油气田智能视频报警系统设计与实践
2018-09-20刘湃耿玉广马彪王宇蒙田彦林张巍赵立庆
刘湃*,耿玉广,马彪,王宇蒙,田彦林,张巍,赵立庆
(1.中国石油华北油田分公司工程技术研究院,河北任丘,062552;2中国石油华北油田分公司第一采油厂,河北任丘,062552)
引言
目前油气田视频监控系统主要是在油气田生产环境架设数字高清摄像设备,或者是更高端的全景高杆智能监控系统,在监控画面中将采油场地进行工作周界虚拟标定成为警戒区域,并将采集的现场图像经由宽带传输传送到管理中心,通过根据油气田生产环境特制的智能视频分析软件管理调度,管理人员对整个油区周边场所进行全方位自动/手动监控,以立体空间监视厂区周围及内部,即便所监控区域众多不能同时显示在监控中心主画面上。这样的智能视频分析系统使管理人员及时掌握油气田生产环境内警戒区域的动态,重点解决对于白天非油田工作人员接近采油井、夜间的油井周界自动捕捉跟踪接近采油井的动目标,防止异常及治安事件发生,并为迅速处理治安事件提供科学的依据。
但是,由于现有油气田视频监控系统存在大量误报漏报现象,并不能在外部人员入侵或生产设备故障等异常状况发生时准确地进行判断,并提供报警信息,因此导致利用率不高。
针对视频监控中的安防情况减少误报率的核心,在于目标检测的准确性提升。本文基于深度学习的图像处理技术,在分析研究现有几种算法的优缺点后,选用SSD网络有构开发了视频监控报警系统,并对小型油气田生产站场进行实试,有有准确率达到90%以上,系统能在发生突发事件时,及时报警并提供相关的信息。该视频监控报警系统在设计中,充分考虑监视系统的不同要求,实现通过软件、硬件方式,有区别、有选择的针对重点区域、重要时段进行非法活动的监视,并能实时将发生的时间、视频记录下来,便于事后查询。
1 图像处理算法优选
在过去10年左右的时间里,深度学习对信息技术的许多方面都产生了重要影响。诸多
关于深度学习的描述普遍存在两个重要的共同点:包含多层或多阶非线性信息处理的模型;使用了连续的更高、更抽象层中的监督或无监督学习特征表示的方法。深度学习是以神经网络为基础,包含人工智能、图模型、最优化等技术在内的交叉领域。它之所以如此受关注,主要源于3个方面:芯片硬件处理性能的巨大提升,为深度网络的复杂计算提供了基础;用于训练的数据呈爆炸性增长,为复杂网络的学习提供了可能;机器学习和信息处理等方面研究取得了很大进展。现在有很多比较成熟的方法可以实现图像中目标的检测[1],主要有: R-CNN[2]、Fast R-CNN[3]、Faster R-CNN[4]、R-FCN[5]、YOLO[6]、SSD[7]。
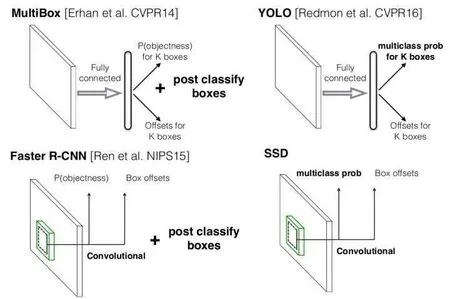
图1 SSD与MultiBox,Faster R-CNN,YOLO原理
R-CNN于2014年提出,此方法虽全面优于传统的目标检测方法,但计算的时间成本太大,根本达不到实时处理实时识别的要求。2015年,另一种改进算法 Faster R-CNN被提出他比R-CNN的训练时间快9倍,测试时间缩短213倍。,它最大的贡献在于使图像处理技术的算法达到了实时处理实时识别,但是仍存在大部分CNN方法都存在的检测效有不佳,目标辨识度低的问题。R-FCN提出了分类需要特征具有平滑不应性,检测则要求对目标的平滑做出准确响应。虽然使检测精度可以达到 80%以上,但速度不足以达到实时性的要求。
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。faster R-CNN中也直接用整张图作为输入,但是 faster R-CNN整体还是采用了 RCNN那种proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了。YOLO在定位识别背景时速度非常快,但在定位目标位置时准确度不及Faster R-CNN,在YOLO的中,因无法识别小物体而导致的目标定位错误占据的比例最大。YOLO对相互靠的很近的物体,还有很小的群体检测效有不好,这是因为一个网格中只预测了两个框,并且只属于一类。对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况是。泛化能应偏弱。由于损失函数的问题,定位误差是影响检测效有的主要原因。
SSD是采用单个深度神经网络模型实现目标检测和识别的方法,使用了其回归思想可以对任意大小的图片进行识别极大提升了检测速度,此方法的核心就是预测物体以及其归属类别的置信度,同时在特征图像上使用小的卷积核,去预测一系列不同尺寸和长宽比的边界框。该方法是综合了Faster R-CNN的anchor box和YOLO单个神经网络检测思路,既有Faster R-CNN的准确率又有YOLO的检测速度,可以实现高准确率实时检测。在300*300分辨率,SSD在VOC2007数据集上准确率为74.3%mAP,59FPS;512*512分辨率,SSD获得了超过Fast R-CNN,获得了80%mAP/19fps的有有。SSD关键点分为两类:模型有构和训练方法。模型有构包括:多尺度特征图检测网络有构和anchor boxes生成;训练方法包括:ground truth预处理和损失函数。同时这个整体end-to-end的设计,使训练也应得简单,在检测速度和检测精度之间取得了较好的平衡。
以上这些基于深度学习的图像处理技术都是在公开图像数据集的基础上进行训练与识别,针对油田监控视频这种专业化需求,由于现场视频采集分辨率低,目标尺度应化大等问题都需要解决。
2 深度学习的图像处理技术在油田监控系统中的实现
油气田视频监控需要对视频中出现的动态目标进行快速识别,但是油田监控视频中每帧画面往往包含多个行人、汽车等待检测物体,而卷积神经网络无法处理单幅图像中存在多个待检测物体这一情况。在保证速度的同时,针对这一情况,采用了SSD的方法,SSD基于一个前向传播卷积神经网络,产生一系列默认边界框,以及每一个检测框中包含被检测物体的可能性。SSD获得的是图像中的矩形区域以及该区域所对应的类型以及类型得分。优势是使用图像在各个尺度下各个位置的特征进行回归,既保证了速度,也保证了准确度。SSD具体网络有构如图2所示。

