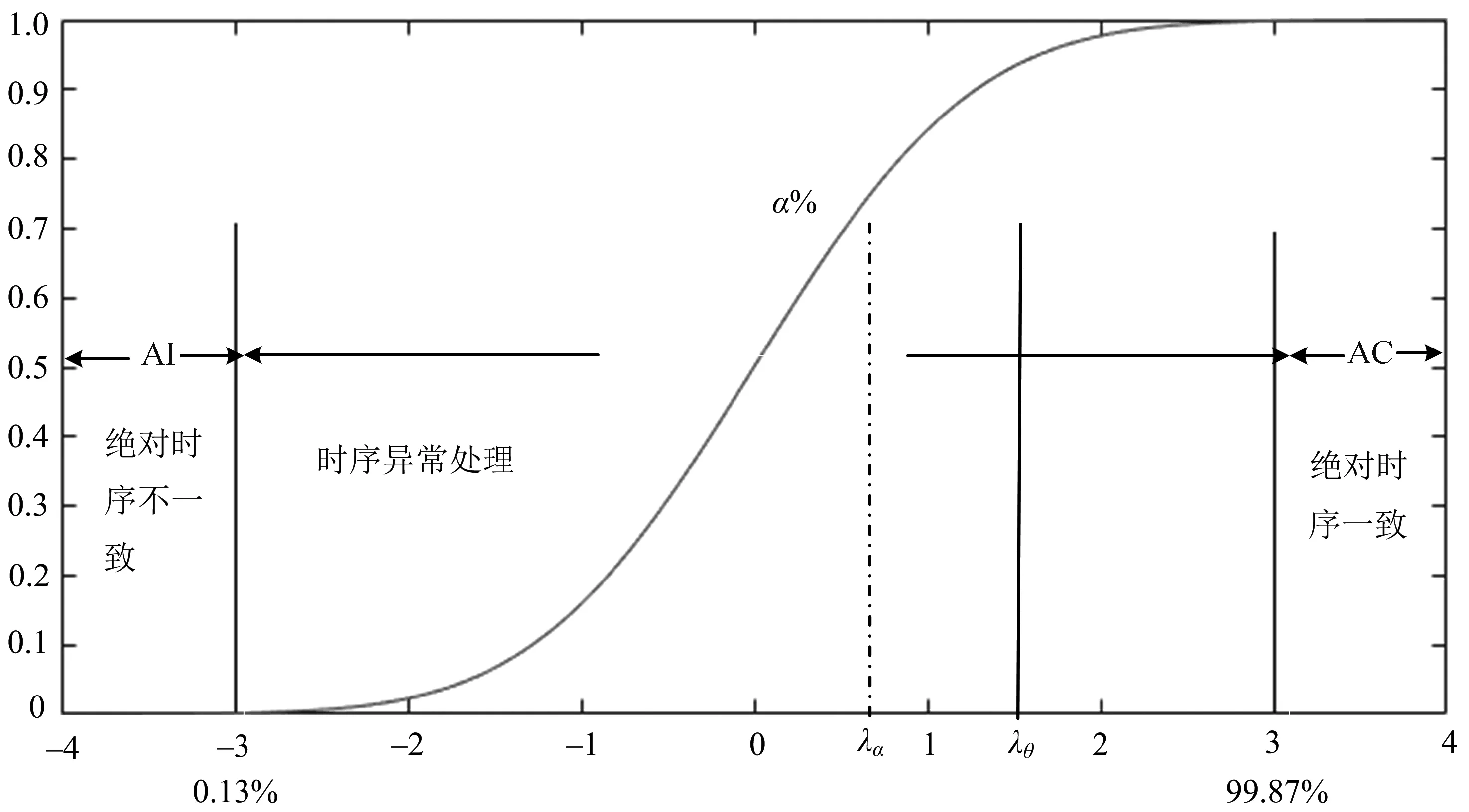
科学工作流是一个单一的工作流实例,该实例包含若干个计算密集型或者是数据密集型的工作流活动,每个活动通常需要运行数分钟甚至数小时.因此,要保证科学工作流最终能按时完成,每个工作流活动的运行时间都需要进行监测.为了更好地描述工作流时序一致性模型,文献[27]给出了关于工作流和工作流活动时间属性的一些注释.假设工作流中的第i个活动是ai,则该活动的实际运行时间、期望运行时间、均值运行时间、最小运行时间、最大运行时间分别记为:R(ai)、E(ai)、M(ai)、d(ai)和D(ai).假设同类活动的运行时间满足正态分布N(μi,σi2),其中:期望是μi,标准差是σi.文献[27]证明,该理论在其他分布模型中也适用,并对性能没有实质影响.假设SW表示科学工作流实例,U(SW)表示科学工作流实例的上界时间约束.基于响应时间的科学工作流时序一致性模型被描述如下:若科学工作流实例SW包含了活动al到活动an,在活动ap(l (1) 则称为绝对一致. 如果 (2) 则称为绝对不一致. 如果 (3) 则称为α%一致. 在上述公式中,R(al,ap)表示活动al到ap的实际运行时间开销,λα(-3≤λα≤3)表示后续活动若以μ+λασ为执行时间,则工作流的按时完成率为α%. λα和α%之间的关系可由公式 计算得到.因此,根据该模型,可以定义基于响应时间的科学工作流的绝对一致、绝对不一致和α%一致状态. 商务工作流由大量的、并发的工作流实例构成,每个工作流实例包含数个或者是几十个活动,这些活动的运行时间通常很短或者较短.因此,在商务工作流的运行过程中,需要监测商务工作流的整体完成情况.文献[28]用单位时间内完成的工作流活动的数量来计算吞吐量,这种定义并不能准确反映出实例密集型工作流的完成情况.每个运行时间不同的活动,对整个工作流运行时间的贡献是不同的.文献[27]以活动运行时间对整个工作流运行时间的贡献作为吞吐量的计算方式,该方式可以准确计算出工作流当前完成的情况. 假设W(BW)表示商务工作流的总工作量,RTHai表示商务工作流中第ai个活动完成时的运行吞吐量.基于吞吐量的商务工作流时序一致性模型被描述如下:在第ai个活动的完成时刻,如果 (4) 则处于绝对时序一致状态. 如果 (5) 则处于绝对时序不一致状态. 如果 (6) 则处于α%一致状态. 通过上面的定义,云工作流系统可以根据用户对服务质量的要求以及所采用的时序异常处理的能力,对时序一致性状态进行自由的划分,该模式更加符合商业计算环境.例如,用户希望工作流实例有90%的按时完成率,系统根据工作流的时序一致性模型,可以算出所需的云计算资源量,从而实现资源的按需提供. 在文献[27]中,作者把基于响应时间和基于吞吐量的时序一致模型总结为都是基于概率的时序一致性模型.