基于二类Logistic回归的小微企业网贷在线评估及实现
2018-09-10黄天云刘一平
黄天云,刘一平
(西南民族大学计算机科学与技术学院,四川 成都 610041)
目前,全国各类企业总数1500多万,其中小微企业占比近80%,小微企业提供了约1.5亿个就业岗位,创造了近60%的GDP[1].然而,小微企业狭窄的融资渠道、高昂的融资成本,极大的阻碍了其发展壮大.互联网金融的发展,则为小微企业的融资提供了新的途径[2].
近年来,大量文献从金融政策及对策分析、实证研究、信用评估、信贷风险控制等方面对互联网金融展开研究;研究对象包括商业银行、个人信贷、P2P网贷、以及小微企业等;研究方法包括实证分析,如商业银行系统性风险[3]、P2P网贷案例[4];统计分析和机器学习,如个人信用和信贷风险评估的Logistic回归模型[5-6]、决策树、支持向量机[7]、Bagging集成学习[8]、粒计算与信息融合[9]等.现有文献对小微企业的互联网金融信用评估和信贷风险控制的研究,以定性分析为主[1,10-11],定量分析的研究尚不多见[2].
以下对某银行9万例小微企业贷款申请数据,首先应用二类Logistic回归得到信用评估初步模型,接着对数据内在的高维特征进行深度挖掘,综合Xgboost[12]、Large-Scale SVM[13].以及 Rank 加权求和,提出一种最佳融合方案—XSL模型,并调用flask[14]实现了一个小微企业的网贷在线申请与审核可视化系统.
1 数据预处理
该银行92420例小微企业贷款申请,审核通过46320例,拒绝46100例.将数据脱敏后整理成一张表,每行对应一个申请者数据,不同列为不同的维度信息,并按如下方法进行数据清洗.
1.1 数据清洗
数值型指标统一量纲:①哑变量:01变量,是或不是的指标.比如性别的男或女,是否为本行客户等;②分类指标:用数字代替,比如教育程度,1初中及以下、2高中、3专科、4本科、6硕士、7博士及以上;还有婚姻情况等.分类型变量也可以转化成01哑变量,比如教育程度分为:是否为初中及以下、是否本科等;③文字型数据:比如备注或说明等,若倾向于分类型的话,可以关键词提取,并分类量化;④异常值剔除:通过作箱型图进行剔除;⑤空缺值补全:原本空缺的、再加上被剔除的,可以用中位值或者平均值补全.
标准化:可能包括以下情形:①越偏向某一值越好:比如年龄,越靠近35越好,min=18,max=60,标准值D=35;②越大越好:比如开业年数、雇员数、月总利润、月净收入等;③越小越好:未还贷款总额、月还款总数.
归一化:用公式f(x)=1/(1+e-x)归一化处理.
1.2 重要指标的拒贷规则分析
各指标的相关性分析如表1,与贷款通过与否相关性较高的是:之前贷款总额、婚姻情况、是否本行客户、现每月还款额4个指标.

表1 各指标相关性分析Table 1 Correlation analysis of the metrics
分析各指标拒贷率直方图,发现有以下单指标拒贷率规则:①之前贷款总额、月还款能力和现每月还款额的拒贷率分布较为均匀;②之前贷款余额大于800,000时,直接拒贷;③申请金额大于 1,000,000时,直接拒贷.
分析不同指标对贷款通过与否的影响,发现有以下拒贷规则:①之前贷款总额与申请通过成负相关,之前贷款越多,拒贷率越高;②已婚且婚姻较稳定的拒贷率较低;③之前是本行客户的话,贷款成功率相对较高;④现每月还款额越多,拒贷率越高.
2 二类Logistic回归分析
Logistic回归模型是目前最成熟、应用最广泛的分类模型.因为申请通过与否是一个二类问题,因此采用二类Logistic回归分析.首先将所有量化指标数据进行归一化处理(数据归一化),然后将所有样本随机分成5个folds,每个fold的前2/3加入到训练样本中,剩下的加入测试样本(交叉验证).运用SPSS软件对训练样本进行Binary Logistic回归分析,结果如表2.
