基于覆盖网络的空气质量评价模型研究
2018-09-23赵莎莎
李 萍,赵莎莎
1 引言
随着社会城市化、工业化的迅猛发展,空气污染问题越来越严重,影响空气污染的六大因素有SO2,NO2,O3,CO,PM2.5 以及 PM10[1-3].空气质量指数(AQI)从2012年上半年出台开始,近年来一直作为我国空气质量的评价标准.AQI即是根据空气质量标准,将六种空气污染物浓度简化为单一概念性指数值形式,根据AQI的值,将空气质量分为六个等级,分别为优,良,轻度污染,中度污染,重度污染和严重污染.然后不同国家的AQI计算细节方面存在着差异性,美国采用NowCast计算方法计算PM2.5与PM10分指数,能快速响应变化的空气质量状况,而中国对这两种分指数进行计算时使用的是24小时的平均值.不管是哪种方法,在对空气质量进行评价时都要通过与AQI的浓度限值参照表以及API的浓度限值参照表进行对比才能得出具体的等级值,操作较为复杂,而且,无法反映各污染物浓度之间的复杂关系.
因此,本文提出基于覆盖网络的空气质量评价模型,首先将不同时间点监测到的六种污染物浓度值投影到一个超球面上,把不同的时间点看成是不同的训练样本.其次,利用覆盖算法把这些样本点分成不同的覆盖,每个覆盖代表同等级的空气质量.最后,将测试样本投影的同一个球面上,通过计算测试样本的污染物浓度与训练样本污染物浓度之间的距离来判断测试样本的类别,即是空气质量等级.本文利用覆盖网络对阜阳地区的空气质量进行评价,得出较满意的结果.
2 覆盖算法
覆盖算法是由张铃等人提出,利用覆盖算法构造k分类的覆盖网络,即是一种构造性的神经网络学习算法,该方法旨在样本集S上寻找一组覆盖领域,使得每个覆盖中的样本点属于同一类别,这组覆盖领域能将不同类别的样本点分割开来[4].覆盖算法的主要思想[5]:首先,把训练样本投影到一个超球面上,其次,随机选择一个点作为中心点,根据样本点的分布,求出半径值,构造覆盖领域,使得该领域中的所有点属于同一个类别,将所有已被覆盖的样本点移除,继续构造新的覆盖,直到所有样本点均被覆盖领域覆盖住,这样就得到了一组覆盖,每一个覆盖相当于是一个神经元.
覆盖算法流程如图1所示.
3 基于覆盖网络的空气质量评价模型
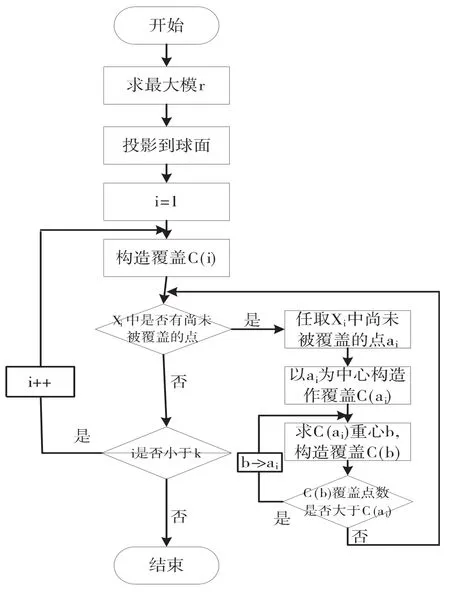
图1 覆盖算法流程图
本文从阜阳地区的空气质量历史数据中选出2016年6月1日到2017年5月31日的空气质量数据作为训练样本,把2017年6月1日到2017年6月30日的空气质量数据作为测试样本,通过覆盖算法,利用训练样本,得出空气质量评价模型.在该评价模型中空气质量共分为六个等级,分别是优,良,轻度污染,中度污染,重度污染和严重污染.通过训练得到模型的主要组成部分覆盖中心点以及覆盖半径,总共训练处129个覆盖,由覆盖的中心和半径构成.每个覆盖属于固定的类别.通过比较测试数据与各个覆盖的位置,对测试数据进行标记,如果测试数据位于某一覆盖内,那么被标记为与该覆盖相同的类别,如果测试数据位于所以覆盖的外部,则按照就近原则对其进行标记.得出测试结果如表1所示,其中r表示2017年6月1日到2017年6月30日的实际空气质量等级,t表示用本文提到的模型所得的这三十天的空气质量等级.由表1可知,对于三十天的空气质量等级进行比较,发现只有两天的空气质量等级不一致,但是差别不大,仅仅相差一个档次,实际是轻度污染,测出的结果是良.模型测出的其余二十八天的空气质量等级与AQI计算得到的实际空气质量等级完全一致.总之,利用本文所提供的方法对阜阳地区的空气质量进行评价,得出的评价结果与AQI的计算方法相比相似度极高,正确率可达百分之九十以上,避免了计算AQI的繁琐步骤.

表1 测试结果
4 结束语
本文提出基于覆盖网络的空气质量评价模型,通过将不同时间点监测到的六种污染物浓度值投影到一个超球面上,利用覆盖算法把这些样本点分成不同的覆盖,每个覆盖代表同等级的空气质量,通过计算测试样本的污染物浓度与训练样本污染物浓度之间的距离来判断测试样本的空气质量等级.本文利用覆盖网络对阜阳地区的空气质量进行评价,与AQI方法得出的空气质量极为相似,对空气质量评价具有一定的实际意义.
