基于k-NN非参数模型的高山松生物量遥感估测研究
2018-09-14谢福明舒清态吴秋菊吉一涛
谢福明,舒清态,字 李,吴 荣,吴秋菊,汪 红,刘 延,吉一涛
(西南林业大学 林学院,云南 昆明 650224)
在应对全球气候变化背景下,森林碳汇的相关研究成为科学界关注的热点。具体研究内容涉及森林固碳能力与计量、监测方法与技术研究等方面。其中,森林碳汇计量和监测是当前研究的核心内容之一。我国森林生物量/碳储量研究刚开始不久,存在基础资料不够系统完整和估算方法不统一等问题,估算的结果差异较大,可比性较差,估算精度还需进一步提高;由于遥感数据具有很大的优势,在大尺度的森林生物量估测中,遥感估测法成为大面积预估森林生物量最主要的方法[1]。传统的光学遥感技术通过处理分析卫星影像的像元亮度值,结合地面调查,间接估测较大区域的连续森林生物量分布。目前,基于以线性、非线性回归为主的参数模型和以神经网络(NN)、支持向量机(SVM)、最近邻法为代表的非参数化模型的估测方法被普遍使用。针对大多数基于遥感数据或其指数与实测生物量数据之间的相关性建立经验模型进行区域尺度的空间反演中,非参数化方法比较有优势[1]。其中k-最近邻法(k-NN)以其可用于单变量和多变量预测、不需要假设自变量与因变量的分布、容易把外部信息运用在感兴趣的地理区域和适用于各种数据集等优势使它特别受欢迎[2-3]。1951年,Fix和Hodges首次将最近邻法作为一种非参数识别技术用于对分布未知的种群进行分类[4]。1990年,Tomppo[5]在芬兰国家森林资源调查中提及了k-最近邻法的应用,为该技术在自然资源领域的应用研究开创了里程碑。此后,诸多国家的许多研究者使用k-最近邻回归模型对生物量、蓄积量、碳储量、树高、胸高断面积等森林参数进行估测,并且在采用遗传算法(GA)加权优化特征变量间的相似度评估后,该模型的精度得到了提升[6-10]。结合Landsat影像、MODIS卫星数据以及机载激光扫描数据的k-NN模型在大面积尺度的森林变量估测中都相继取得了较好的结果[10-15]。国内的部分研究学者也将k-最近邻法运用于区域森林生理参数估计,如陈尔学等[16]运用Landsat数据和k-NN法对小面积统计单元森林蓄积量估测,其结果表明采用k-NN法对县市级统计单元森林参数的估测效果明显优于只利用固定样地数据的传统参数估测方法。2011年,郭颖[17]运用k-最近邻法(k-NN)等非参数回归模型对甘肃省西水林场的森林地上生物量进行估测,并用随机森林算法(RF)进行特征选择后估测精度得以提升,优化后的算法在处理错误样本时具有良好的容错能力。然而,针对不同的森林类型或树种、不同规模尺度的遥感数据与样地数据以及不同的模型等,其估测效果都有所不同,而且没有可比性。因此,本文结合Landsat数据与非参数k-NN模型实现了香格里拉市的高山松地上生物量估测反演,获取高山松生物量空间分布格局,为低纬度高海拔地区的乔木森林资源保护及开发提供了技术案例。
1 研究区概况与数据采集
1.1 研究区概况