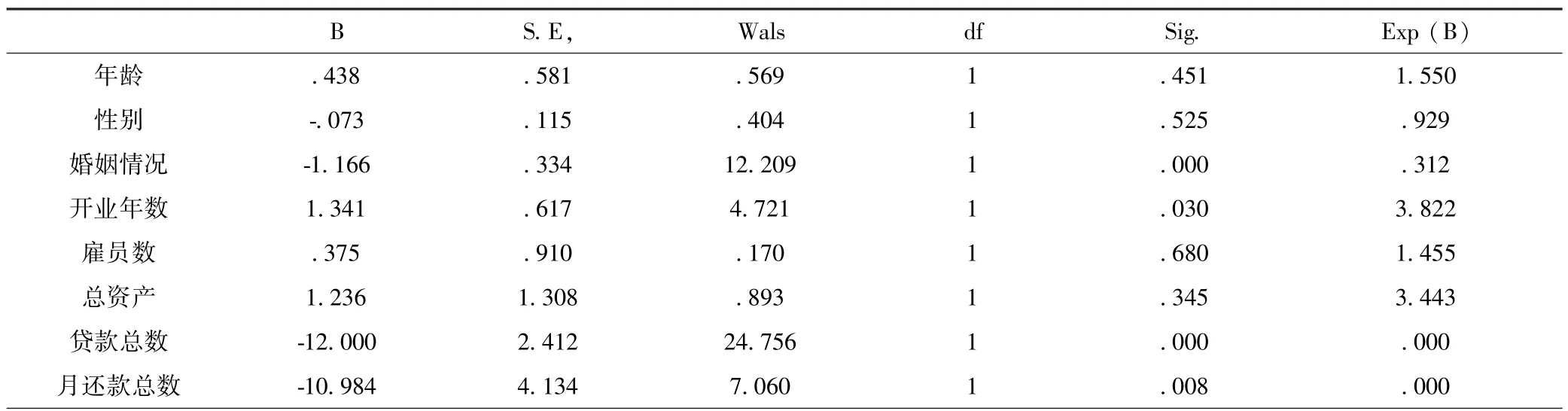
表2 方程中的变量(一致性指标)Table 2 Variables in Equation(Consistent metrics)

B S.E, Wals df Sig. Exp(B)负债 1.352 1.396 .937 1 .333 3.864是否本行客户 .714 .110 42.266 1 .000 2.042申请金额 -1.167 .996 1.374 1 .241 .311月还款能力 .509 2.400 .045 1 .832 1.663常量 -.081 .217 .138 1 .710 .922

表3 方程中的变量(全部可量化指标)Table 3 Variables in Equation(All quantitative metrics)
2.1 信用评估模型
Credit=-1.166×婚姻情况+1.341×开业年数-12.0×贷款总数-10.984×月还款总数+0.714×是否为本行客户. (1)
在训练集上检验:当信用评分为正数时,通过率比负数时高的多,如图1.
在测试集上测试:经测试得到类似结果,并作ROC曲线如图2.最终该模型的AUC=0.681,结果一般.
