基于聚焦爬虫的搜索引擎的设计与实现
2018-09-21赵建华蒋劲松
赵建华,蒋劲松
(商洛学院 数学与计算机应用学院,陕西 商洛 726000)
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎[1-2]是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,并将用户检索的相关信息展示给用户的系统。然而,这些通用性搜索引擎也存在着一定的局限性[3-4],如下所示:
(1)不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
(2)通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
(3)万维网数据形式的丰富以及伴随着网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
(4)通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择地访问万维网上的网页与相关链接,获取所需要的信息。与通用爬虫不同,聚焦爬虫并不追求大的覆盖,而是将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源[5-7]。
本文设计并实现了一种基于聚焦网络爬虫的搜索引擎。采用Java服务端网页(JSP)技术来开发用户界面,MyEclipse 作为开发设计平台,Tomcat6.0 作为系统服务器,MySQL作为系统数据库。通过聚焦爬虫获取网站数据并建立索引数据库,为用户提供一个方便的信息检索工具。该引擎可以实现网站数据搜索、关键词分析等功能。
1 系统设计
设置了2个角色,分别为普通用户和数据库管理员。普通用户可以实现网页搜索、图片搜索等功能;数据库管理员可以实现网络爬虫和数据库的管理,通过网络爬虫获取网站数据并建立索引数据库等功能。系统功能模块如图1所示。
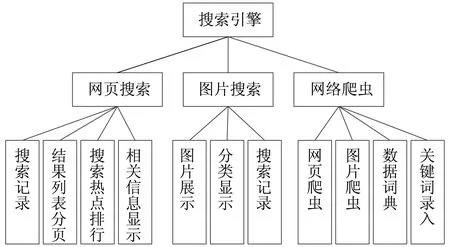
图1 系统功能模块Fig.1 System function module
1.1 普通用户
普通用户可以实现网页搜索、图片搜索等功能。用户在输入关键词后点击搜索按键或者回车,跳转至结果页面。如果程序发现的网站符合用户的要求,就会根据网页中关键字的位置、出现次数计算出每个网页的排名,最后按排名的顺序返回给用户。普通用户也可以实时更改搜索要求。用户获取结果后,可以点击任意链接跳转到相应的网页。普通用户模块流程如图2所示。
1.2 数据库管理员
数据库管理员主要完成网络爬虫和数据库的管理。数据库管理员模块流程如图3所示。数据库管理员界面显示一些系统基础数据,如数据数量和用户数量等。若数据库管理员想要查看网页数据,则点击网站数据菜单项下的数据列表,即可获取全部网页数据。
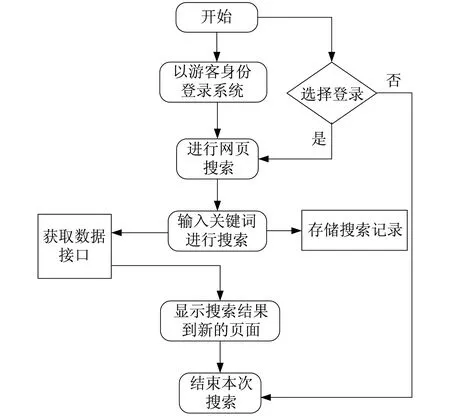
图2 普通用户模块流程Fig.2 Flow chart of ordinary user module
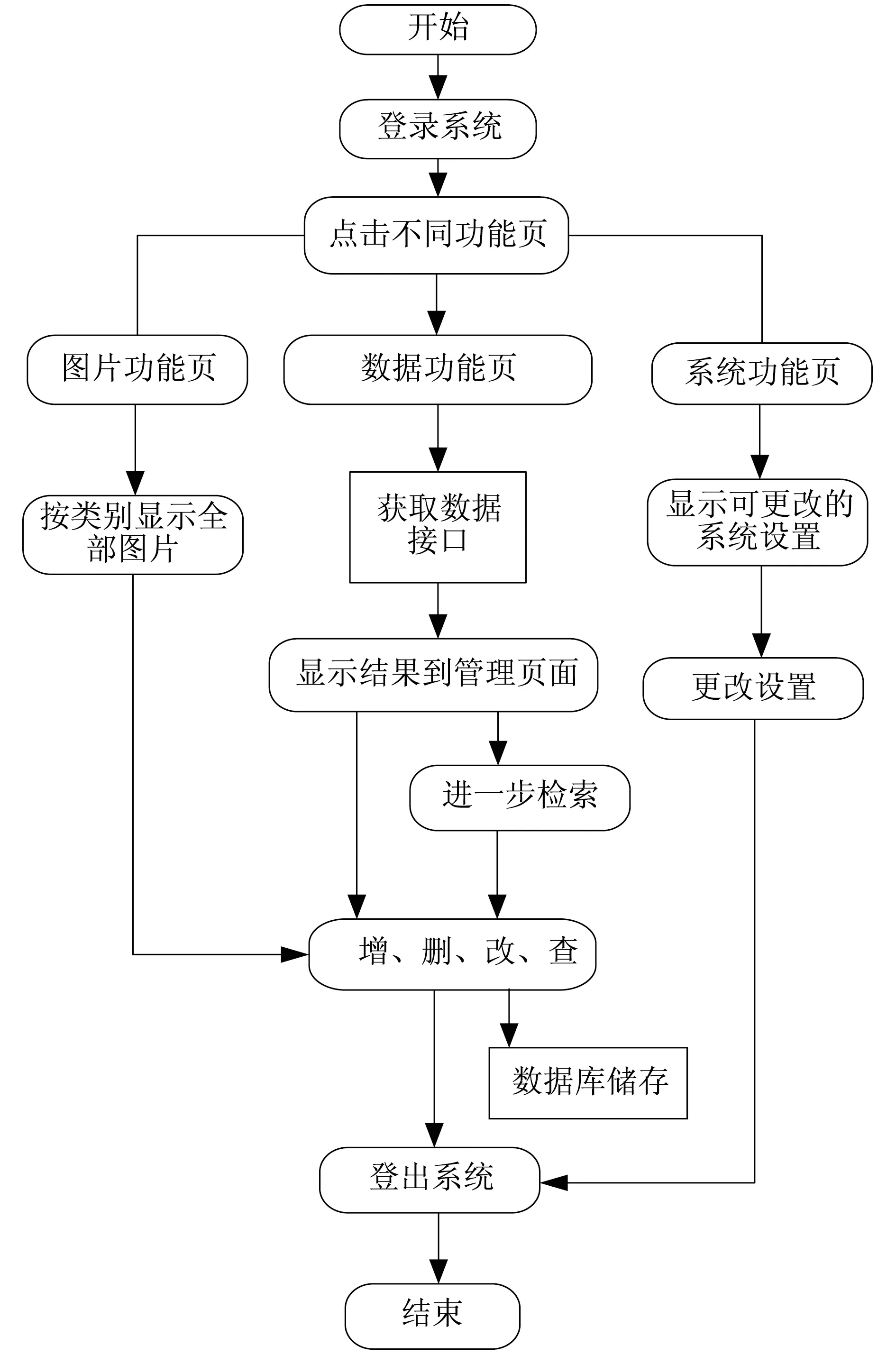
图3 数据库管理员模块流程Fig.3 Flow chart of database administrator module
1.3 网络爬虫
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统网络爬虫从一个或若干个初始网页的统一资源定位地址(URL)开始,获得初始网页的URL。在抓取网页的过程中,不断从当前网页抽取新的URL放入队列,直到满足系统的一定停止条件。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,根据一定的搜索策略从队列中选择下一步要抓取的网页的URL。重复上述过程,直到达到系统的某一条件时停止。聚焦爬虫爬取过程的数据流如图4所示。

