基于特定话题的网络水军识别研究
2018-09-14程传鹏张书钦刘小明夏敏捷
程传鹏,张书钦,刘小明,夏敏捷
(中原工学院 计算机学院,河南 郑州 450007)
网络水军,即受雇于某个组织或者个人,以发帖、回帖为主要手段,为雇主进行网络造势的网络人员,有专职和兼职之分。网络水军受利益驱动,通过操纵软件机器人或水军账号,在互联网中制造、传播虚假意见和垃圾信息等,妄图达到影响网络民意、扰乱网络环境等不正当目的。由于网络成员的匿名性和隐蔽性,给水军的识别带来了很大的困难。网络水军识别研究被认为可以有效解决此问题,得到学术界和工业界广泛关注,并取得了一定的研究成果。当前,网络水军识别研究按照目标领域的不同,可以分为邮件领域、电子商务领域、社交网络领域等;按照研究方法的不同,可以分为基于用户产生内容特征、基于用户行为相关特征、基于用户环境特征的识别方法[1]。本文分析了网络论坛中水军用户的各个特征,给出了基于特定话题的水军账号识别方法。
1 相关研究及本文的研究思路
目前的水军识别方法主要有3种。一种是基于评论文字内容分析的方法。胡舜良等提出了对发帖内容进行分析、处理,生成Hash值,通过各个发帖Hash值之间的比较,确定该贴是否为水贴[2]。杨长春等指出水军的评论内容具有重复或者相似性,提出了基于文本相似度的网络水军发现算法,通过建立高效的B-Tree来索引评论内容,算法具有较高的处理速率[3]。Liu H Y等通过分析评论者所发表的评论文字内容,发现水军的情感倾向性明显,偏离正常用户的评论[4]。Jindal N等利用自然语言处理统计知识,发现水军用户在发表评论时趋向于使用大量形容词,或者文字有较多的重复[5]。Lim E P等通过分析Amazon中大量的用户评论,总结了几种具有代表性的网络水军行为,发现水军为了尽可能地减少自身工作量并获得最大的利益,只会选择特定的目标商品进行评价,目标针对性强,并且会大量复制已发表或者别人的评论[6]。第二种方法是分析水军的行为特征。王烁等提出了一种“水军”探测静态方法,认为网络评论中从好到差的评论数量分布规律应该符合统计学中的正态分布这一规律[7]。Mukherjee A等分析了水军的各种行为,发现网络水军有别于正常用户的评论:时间集中突发、评论极端,利用用户及其发表的评论特征构建分类器,依据上述水军行为特点将其与普通用户区分[8]。Hayati P等通过追踪用户行为特征来发现网络水军[9]。余玲通过分析不同周期内和不同时间起点的贴文和评论的统计数量分布,来寻找水军的群体性行为特征[10]。第三种方法是通过用户之间的关系来识别水军。Xu C等通过网络水军之间形成的组织关系发现网络水军形成的团体,并在此基础上计算水军与其邻居间的相似性,利用K近邻算法修正对该网络水军的分类判定[11]。陈桂茸等在分析网络水军灌水行为的基础上,提出了一种网络论坛水军账号快速检测算法[12]。范纯龙等以特定网络论坛数据为分析对象,利用由账户及其间关系构成的复杂网络,分析了论坛上社区和网络组织的统计特征和典型结构[13]。张慧杰提出了基于多特征尺度空间模型的组织发现技术,首先构建了用户同时出现次数模型、评分相似度模型、同品牌率模型,对构建的评论用户关系网进行处理,逐步发现其中存在的稳定网络组织;然后通过优选网络组织中的关键评论来确定网络水军,进而甄别出网络中存在的组织是否为网络水军[14]。
有些用户账号在一些话题上表现出正常的用户特征,而在另外一些话题上则有意或者无意地充当了水军。因此,本文将研究定位为网络论坛中针对特定话题的网络水军识别。通过人工对选定的代表性话题帖子进行标注,标注出正常用户和水军用户,分别提取出两种用户的用户名特征、注册时间特征、回帖时间特征、关注度特征、回复频度特征、话题回复特征以及负面情感特征,利用这些特征对用户进行向量化表示,形成分类的训练集模型。对待检测话题帖子里的用户,按照同样的方法进行向量化表示,利用训练集模型识别出正常用户和水军用户。整个流程如图1所示。

