有限混合模型回归分析
2018-09-11胡良平
胡良平
(1.军事科学院研究生院,北京 100850;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029
1 概 述
1.1 有限混合模型
有限混合模型[1]见式(1):
(1)
在式(1)中,假定y是一个可观测的随机变量,其分布取决于一个不可观测的隐变量S,它有k种可能的状态;k的取值是未知的,但至少是有限的。
令πj表示S取值j的概率,在S=j的条件下,假定反应变量Y的分布是fj(y;αj,βj|S=j)(注:它是一个概率密度函数)。
1.2 有限混合模型回归分析应用的场合
根据研究目的确定了一个具有同质性的研究总体,若从该总体中随机抽取样本含量为n的个体,从每个个体身上测量某计量指标的数值,依此法收集到的n个计量数据被称为“单组设计一元计量资料”。描述这组计量数据的方法有如下几种:第一,编制频数分布表;第二,绘制直方图;第三,拟合频数分布曲线。
当直方图显示只有一个高峰时,就称其为“单峰分布”。此时,可以根据高峰所处的位置,分为“正偏态分布(高峰位于左侧)”“对称分布(高峰居中,其特例为正态分布)”和“负偏态分布(高峰位于右侧)”。此时,若希望拟合频数分布曲线,可以利用SAS中CAPABILITY过程,见文献[2]。
当直方图显示有两个或多个峰时,就称其为“多峰分布”。它们很可能是由多个“单峰分布”叠加而形成,被称为“有限混合分布样本”。在实际问题中,这种混合分布样本很可能来自一个“不同质”的总体,例如正常人样本、某种疾病不同严重程度(轻、中、重度)的患者样本。若希望拟合频数分布曲线,可以利用SAS中FMM过程,见文献[1]。
1.3 有限混合模型回归分析的计算原理
1.3.1 概率分布
对于样本资料而言,描述单组设计一元计量资料的频数分布情况,所采用的方法被称为“拟合频数分布曲线”;而对于总体资料而言,描述其一元连续性变量的变化规律,所采用的方法被称为“呈现概率分布密度函数”。在运用统计学解决实际问题时,通常都是通过样本信息去推论总体的规律,故通常都是以“拟合频数分布曲线”取代“呈现概率分布密度函数”。换言之,就是以“精确的概率分布密度函数”作为理论依据,描述“频数分布曲线”的变化规律。
1.3.2 计算原理
式(1)描述的“频数分布曲线”仅适用于“单组设计一元计量资料”,然而,当资料中还有影响计量结果变量的自变量z和x时,需要将式(1)修改成式(2)的形式:
(2)
在式(2)中,有k个样本混合在一起,k值需要结合专业知识事先给定;求和符号之后的第1项为样本来自第j个总体的概率,其自变量为z;而其后的那一项为第j个样本的“频数分布(对样本而言)”或“概率密度函数(对总体而言)”,其自变量为x。式(2)中求和符号之后的第1项还应满足下式要求,见式(3):
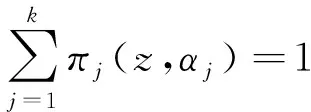
(3)
在式(3)中,πj≥0,对于所有的j(j=1到k)都成立。
要想在式(3)的约束条件下求解式(2),涉及到“一般混合模型”的求解理论和技术方法,涉及到基于多种常用概率密度函数构造“对数似然函数”并求解,还涉及到贝叶斯统计模拟算法[1,3-4]等深入的内容,因篇幅所限,此处从略。
2 基于有限混合模型回归分析解决实际问题
2.1 问题与数据结构
【例1】下面是一个关于牛的喂食时间间隔的数据(计量数据)。按两种情形对时间进行划分:第1种情形:分为3类不同的时间段(相当于前面所说的混合样本个数k=3),即:①各次进食之间的时间间隔很短;②各次进食之间的时间间隔稍长一点,间隙让牛饮水;③每两次进食之间的时间间隔很长。第2种情形:在上面的3类时间间隔组中的每一种时间间隔内,不同牛的进食时间是不尽相同的。
测量141 414头牛中每头牛每两次进食之间的“时间间隔数据(int)”,再取其对数,记为“logint”。以其为“计量结果变量(特别说明:选取这样的指标作为结果变量,只有在特定专业领域内才有意义,在一般的实际问题中,‘时间间隔’是不可能用作结果变量的)”,由于原始数据的精确度很高,保留其精确度为“0.05”,这就导致了相同的数据很多,于是,可用类似“频数表”简化地呈现原始数据,其数据格式见表1。

表1 141 414头牛中每头牛每两次进食之间的“时间间隔数据(logint)”
注:表中仅列出了极少部分数据,详细数据见后面SAS程序
【对数据结构的分析】以上采用“频数分布表”形式呈现了资料,而资料的原始形式很简单,即一个计量变量“logint”,它有141 414个取值。通常这样的数据被称为“单组设计一元计量资料”;而在本例中,因所有数据分别属于“3类不同的时间段”。也就是说,若用一个变量k代表“3类不同的时间段”,将此变量“k”及其具体取值也体现在每个“logint”数据之前,相当于多了一个“分组变量”。此时,全部数据就可被视为“单因素三水平设计一元计量资料”了。