如图1所示,根据正态分布“3σ”准则可知99.73%的活动的运行时间都在(0.13%, 99.87%)范围内.图1的左边即绝对不一致(absolute inconsistency,简称AI)部分,表示工作流出现严重的时序违背;图1的右边即绝对一致(absolute consistency,简称AC)部分,表示工作流处于良好的时序一致状态.在工作流运行的任意时刻,都可根据工作流的时序约束计算出当前工作流的时序一致状态α%.假设用户和服务提供者之间协商的最低可接受的时序一致性状态为θ%,根据α%与θ%的比较,即可判断出当前工作流的时序一致状态是否满足用户的要求. 图1 基于概率的时序一致性模型 时序检测点的选择是在工作流运行过程中选择活动的子集作为时序检测点,在时序检测点上对工作流的时序异常状态进行评估、处理,最终保证工作流能按时完成.因此,时序检测点的数量还影响后续时序异常处理的次数和工作流的按时完成率.选择过多的时序检测点,还可能增加后期时序异常处理的开销[29].时序检测点的选择策略有很多种方法,例如:文献[17]提出了时序检测点选择的评价标准——充分必要性,“充分性”即只有发生了时序异常的活动点才会被选择为检测点,“必要性”即没有遗漏任何发生了时序异常检测点,而“充分必要”是时序检测点选择策略理论上的最优标准,最大限度地保证了工作流的时序异常得到及时处理;文献[22]将用户根据经验选择的活动作为时序检测点;文献[30]把工作流的每个活动选择为一个时序检测点;文献[31]选择活动运行时间大于平均运行时间的活动为时序检测点.该节针对基于响应时间的科学工作流时序检测点选择策略和基于吞吐量的商务工作流时序检测点选择策略分别进行概述. 文献[19]提出一种基于概率时间冗余的科学工作流充要时序检测点选择策略,该策略利用基于响应时间的时序一致性模型,实现对科学工作流中的时序检测点选择.该策略中的概率时间冗余的定义被描述为:活动ap是活动ai和活动aj(i PTR(U(ai,aj),ap)=u(ai,aj)-[R(ai,ap)+θ(ap+1,aj)], (7) 其中 根据概率事件冗余的定义,最小概率时间冗余的定义可描述为:假设U1,U2,…,UN是N个包含ap的上界约束,则最小概率时间冗余可被表示为 MPTR(ap)=min{PTR(Us,ap)|s=1,2,…,N]. 该定义可以使工作流运行过程中的时序异常被尽早检测到.根据该定义,则有在活动点ap,如果不等式 R(ap)>θ(ap)+MPTR(ap-1) 成立,则至少有一个时序约束是异常的.因此,活动点ap被选择为一个时序检测点,同时该策略选择的检测点满足充要条件. 文献[27]提出一种基于吞吐量的商务工作流充要时序检测点选择策略,该策略的核心思想是,在商务工作流的执行过程中,如果在某个活动点上,当前的完成率低于目标按时完成率,则该活动点被选择为时序检测点.