图1 研究区地理位置与样地点分布图Fig.1 Location of study area and the distribution of field data
研究区香格里拉市(99°20′~100°19′E、26°52′~28°52′N)隶属迪庆藏族自治州,位于云南省西北部、迪庆州东北部(图1)。境内地势高耸,热量不足,气温偏低,多年平均气温5.5 ℃,历年平均降雨量618.4 mm,属山地寒温带季风气候。由于地处云南亚热带常绿阔叶林植被区向青藏高原高寒植被区过渡地带,植被分布南北差异明显,山体垂直分布完整而典型。森林面积大,覆盖率高,天然林占绝对优势,主要分布有10种植被类型,常见的树种有云杉(Piceaasperata)、冷杉(Abiesfabri)、高山松(Pinusdensata)、云南松(Pinusyunnanensis)、高山栎(Quercussemicarpifolia)等。其中,高山松是研究区境内喜光、耐寒、耐贫瘠的主要优势树种,适应性广,更新能力强,一般分布在海拔3 300~3 800 m,占全市乔木林面积的22.7%。
1.2 数据采集
1.2.1 遥感数据 Landsat-8卫星于2013年2月11日发射,是美国陆地探测卫星系列的后续卫星。Landsat-8卫星搭载了陆地成像仪(OLI)和热红外传感器(TIRS)。OLI被动感应地表反射的太阳辐射和散发的热辐射,有9个波段的感应器,覆盖了从红外到可见光的不同波长范围。与Landsat-7卫星的ETM+传感器相比,OLI增加了一个蓝色波段(0.433~0.453 μm)和一个短红外波段(band 9:1.360~1.390 μm),蓝色波段主要用于海岸带观测,短红外波段具有水汽强吸收特征;可用于云检测的TIRS是有史以来最先进,性能最好的热红外传感器。本文采用OLI传感器3景影像数据完全覆盖香格里拉市区域(见图1(b)),卫星数据参数详见表1。

表1 香格里拉研究区卫星数据参数表
1.2.2 样地数据 本研究中样地数据采集时间为2014年10月24日—11月14日,在香格里拉市境内的高山松分布范围内,布设了50块不同龄级的30 m×30 m样地(图1),使模型的建立更符合现实意义。主要记录样地内每株立木的径阶、树高、胸径以及样地坐标和海拔等因子。样地中心GPS坐标是使用差分GPS(DGPS)测得样地4个角点坐标后计算得到。由于DGPS精度相对手持GPS精度较高,其相对误差均小于1 m,远小于遥感因子的30 m分辨率,所以本次样地采样在很大程度上减少了一般手持GPS误差较大而带来的样地位置和真实位置之间的差异。
2 数据处理与研究方法
2.1 数据处理
2.1.1 遥感数据预处理 遥感影像前期预处理在图像像元上最大化地还原地物的原始反射率等诸多信息,对于构建的反演模型至关重要,包括辐射定标、大气校正、几何精校正、镶嵌与裁剪等工作。利用ENVI 5.3实现对影像数据的预处理,辐射定标工具(Radiometric Calibration)能自动从元数据文件中读取参数,将图像的数字化量值(DN)转化为辐射亮度值或反射率等物理参数;FLASSH大气校正模块是基于MODTRANS辐射传输模型的较先进的校正算法,能够排除气溶胶、地形等因素造成的反射信息误差;几何精校正则基于SPOT高分辨率影像,利用地面控制点GCP和多项式几何校正数学模型,实现对非系统因素产生的误差的校正;最后,利用矢量边界完整的裁剪出研究区域的影像,见图1。
2.1.2 样地数据处理 利用高山松立木材积公式计算每株立木的材积,求和得样地高山松每木检尺蓄积量,样地实测数据包含:平均树高、平均胸径、样地蓄积和中心点地理坐标;其中,蓄积量和生物量转换模型则引用于前人的研究结果,见式(1),实测生物量描述见表2,该模型基于统计学原理与方法,实现了林分蓄积量与生物量之间良好的线性转换关系。最后,将样地数据依据地理坐标叠加至遥感数据图层,提取样地点处对应的像元值作为建模因子。
B=0.516 8×V+33.237 8[18]
(1)
式(1)中:B为高山松的林分生物量,单位:t/hm2;V为林分蓄积量,单位:m3/hm2。