【统计分析方法的选择】若希望采用“单因素三水平设计一元计量资料”方差分析处理此资料,就必须在资料中全面反映出变量k及其取值;而在本例中,统计分析目的是“拟合频数分布曲线”,就只需要告知有“k个样本”(注意:k必须是一个具体的正整数),并且还需要告知这k个样本所代表的“分布”分别是什么。与特定分布对应的“参数”可以告知,也可以不告知。例如“dist=normalk=2 parms(3 1, 5 1)”,这就是告知:有2个正态分布的样本,它们的均值分别为3和5、方差分别为1和1;又例如“dist=normalk=2”,这就是告知:有2个正态分布的样本,它们的均值和方差都没有指定,由统计软件根据实际数据去估算。
2.2 创建SAS数据集
创建一个名为“cattle”的临时SAS数据集的SAS数据步程序:
data cattle;
input LogInt Count @@;
datalines;
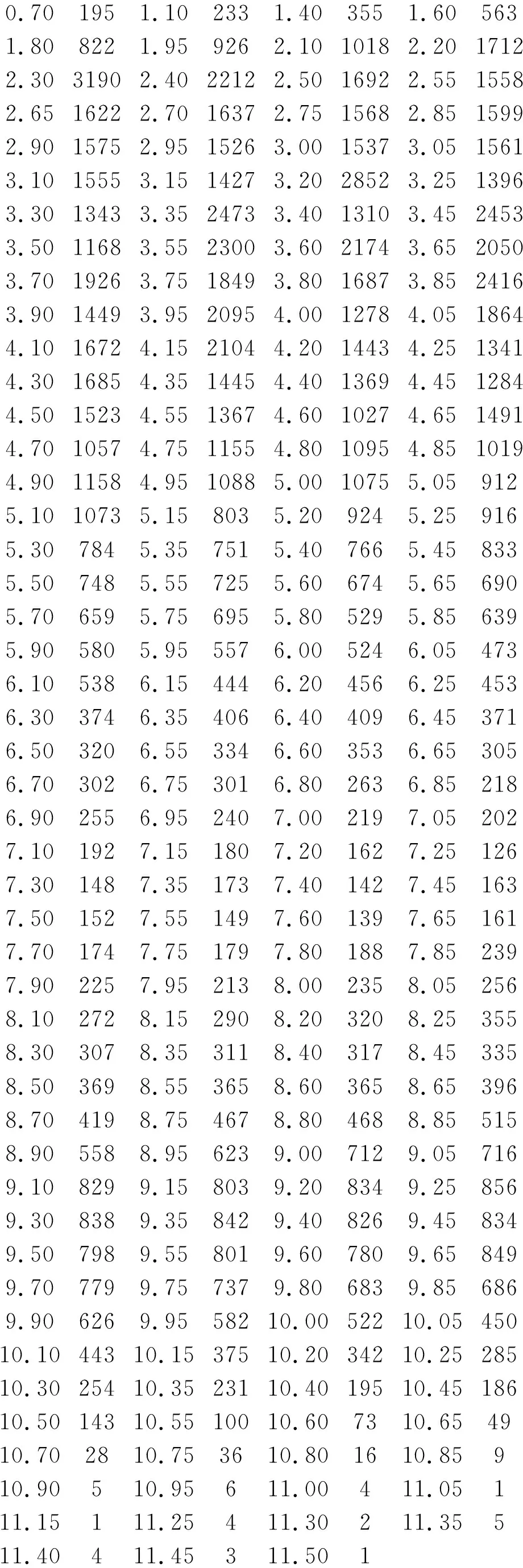
0.701951.102331.403551.60563 1.808221.959262.1010182.201712 2.3031902.4022122.5016922.551558 2.6516222.7016372.7515682.851599 2.9015752.9515263.0015373.051561 3.1015553.1514273.2028523.251396 3.3013433.3524733.4013103.452453 3.5011683.5523003.6021743.652050 3.7019263.7518493.8016873.852416 3.9014493.9520954.0012784.051864 4.1016724.1521044.2014434.251341 4.3016854.3514454.4013694.451284 4.5015234.5513674.6010274.651491 4.7010574.7511554.8010954.851019 4.9011584.9510885.0010755.05912 5.1010735.158035.209245.25916 5.307845.357515.407665.45833 5.507485.557255.606745.65690 5.706595.756955.805295.85639 5.905805.955576.005246.05473 