这里,假设THConsai表示商务工作流中第ai个活动完成时的约束吞吐量,则具体的定义被描述为:在活动点ap,如果不等式 RTHai 成立,则该活动点ap被选择为一个时序检测点.由于该策略是沿着商务工作流的运行过程在每个活动完成点上进行检测的,因此该策略选择的检测点也满足充要条件. 上述不等式本质上反应的是商务工作流当前的运行情况,根据该运行情况,可以计算出商务工作流当前的按时完成率.假设用户和服务提供者协商的商务工作流的按时完成率为θ%,根据上面给出的基于吞吐量的商务工作流时序一致模型,可以计算出当前时刻商务工作流的成功率α%,如果不等式α%<θ%成立,则表明当前时刻的按时完成率低于目标值,即商务工作流有超时的风险,该活动点应被选择为一个时序检测点. 时序异常处理是针对工作流实例在运行过程中检测到的时序不一致情况进行分析,并采取相应的时序异常处理策略,最终保证工作流实例按时完成.文献[32]把工作流的时序异常处理策略分为3大类:无操作、回滚和补偿.其中,无操作对工作流运行过程中监测到的时序异常不做任何处理,认为工作流系统具有自恢复能力,这种方式被认为是有风险的.回滚策略是重新运行工作流的部分活动,减少活动的运行时间,该策略并不能消除工作流的总体延迟时间.补偿是一种较为合理的工作流异常处理策略,常用的补偿策略有加资源和重调度[33].具体来说,加资源是在云环境中申请新的资源,而重调度是对工作流的后续活动重新生成一个新的调度计划.文献[21]提出了一种考虑自恢复的科学工作流的时序异常处理策略.文献[34]提出了一种针对商务工作流的异常处理策略.还有一些基于蚁群算法ACO(ant colony optimization)和粒子群算法PSO(particle swarm optimization)等算法的时序异常处理策略[35-36]. 文献[19]提出一种基于遗传算法的局部重调度的科学工作流时序异常处理策略.该策略的核心思想是在时序异常处理点上,计算工作流之前活动的最大概率时间赤字和后续每个活动所能弥补的时间量,利用基于遗传算法的局部重调度策略对后续的工作流活动重新生成运行序列,使后续活动的运行可以弥补之前活动运行过程中产生的时间赤字,从而使工作流最终能按时完成. 在活动点ap,概率时间赤字被定义为 PTR(U(ai,aj),ap)=u(ai,aj)-[R(ai,ap)+θ(ap+1,aj)], (8) 则最大概率时间赤字为 MPTR(ap)=min{PTR(Us,ap)|s=1,2,…,N}, (9) 因此,每个活动所能恢复的时间赤字为 (10) 计算出每个活动所能恢复的时间赤字之后,调用基于遗传算法的局部重调度策略,即可实现对工作流时序异常的处理.该策略主要是通过限定子代的数量,来降低算法的时间复杂性,使算法在多项式时间内计算出工作流活动的重调度序列.同时文中还给出了该策略有效性和可行性的相关证明. 由于商务工作流中包含大量的活动,而每个活动的运行时间又不相等,这导致按照时序一致性模型进行检测时,会发现很多时刻商务工作流都会有时序异常发生.