表2 高山松实测样地地上生物量描述统计分析
2.1.3 建模因子提取 对预处理后的影像数据通过波段运算工具提取单波段、多波段组合、植被指数和地形特征等共计18个因子,作为建模因子备选参数:
(1)原始波段因子。一般研究植被的波长范围为400~2 500 nm,故本次采用的原始波段为可见光波段(400~700 nm):Band 1-4、近红外波段(700~1 300 nm):Band 5和短红外波段(1 300~2 500 nm):Band6-7。
(2)波段指数因子。波段指数的信息来源于原始波段,却以2个或多个波长范围内的地物反射率的组合运算增强了地物某一特性或者细节。本次研究涉及的波段指数因子及其计算公式如下:
归一化植被指数:NDVI=(ρNIR-ρR)/(ρNIR+ρR);
(2)
比值植被指数:SR=(ρNIR/ρR);
(3)
差值植被指数:DVI=ρNIR-ρR;
(4)
(5)
(6)
(7)
(8)
其中,ρNIR、ρR、ρBLUE分别为近红外波段、红外波段、蓝光波段的反射率;Bandi为Landsat OLI 传感器的第i波段;L为土壤调节系数,因香格里拉市植被覆盖面积为89%,本文中L取0.25[19]。
(3)地形因子。由DEM派生的坡度(slope)、坡向(aspect)和海拔(elevation)因子组成。
2.2 k-最近邻法(k-NN)

(9)

(10)
dij2=(Xi-Xj)′M(Xi-Xj)
(11)
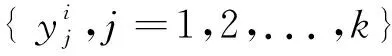
2.2.2 精度评价 运用样本置留法,按3∶2的比例随机选取30个样本作为参考集,20个样本作为目标集。并采用决定系数(R2)、均方根误差(RMSE)对模型精度进行评价,二者计算公式为:
(12)
(13)
式中,n为样本数,xi为目标集响应变量的模型估测值,yi为目标集响应变量的实测值。
3 结果与分析
本研究中的k-NN模型算法在MATLAB软件平台编程实现,主要算法流程为数据的读取与归一化、计算特征变量间的空间相似度、依据k值选取最近邻个体、确定近邻加权大小和计算变量的预测值等。同时,考虑到模型反演数据量大,采用分块处理的方法将研究区进行分块后逐一估测,实现对整个研究区像元尺度上的高山松生物量估测反演。
3.1 最优参数的选择
3.1.1k值的优化选择k值决定了计算响应变量预测值时需要考虑的最近邻个数。本次研究中考虑了0~20范围内的k值,在不同的模型结构配置下采用了精度评价指标分析选取最佳值:当k<5时,估测模型的精度随k值呈现增加趋势,在k=1时模型的精度最低;当k≥10时,模型的精度趋向平稳,受k值的影响较小;在k值为4或5时,模型精度达到最佳,均方根误差(RMSE)达到最低值。图2是不同参数组合下的精度评价指标随k值波动的变化曲线,直观地反映了k-NN模型参数对其预测结果的影响情况。