6.105386.154446.204566.25453 6.303746.354066.404096.45371 6.503206.553346.603536.65305 6.703026.753016.802636.85218 6.902556.952407.002197.05202 7.101927.151807.201627.25126 7.301487.351737.401427.45163 7.501527.551497.601397.65161 7.701747.751797.801887.85239 7.902257.952138.002358.05256 8.102728.152908.203208.25355 8.303078.353118.403178.45335 8.503698.553658.603658.65396 8.704198.754678.804688.85515 8.905588.956239.007129.05716 9.108299.158039.208349.25856 9.308389.358429.408269.45834 9.507989.558019.607809.65849 9.707799.757379.806839.85686 9.906269.9558210.0052210.0545010.1044310.1537510.2034210.2528510.3025410.3523110.4019510.4518610.5014310.5510010.607310.654910.702810.753610.801610.85910.90510.95611.00411.05111.15111.25411.30211.35511.40411.45311.501
;
run;
2.3 利用SAS/STAT中KDE过程绘制资料的频数分布曲线
利用下面的SAS过程步程序,可以绘制出反映计量变量logint的频数分布直方图和频数分布曲线图。
ods graphics on;
proc kde data=cattle;
univar LogInt / bwm=4;
freq count;
run;
【SAS主要输出结果】
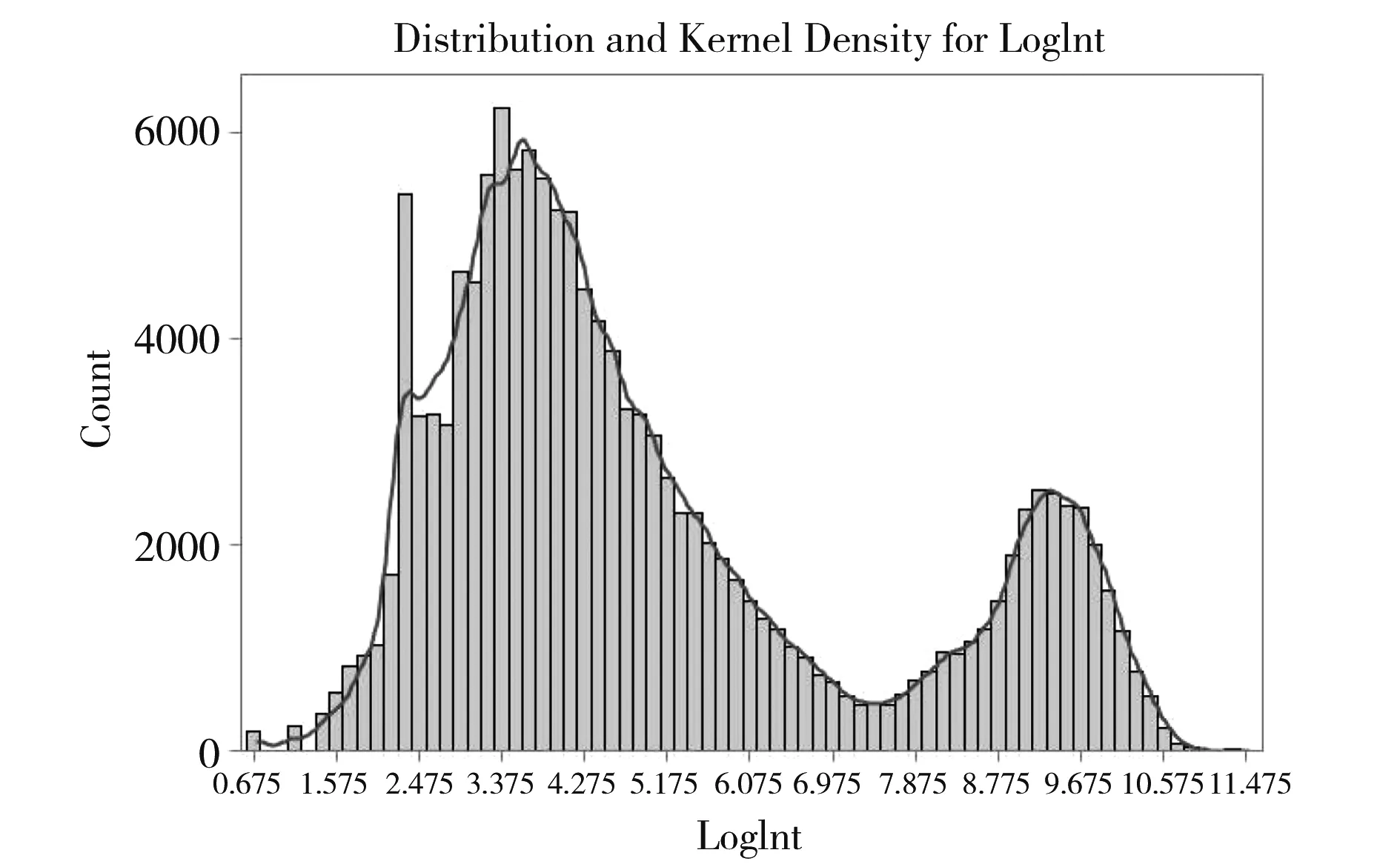
图1 本例资料的频数分布直方图与频数分布曲线图
图1给人的印象是由两个频数分布混合而成的,然而,由专业知识可知,它实际上是由三个频数分布混合而成的。