其中有大量的时间赤字都非常小,可以认为后续活动的时间冗余可以自动补偿这部分时间赤字[35-36].基于此思想,作者提出一种考虑自我恢复的基于阈值的时序异常处理策略.该策略的思想是,在每个时序检测点,对商务工作流的时间赤字进行判断,当时间赤字足够大时,即在活动ai的完成时刻,当商务工作流的时间赤字大于3*σi时,则启动时序异常处理.在时序异常处理时,根据每台服务器所能恢复的最大时间赤字,采用阈值的方式来计算添加服务器资源的数量.阈值的定义为 (11) 其中:Mmax(a)表示商务工作流活动中运行时间最大的一类活动的均值运行时间,即Mmax(a)=max[M(ai),M(aj),…,M(an)],S(TH)表示服务器单位时间内完成的吞吐量. 添加服务器数量的计算公式为 THConsai-RTHai≤n*THThres. (12) 满足不等式的最小整数n即为添加服务器的数量.该策略可以在花费小代价的情况下,使商务工作流的服务质量达到用户的需求. 该文针对云工作流的时间延误处理策略从时序一致性建模、时序检测点选择策略和时序异常处理策略3个方面分析,并把云工作流分为计算密集型的科学工作流和实例密集型的商务工作流两大类来进行归纳总结.最后,结合当前的研究趋势,探讨了云工作流时间延误处理领域未来的研究方向. 尽管在云环境下针对提高科学工作流和商务工作流的服务质量,已经提出了不少方法,但是随着云计算、边缘计算以及大数据的发展,云工作流的服务质量依然是一个需要研究的热点课题.作者认为未来的研究方向有以下几点: (1) 提高云工作流时间延误处理策略的鲁棒性.即使在云计算环境差异非常大的情况下,依然能保证云工作流系统的服务质量达到用户的需求. (2) 研究通用云工作流时间延误处理框架.目前,科学工作流和商务工作流的时间延误处理策略是从不同角度进行处理的.可以考虑设计一种通用的云工作流时间延误处理框架,能适用于科学工作流和商务工作流两种不同的模型. (3) 研究复杂云工作流模型的时间延误处理策略.针对更加复杂的云工作流,例如物流工作流,在分析时既要考虑整体时间延误的处理,又要分析单个实例的时间延误情况.这需要设计更加复杂的云工作流时间延误处理策略. (4) 研究基于深度学习的智能云工作流时间延误处理策略.目前,深度学习理论的高速发展,使一些领域的研究取得了突破性的进展,例如在计算机视觉领域.因此,可以考虑借助于当前深度学习的研究成果,设计智能的云工作流时间延误处理策略.1.2 基于吞吐量的商务工作流时序一致性模型
1.3 基于概率的工作流时序一致性模型
2 时序检测点选择策略
2.1 基于概率时间冗余的科学工作流时序检测点选择策略
2.2 基于吞吐量的商务工作流时序检测点选择策略
3 时序异常处理策略
3.1 基于重调度的科学工作流时序异常处理策略
3.2 基于加资源的商务工作流时序异常处理策略
4 结束语
