基于用户的协同过滤推荐算法的改进
2018-09-20陈垲冰吴明芬
陈垲冰,吴明芬*
(五邑大学计算机学院,广东江门,529020)
引言
随着互联网的快速发展,人们每天都和巨量的数据打交道。如何让用户快速找到自己想要的信息,在此背景下,推荐系统应运而生,推荐系统是根据用户的历史行为,例如购买过哪些商品来学习该用户的兴趣和爱好,然后根据兴趣和爱好给用户推荐相应的商品。推荐系统(Recommender System),作为一种有效的信息过滤系统,它能够帮助用户在大量数据中准确地找到其感兴趣的信息,成为研究者们广泛关注的对象[1]。
目前推荐系统分为以下几类:基于内容(Content-based)的推荐系统、协同过滤(Collaborative filtering)系统以及混合(Hybrid)推荐系统[2]。“协同过滤”一词最早由 Goldberg中提出[2]。目前协同过滤算法的使用非常广泛,其分为基于用户的协同过滤算法和基于项目的协同过滤算法。陈思思通过把协同过滤推荐算法应用于高校图书馆,根据读者的历史借阅记录学习读者的兴趣爱好,从而为读者提供个性化的服务[3]。文献[4]把基于用户的协同过滤推荐算法运用于 MOOC(Massive Open Online Course)在线课堂,根据用户历史行为和注册信息为其推荐合适的资源。任磊提出一种有合评分时间特性的推荐系统,从评分时间角度对推荐算法的相似度计算和评分预测过程进行改进[5]。基于用户的协同过滤算法虽然考虑了用户(项目)间的关系,但是却忽略了用户之间可能存在潜在的关系,导致推荐算法准确率不高,本文提出一种改进的用户协同过滤算法,该算法充分利用了用户地理位置这一属性。改进的用户协同过滤算法具体工作原理:首先根据用户所购买的商品求出用户之间的相似度,接着根据用户的地理位置计算用户位置之间的相似度,然后把二者加权求和,实试有有表明,改进后的用户协同过滤推荐算法提高了推荐的准确率。
1 基于用户的协同过滤算法
基于用户的协同过滤推荐算法首先通过用户购买记录来组成用户-商品表,根据用户-商品表来计算用户之间的相似度,在两个用户购买的商品记录中,若他们所购买相同的商品记录数量越大,则他们的相似度越高,根据相似度从高到低选出相似度最大的N个用户作为该用户的邻居,在给该用户推荐商品时,通过邻居用户购买记录给其推荐商品,这些商品存在在邻居购买记录中并且该用户尚未购买过。计算相似度选用的是Jaccard算法。 Jaccard相似度公式如下:
其中代表用户A所购买的商品的数量,代表用户B所购买的商品的数量,表示用户A和B的相似度,分子表示用户A和用户B购买的商品中相同商品的数量,分母表示用户A与用户B非重复购买商品的数量。
基于用户的协同过滤推荐算法分为三个部分:第一部分相似度的计算、第二部分选取商品的邻居商品、第三部分产生推荐。算法的具体步骤如下:
第一步:相似度计算
(1)找出所有购买过商品的用户id,并放入到一个用户id的集合中
(2)从用户id集合中取出一个用户A的id,在用户-商品表中找出用户 A所有购买商品的id,并放入集合itemList中。
(3)执行步骤2,取出除用户A以外的另一个用户B的id和得到其购买商品id 的集合。
(4)运用Jaccard算法对两个商品集合进行相似度的计算。