2.4 利用SAS/STAT中FMM过程拟合“三分量频数分布曲线”
“三分量频数分布曲线”就是拟合“由三个不同分布样本混合而成的一个总样本”的频数分布曲线。程序将给出三条各自的频数分布曲线以及一条混合的频数分布曲线。
领域专家给出的三个分布分别为:①正态分布,N(3,12);②正态分布,N(5,12);③威布尔分布。利用下面的SAS过程步程序,可以拟合并绘制出反映计量变量logint的频数分布曲线图。
proc fmm data=cattle gconv=0;
model LogInt = / dist=normal k=2 parms(3 1, 5 1);
model + / dist=weibull;
freq count;
run;
【SAS主要输出结果及解释】

Fit Statistics-2 Log Likelihood563153AIC (smaller is better)563169AICC (smaller is better)563169BIC (smaller is better)563248Pearson Statistic141458Effective Parameters8Effective Components3
以上是拟合统计量的有关计算结果:前5行都是关于拟合效果的评价指标及其取值,这些数值只有在两个或多个模型比较时才有参考的价值。
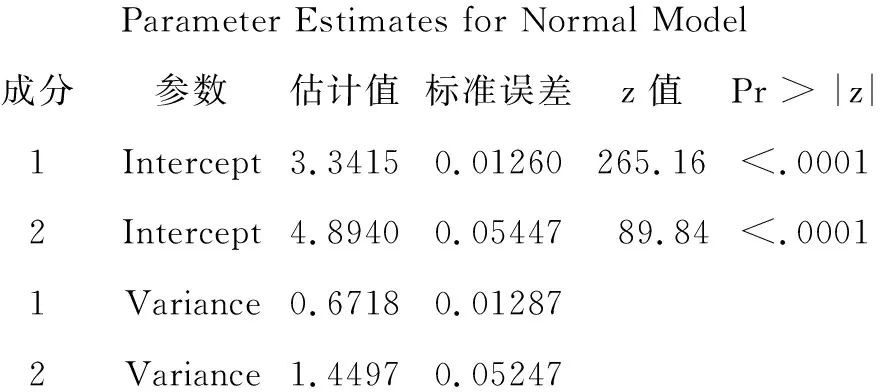
Parameter Estimates for Normal Model成分参数估计值标准误差z 值Pr > |z|1Intercept3.34150.01260265.16<.00012Intercept4.89400.0544789.84<.00011Variance0.67180.012872Variance1.44970.05247
以上是基于“正态分布”假定条件下,计算出两个正态分布对应的“参数估计”结果。因为对于每一个特定的正态分布而言,只要给定了“均值”与“标准差(或方差)”,该正态分布也就唯一被确定了。
第1个正态分布为:N(3.3415,0.6718)=N(3.3415,0.81932);
第2个正态分布为:N(4.8940,1.4497)=N(4.8940,1.20402)。