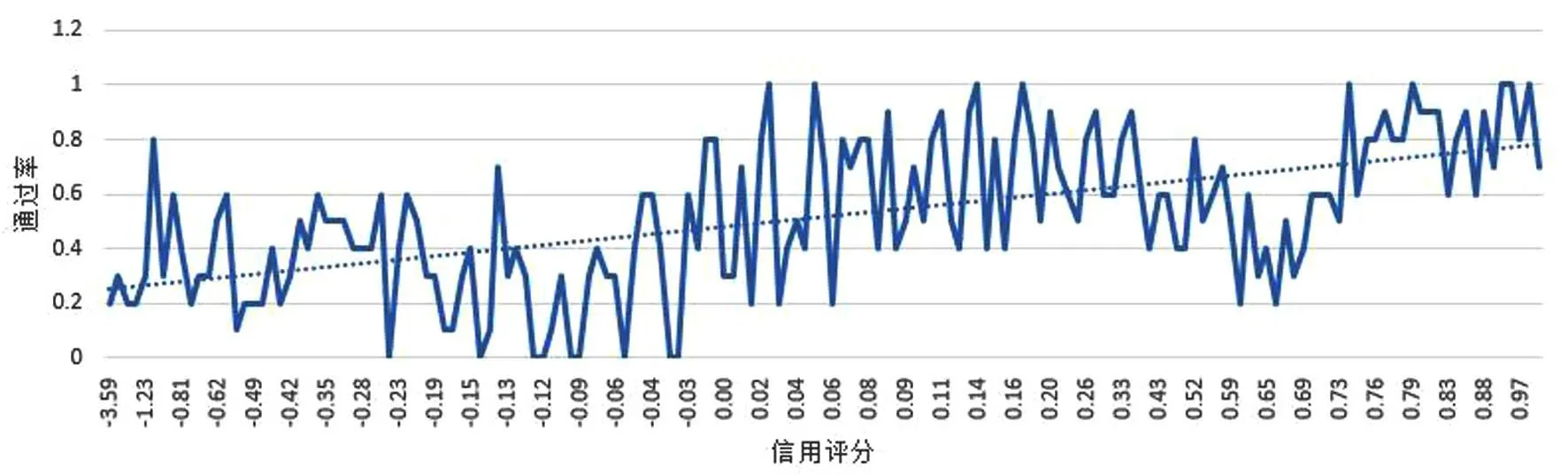
图1 一致性指标下的不同信用评分通过率Fig.1 Pass rateof different credit score(Consistent metrics)
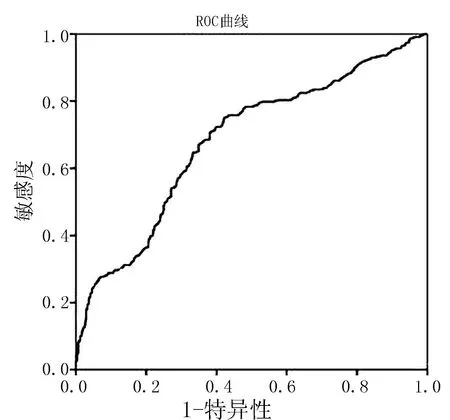
图2 测试集的ROC曲线Fig.2 ROC curve with consistent metrics in test set
2.2 模型改进
选用全部可量化的指标,如表3.得到回归方程:
Credit=-1.417×年龄-0.078×性别-0.952×婚姻情况+1.321×开业年数+0.222×雇员数+0.476×总资产-9.167×贷款总数-19.350×月还款总数+0.706×负债+0.570×是否为本行客户+-0.018×申请金额+4.809×月还款能力+0.405. (2)
结果检验 信用得分的申请通过率走势如图3;全部量化指标的ROC曲线见图4,测试集上的AUC=0.835;结果检验见表4.
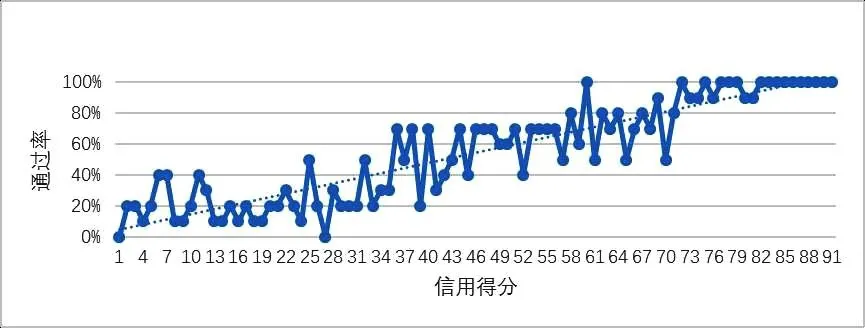
图3 全部可量化指标下的不同信用评分通过率Fig.3 Pass rateof different credit score(All quantitative metrics)
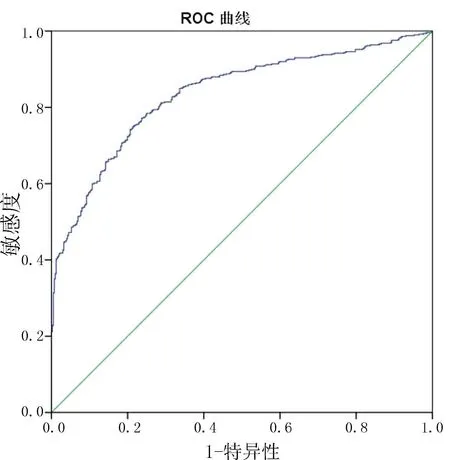
图4 全部量化指标的ROC曲线Fig.4 ROC curve with all quantitative metrics in test set
2.3 信用评估初步结论
1)经比对,最终选用全部可量化指标的信用模型,如公式(2),并记信用得分:Score=1000/(1+e-Credit);
2)经计算,当信用Score<600时,平均通过率为38%;当信用Score>600时,平均通过率为89%;
3)初步认定,运用该模型,当Score>600时,建议通过;否则建议拒绝.

