一种双LSTM结构的图像多标签分类方法
2018-09-20胡伏原沈军宇
吕 凡,胡伏原,沈军宇,孙 钰
(苏州科技大学 电子与信息工程学院,江苏 苏州 215009)
近年来,图像多标签分类获得了许多学者的关注。传统的多标签分类算法分为两种[1],分别是问题转换法和算法适应法。其中问题转换法将多标签问题转化为单标签问题进行计算,例如Binary Relevance算法[2]和Classifier Chains算法[3],等等;算法适应法将已有的单标签分类算法应用到多标签分类问题上,例如多标签k-NN算法[4]和多标签决策树算法[5]。目前,针对图像多标签分类问题,基于深度学习的方法受到广泛关注,其中基于CNN的方法和基于CNN-RNN的方法取得了较好的效果。CNN方法通过卷积神经网络[6](Convolutional Neural Network,CNN)提取图像中的高维特征,直接利用传统分类器对特征进行分类。Gong等人[7]基于CNN构建了一个配准排序的top-k的目标函数,优化后可以使得正样本的排序高于负样本,从而进行分类。Wei等人[8]提出了一种基于图像子区域的方法,将图像分解为多个包含单标签的子区域以简化多标签问题。CNN-RNN方法借助循环神经网络[9](Recurrent Neural Network,RNN)的序列处理能力将图像的多标签分类问题看作是一个序列生成问题。Wang等人[10]利用LSTM解析从CNN中提取的图像特征,生成相关的图像多标签序列。Liu等人[11]通过正确的标签来规则化CNN的参数,并采用CNN的预测值初始化LSTM进行标签序列生成。上述CNN-RNN方法中,其前提在于将图像的多个标签看作是具有一定规则的序列。
Jin等人[12]提出了在CNN-RNN结构中,多标签预测结果和标签的顺序具有密切关联,并验证了采用不同的标签顺序将会改变预测的效果。但由于图像的多个标签是并列的关系,并不存在具体的前后顺序,从而无法确定绝对合适的标签序列。仅采用一种设定的顺序使得标签容易在RNN的迭代过程中丢失,无法保证预测到全部标签。例如,构建CNN-RNN结构对图1所示图像进行多标签预测,采用从左至右顺序的预测结果为“sofa,bottle,plant,tv”,采用从远至近顺序的预测结果是“tv,chair,sofa”,二者分别丢失了标签“chair”和标签“bottle,plant”。

