基于多任务结构稀疏表示的跟踪算法*
2018-09-27陈志国
王 琳, 陈志国, 傅 毅,2
(1.江南大学 物联网工程学院,江苏 无锡 214122;2.无锡环境科学与工程研究中心,江苏 无锡 214153)
0 引 言
近几年,伴随着稀疏表示在人脸识别[1]、图像恢复[2]和视觉跟踪[3,4]等领域的广泛应用,目标跟踪得到快速发展,并成为国内外热门研究课题[5~7]。在目标跟踪中利用稀疏表示求得线性表示系数后,根据重构误差最小确定最终的跟踪目标。研究人员提出了很多基于稀疏表示的生成模型跟踪算法[5,8]。Mei X等人[9]最早将稀疏表示引入到跟踪中,同时利用目标模板表示未遮挡部分和琐碎模板处理遮挡和噪声带来的问题,在一定程度上取得了很大的成功,但求解l1规范稀疏方程的计算量大。基于文献[9],Bao C等人[10]通过近端加速算法求解l1最小化问题来提高计算效率;Zhang T等人[11]提出了基于多任务联合稀疏模型的跟踪算法,利用l2,1规范解决求解l1规范稀疏方程计算量大的问题,并通过考虑粒子间的潜在关系提升跟踪的准确性;Jia X等人[12]将局部稀疏表示模型应用到跟踪中,该方法利用一系列的重叠图像块来表示目标区域的特殊空间布局结构,并通过实时更新模板,处理跟踪中的遮挡问题。
本文通过预先将每帧图像调整到固定尺寸,处理由于目标的快速运动所引起的模糊情况,并采用重叠分块构建结构稀疏的外观模型;利用l2,1规范最小二乘求解各图像块对应的稀疏编码系数,并利用对齐池算法提取多任务结构稀疏表示系数信息,判断候选样本与目标相似性。
1 多任务结构稀疏表示的目标跟踪算法
1.1 调整图像大小
基于粒子滤波的目标跟踪算法用变换参数控制跟踪中的搜索区域,如果跟踪区域很小,当目标发生快速运动时,算法很可能丢失目标。相反,如果跟踪区域很大,受到背景的干扰,算法易发生漂移。由于不同的视频图像的分辨率不同,利用绝对数量的像素作为单位来设置参数会得到不同的搜索区域。因此,本文提出根据视频的分辨率按比例调整参数,将视频图像重新调整为固定的尺寸。
1.2 多任务重叠分块稀疏外观模型