表4 检验结果变量:Var00007Table 4 Variables validation
3 特征选择与模型融合
3.1 特征表达与选择
1)特征表达
地理位置:根据样本数据提供的地理位置信息,统计每个省份和城市的违约率,颜色越深代表违约率越高,如图5.对最高违约率的地区(6个)构建6维二值特征0或1(独热编码-one-hot encoding),并保留其中有判别性的列.编码结果还可以使用合并变量的方法,按城市等级如一线、二线来合并.
另外,也可将城市名用经纬度替换,这样就能将类别型变量转化为数值型变量,如北京的经纬度(39.92,116.46)可替换为两个数值型特征.加入经纬度后,线下交叉验证能有千分位的提升.
成交时间特征:按日期统计训练集中每天借贷的成交量,正负样本分别统计,得到图6,横坐标是日期(20131101-20141109),纵坐标是每天的借贷量.绿色曲线(count0)对应不违约样本,蓝色曲线(count1)是违约样本每天的数量(为了对比明显,将数量乘以2).
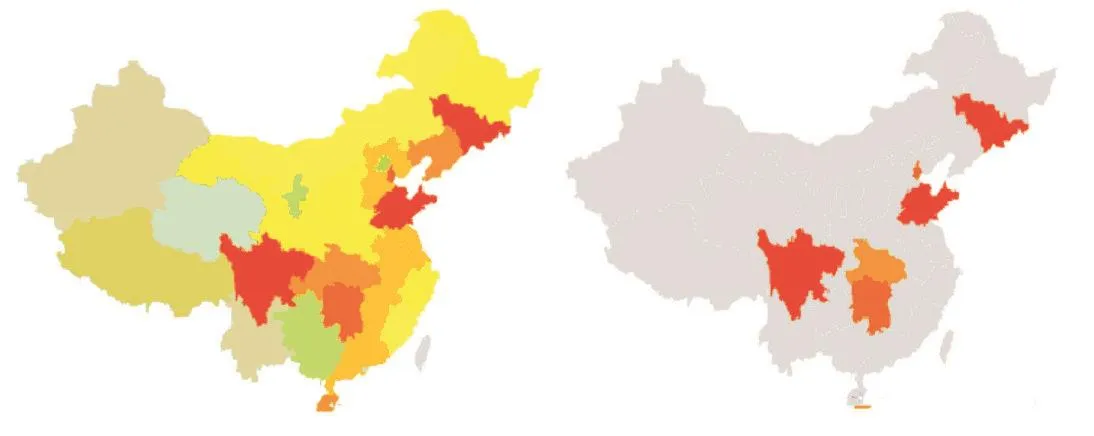
图5 省份违约率可视化(左图);突出省份违约率(右图)Fig.5 Contract break rate of provinces(left)and those most prominent(right)
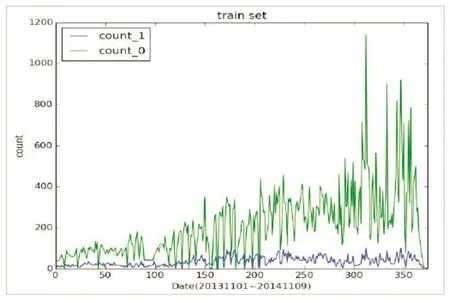
图6 按日期借贷违约情况统计Fig.6 Loan break rate statistics of each day
类别特征:除了上述类别特征的特殊处理外,其他类别特征都做独热编码.