图1 按照不同顺序预测的标签(括号内代表缺失的标签)
笔者针对CNN-RNN方法中采用单一标签顺序而导致预测效果不足的问题,提出了一种双LSTM的方法CNN-BiLSTM。该方法在CNN-RNN的基础上,构建两个LSTM序列生成模块,通过不同的序列规则生成预测标签序列。考虑到虽然两个LSTM的标签顺序不同,但是标注的内容应当是一致的,通过均方误差缩小由不同序列规则生成标签的差异。最终,通过结合两个LSTM的标签预测结果减少标签的丢失,从而得到最终的预测标签。通过在PascalVOC2007数据集上的实验验证了提出方法的有效性。
1 双LSTM图像多标签分类方法
1.1 问题描述
将图像的多标签分类问题定义为一个标签序列生成问题,以预测出给定图像所有可能的标签。给定图像训练集 X={x1,x2,…,xN}和对应的标签 Y={y1,y2,…,yN},其中 N 代表训练图像的数目。第 i张图像 xi对应的标签是 yi={yi1,yi2,…,yiC},其中 C 代表标签数目;yij=1 代表图像 xi包含标签 j,否则 yij=0。文中构建端到端的模型,学习从图像到标签的映射h:X→Y。测试时,给定一张图像,通过映射h预测出图像对应的多个标签。
1.2 双LSTM的构建
文中设计的双LSTM方法CNN-BiLSTM,其模型框架基于CNN-RNN的模型结构。文中方法服从“编码器-解码器”(Encoder-Decoder)设计模式,通过这种模式可以学习从一种表征方式到另一种表征方式的转化方法。编码器部分利用CNN从所给图像中提取图像的高维特征,并在解码器中利用RNN对特征进行解码生成相关的图像标签序列。模型结构如图2所示。
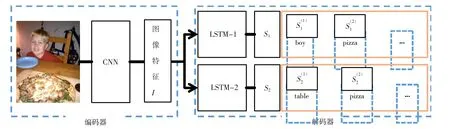
图2 双LSTM结构的图像多标签分类方法
基于CNN-RNN结构,模型中将图像的多个标签看作是一种序列。文中首先利用CNN从图像中提取出特征I。为了充分利用深度神经网络的特性,采用从最后一层全连接层提取特征。RNN部分构建双LSTM结构,其中每一个LSTM对图像按照不同标签序列进行预测。RNN经常应用在序列的生成等任务[13],LSTM[14](Long-Short Term Memory)是 RNN 的变种结构,如图3所示。在RNN的基础上,LSTM加入了三个控制门,即遗忘门、输入门和输出门,分别来控制是否遗忘当前的状态,是否获取当前的输入信息以及是否输出当前的状态。这三个控制门使得LSTM在长短期的序列记忆中都能够有较好的表现,并且使得模型更易于优化。参照文献[15],文中的LSTM的前传流程可以表示为
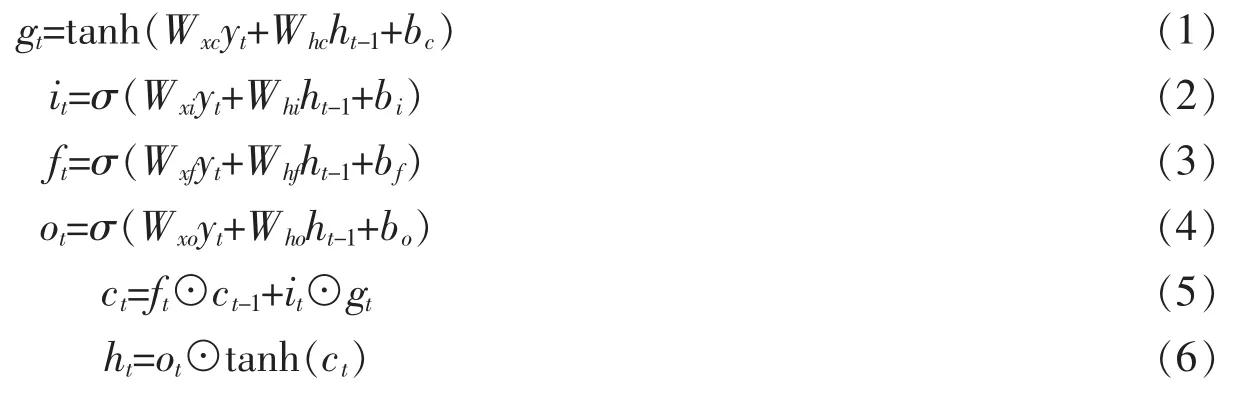

图3 LSTM的单元结构
其中所有的W和b都代表待训练参数,yt代表t时刻的输入。it,ft和ot分别代表了LSTM中的输入门、遗忘门和输出门。ct和ht分别表示了LSTM的记忆单元和隐藏状态。σ(x)=1/(1+e-x)为sigmoid激活函数。
文中在传统的CNN-RNN的基础上设计了双LSTM的结构CNN-BiLSTM。如图2所示,通过CNN解析出图像特征I之后,解码器中构建独立的两个LSTM结构LSTM-1和LSTM-2,同时接受来自CNN的图像特征。在此过程中,对输入到LSTM中的每一个标签进行相同的Embedding操作

其中,ek=[0,…,0,1,0,…,0]是第 k 个标签的 one-hot编码形式,说明图像包含标签 k,其中 ek[k]=1;UE代表Embedding矩阵。通过LSTM单元运算之后,在预测下一个单词的时候,对LSTM的隐藏状态进行计算,得到当前过程预测的标签

