基于时间序列和聚类的挤压机能耗异常检测研究
2018-10-09曾利云张植豪
曾利云,肖 云,张植豪
(广东工业大学机电工程学院,广东广州 510006)
0 引言
挤压机是铝型材加工生产的核心设备,在运行过程中会消耗大量电力。铝型材加工企业的能源管理系统可实时采集挤压机生产过程中的能耗数据。通过对数据的分析,能检测出挤压机在生产过程中的能耗异常行为,从而为企业节能减排、提高能源效率提供有价值的信息。所谓异常数据,是指在数据集中与众不同的数据,并且这些数据并非随机偏差,而是产生于完全不同的机制。挤压机能耗异常特征可以分为点异常和模式异常,在生产过程中存在难以精确检测出能耗异常状况,难以建立精确的异常检测数学模型的问题。
异常检测被广泛应用于设备状态监测、建筑能耗、网络入侵检测以及其它领域。能源消耗领域的异常检测方法包括回归法、k-最近邻域(K-NN)、熵法和聚类法[1]。Zhao[2]提出一种基于动态时间规整(DTW)的自适应模糊C均值(AFCM)方法,可以有效地检测某钢铁厂的能量异常数据。Guo[3]提出一种车间级热损失故障检测方法,建立TVWS的动态分层能耗模型,采用LMBP算法和能耗因子法对热损失基线进行估计。Khatkhate[4]利用相关测量的时间序列数据,建立隐马尔可夫模型,以用于机械系统异常检测。王伟影等[5]针对燃气轮机运行过程中的健康维护问题,采用模糊C均值聚类算法对燃气轮排气温度进行异常检测。贺惠新[6]针对燃气轮机的点异常和序列异常,分别引入以样本为核心的聚类思想和基于加权流形嵌入的方法对其进行检测。戴慧[7]基于滑动窗口数据的置信区间,构造变化趋势特征值和相对变化趋势特征值分别用于二次探测,能够快速准确地探测出变电站各设备表数据集的异常点。Chou[8]提出一种具有滑动窗口的ANN和ARIMA混合模型,利用大量的数据集来识别建筑空间的异常功耗。Akouemo[9]提出一种用于异常检测的概率方法,应用于天然气的时间序列数据中,可识别未知来源的异常。目前,在基于全局的检测方法中,由于过分关注全局的环境,容易忽略局部的异常变化,容易造成漏报;而基于局部序列的方法中,因为过分关注局部的细微变化,而没有从整体去考虑序列正常行为的特点,容易造成误报。
本文作者针对挤压机生产过程中的能耗特征和传统异常检测算法漏检率高、效率低的问题,提出一种基于K-MLS和K-MLOF的挤压机能耗异常检测方法。实验证明,该方法能够有效检测出挤压机生产过程中的能耗异常现象,并且具有通用性和鲁棒性等特点。
1 问题描述
铝型材挤压机生产过程中,由于设备因素、人为误操作等原因均会导致能耗异常现象,造成大量能源浪费。目前,随着工业信息技术的发展,大多数铝型材企业都建立了能源管理系统来监控内部能源状况,用来优化能源运作,节约成本。能源管理系统实时采集到的挤压机能耗异常数据,通常有如下几类特征:
(1)点异常:由于数据采集系统故障或信息传输问题,比如智能仪表故障、通信中断、存储异常等,导致在某个时间点的能耗数据偏离正常值,但是其邻近域内的能耗数据又是正常的,其表现形式如图1(a)所示。
(2)模式异常:指一段数据集相对于整个数据集的其他部分表现为异常,但这一段数据集中的单个数据可能是异常,也可能不是异常的情况。其表现形式如图1(b)所示。

图1 不同特征的能耗数据趋势图
2 基于时间序列和聚类的异常检测方法
能源管理系统实时采集到的挤压机能耗数据表现出时序性、周期性和分类特性。能耗数据的周期性反映出了铝型材连续挤压过程中的相似生产过程;分类特性则表现了一个挤压周期中不同挤压阶段。因此,基于铝型材生产能耗数据特点,将异常检测分为两个阶段:一是针对挤压过程,检测挤压机在生产过程中出现的点异常现象;二是针对挤压周期,检测挤压机生产过程中出现的模式异常现象,以弥补模式异常或点异常分别检测时的漏检情况。整体异常检测模型如图2所示。