组合特征:对判别性较高的数据特征进行整理合并,用这部分特征构建组合特征.将特征两两相除,取其中线下交叉验证值能达到0.73+的Top N个特征.
2)特征选择和降维
以下采用基于模型的特征排序法,如Xgboost来做特征选择[12].以降低特征维度.这样做的好处在于:模型的学习过程和特征的选择过程是同时进行的.Xgboost模型训练完成后可以输出特征的重要性,据此保留Top N个特征,从而达到特征选择的目的.
基于前面构建的特征,加上原始特征共有1439维.在这1439维特征上训练Xgboost.经计算,单模型交叉验证值为0.7833(在下文中,称此模型为xgb_7833).
3.2 模型训练
1)xgb子模型bagging
受bagging思想的启发[15],对单模型xgb_7833做了进一步改进.xgb_7833确定了一组不错的参数,让这些参数在一定的小范围内随机波动,同时对特征进行随机抽样,训练多个xgb子模型进行bagging.例如,xgb_7833的参数取值为0.75,而各个xgb子模型的参数则在(0.7,0.8)之间随机取值;各个xgb子模型的特征,则在xgb_7833的1439维特征上,随机抽取部分进行训练.这种方法在参数和特征上都引入了多样性(差异性),使得最后bagging的效果有较大提升,交叉验证值达0.787.模型框图如图7所示.
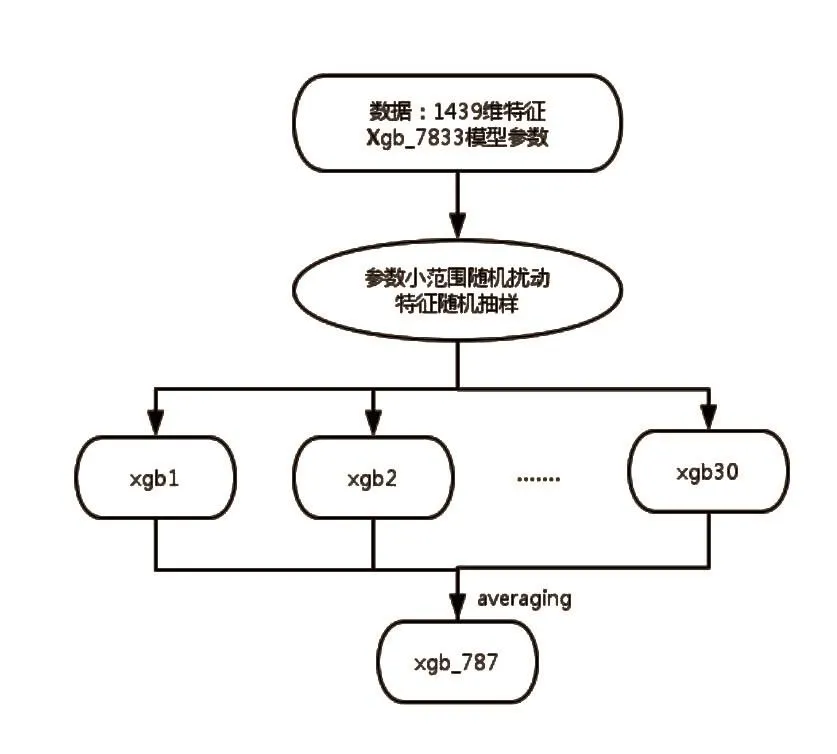
图7 Xgb子模型baggingFig.7 30 xgb sub-models are trained and bagged
2)Large-Scale SVM
为了在保证准确率的同时,减少样本训练时间,也可用SVM进行训练.SVM解决large-scale数据问题,一般采用工作集方法、训练集分解方法,或增量学习方法等[13].
