Web日志挖掘中的数据预处理研究
2018-09-10于琦
于琦
摘 要:本文首先在“信息爆炸”的时代背景下提出数据挖掘和Web数据挖掘的重要性,然后针对Web日志挖掘详细讨论了其数据预处理的主要步骤及其过程方法,最后阐述了Web日志挖掘在网站建设上的应用,为后继研究提供了参考。
关键词:数据挖掘;Web日志挖掘;数据预处理
中图分类号:TP311.13 文献标识码:A 文章编号:1003-5168(2018)19-0018-03
Research of Data Preprocessing Method for Web Log Mining
YU Qi
(Library, Henan University of Economics and Law,Zhengzhou Henan 450046)
Abstract: In this paper, the importance of data mining and Web data mining was proposed in the background of "information explosion", and then the main steps and process methods of Web log mining were discussed in detail. Finally, the application of Web log mining in website construction was expounded, which provided a reference for future research.
Keywords: data mining ; Web log mining; data preprocessing
1 研究背景
在过去的十年左右,人们利用信息技术生产和收集数据的能力大大提高。许多数据库已被用于商业管理、科学研究和工程开发等领域,这一势头将继续增长。但同时,过量的信息也成了每个人都需要面对的问题,如何从繁杂的信息中及时发现有用信息并提高信息的利用率成为基亟待解决的主要问题。因此,面对这种情况,数据挖掘(Data Mining)技术应运而生,且迅猛发展,呈现出越来越强劲的生命力。数据挖掘[1]是从大量的、不完整的、嘈杂的、模糊的和随机的实际应用数据中提取隐含的、但潜在有用的信息和知识。
Web挖掘[2]是一种数据挖掘,指的是使用数据挖掘技术来发现WWW数据中潜在的、有用的模式或信息。Web挖掘研究涵盖了许多研究领域,包括数据库技术、信息获取技术、统计学、机器学习和人工智能中的神经网络。Web挖掘可以分为三类:Web内容挖掘、Web结构挖掘和Web使用挖掘[3]。Web使用模式挖掘是指Web使用挖掘,主要是挖掘网站访问日志和用户访问模式[4]。其可以提取设计者的领域知识、用户的兴趣水平和用户的访问习惯等,并获得个性化服务、用户访问控制等对网站设计者和运营商有用的决定性信息。本文主要讨论Web日志挖掘预处理的主要步骤及其处理方法,希望能为相关人员提供一些参考。
2 Web日志挖掘预处理的主要步骤
Web日志挖掘主要分为3个步骤[5]。
2.1 数据预处理
数据预处理主要包括数据清洗和事务识别。其中,数据清洗包括无关记录的剔除、判断 是否有重要的记录未被记录、用户识别等。事務识别是指将页面访问序列划分为表示Web事务或用户会话的逻辑单元。数据预处理阶段根据挖掘的目的,对原始Web日志文件中的数据进行提取、分解和合并,最后转换成适合数据挖掘的数据格式,并保存在关系数据库表或数据仓库中,等待进一步处理。
2.2 模式识别
运用各种算法对处理后的数据进行挖掘,生成模式。
2.3 模式分析
分析用户访问模式以提取有价值模式的过程。数据预处理是整个过程的基础,也是实施有效挖掘算法的前提,其在Web日志挖掘中扮演着非常重要的角色。原始日志文件是一个简单的平面文本文件,包括了一些需要处理的不完整的、冗余的和错误的数据,若不对其进行处理,将直接影响挖掘效果。另外,还需要实施一些OLAP分析和挖掘算法,同时依靠规范化的数据源,因此还需要调整数据存储格式以适应所使用的挖掘方法。
3 Web日志挖掘的预处理过程及方法