给定由N个目标模板组成的字典集T=[T1,T2,…,TN]∈Rd×N,将T中的每个模板进行分块处理,块数为K,相邻的块之间部分面积是重叠的,所有分块的组合构成一个包含N×K个模板的字典集D=[d1,d2,…,d(N×K)]∈Rd×(N×K)。同样,对n个候选样本X=[X1,X2,…,Xn]∈Rd×n进行重叠分块处理,每个分块对应一个新的样本,一个候选样本分块后为X1=[x1,x2,…,xK]∈Rd×K,每个候选样本的所有分块组成一个新的候选样本X=[x1,x2,…,xn×K]∈Rd×(n×K)。利用所有模板局部块线性组合编码所有候选样本区域的局部块,可得相应n×K个稀疏系数向量c1,c2,…,cn×K
(1)
式中C=[c1,c2,…,cn×K]为由各候选样本局部块的稀疏系数向量组成的对齐池;ci为对应于第i块的稀疏编码系数,含有N×K个元素。
在获得对齐池C之后,需要提取C中与目标相关的稀疏系数信息,进而判断候选样本与目标的相似性。如果候选样本与目标相似,那么其分模板对应的稀疏系数值将较大,其余分模板的值将较小;相反,稀疏系数值将不会集中在其对应的分模板上,而是分散到每个分模板。因此,候选样本对应的稀疏系数越大,成为最终跟踪结果的可能性越高。选取一个候选样本介绍提取结构稀疏表示系数信息的过程。C1=[c1,c2,…,cK]∈R(N×K)×K为候选样本X1=[x1,x2,…,xK]∈Rd×K的稀疏编码系数。
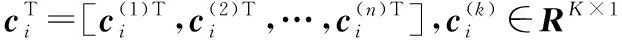
(2)
式中wi对应第i个分块,Γ为归一化项。
将Y1所有的局部块组合在一起以表示目标的整体结构,则各局部块对应的稀疏系数累加结果集为W=[w1,w2,…,wK]∈RK×K。如果候选样本与目标相似,那么W对角线上的值将较大;反之,则W中各元素没有规律。图1为对齐池中稀疏系数的提取过程。
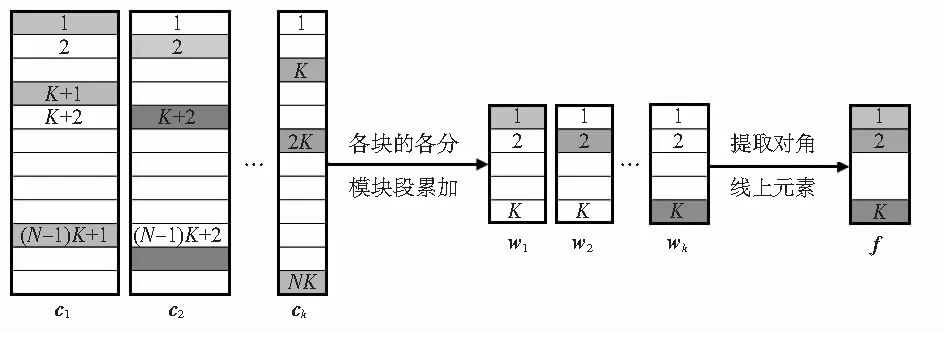
图1 稀疏系数信息的提取过程
提取矩阵W对角线上的元素作为结构稀疏表示的系数信息f=diag(W)。
1.3 算法实现
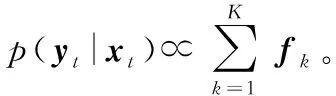
方程右边的部分根据提取的稀疏系数f,描述候选样本与目标的相似度。
2 实验结果
2.1 参数设置