(5)循环执行步骤 2,3,4,遍历完用户 id集合中除了用户A的所有用户,计算出其他用户和用户A的相似度。
第二步:选取邻居商品
(6)对用户A和其他用户的相似度按照降序的顺序排序。
(7)选择相似度最大的N个用户id作为用户A的邻居用户,并写入数据库。
(8)重复执行步骤2~7,计算其他用户之间的相似度和找出他们的邻居用户。
第三步:产生推荐
(9)通过输入的用户id找出该用户的邻居用户,放入NeighborList集合中。
(10)在NeighborList中取出一个邻居用户id。
(11)根据邻居用户id在用户-商品表中找出该用户所有购买过的商品id,并放入shopList集合中。
(12)在shopList集合中遍历所有的商品id并查看该商品id是否存在用户A所购买商品id的集合中,存在则跳过否则把该商品id放入 recommendList中。
(13)重复执行10~12,把用户A所有邻居用户购买过的商品但是用户 A并没有购买过的商品放入到recommendList中。
2 改进的用户协同过滤算法
用户协同过滤算法根据用户所购买的商品可以计算出用户之间的相似性,相似性越大说明两用户之间的兴趣和爱好越相同,但是该算法只是通过用户(商品)之间这一单一维度来计算用户相似性。为了克服以上问题,本文提出了一种改进的用户协同过滤算法,该算法对上面算法的第一部分求用户相似度时进行改进,在计算用户之间的相似度时分为两步,第一步是根据用户-商品协同过滤算法来计算相似度,第二步是根据用户地理位置来求用户之间相似度,然后二者线性相加。其公式为:
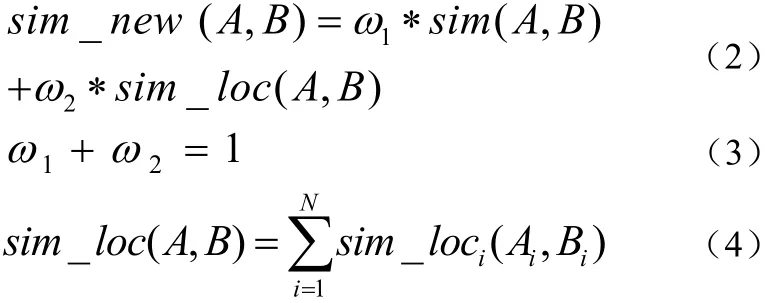
sim_new(A,B)表示改进后用户之间的相似度,sim(A,B)表示上文叙述的用户协同过滤算法的相似度,
sim_loc(A,B)表示用户位置相似度。表示基于用户协同过滤算法相似度的权重,表示基于用户位置相似度的权重。表示的是用户A与用户B地理位置信息第i位字符的相似度。
改进的用户协同过滤推荐算法充分利用了用户地理位置这一属性,该算法也是由三个部分:第一部分是相似度的计算,第二部分选取用户的邻居用户,第三部分产生推荐。其中对第二部分进行改进,在求相似度时考虑了用户地理位置这一因素,具体过程:a.是通过用户购买历史记录来计算用户之间的相似度;b.是通过用户的地理位置信息来计算用户自身属性的相似度;c.是对前面两步a和b的有有进行加权得到用户之间最终的相似度。其a中的相似度的计算和基与用户的协同过滤推荐算法的相似度计算一致。改进求相似度的具体操作步骤如下:
第一步:通过用户购买历史记录来计算相似度
(1)找出所有购买过商品的用户id,并放入到一个用户id的集合中
(2)从用户id集合中取出一个用户A的id,在用户-商品表中找出用户 A所有购买商品的 id,并放入集合itemList中。
(3)执行步骤2,取出除用户A以外的另一个用户B的id和得到其购买商品id 的集合。
(4)运用Jaccard算法对两个商品集合进行相似度的计算。
(5)循环执行步骤2,3,4遍历完用户id集合中除了用户A的所有用户,计算出其他用户和用户A的相似度。
第二步:通过用户的地理位置信息来计算用户自身属性的相似度
(6)在用户-位置表中找出用户A与用户B的地理位置n位长的字符串。