图1 特定话题水军识别流程示意图
2 网络水军相关特征以及计算方法
随着移动网络的普及,人们不仅可以通过计算机上网,而且还可以借助手机随时随地登陆互联网。由于网络的这种开放性,网络水军具有较强的隐匿性,这给网络水军的识别带来了很大的困难。但是通过对大量水军用户的观察,可发现水军用户区别于正常用户的一些特征。
2.1 用户名特征
话题发布后,水军要达到回帖的目的,必须要大量注册账号。对于一个比较热门的论坛,已注册的用户数量非常庞大,为了避免和已注册的用户账号冲突,网络论坛在新用户注册时,一般会在用户所填写的注册账号后面加上一些随机的数字,例如“张三184”“zhangsan978”“李四1”“王五2”等等。除了正常注册帐号外,有时候水军还会购买通过程序自动注册的账号。一般来说,尽管注册时间不一定相同,但是水军注册的用户名会很类似,如果用Fname表示用户U的用户名特征,其值可以用下式进行计算:
(1)
式中:Lennumber表示用户名中数字字符个数,Lenname表示用户名中字符总数。
2.2 注册时间特征
通过大量的实例观察到一个事实:水军账号为了达到通过回复贴子来左右话题的舆论方向,一般都会在话题开始前后的一段时间内开始注册大量的新账号。如果用Fregtime表示用户U注册时间特征度,其值可用下式进行计算:
(2)
式中:Duserreg表示用户U注册的日期,Dtopicstart表示话题T开始的日期,abs表示取绝对值。
2.3 回帖时间特征
话题开始后,水军用户一般都会对相关话题进行集中回复。在话题开始之前或者话题沉寂时,账号一般都不活跃。用Spanreply来表示用户U最近半年内所回复的帖子跨越天数;Spanregtime表示截止到采集当天,用户U账号己存活的天数(注册天数)。水军用户在话题开始后会变得突然活跃,上述特征值会偏高;而对于正常用户而言,这一特征值较低。用Fspan表示回帖时间特征,其值可用下式计算:
(3)
2.4 关注度特征
在网络论坛中,用户会对自己感兴趣的帖子作者进行关注。同样,如果一个用户在网络论坛中有较高的人气,也会被论坛中其他用户所关注。水军用户的主要目的是为了对特定的话题进行造势,很少会去关注其他用户,也很少会被其他用户所关注。用Fcore表示用户U的关注度特征,其值可用下式进行计算:
(4)
式中:Numberfollow表示用户U在论坛中被其他用户关注的数量,Numberfriend表示用户U在论坛中关注的其他用户数量。
2.5 回复频度特征
网络水军会对某个话题的相关帖子反复回应,即顶贴。用Freplyfre表示用户U对话题T的回复频度特征,其值可以用下式进行计算:
(5)
式中:Numberu表示用户U回复话题T的次数,Numberreplyfre表示话题T的总回复次数。
2.6 话题回复特征
互信息是计算语言学模型分析的常用方法,它度量两个对象之间的相互性。水军用户一般只会对特定的话题感兴趣,只会针对特定话题的帖子进行回复,因此,话题的回复特征也是甄别水军账号的一个特征。
如果用FMI表示话题回复特征,A表示用户U回复话题T的频数,B表示用户U回复的不属于话题T的频数,C表示用户U没有回复话题T的频数,N表示论坛中一段时间内所发表的帖子总数,参照互信息公式,话题T和用户U的互信息可由下式计算:

(6)
2.7 负面情感特征
网络水军在发表评论时,一般用词比较极端,文字特征明显,情感倾向特别强,通过恶意的方式达到贬低对手的目的,妄图左右舆论的走向,所以可通过计算负面的情感倾向来甄别水军帐号。
用FSO表示用户U在话题T上的负面情感特征值,考虑程度副词对情感度的影响,其计算公式可以表示如下形式:
(7)
式中:NWordsj表示负面情感基准词,Sim(WI,NWordsj)表示词语Wi和NWordsj之间的语义相似度[15],m表示用户所发表的评论中去掉停止词之后词语的个数,n表示负面情感基准词个数。
《知网》情感分析用词语集中提供的程度副词一共有4个等级集合,依照程度从低到高的顺序分别用Set1、Set2、Set3、Set4来表示。DegWi表示Wi前的程度副词,Deg按如下规定取值:
3 实验及评价
3.1 实验数据
目前,网络水军识别研究中没有公开可用的数据集。为验证本文所提方法的合理性和有效性,通过“天涯论坛”的Oauth授权,申请了App Key和App Secret;利用论坛所提供的开发者文档中的“用户相关”“关系相关”以及“论坛相关”的API编写了一个数据采集工具,并利用该工具采集了论坛中比较热门的几个话题,共1 358个帖子;分别提取每个贴子里所有评论者的账号、评论内容、注册时间、最近半年内所有回复的帖子内容、回复时间以及评论者的个人信息,包括评论者关注的其他用户数及评论者的粉丝数等信息。
判断用户是否为水军的标准为:注册时间与话题爆发时间相近;观点明确地偏袒一方;言辞激烈,夹杂有很多不文明的用词;几乎所有的回复都是针对特定的某一个话题。
为了获取客观、准确的标注结果,本文开发了标注平台进行机器识别,并邀请两位研究生对所提取出的用户进行人工随机、交叉标注。
为评价识别效果,本文采用最通用的性能评价方法:准确率和召回率。二者的公式定义如下:

(8)
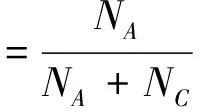
(9)
式中:NA表示系统识别出的水军用户数量,NB表示正常用户被系统识别为水军的数量,NC表示是水军但是系统没有识别到的用户数量。
对于人工标注判断标准,因每个人的判断标准有差异,因此,选择两个标注者所选择出的交集作为最终的识别结果,并假定人工判别准确率和召回率都为100%。
3.2 实验结果分析
为了客观评估本文提出方法的有效性和合理性,利用所设计的数据采集工具获得所需数据,得到27 436个论坛用户,人工判别得到水军用户账号953个。经过预处理后取出500个正常用户,并与500个水军账号混合组成实验数据集。依照上文中的特征,将用户进行向量化表示为:Ui(WFname,WFregtime,WFspan,WFcore,WFreplyfre,WFMI,WFSO)。为了验证本文中所提出的方法,本文一共做了两组实验。
第一组实验是利用KNN进行分类。通过人工选择一定数量的论坛用户(包括正常用户和水军用户),作为分类的训练集,计算待判别用户与所有训练集中用户的相似度,在训练集中选出与待识别用户最相似的K个用户。用户相似度计算方法如下:
(10)
式中:Sim(Ui,Uj)表示用户Ui和Uj的相似度,M为特征向量的维数,Win、Wjn为第i、j个用户向量的第n维值。
在待识别用户的K个邻居中,分别计算权重,计算公式如下:
(11)
(12)

比较p(Ux,C1)和p(Ux,C2),如果p(Ux,C1)>p(Ux,C2),那么Ux为正常用户,否则为水军用户。由于网络论坛用语的多样性,我们利用词语对照表对所出现的网络用语进行了规范化处理,并对文本分词后的词语进行了同义词以及近义词扩展。在KNN分类实验中,分别采用本文中的用户相似度计算方法和文献[3]中所提到的文本相似度方法进行对比,实验中K分别取值150、200、250、300、400,两种方法所得到的准确率和召回率比较结果如图2、图3所示。

图2 不同方法识别准确率比较结果图

图3 不同方法识别召回率比较结果图
从图2和图3可以看出,采用本文中的方法,所得到的准确率和召回率都要优于文本相似度方法。从语料里去掉语言不规范以及较短文字的评论后发现,基于文本相似度方法的准确率和召回率都达到了80%以上,这说明网络表达方式的多样性以及文本长短分布的不平衡是文本相似度识别方法难以取得较高准确率和召回率的主要原因。
第二组实验是采用台湾大学林智仁博士等开发设计的LIBSVM通用SVM软件包来识别,核函数为Polynomial。对各个特征进行组合实验,特征集FSet1的特征向量为(WFname、WFregtime、WFspan、WFcore、WFreplyfre、WFMI、WFSO),特征集FSet2的特征向量为(WFregtmie、WFspan、WFcore、WFreplyfre、WFMI、WFSO),特征集FSet3的特征向量为(WFname、WFregtime、WFspan、WFcore、WFreplyfre、WFSO),特征集FSet4的特征向量(WFname、WFspan、WFcore、WFMI、WFSO),所得到的准确率和召回率如表1所示。

表1 选择不同特征所取得准确率和召回率结果 %
从表1可以看出,采用特征集FSet1,即使用了本文中所提出的所有特征,准确率和召回率分别达到了78%和74%;特征集FSet2是从所有特征里去掉WFname,准确率和召回率下降明显,分别下降13%和6%;特征集FSet3去掉了WFMI,准确率和召回率分别为62%和53%,说明WFMI在水军识别上具有很好的特征识别度;特征集FSet4去掉了WFregtime和WFspan,准确率只有较小的下降。本组实验说明WFname和WFMI对水军识别的准确率和召回率有较大的影响。
在两组实验条件下,本文提出的水军识别方法的准确率和召回率都达到了70%以上,因此该方法对于特定话题水军的识别有一定的应用价值。
4 结 语
本文对网络论坛中水军的各种特征进行了分析,提出了一种基于特定话题的网络水军识别方法。通过对大量实例的观察,总结出网络水军明显区别于正常用户的7个特征,并给出了合理的特征度计算公式。依据所选择出的特征,对每个论坛用户建立向量空间模型后,利用机器学习的方法来识别出水军。实验表明,本文提出的识别方法能有效识别针对特定话题的网络水军。