1.3 模型训练
模型在LSTM的每一步预测都会计算一个局部损失,即考虑预测的标签和LSTM规定采用的序列顺序中出现的标签一致。因此,文中对LSTM-1和LSTM-2分别计算其对数似然运算,得到各自的损失函数L1(i)和

在此基础上,LSTM-1和LSTM-2虽然采用的不同序列规则生成多标签图像的预测,但是其本身对应的是同一张图像,因此,生成的标签序列虽然顺序不同,但应当内容一致。例如,针对图2中的图像,预测的顺序可能是“男孩、披萨、桌子”也可能时“披萨、男孩、桌子”,但是表现的内容是一致的。因此,文中构建了损失函数L3,来缩小二者之间的差异

综上,构建最终的损失函数L

2 实验结果与分析
2.1 数据集与实验设置
文中采用了图像多标签数据集PascalVOC2007[16]对所提算法进行验证。PASCAL Visual Object Classes Challenge(Pascal VOC)数据集被广泛使用在图像多标签分类和语意分割等领域。数据集包含5 011张训练图像和4 952张测试图像,共包含20个类。
所提方法中,CNN部分采用VGG-16[17]的网络结构,并从其最后一个全连接层fc_7提取图像特征。VGG-16的参数采用在ImageNet大规模单标签数据集上将预训练的参数进行初始化。文中,LSTM-1和LSTM-2的隐藏状态和记忆单元的大小都设为512。为了方便预测,在预测的文本序列中,插入了独立的开始标签
文中的对比方法包括 INRIA[18]、FV[19]、CNN-SVM[20]、I-FT[8]、HCP[8]、CNN Multi-label以及 CNN-RNN。文中的双LSTM方法CNN-BiLSTM中两个LSTM采用了不同的标签序列规则。文献[12]中的分析,采用四种不同的多标签序列规则,分别是:(1)高频排序(Frequency),按照数据集中各个标签出现的频率从高到低排序;(2)低频排序(Rare),按照数据集中各个标签出现的频率从低到高排序;(3)字典排序(Dictionary),按照各个标签的单词首字母的在字典顺序排序;(4)随机排序(Random),按照随机顺序排序。
