基于Can树的关联规则增量更新算法改进
2018-09-08潘皓安
胡 军,潘皓安
(重庆邮电大学 计算智能重庆市重点实验室,重庆 400065)
0 引 言
关联规则挖掘是知识发现中的重要问题之一。自从1993年Agrawal教授[1]提出关联规则的概念开始,关联规则的研究一直未中断过。挖掘关联规则的关键是发现频繁项集。1994年Agrawal等提出了Apriori算法[2],利用连接和剪枝对候选项集进行处理,从而得到频繁项集;2000年Han等基于树型提出了频繁模式增长(frequent pattern growth algorithm,FP-Growth)算法[3],该算法在挖掘过程中不产生候选项,因此,较之前的算法,该算法时间优势明显,但因要存储所有频繁模式,内存占用较高。这些方法都以静态数据为研究对象,然而在实际问题中广泛存在着动态数据。为从动态数据中挖掘关联规则,人们提出了关联规则的增量更新挖掘算法。Cheung等在ICDE`96上提出了快速更新算法(fast update algorithm, FUP)算法[4]来解决在数据集增加情况下的频繁项集挖掘,其后又在1997年提出了FUP2算法[5]解决数据集减少时的频繁项集挖掘;冯玉才等于1998年提出了增量更新算法(incremental updating algorithm,IUA)算法[6]解决了支持度变化情况下频繁项集的挖掘;Koh等在2003年基于FP-tree算法提出了基于FP树的增量挖掘算法(adjusting FP-Tree for incremental mining algorithm,AFPIM)算法[7]解决数据集变化情况下的挖掘。在众多面向增量关联规则的算法中,FP-Growth改进的算法性能要比Apriori改进的算法好,但是操作远比后者繁琐[8-9]。为了方便事务的增加删除操作并保持挖掘效率,W.Cheung等[10]于2003年结合FP树和前缀树提出了压缩排列的事务序列树(compressed and arranged transaction sequences tree,CATS-tree),首次实现了“一次建立,多次挖掘”的目的;Leung在2005年在CATS树基础上改进了树节点的排列方式提出了Can树[11],Can树要求事务中的各项先按照某种顺序排序,然后再开始建树和挖掘等操作,以此再次提高了挖掘效率。
Can树(Canonical order tree)利用树型存储了所有数据,方便了数据的增删以及支持度改变后的再次挖掘。在挖掘时采用了和FP-Growth同样的方法。因为Can树比FP树更加庞大,这导致在某些情况下Can树挖掘频繁项集所需时间有可能大于FP-Growth算法,例如Sadat等[12]在2015年对Can树和FP-Growth算法进行了比较,发现在高阈值的最小支持度时,Can树的性能优于FP-Growth,但在低阈值的最小支持度时,性能不如FP-Growth算法。虽然Can树已提出了十多年,但改进方法并不多。邹力鹍等[13]在2008年采用了子父节点指针代替原先的父子节点指针,以此快速生成条件模式树,提高算法效率。陈刚等[14]在2014年提出一种基于CAN树的快速构造算法(a fast construction algorithm based on Can-tree,FCCAN),该算法同样使用子父节点指针代替原先的父子节点指针,并增加基于hash表的辅助存储结构,用于减少项目的查找时间。Roul等[15]在2014年提出了生成和归并树(generate and merge tree,GM-tree),他们保留了Can树生成的方式,在增量时对数据进行分块,每一块生成一棵树,最后再进行树合并。但是,Can树由于存储了所有数据,导致规模过大,因此挖掘效率有待提升。为了优化Can树规模,提高挖掘效率并且改善Can树的不稳定性,本文中我们提出了一种改进的基于Can树的关联规则增量更新算法,并通过实验对该算法的有效性进行了验证。