实验中的测试视频和实验参数的设置固定不变,用于测试的视频由标准数据集Benchmark提供。实验是基于MATLAB R2013a平台,硬件配置为Intel Core i3 2.10 GHz,内存为2 GB的PC。粒子采样过程中的6个变换仿射参数设为[4,4,0.005,0.0,0.005,0]T。粒子滤波中粒子的数目决定了跟踪的效果,为保证跟踪准确性的同时降低计算复杂度,本文粒子数n=400,目标模板的个数N=20。l2,1优化算法中稀疏性限制参数λ=0.01,η=0.01,迭代次数Iter=5。将目标图片调整为固定大小宽240、高320,重叠分块数为9。
2.2 定量分析
本文算法在多任务跟踪(multi-task tracking,MTT)算法的基础上,融合带有重叠分块的结构稀疏表示和调整图像大小的改进算法。
实验1通过对比本文算法多任务视觉跟踪(multi-task visual tracking,MTVT)和MTVT-resize得出的实验结果,验证按比例将图像调整到固定大小在处理目标快速运动时的效果。图2为在Benchmark上得到的对应于快速运动因素的成功率和精度的比较结果,可见,未调整图像大小的MTVT-resize算法,取得的曲线下的面积(area under curve,AUC)值为23.7 %。采用调整图像大小之后结果提升到27.4 %。在精度图中,MTVT的值为32.4 %,去掉调整图像大小后,值降为28.1 %。实验1说明按比例将图片调整到固定大小,能够有效地处理视频中目标的快速运动。
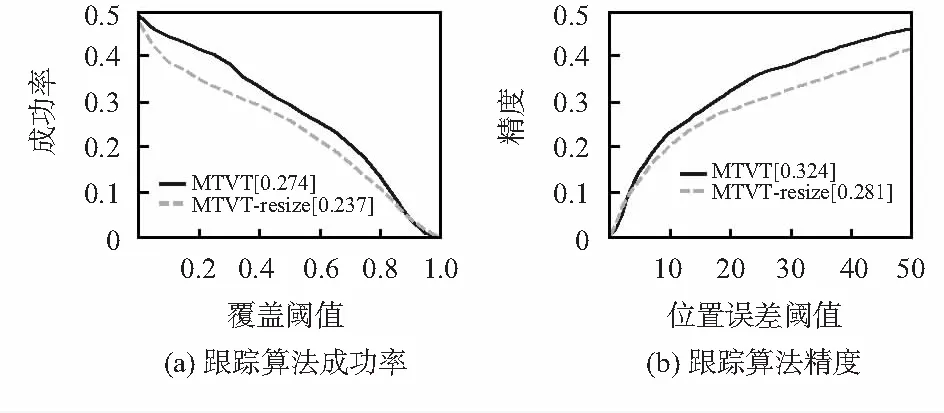
图2 调整图片大小对于快速运动的跟踪结果
实验2通过9个具有挑战性视频序列:car4,shaking,faceocc1,coke,boy,suv,freeman3,jogging —2和singer1,验证本文提出的MTVT算法的性能。测试视频中包含由于形态变化、光照、尺度和遮挡等因素引起的目标外观变化,给跟踪带来较大的困难。为了评估本文算法的性能,将本文算法MTVT与其他4种比较先进的算法进行比较,算法包括:增量学习视觉跟踪(incremental learning visual tracking,IVT)[4]、使用加速近端梯度的L1跟踪器(Li tracker using accelerated proximal gradient,L1APG)[10]、多实例学习(multiple instance learning,MIL)[3]和MTT[11]。