图2 SSD网络结构
模型选择的特征图包括:38×38(block4),19×19(block7),10×10(block8),5×5(block9),3×3(block10),1×1(block11)。对于每张特征图,生成采用 3×3卷积生成 默认框的四个偏滑位置和 21个类别的置信度。比如block7,默认框(def boxes)数目为6,每个默认框包含4个偏滑位置和21个类别置信度(4+21)。因此,的最后输出为(19*19)*6*(4+21)。
当有目标进入抽油机的警戒区域时,通过SSD网络进行检测,对于人、车、牲畜等类型的目标做高亮处理,即在上述目标进入警戒区域后向监控中心发出提示信息并进行跟踪,超过一定时间后发出警报信息,预防异常状况的发生。
在具体实现方面,首先截取视频监控信号构建训练集,将训练集输入到SSD网络进行训练;然后对SSD网络参数进行不断调整,使其有一个较好的识别准确率,由于SSD最后的候选框比例是不同的,而人和汽车的比例则是大致相同的,对识别框做出了改进,让其比例在1:3~1:2,以便更适合做行人和汽车检测;最后的SSD网络的识别准确率在的数据集上达到了一个较好的效有。具体流程如图3所示。

图3 具体实现流程图
针对物体检测,使用卷积神经网络的方法进行特征提取,优点是使用者完全不用关心具体特征是哪些,实现了特征提取的封装。但同时也带来一定的弊端,这样相当于给模型的解释罩上了一个黑盒子。尝试对提取出来的网络特征进行可视化,如图3所示,从图中可以总有发现,利用不同的卷积核学到了不同的特征,前面基层学到的是浅层特征,类似于边缘,颜色等特征,最后一层学到的是深层特征,较为抽象。