1 Can树
Can树是Leung于2005年基于CATS树改进后提出的解决关联规则增量挖掘的算法[11]。Can树采用了前缀树,并让尽量多的相同事务项合并在一起,以此来存储所有数据。算法要求事务中的每个项按照某种特定顺序进行排序后再构建Can树,排序一般采用字典序、字母序等,这样在挖掘增量关联规则的时候,新来的数据可以直接链入到原来的Can树中,不用重新构建新树以及再次扫面原来的数据,从而提高了关联规则增量更新的效率。
Can树挖掘频繁项集总共分为2步:先构建Can树,再从Can树中挖掘频繁项集。Can树的构建很简单,先将事务中的项按照字典序或字母序排序(这2种排序方法是Can树默认的),然后将排序后的事务依次插入到Can树中即可。因为,事务项已经按照统一规则排序,在插入时无须对树枝进行多余的剪枝或转换等操作。从Can树中挖掘频繁项集的过程如下。
1)从Can树节点自下而上挖掘。首先找到最下面的项,构建每个项的条件模式基;顺着Can树,找出所有包含该项的前缀路径,这些前缀路径就是该项的条件模式基(conditional pattern base, CPB);所有这些CPB的频繁度(计数)为该路径上项的频繁度(计数);
2)累加每个CPB上的项的频繁度(计数),过滤低于阈值(最小支持度)的项,构建条件FP-tree;
3)递归挖掘每个条件FP-tree,累加后缀频繁项集,直到条件FP-tree为空或者条件FP-tree只有一条路径(只有一条路径情况下,所有路径上项的组合都是频繁项集)。
Can树相对于其他增量挖掘算法的优势是可以存储所有数据,在挖掘动态数据时,省去了再次读取或扫描原数据的步骤,以此节约了时间,但缺点也较明显:因要存储所有数据而使得Can树需要占用大量内存存储整棵Can树,所以Can树的规模大小直接决定了占用的内存大小。此外,在增量挖掘时,不论是增删数据还是挖掘频繁项集,都需要遍历Can树,所以Can树的规模大小还间接的决定了Can树算法的时间效率。
2 一种基于数据量排序的Can树
根据前述,Can树的规模对算法的效率有直接影响,而当前预排列事务数据时所使用的顺序将有可能使得Can树的规模太大,从而使得算法效率较低。例如,数据集如表1所示。

表1 数据集
表1数据集已按照字母序排序,在此基础上建立Can树,则会得到如图1a所示的Can树。
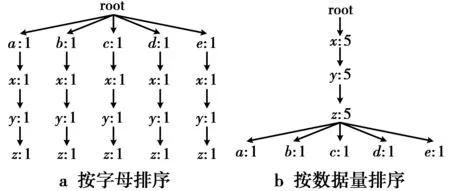
图1 数据集建立Can树Fig.1 Built Can-tree
由图1a可看出,该树中有很多节点是表示相同数据项的,例如节点a,节点b,节点c,节点d,节点e的第一个子节点都是项x,由于未能合并在一起,在挖掘树时,需要遍历整棵树,从而降低了挖掘效率。如果能够尽量让相同的数据项使用同一个树节点,则可以有效减小树规模,从而提高挖掘效率。因此,本文通过改变以往的排序方法,提出了一种基于数据量排序的Can树。具体而言就是将次数最多的数据项放在最前面,将次数最少的数据项放在最后面,这样可以让尽量多的相同数据项使用同一个节点,以此来减小Can树规模。以表1所示的数据集为例,该数据集在扫描一次数据后可得到:{a:1,b:1,c:1,d:1,e:1,x:5,y:5,z:5}。将该结果按递减排序得到一个顺序:{x,y,z,a,b,c,d,e},再将原数据项依照上面的顺序排序,如表2所示。

表2 数据集按照数据量排序