文中构建的CNN-BiLSTM中的两个LSTM分别采用高频和低频的顺序进行标签的预测。
2.2 实验结果与分析
实验结果见表1。文中提出的CNN-BiLSTM方法达到了85.4%的mAP(mean Average Precision),并且在标签 “table”、“dog”、“person” 和 “tv” 上取得了最好的效果。对比方法中,HCP-2000C取得了近似的结果85.2%,但该方法将图像分割为多个子区域,并在训练中引入额外的2 000个类信息提高训练效果,效率较低且依赖于子区域的提取效果。在CNN-RNN的方法中,采用高频排序(84.7%)和低频排序(84.9%)取得的效果要明显好于字典排序(84.1%)和随机排序(83.8%),说明了标签的顺序对结果具有较大影响。文中提出的CNN-BiLSTM的两个LSTM分别采用高频和低频的排序方式,结合两种序列规则,最终的结果高于单独采用二者的结果,这证明了文中提出算法的有效性。如图4所示,采用文中的CNN-BiLSTM结构进行预测,对每一张图像分别列出了其LSTM-1、LSTM-2、最终预测Pd和真实标签Gt。尽管LSTM-1和LSTM-2预测的结果可能不同或者不全部正确,但是通过融合二者的预测结果,可以使得最终的预测结果更加准确。
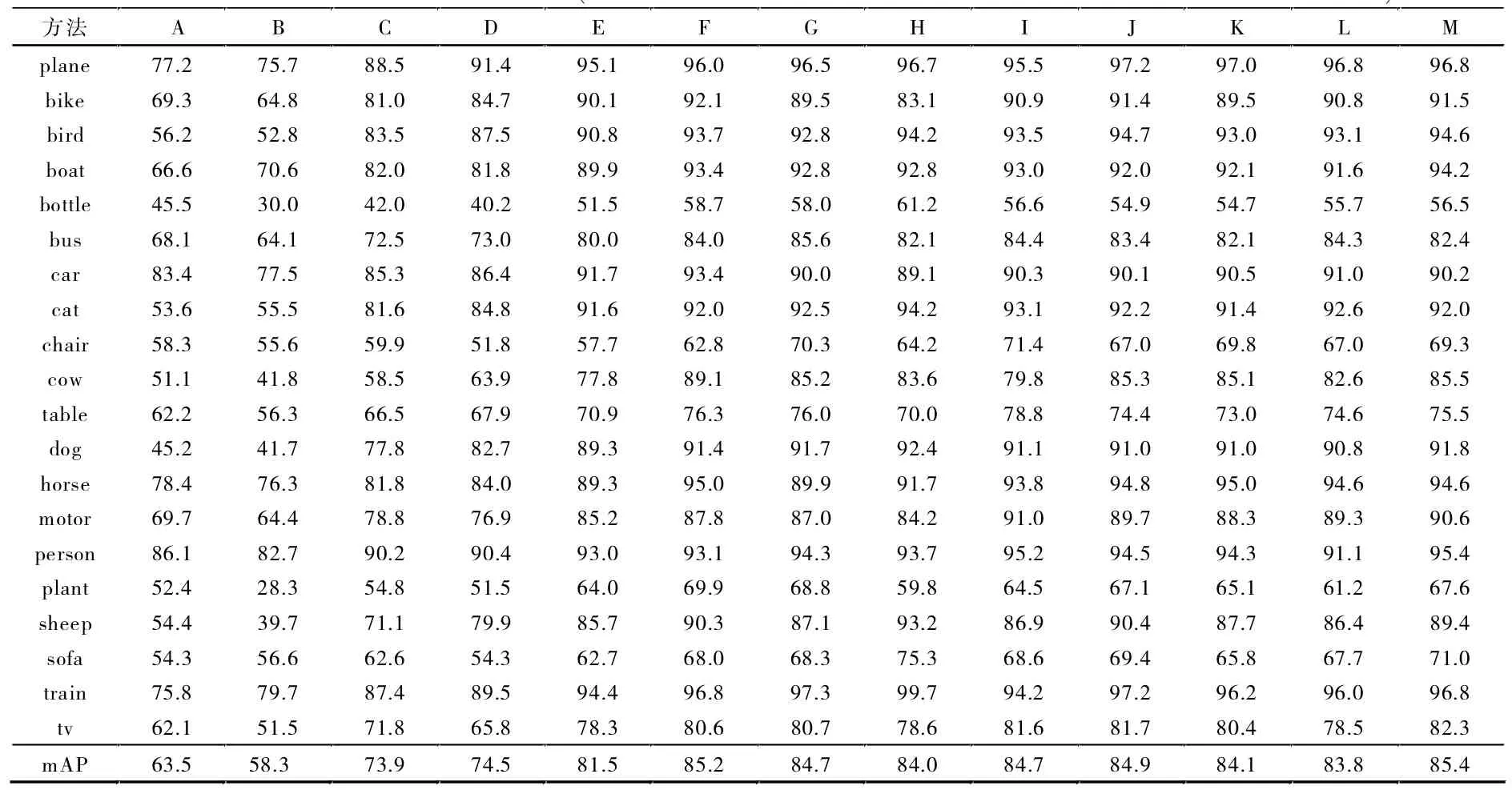
表1 在VOC 2007上的实验结果(包括每一个类的平均精度AP和所有类别的均值平均精度mAP)

图4 在Pasocal VOC 2007上的预测图例
3 结语
笔者提出了一种双LSTM的图像多标签分类方法CNN-BiLSTM,该方法在CNN-RNN的基础上,同时考虑不同序列顺序的预测方式,构建了两个独立的LSTM分别按照不同的标签顺序规则预测。实验证明,该方法能够有效提高传统CNN-RNN的效果,提高了只考虑一种标签顺序情况的效果。