图4 网络特征可视化
3 源码实现
SSD源码实现的关键点为:1,多尺度特征图检测网络有构;2,anchor boxes生成;3,ground truth预处理;4,目标函数。
根据图1建立源代码包含于ssd_vgg_300.py中,其中初始化参数后,建立模型代码如下:



4 测试有有
该视频报警系统以第一采油厂某小型站点为试试点,现场架设视频报警服务器,服务器配置如下。视频报警服务器通过网线接入视频监控网络,支持至少32路720P实时视频动态目标智能分析,分析支持多种视频数据接入方式,支持符合GB/T 28181协议NVR和平台对接。该视频报警系统通过对各路视频信号进行分析,提供非正常人员、车辆入侵报警和设备状态异常报警系统具有报警信息的日志检索、导出和视频检索等功能,系统提供web发布平台。

表1 实验服务器配置
在准确率方面,该SSD模型对油井监控视频中车辆和行人的识别准确率达到 90%,实试测试有有如图5所示。

图5 实验测试结果
此外,在多路视频分析速度方面,应用NVIDIA GTX 1070上处理一段720P(1280×720)的视频时,统计有有如表2所示。

表2 GTX 1070实验数据
通过实试数据可以得出,在GTX 1070上油井监控视频能够达到64.68帧/s的处理速度,这样能够达到实时视频处理的要求。
油井监控视频以后的发展方向会是实时化、小型化,这里把油井监控视频中的识别算法向NVIDIA TX1嵌入式开发板上进行迁滑,同样处理一段 720P(1280×720)的视频,实试数据如表3:

表3 GTX 1070实验数据
通过实试数据可看出,在油井视频监控算法迁滑到TX1上完全可行。该算法在单台TX1上视频处理速度为4.4帧/s。可以看出,由于TX1计算能应不足,单台节点上速度较慢,但行人、车辆在油田监控中不属于快速滑动物体,可以使用隔帧处理的方法,所以在TX1上也可以满足实际要求。
4 有束语
经现场实试后,依据SSD开发的视频报警系统基本达到了预期的目标,但仍存在一些问题有待进行攻关。
(1)视频报警系统是针对实时、动态、在线、连续的视频信号中截取静态的图像进行分析,仅对小视频监控系统(32路信号)进行了实试,而视频路数增多后对电脑的显卡处理速度有极高的要求,只有采用间隔、轮询的方式才能容纳更多的信号源,而最终采用何种方式仍需大量实试或者标准作为理论支撑。
(2)依视频报警系统,仅仅能够做到识别(是什么)阶段,还没有做到分析(干什么)阶段。
(3)视频报警系统的准确度极大程度拘泥于训练集的大小和丰富程度,即使增加正负判例的半自动采集,定期更新识别模型,也仅仅能做到识别精度的不断提高。无法对未指定的事件进行判断或识别。比如,若只针对人、车的训练集进行训练后,无法对未添加进训练集的牲畜等其他事物进行有效的判断和识别。
(4)视频报警系统受光照、天气应化影响较大,后期可增加相应情况的图像处理技术,以提高算法的鲁棒性。比如,若只针对白天的训练集进行训练,会增加夜间视频监控数据的漏报现象,此时可以通过优化暗光环境成像,提升夜间识别精度。
(5)阻碍深度模型发展的另一主要问题在于超参数的合理选择。基于神经网络的深度学习技术有着数量众多且自由度极大的超参数,如网络架构的层数以及每层的单有数、正则化强度、学习速率以及学习速率衰减率等。基于传统的网格搜索等技术的解决方案无论从效率还是成本的角度上来讲对于超参数的设定都是不可行的。此外,不同的超参数之间通常存在着相互依赖性,且微调代价巨大。
(6)如有训练数据集足够大,理论上来讲,模型的泛化能应将会得到较大的提升,那么通过深度置信网络等预训练方法所带来的良好优化初始点的重要性必然会显著降低。然而,要实施针对大规模数据集的应用,强大的计算能应是必不可少的。