上述跟踪算法的代码由Benchmark提供,且所有的跟踪结果可以通过相应网站获得。表1为5种跟踪算法在9个视频序列上跟踪的平均中心位置误差,其中,最好的结果用粗体字体标出,次好的结果用斜体字体标出,由表可知,在视频car4中,增量视觉跟踪(incremental visual tracking,IVT)算法获得了最好的效果,而MTVT的结果与其相近,同时,在其他8个视频中MTVT都取得了最小的平均中心位置误差。MTVT也取得了最好的平均值9.3,算法MIL取得了第二好的结果53.7,但远超于MTVT。
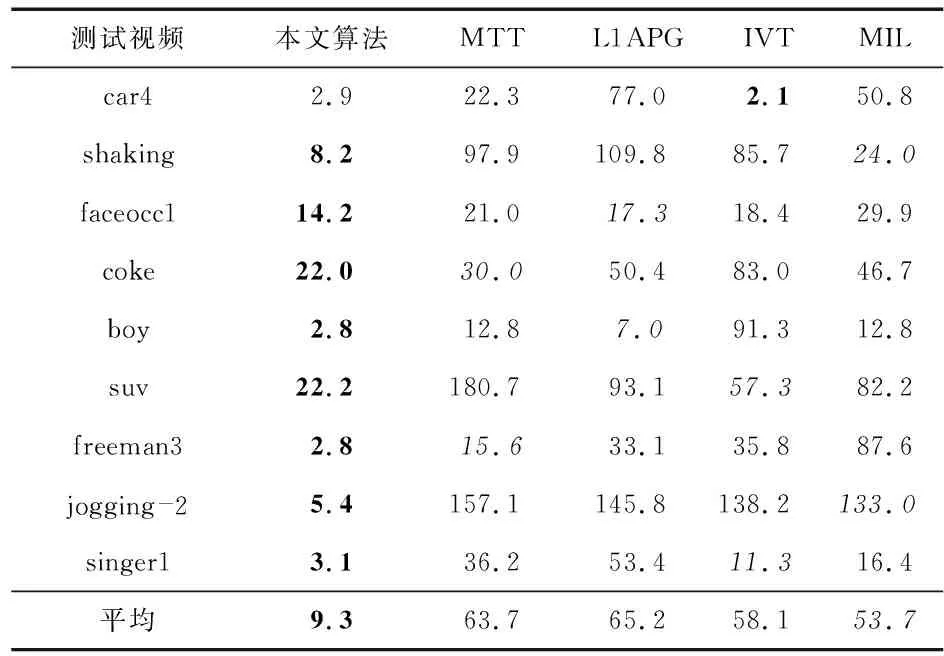
表1 跟踪的平均中心位置误差
表2为5种跟踪算法在9个视频序列上跟踪的平均覆盖率,其中,最好的结果用粗体字体标出,次好结果用斜体字体标出,可见,MTVT在视频shaking,faceocc1,boy,suv,freeman3,jogging —2和singer1中取得最大覆盖率,平均覆盖率为72 %。算法IVT在视频car4中取得了最好的结果,算法MTT在视频coke中取得了最好的结果,MTVT均为第二。
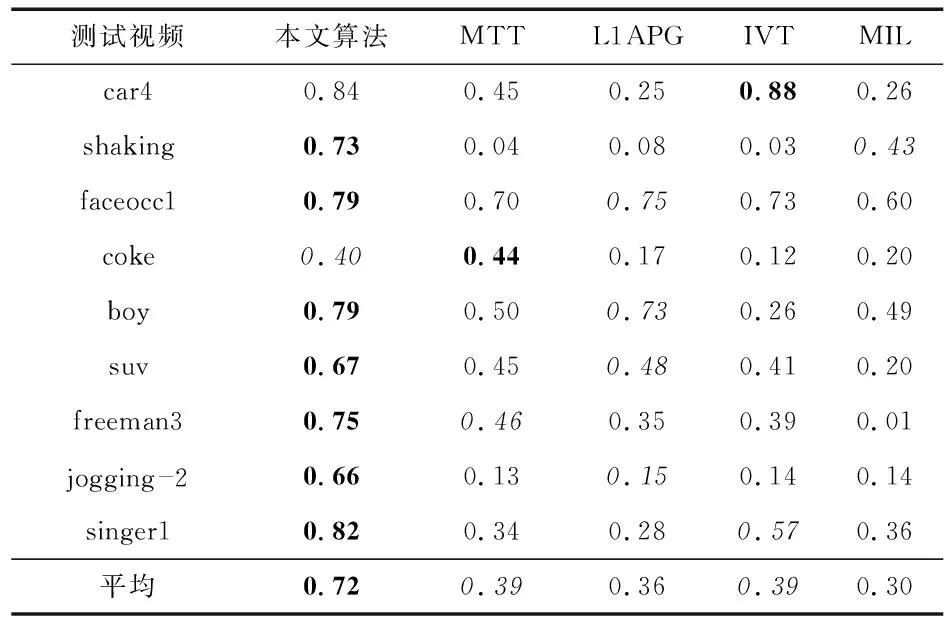
表2 跟踪的平均覆盖率
图3为Benchmark上得到的5种算法在51个具有挑战性的标准视频集上的成功率和精度的比较结果。从图3(a)可以看出,和其他的4种算法相比本文的MTVT算法获得了最好的实验结果。在图3(b)中MTT的结果为47.5 %,MTVT较其高2 %,获得第二好的成绩。算法L1APG和MTT,在图3中的结果分别为38 %,48.8 %和37.6 %,47.5 %。MTVT在图3中的结果分别为38.2 %(第一)和49.5 %(第二),均高于L1APG和MTT,表明本文提出的算法在一定程度上提高了跟踪的准确性,同时保证了跟踪的精度。
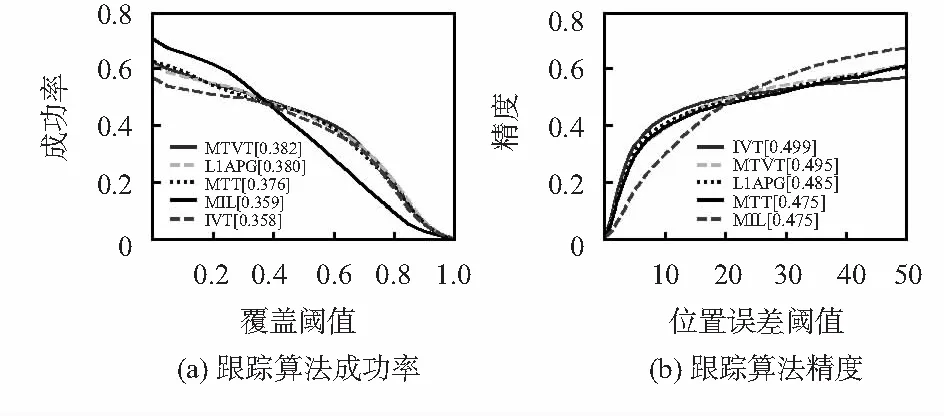
图3 各跟踪算法的成功率和精度
3 结束语
实验结果表明:提出的目标跟踪算法具有更强鲁棒性和更高的准确性。