图2 异常检测模型
2.1 相关定义
(1)定义1:时间序列
设时间序列ti时刻的记录值为vi(ti),记录时间ti是严格 增 加 的 (i<j⇔ti<tj) ,则 可 将 时 间 序 列 记 为X=<x1=(t1,v1(t1)),x2=(t2,v2(t2)),...,xn=(tn,vn(tn))> , 简 记 为X=<x1,x2,...xn>。
(2)定义2:时间序列的子序列
设有时间序列 X=<x1,x2,...,xn> 和 X1=<xi1,xi2,...,xin> ,其中,xi1,xi2,...,xin∈X ,并且有1<i1<...<in<n 。则称 X1为X的子序列。
(3)定义3:欧式距离
给定时间序列 X=<x1,x2,...,xn>和Y=<y1,y2,...yn>,则欧式距离可表示为:

2.2 时间序列点异常检测
2.2.1 能耗数据分类处理
挤压机与其挤压状态存在着一定的对应关系,即当挤压机处于空载前进和快速后退阶段时,其能耗比较小;当挤压机处于挤压状态时,其能耗比较高。针对这一耗能特点,为了更加精确的对能耗数据进行点异常检测,有必要针对不同的情况进行分类处理。
K-Means算法是典型的聚类算法,其目的是根据距离中心最近原则,通过计算其他数据对象到各聚类中心的距离,在不断迭代循环中,将数据分配到指定的不同的K个类簇中,使得簇间相似度尽可能大而簇内相似度尽可能小。鉴于K-Means算法的聚类作用且简单高效,本文作者使用该方法对一段时间内的能耗数据进行分类处理,K-Means具体算法流程图如图3所示。
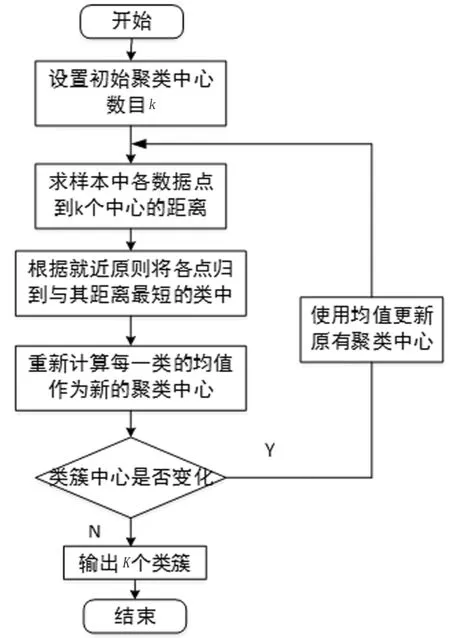
图3 K-Means聚类算法流程图
输入:长度为N的数据集X={x1,x2,...,xn},最终聚类个数K;
输出:聚类后的K个类簇C={c1,c2,...,ck}。
2.2.2 LOF异常系数
为说明LOF异常系数,首先给出K-近邻距离的概念,设q为数据点集A中的一点,k为任意给定的正整数,则q点的K-近邻距离k-dist(q)满足如下条件:
(1) A至少有k个点(不包括q点),他们到q点的距离小于或等于 k-dist(q),即存在 k个点x∈A{q},d(q,x)≤k-dist(q)。
(2) A中最多有k-1个点(不包括q点),他们到q点的距离小于 k-dist(q),即存在 k个点x∈A{q},d(q,x)<k-dist(q)。
在K-近邻距离定义的基础上,可将点q到点o的K-近邻可达距离表示为:

式中:d(q,o)表示点q到点o之间的欧式距离。
接下来可得点q的异常系数LOF(q)为:
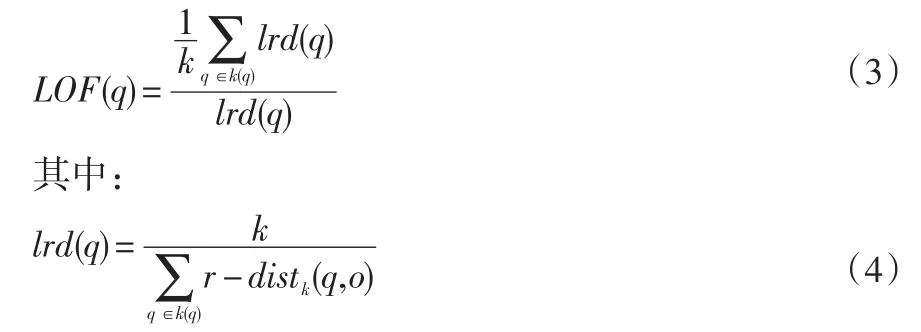
在上面的公式中,k(q)表示点q的近邻范围,lrd(q)指点q的K-局部密度,它反映了点q周围点分布的密度状况。以LOF(q)作为衡量某一点是否异常的指标,当其较大时,表示点q周围中包含的点比较稀疏,进一步说明点q是异常点的可能性较大。
2.2.3 基于K-MLS的时间序列点异常在线检测模型
针对挤压机能耗特点,结合时间序列和聚类的思想,提出一种基于K-Means和LOF的时间序列点异常在线检测模型,简称基于K-MLS的点异常检测算法。在使用K-Means算法对历史能耗数据分类的基础上,使用LOF异常系数对不同类别的实时能耗数据进行异常检测,具体实现流程如图4所示。
2.3 时间序列模式异常检测
针对模式异常,提出了一种K-MLOF时间序列模式异常检测方法。从模式的角度检测时间序列能耗数据的异常行为,弥补了点异常检测算法仅仅能检测出单个异常数据的局限性,提高了异常检测的效率和准确率。
2.3.1 特征值
在挤压机能耗数据中,为全面表示能耗数据时间序列的模式特征,提取一段子序列的特征值:高度、均值、方差、标准差,从而将时间序列映射到多维特征空间。
首先,将边缘权重因子的定义为:


图4 点异常检测流程图
式中:
m为检测边缘权重因子W(i)的窗口宽度,即子序列长度;
xmaxxmin为每一个检测窗口中所检测到的最大/小序列值。
子序列的高度定义为:

子序列的均值定义为:

2.3.2 k-异常因子(K-MLOF)
将时间序列子序列映射到四维特征空间C(h,x-,σ,s)后,给定 k∈N+,设点 p(hp,xˉp,σp,sp),q(hq,xˉq,σq,sq)为四维特征空间中的任意一点,那么p与q之间的欧式距离可表示为
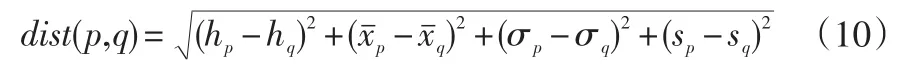
结合上文对kth距离k-dist(p)的介绍,可得
对象p的k平均距离为

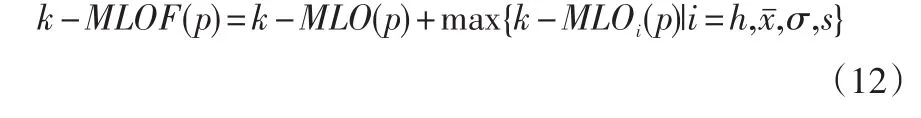
其中,
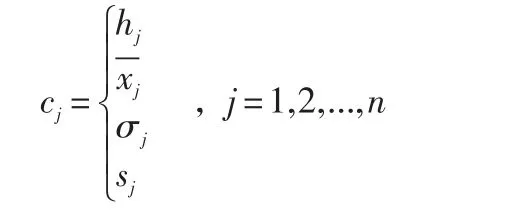
根据定义知,K-MLOF的值越大,子序列段对应的模式是异常模式的可能性就越大。
2.3.3 基于K-MLOF的时间序列异常模式检测算法
输入:时间序列X=<x1,x2,...,xn>及其长度n,子序列长度m,滑动窗口l以及近邻数目k;
输出:时间序列中的异常子序列。
具体流程:
(1)给时间序列X加窗,记为Fi,其中,i表示第几个滑动窗口,首先,令i=1;
(2)对时间序列X=<x1,x2,...,xn>,以挤压周期为界将其分为N个子序列,使用公式(5)计算出每个子序列的边缘权重因子;
(3)计算特征值,规范化每一段子序列的4个特征值,将其值都限定在(0,1)之间;
(4)由公式(10)—(12),计算每个子序列的K-异常因子,当k-MLOF的值显然较大时,表示该段子序列为异常模式的可能性最大;
(5)滑动窗口右移,i++,转(2);
(6)输出异常模式子序列。
3 验证与讨论
3.1 能耗数据采集及预处理
提取能源管理系统数据库中的挤压机能耗历史数据用于模型验证,并将验证后的模型用于挤压机能耗数据在线异常检测。在能耗数据异常检测之前,对能耗数据做如下几种数据预处理:数据平滑处理、缺失数据处理。处理前和处理后的能耗数据图如图5所示。
3.2 异常能耗数据检测
以华南某大型铝型材生产企业的SY-1800Ton型挤压机作为案例研究,以能源管理系统的数据库中取自2016年10月生产同种型号铝材的能耗数据作为数据样本。首先对数据样本进行预处理,其次将整个样本分为训练样本和测试样本两类,其中训练样本不含异常能耗数据。为了更清晰的观测到模型的性能,已知测试样本中包含了2个模式异常数据集和5个点异常数据,其中模式异常数据在整体上表现为异常,但是数据单独分开来看并非异常。
实验配置为:Win7系统,MATLAB12(a),CPU2.4 Hz,内存4.0 GB。
3.2.1 点异常检测
针对挤压机能耗数据曲线的特点,观测图5的挤压机能耗曲线周期图可知,能耗数据呈现两极分化的状态,处于临界状态的值较少,高能耗数据对应挤压状态,低能耗数据对应挤压前和挤压后两种状态,简称非挤压状态。鉴于此,在使用K-Means方法对历史能耗数据分类时,设置最终聚类数K=2。将训练样本数据输入到模型中通过MATLAB进行仿真训练,仿真分类结果中的高能耗数,对应挤压状态;低能耗数据对应非挤压状态。利用测试数据代替实时能耗数据,给定初始近邻距离,对各数据点,首先判断所属类别,再与同类别能耗数据进行离群点分析,计算LOF异常系数值。如图6为各能耗数据点的LOF值。
从图中可以看到,LOF的值大部分在1附近波动,但图中标记的5点的LOF值明显高于其他点,若令LOF值大于2的点为异常点,则可判断标记点对应的能耗数据为异常点。由于模式异常序列拆分成单个点时,其并非为异常点,所以在计算单个点LOF值时仍处于正常范围。