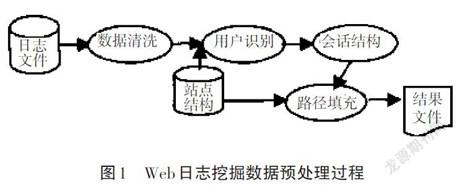
目前,市场上流行的Web服务器(如IIS、Apache等)通常为每次访问网页时保存了日志条目,其忠实地记录访问Web服务器的数据流信息[6]。日志文件可以根据客户的不同需求调整记录哪些信息。数据预处理是非常关键的一步,根据不同的情况和业务,所需要的数据是从海量原始数据中提取的,同时处理一些不完整的数据。Web日志挖掘的数据预处理包括依赖于域的数据清理、用户识别、会话识别、路径补充和事务处理识别[6]。预处理日志的结果直接影响挖掘算法生成的规则和模式。因此,预处理过程是保证Web使用挖掘质量的关键。
数据预处理是将日志文件转换为数据库文件的工作。其目的是将网络日志数据转换为适合数据挖掘的精确数据。结合数据挖掘中遇到的问题,可以将预处理过程分为以下步骤[7](如图1所示)。
分析用户访问网站的方式对为网站安排逻辑结构和制定有效的营销策略具有重要的意义。由于WWW网络的结构特点,每个网站的物理拓扑结构和用户的访问方法都不相同,且很难确定Web日志中的用户、会话或事务。因此,为了确保挖掘算法的有效性,Web日志需要进行预处理。日志预处理步骤如下。
3.1 数据清理
数据清理是指根据需求处理日志文件,包括删除不相关的数据,合并某些记录以及在用户请求页面时正确处理错误。
数据预处理的主要任务是数据清理。在分析任何形式的网络日志过程中,清除服务器日志中的无关数据非常关键。只有当服务器日志中表示的数据能准确反映用户对Web站点的访问时,通过挖掘获得的关联规则才真正有用。工作人员可以定义默认规则库来帮助删除记录,并且可以根据所分析网站的类型修改此规则库。网站可以分为普通网站、图片网站和视频网站等,相应的规则库可以单独建立。在清理过程中,应确定要分析的网站类型,并根据这些网站的规则库进行数据清理。当然,也可以根据需要修改规则库。
3.2 用户识别
由于本地缓存、代理服务器和防火墙的存在,有效识别用户的任务变得非常复杂:不同的用户通过简单的代理同时访问Web服务器;同一个用户可以在别的机器上访问Web服务器;用户可以使用不同的浏览器访问同一台计算机上的Web服务器。当不同用户使用同一台机器浏览网站时会造成混乱。为此,笔者提出以下启发式规则来识别用户[8]。①不同的IP地址代表不同的用户。②当IP地址相同时,默认不同的操作系统或浏览器代表不同的用户。③在IP地址相同,用户使用的操作系统和浏览器也相同的情况下,则判断每一个请求访问的页面与访问过的页面之间是否有链接。如果一个请求访问的页面与上一个已经访问过的页面之间并没有直接链接,则假设在访问Web站点的机器上同时存在多个用户。
一般采用的方法是基于日志站点的方法,还可以使用一些启发性规则,但使用这些规则难以保证准确识别用户,因此用户识别是个难题。
3.3 会话标识
用户会话是指用户对服务器的有效访问,通过其不断请求的页面,用户可以获得在网站上的访问行为和浏览兴趣。在跨越相对较大的时区的Web服务器日志中,用户可能会多次访问该站点。会话ID的目的是将用户的访问日志分成单个会话[9]。最简单的方法是运用超时技术,如果两页之间的时间差超过某个阈值,则假定用户开始新的会话。
3.4 路径补充
识别用户会话过程中的另一个问题是确定访问日志中的重要请求是否存在未被记录的情况。这需要路径补充来完成这些记录。路径补充的目的是完成未记录在访问日志中的用户记录并获取用户的完整访问路径,以便更准确地发现用户的访问模式。检查参考信息以确定当前请求来自哪个页面。如果用户的历史访问记录中有多个页面包含指向当前请求页面的链接,则将请求时间最接近当前请求页的页面作为当前请求的来源。如果参考信息不完整,则可以使用站点拓扑[10]。
3.5 事务的识别
在Web日志挖掘领域,用户会话是唯一具备自然事务特征的对象,但其需要特定的算法将用户会话分割为更小的事务。划分事务的主要方法是引用时长和最大前向引用。