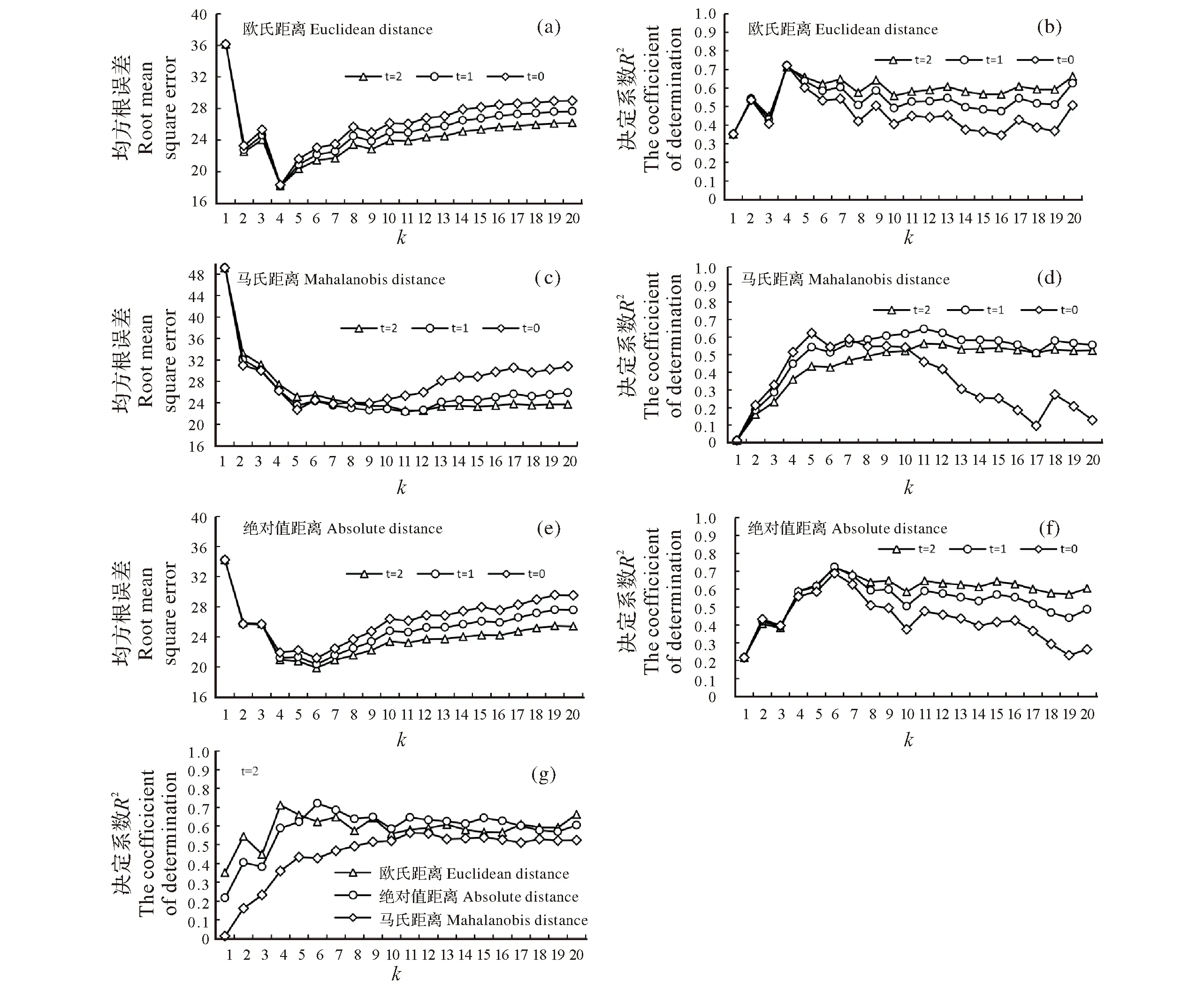
图2 不同参数组合下的k-NN模型精度变化曲线Fig.2 Accuracy curve of the k-NN model with different parameters


表3 不同参数组合下的k-NN模型精度对比(部分)

图3 高山松实测生物量与预测生物量的拟合线图(模型参数:欧式距离、k=4、t=2)Fig.3 Observations versus predictions:Pinus densata aboveground biomass(Model metrics:Euclidean distance,k=4,t=2)
综合上述参数的择优分析,确定本次研究最终采用的k-NN模型参数结构为:采用欧式距离度量特征变量间的相似度,k、t值分别取4和2;图3是基于参数优化的k-NN模型的生物量预测值与实测值的线性拟合结果。
3.2 生物量估测反演
目前,结合遥感数据和实测样地数据,利用回归模型对生物量等森林生理参数和属性估测的研究中一般采用基于像元尺度或基于样地尺度的2种估测方法。本文基于像元尺度的模型估算研究区高山松生物量并用预测的生物量值进行反演。图4a是依据二类调查数据将高山松分布区域随机分成27块的编号图,利用已构建的模型依次对每一块区域的生物量进行估测,其对应的像元数与生物量估测结果见表4。统计得到整个研究区的高山松生物量估计值为22 496 140.79(约0.22亿t)。估测的高山松生物量在空间分布上与研究区实际情况相一致,与岳彩荣[20]基于SVM的高山松生物量估测结果(约为0.17亿t)和王金亮等[21]利用遥感信息模型估测的结果(约为0.20亿t)等有可对比性。