图5 处理前后的能耗数据图
3.2.2 模式异常检测
在验证K-MLOF算法的实验效果时,直接使用包含异常样本的测试数据样本进行仿真验证,实验中,给定能耗时间序列样本长度为0.5 h采集到的能耗数据个数,子序列长度m取能耗数据周期时间2 min,在仿真实验中不断对k的取值进行变动,结果表明,当k取值在11~28左右变化时,检测效果最好,其仿真效果图如图7所示。

图6 挤压机能耗数据点的LOF系数

图7 模式异常检测仿真结果图
根据图7可以看出,在时间段A和B区间内,K-MLOF异常因子明显高于其他时间,在给定的样本中同样是在A、B时间段内挤压机能耗出现模式异常,图中在点异常的地方,其K-MLOF异常因子并没有太大的变化,由此可证明算法在模式异常检测上的有效性。
3.3 分析与讨论
通过上述仿真实验,证明本文作者提出的K-MLS算法和K-MLOF算法在检测挤压机能耗点异常和模式异常的有效性,为进一步说明该算法相对于原算法或其他算法的优势,在同一样本的前提下,使用不同算法进行了仿真实验,对点异常检测,使用原K-means算法和本文所提出的算法进行比较,结果如表1所示,对于模式异常检测,使用了K-NN算法与K-MLOF算法进行比较,结果如表2所示。

表1 原K-means及K-MLS的准确率及运行时间
实验表明,本文作者提出的点异常检测算法虽然在运行时间上与原算法不相上下,但其准确率提高了;模式异常检测算法在准确率对比其他算法也有较大的优势。实验最后,将点异常检测结果和模式异常检测结果合并,删除重复异常点,最终将能全面得到挤压机能耗异常序列。
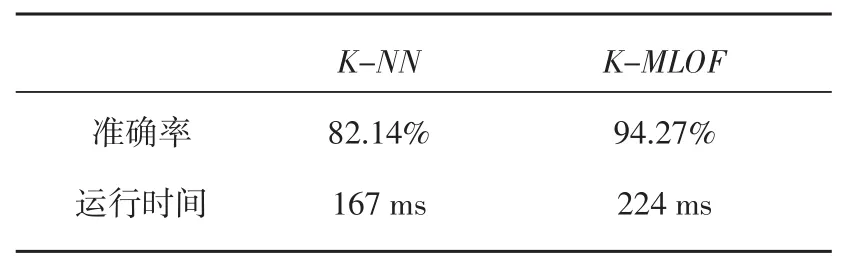
表2 K-NN及K-MLOF的准确率及运行时间
4 结论
针对挤压机生产能耗数据的异常特征和传统异常检测算法漏检率高、效率低的问题,提出一种基于时间序列和聚类的多层次异常检测方法。并采用华南某铝型材生产企业的挤压机能耗数据对其进行了验证。通过与现有异常检测算法的检测结果对比,验证了该算法的有效性和优越性。