本方案共训练30个svm,每个svm用到的训练数据只是原始数据的一个子集,子集产生的方式基于Bootstrap抽样,对30个svm的预测结果进行平均.经计算,验证集上的交叉验证值为0.77.
3.3 模型融合
1)模型融合方案
本框架主要实现2层的多模型融合,得到4个融合方案,如图8.
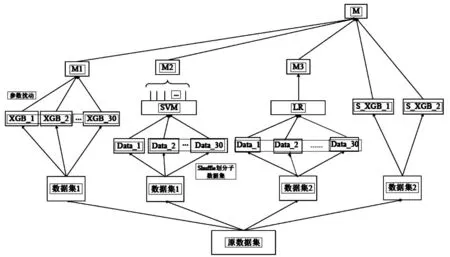
图8 模型融合总框架Fig.8 Main framework for model fusion:Xgb,SVM and LR
方案1 Bagged Xgboost:通过参数扰动生成30个不同的xgb子模型,对同一数据集进行训练产生结果,采用均值融合产生M1结果;
方案2 Large-scale SVM:通过shuffle将数据集划分为30子集,对30个svm的输出取平均产生M2结果;
方案3 LR:采用LR对输出特征进行权重训练学习,克服手工选择权重的问题,产生M3模型;
方案4 单模型:根据上面单模型交叉验证,调试出2个不同版本的最优单模型,S_XGB_1、S_XGB_2,即生成不同的单模型结果.
2)最佳融合方案—XSL模型
模型融合的关键在于模型差异性,框架中体现出的模型差异性主要在3个方面:不同模型、相同模型不同参数、不同训练数据集.因此在每次融合之前需要参考各个模型的相关性,可采用Pearson相关系数进行评价.
最上层的融合方式可以采用均值融合、rank均值融合等简单方式.最终选用的是效果最好的1/rank加权融合(按Score降序),并命名为XSL模型.经计算,模型的交叉验证值达到0.79,效果得到稳定提高.
4 网贷在线申请与审核
4.1 前置条件
申请人年龄(<18)、负债率(>1)、还款能力系数( <0.6)、申请金额( >1,000,000)、信用得分 Score(<600)等,都是拒贷的前置条件.(负债率=总负债/总资产;还款能力系数=(月净收入-申请总额/申请期数)/月净收入).
4.2 得分模型
由上述模型得到各项指标权重,并计算5个子模型得分:
1)个人信息得分=年龄×0.120929+性别×0.073707+婚姻×0.099202+教育 ×0.089850+居住状况×0.185520+在成都居住年数×0.359399+是否本行客户×0.071394.
2)生意信息得分=开业年数×0.527716+雇员数×0.209424+组织形式×0.182949+是否有营业执照×0.079910.
3)财务情况得分=负债率×0.3580+月总利润×0.1952+月净收入×0.4468. (月总利润=(月均销售额×月均利润)+月均其他收入;月净收入=月总利润-月均还款数).
4)贷款记录得分=是否有逾期记录×0.235012+是否还完银行贷款×0.197620+未还贷款总额×0.235012+月平均还款×0.332357.
5)还款能力得分=还款能力系数×0.75+自我认知系数×0.25.(自我认知系数=申请月还款数/月净收入).
总得分模型:应用公式(2),并量化为最终得分Score.
4.3 审核结果可视化
Python加载flask来搭建web框架[14].实现网贷在线申请与审核系统,并将审核结果可视化,如图9.

图9 小微企业网贷在线申请系统界面及审核结果可视化Fig.9 Online loan application and audit system for small enterprise:user interface and data visualization
5 结束语
对已有借贷企业信息各项指标的主观定性描述、定量量化、分类汇总,本身还是有一定误差的;而且由于申请人填写的信息不规范、不完整,在迭代过程中会引入二次误差,模型还有很大改进空间.
二类Logistic回归分析得到的信用评估模型不够精准,引入分类树或神经网络,效果会更明显.其他的网络信用数据,如芝麻分或京东的信用分等也可加以参考,这样能将坏账率控制到更低水平.