图4 爬取过程的数据流Fig.4 Data flow of crawling process
本搜索引擎的爬虫程序采用聚焦爬虫编写,优点是可以选择性地爬取那些与预先设置好的关键词序列相关的网页[8-9]。爬虫程序源码部分由Python语言编写,编写的软件是PyCharm。爬虫实现过程的部分关键代码如图5所示。下载网页部分代码如图6所示。

图5 爬虫代码Fig.5 Code of the crawler

图6 下载网页部分的代码 Fig.6 Code of downloading page part
2 系统实现
2.1 用户功能实现
用户在访问系统后就可以看到首页界面。首页采用简单的结构设计,直接向用户提供本系统的核心功能——网页搜索。系统首页如图7所示。

图7 首页Fig.7 Home page
搜索结果的显示包含左侧信息栏、中间搜索结果列表和右侧搜索热点列表等内容。
(1)左侧信息栏
在页面的左侧放一个栏目用于提示用户搜索结果的一些细节,除了显示当前关键字外,还有相关关键词,点击即可访问相关页面。左侧信息栏如图8所示。

图8 左侧信息栏Fig.8 Left information column
(2)中间搜索结果列表
如图9所示,中间搜索结果列表和市面上的搜索引擎一样,每条结果都由三部分组成,分别是标题、简要介绍和修改日期(网站被爬取的日期)。

图9 中间搜索结果列表Fig.9 Middle part search result list
(3)右侧搜索热点列表
在热点搜索里,每个关键词都有一个搜索指数。每当有人搜索该关键词时,指数就会上涨。页面直接输出数据库里按搜索指数排名前10的记录,如图10所示。

图10 右侧搜索热点列表Fig.10 Right search hot spot list
2.2 数据库管理员功能实现
由于系统的管理后台作为前台的铺垫和延伸,因此在后台管理界面上设计了数据查询以及分类搜索等功能,针对不同权限的数据库管理员提供不同的数据查看与修改方式。数据库管理员的欢迎界面如图11所示。
数据库管理员后台的功能模块可以简单地分为数据管理和用户管理,数据管理模块又可以分为图片管理和爬虫管理2个部分。
(1)图片查询页面
图片数据按类别存放到不同的文件夹下,被数据库管理员检索的时候先按编号排序显示在列表中,支持多列排序功能。点击类别标签可进入图片展示页面,该页面可浏览该类别下的所有图片。在图片展示页面,所有图片被平铺在页面上,可以点击单个图片放大查看,也可以批量删除图片。图片浏览列表如图12所示。
(2)爬虫管理
在关键词管理模块中,关键词的来源有以下2个:一是由用户搜索时添加,二是在爬取网页的过程中写入数据库。数据库管理员可以实时管理每个关键词,或者自行添加关键词,关键词的排行是实时变动的,用户搜索某个关键词的次数越多,排名就越靠前。关键词排名列表如图13所示。
3 结语
本文介绍了基于聚焦爬虫搜索引擎的实现过程。该系统实现了网页搜索、图片搜索以及热点搜索排行等功能。通过大量测试,系统运行良好,具有较好的用户体验。

图11 管理后台主界面Fig.11 Main interface of management backstage

图12 图片浏览列表Fig.12 Picture browsing list
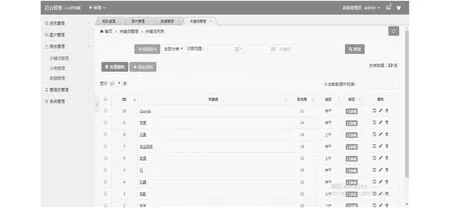
图13 关键词排名列表Fig.13 Keyword ranking list