Parameter Estimates for Weibull Model成分参数估计值标准误差z 值Pr > |z|逆关联估计3Intercept2.25310.0005064452.11<.00019.51743Scale0.068480.000427
以上是基于“威布尔分布”假定条件下,计算出对应的“参数估计”结果。
第3个威布尔分布为:W(α,β,δ),其中,α>0为形状参数,β>0为尺度参数,δ≥0为位置参数。上面计算的结果为:α=exp(2.2531)=9.5174、β=0.0685、δ=0。

Parameter Estimates for Mixing Probabilities成分参数链接尺度估计值标准误差z 值Pr > |z|概率1Probability0.81060.0340923.78<.00010.45452Probability0.53050.0464011.43<.00010.3435
以上输出的是各分布在混合分布中出现的概率,第1个正态分布出现的概率为0.4545,第2个正态分布出现的概率为0.3435,而第3个威布尔分布出现的概率为1-(0.4545+0.3435)=0.2020。于是,就可以写出混合样本的概率密度函数如下:
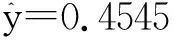

图2 本例资料的频数分布直方图与拟合的频数分布曲线图之一
若利用下面的SAS程序,可以获得与上面类似的结果,但会有较明显的变化:
proc fmm data=cattle gconv=0;
model LogInt = / dist=normal k=2;
model + / dist=weibull;
freq count;
run;
ods graphics off;
【SAS程序说明】这段SAS程序与前面那段SAS程序非常相似,其主要区别在于:前面指定了两个正态分布的“均值”与“方差”,而现在这段SAS程序没有指定参数的具体数值,完全由实际的样本数据计算而得。
【SAS主要输出结果如下】

Fit Statistics-2 Log Likelihood564431AIC (smaller is better)564447AICC (smaller is better)564447BIC (smaller is better)564526Pearson Statistic141228Effective Parameters8Effective Components3