(a)分块编号;(b)生物量空间分布图(a)Block number;(b) The spatial distribution of biomass图4 像元尺度下基于k-NN模型的香格里拉市高山松地上生物量反演结果Fig.4 The spatial distribution of Pinus densata aboveground biomass in Shangri-la at the pixel scale based on k-NN model

编号Number像元个数Number of pixel生物量/tAboveground biomass编号Number像元个数Number of pixel生物量/tAboveground biomass编号Number像元个数Number of pixel生物量/tAboveground biomass197 0611 113 706.251069 531807 940.921957 616671 981.94227 263304 072.2011169 4791 958 356.972049 767569 445.943102 3601 173 724.961287 8811 016 597.732165 713780 240.74448 066550 318.6313103 0101 203 704.102266 890779 716.65567 590778 537.251475 249866 274.592350 723589 941.746111 4831 269 431.551524 887285 493.502429 258339 609.41748 328558 960.921653 199615 392.442566 588774 198.578117 7881 363 803.001750 877594 906.542629 323341 042.579165 1111 900 327.331870 132792 035.852743 692496 379.45
像元个数总计为1 939 779;生物量总计为22 496 140.79(t)
研究区的高山松生物量预测值最低为62 t/hm2,最高为157 t/hm2,主要集中在125~135 t/hm2,其次是115~125 t/hm2。数值介于实际生物量的测量值(49~195 t/hm2),正如Chirici[3]所说,k-NN法的一个缺陷就是估测的值只能局限于实测值范围内进行估测,不会对超出实测值范围的值进行预测,但也能客观的反映出研究区高山松生物量的分布格局(图4b)。
4 讨论与结论
4.1 讨论
本研究基于非参数模型建立了高山松地上生物量遥感估测模型,并实现了研究区香格里拉市的高山松生物量反演:以Landsat8/OLI为信息源,结合地面50个实测样地数据,建立了研究区高山松地上生物量k-最近邻法(k-NN)遥感估测模型。对k-NN模型参数的优化结果表明:(1)特征变量间的相似度评价方式中,欧式距离最稳定,效果最好,其次是马氏距离和绝对值距离;(2)最佳的近邻个数k值为4,其对模型精度的影响呈现规律:当k<5时,模型的精度随k值呈现增加趋势;当k≥10时,模型的精度趋向平稳,受k值的影响较小;在k值为4或5时,模型精度最高,k=1时模型的精度最低;(3)模型精度受距离分解因子t的影响较小,相比之下,t值取2时模型精度较好。参数优化后的k-NN模型拟合精度为,R2等于0.71,RMSE为18.21 t/hm2,估测得到研究区像元尺度下的高山松生物量为0.22亿t。
4.2 结论
(1)在建模因子选取多少的问题上,应采取优化算法实现对特征变量的加权或排除不相关变量,并通过与不同的传感器以及非遥感变量(如降水或气候图)等数据的集成使用,来提高对森林结构和功能等森林属性的预测精度。
(2)k-NN模型的结构配置优化可以通过进行多种诊断测试,观察参数和特征变量的变化来确定更准确的结果,比如包括特征变量的筛选、选取复杂的距离度量方式,以及k和t的优化。目前,没有统一标准的优化步骤顺序使模型产生更高的精度,一个合理的顺序应为:首先选择通过消除冗余特征变量来减少特征变量的维度灾难影响;然后根据特征变量集的性质,选择更复杂的距离度量(例如加权欧氏距离或典型对应分析指标)进行测试;最后可以利用交叉验证的留一法对k值进行优化选择。
(3)虽然遥感数据能够较好的估算森林生物量,但普遍存在生物量饱和问题,即随着生物量的增大,光谱反射率和后射散射系数对生物量的敏感性较小,不能有效的反应生物量的变化情况,降低了高森林生物量的估测精度,故研究光谱“饱和点”的识别并在其基础上的生物量遥感估算模型的构建就变得更有意义。