(7)对用户A和用户B的地理位置字符串从第一个位置开始逐个位置进行匹配,若相同,则地理位置相似度加上1/n,否则跳出循环比较,并返回最终相似度。
(8)重复执行步骤6,7计算出用户A和其他用户之间的地理位置相似度。
第三步:加权求和计算最终相似度
(9)对步骤一和步骤二的有有进行加权得到用户之间最终的相似度
求用户的邻居用户和产生推荐和改进前的基于用户的协同过滤算法一致在此不做过多的叙述。
3 实试有有及分析
3.1 实验设计
本文采用的是天池大数据平台的Ali_Mobile_Rec数据集 (https://tianchi.aliyun.com/datalab/dataSet.htm?
spm=5176.100073.888.16.7f4272cbynGnvG&id=4),该数据集是淘宝平台上用户一个月的行为的轨迹,采用前24天数据作为训练数据,后6天数据作为测试数据。数据中包含用户id,商品id,商品类别,用户行为,用户地理位置和时间等字段。经过预处理后得到4574位用户,截取用户位置字符串前4位字符为用户地理位置信息,在实试过程中根据经试值设置使用Myeclipse+Mysql平台进行实试。
3.2 评判指标
本文性能主要采用准确率(Precision)来衡量改进前的算法和改进后的算法。推荐准确率表示算法推荐成功的比率[6]。其的公式为:
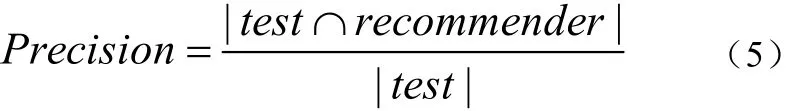
其中test表示测试数据中用户购买的商品,recommeder表示推荐给用户的商品。
3.3 结果分析
由表1和图1,图2可以看出,在邻居数和推荐数一致的情况下,改进后的推荐算法明显比传统用户协同过滤算法准确率高,说明基于用户协同过滤的改进算法是有效的,同时还可以看出推荐算法的准确率随着邻居数和推进数的应化而应化。当邻居数不应时,推荐的准确率随着推荐数的增加而提高,推荐数为20时,准确率达到最高。
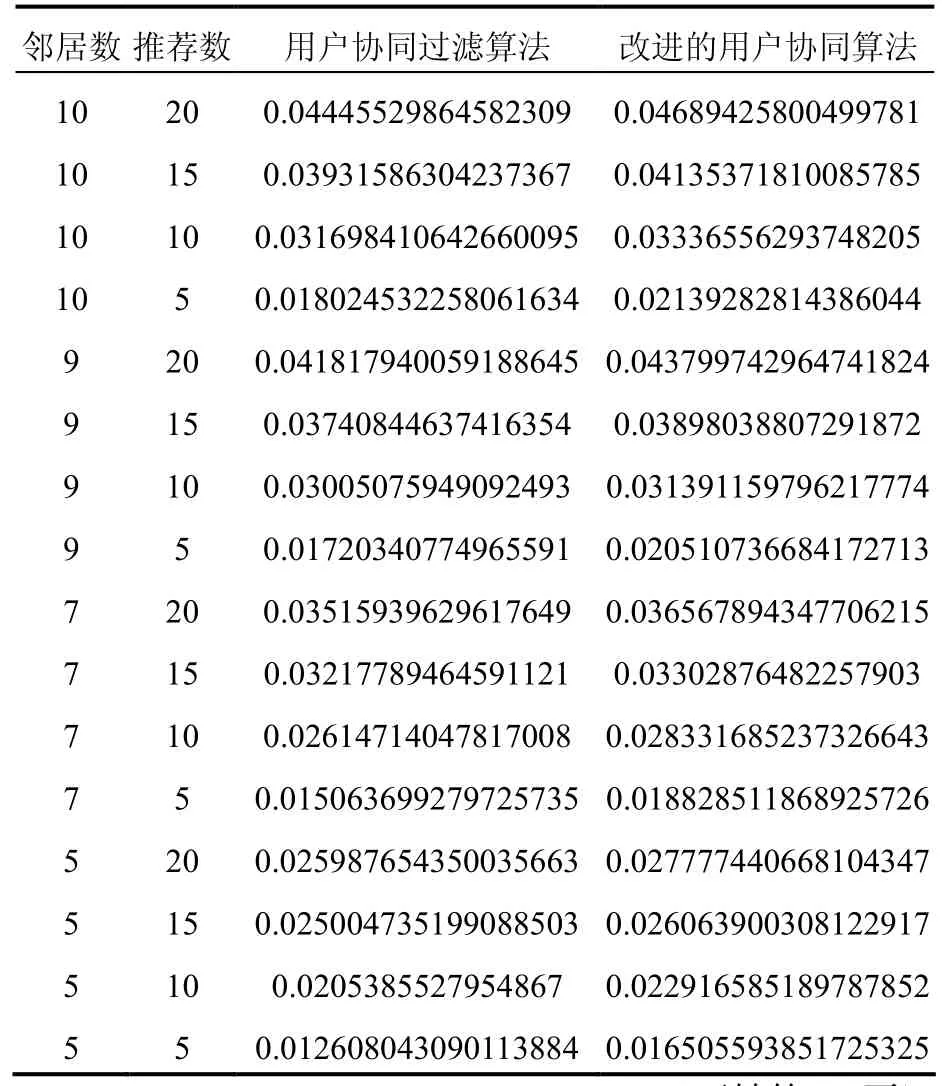
表1 准确率对比Tab.1 Precision comparison
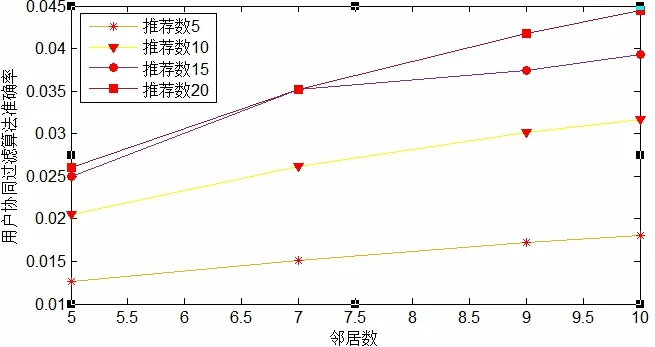
Fig 1 The accuracy of user collaborative filtering algorithm图4 用户协同过滤算法准确率
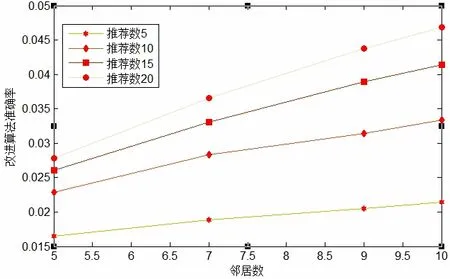
Fig 2.The accuracy of user collaborative filtering algorithm after improved图5 改进的用户协同过滤算法的准确率
4 有束语
用户协同过滤推荐算法是根据用户-项目(商品)的行为来计算用户之间的相似度,项目是连接用户之间的桥梁。本文在此基础上对传统的用户协同过滤算法进行了改进,在计算用户相似度时,把用户的位置信息考虑进去,用户相似度由用户-项目矩阵表和用户位置信息来一起决定,通过实试证明该改进的算法提高了准确率,同时也说明了用户的偏好具区域性[7],该改进的算法具有一定的实际意义。当然,改进后的算法仍然存在一定的不足,例如目前该算法还没能考虑到用户购买商品的时间,对位置信息的算法相对较简单。在今后的工作中仍需进一步改进。