以上是拟合统计量的有关计算结果:前5行都是关于拟合效果的评价指标及其取值,与前面相同内容作比较,AIC、AICC和BIC的数值(说明:这些数值越小越好)都变大了,说明现在的模型对资料的拟合效果有所下降。
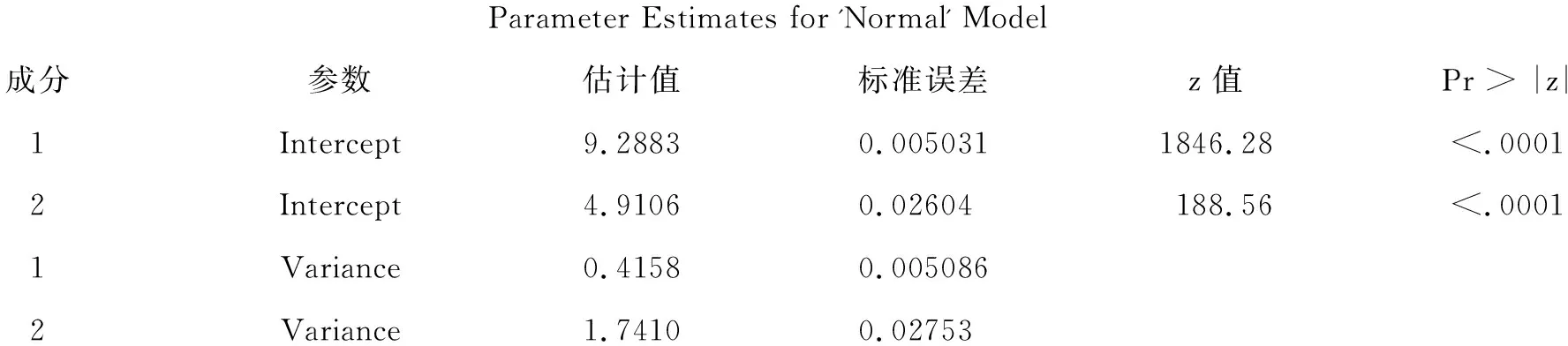
Parameter Estimates for 'Normal' Model成分参数估计值标准误差z 值Pr > |z|1Intercept9.28830.0050311846.28<.00012Intercept4.91060.02604188.56<.00011Variance0.41580.0050862Variance1.74100.02753
第1个正态分布为:N(9.2883,0.4158)=N(9.2883,0.64482);
第2个正态分布为:N(4.9106,1.7410)=N(4.9106,1.31952)。

Parameter Estimates for ' Weibull' Model成分参数估计值标准误差z 值Pr > |z|逆关联估计3Intercept1.29080.002790462.71<.00013.63583Scale0.20930.001311
第3个威布尔分布为:W(α,β,δ),其中,α>0为形状参数,β>0为尺度参数,δ≥0为位置参数。上面计算的结果为:α=exp(1.2908)=3.6358、β=0.2093、δ=0。

Parameter Estimates for Mixing Probabilities成分参数链接尺度估计值标准误差z 值Pr > |z|概率1Probability-0.82800.01922-43.08<.00010.19022Probability-0.15050.03678-4.09<.00010.3745
以上输出的是各分布在混合分布中出现的概率,第1个正态分布出现的概率为0.1902、第2个正态分布出现的概率为0.3745,而第3个威布尔分布出现的概率为1-(0.1902+0.3745)=0.4353。于是,就可以写出混合样本的概率密度函数如下:
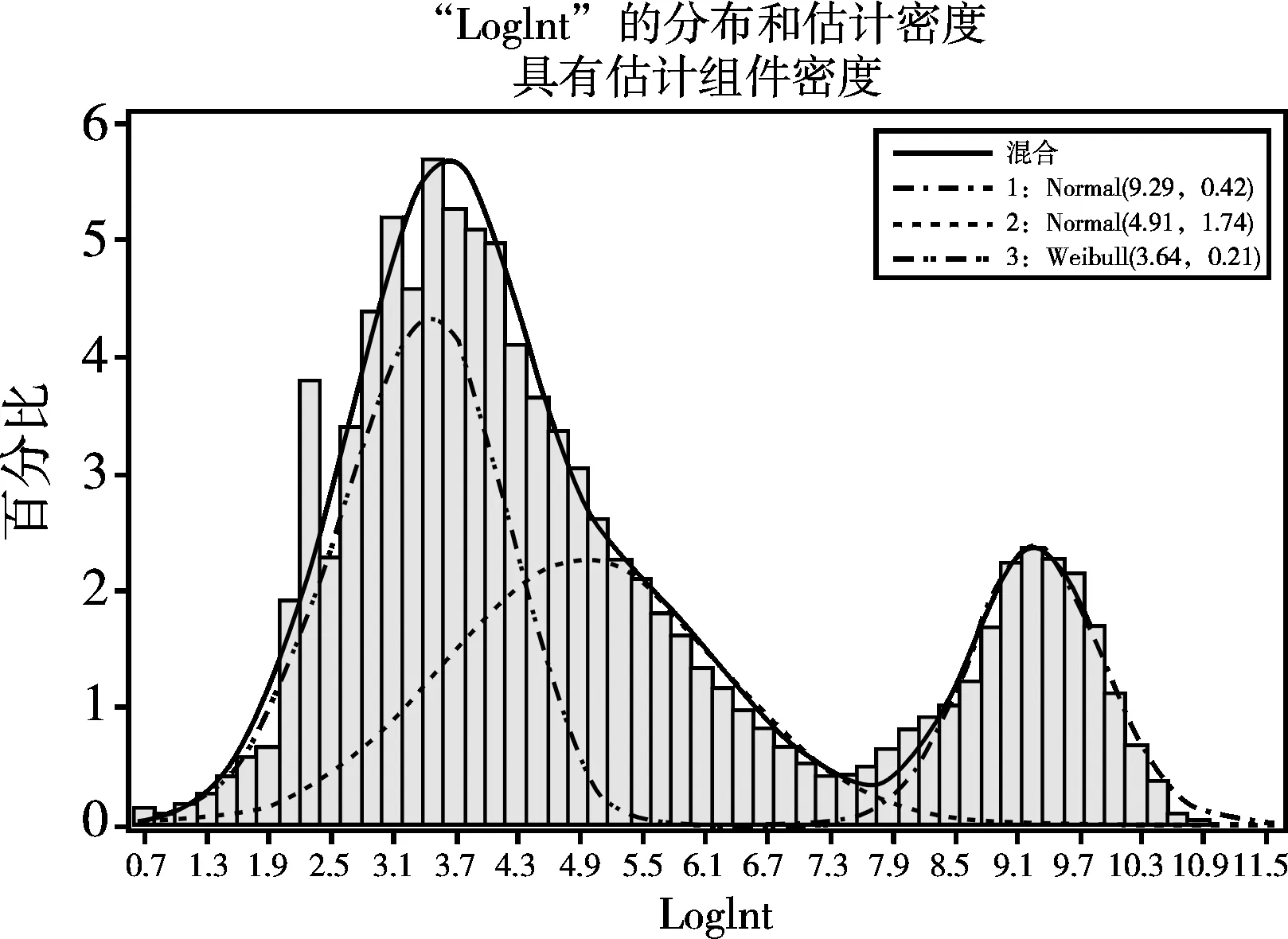
图3 本例资料的频数分布直方图与拟合的频数分布曲线图之二
文献[5]中有一个关于“1 000例血清谷丙转氨酶(SGPT)的资料”,请感兴趣的读者运用本文提供的SAS程序对“混杂样本(包括‘非肝病患者’与‘肝病患者’)”进行剖分,并与此文献中基于“G-C级数”剖分的结果进行比较。