3.5.1 引用时长。网页可以简单地分为2类:内容页面和导航页面[11]。当页面中超链接的数量达到一定数量时,可以将其视为导航页面,这是一种静态分割方法。内容页面通常是用户关心的信息,浏览时间长。导航页面是用户设置的快速查找所需信息的坐标,浏览时间短。通过估计整个日志中辅助页面的比例,可以使用最大似然估计算法来划分辅助页面和内容页面的划分时间。通过比较来划分时间,页面可以分成内容页面或导航页面,这些页面被划分成不同的事物。
3.5.2 最大前向引用。有时,一些页面会包含更多的超链接,这些是用户关心的信息。但是,其被用作内容页面。在这种情况下,事务可以由Chen[12]等人提出的最大前向参考路径(简称MFP)来定义。对于每个用户会话,从起始页面开始,每个最大的前向参考路径是一个事务。当出现前向指引时,开始新的事务。
3.6 内容和结构数据的预处理
内容和结构数据的预处理基于特定的应用程序,将Web页面中文本、图像、脚本和超链接转换为Web使用挖掘的格式。例如,根据网页的文本内容,描述与页面相关的概念主题,用于网页的聚类[13],根据网页间的超链接信息构造网站的拓扑结构图,用于识别用户。
4 结语
本文主要讨论Web日志挖掘中数据预处理的主要步骤及其方法和技术,这在挖掘过程中起着重要的作用,数据预处理的质量将直接影响最终的挖掘效率和结果。由于网站的复杂性和用户访问模式的诸多不确定性,数据预处理技术仍不完善,有待改进。例如,数据采集机制和开发技术变得更加可行,用户识别和会话识别的准确性进一步提高,算法的時间复杂度和空间复杂度需要进一步降低。这些问题的解决将为后续的模式发现和模式分析提供真实和完整的数据。
参考文献:
[1]李雄飞,李军.数据挖掘与知识发现[M].北京:高等教育出版社,2003.
[2]刘立军,周军,梅红岩.Web使用挖掘的数据预处理[J].计算机科学,2007(5):200-201.
[3]刘斌,陈桦.向量空间模型信息检索技术讨论[J].情报杂志,2006(7):92-93.
[4]Jetal S. Web Usage Mining: Discovery and Application of Usage Patterns from Web Data[J].SIGKDD Explorations,2000(2):12-20.
[5]童恒庆,梅清.Web日志挖掘数据预处理研究[J].现代计算机,2004(3):6-9.
[6]刘立军,周军,梅红岩.Web使用挖掘的数据预处理[J].计算机科学,2007(5):200-201.
[7]李烈彪,张海鹏,周亚峰.Web日志挖掘中数据预处理方法的研究[J].计算机技术与发展,2007(7):45-48.
[8]张健沛,刘建东,杨静.基于Web的日志挖掘数据预处理方法的研究[J].计算机工程与应用,2003(10):191-193.
[9]何黎明.Web日志的预处理技术[J].长江大学学报(自科版),2007(2):310-311.
[10] Cooley R,Mobasher B,Srivastava J. Data Preparation for Min-ing World Wide Web Browsing Patterns[J]. Journal of Knowl-edge and Information Systems,1999(1):5-32.
[10] Chen MS, Park J S, Yu PS.Data Mining for Path Traversal Pat-terns[A]//In: Proc.of the 16th Intl Confon Distributed Compu-ting System[C].Hong Kong,1996.
[12]Perkowitz M,Etzioni O. Towards Adaptive Web sites: Conceptual Framework and Case Study[J]. Computer Networks,1999(11–16):1245-1258.
[13]Perkowitz M. Adaptive Web Sites : Automatically Synthesizing Web Pages[C]// Proc. National Conference on Artificial Intelligence, Madison. 1998:727-732.