这样排序后,再进行Can树的建立,可得图1b所示的Can树。
比较图1a和图1b,可以计算出使用字母序排序建立的Can树节点数有21个(包含root节点),而使用数据量排序建立的Can树节点树只有9个(包含root节点)。可见,由于相同的数据项都使用了同一个树节点,本文的方法较原有的方法所得到的树规模小得多。
2.1 构建Can树
在首次构建Can树时,需得到一个数据量排序顺序(即原数据量顺序),在增量更新时,由于数据量在变化,数据量排序顺序也有可能发生改变,所以在增量更新挖掘时,排序顺序仍采用原数据量顺序进行排序,同时数据量排序结果仍进行更新,得到新数据量顺序,以方便挖掘时在比较该项的总计数是否低于阈值(即该项是否为频繁项)时能够直接判断使用,不用再次计算。并在建树同时,参考陈刚等[13]的改进方法,增加hash表记录每个项在树中的位置,因为初次建树和增量建树略有区别,所以实现部分稍有不同,初次建树伪码如下。
输入:原数据集DB;
输出:Can-tree,原数据量顺序data_order
1) data_order=scan(DB);//扫描数据库,获得原数据量顺序
2) for each trans in DB
3) sort(trans,data_data)//将每条事务根据原数据量顺序排序
4) insert(trans,Can-tree)//将排序后的事务插入树T中
5) end for
增量建树伪码为
输入:增量数据集db,已生成的Can-tree,原数据量顺序data_order;
输出:Can-tree,新数据量顺序new_data_order,
1) new_data_order=scan(db,data_order);//扫描增量数据库,并结合原数据量顺序,得到新数据量顺序
2) for each trans in DB
3) sort(trans,data_data)//将每条事务根据原数据量顺序排序
4) insert(trans,Can-tree)//将排序后的事务插入树T中
5) end for
2.2 挖掘Can树
Can树挖掘的流程如图2a所示。因为Can树保存了所有数据,该方法遍历所有项时就会遍历非频繁项,这样会浪费部分时间在非频繁项上。所以本文结合之前得到的数据量排序顺序对挖掘过程进行了改进。在挖掘时,根据数据量排序顺序,将数据量低于阈值(最小支持度)的项舍去,只需要构建数据量高于或等于阈值(最小支持度)的项的CPB即可,后续步骤则继续原方法,改进后的挖掘流程如图2b所示。
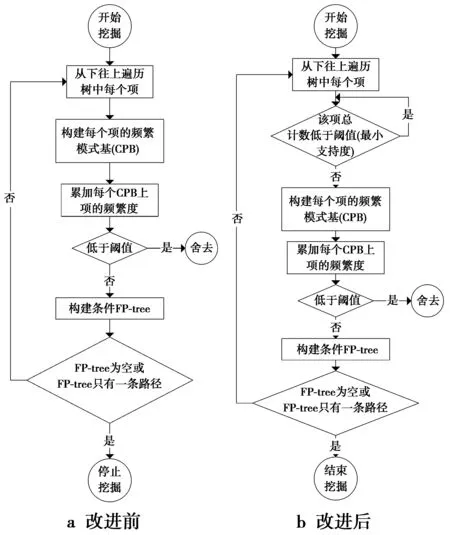
图2 挖掘Can树流程图Fig.2 Flow chart of mining Can-tree
这样可以减少遍历一些非频繁项所花的时间。改进后的挖掘伪码如下。
输入:Can-tree,最小支持度min_sup;
输出:频繁项集fre_items;
1) for item in new_data_order
2) if item.num>=min_sup
3) CPBs=add all item CPB
4) delete_unfrequentitem(CPBs)
5) CP-tree=constrct(CPBs)
6) fre_items=fre_items∩mining(CP-tree,min_sup)
7) end if
8) end for
3 实验结果与分析
实验主要从2方面进行了对比,实验1利用不同量的数据进行建树,比较了2种不同排序方法建立的Can树的规模大小;实验2通过增量挖掘比较了基于2种不同排序方法的Can树算法、FP-Growth算法、以及陈刚等提出的FCCAN算法的时间效率。
实验中使用了3个公开的数据集:①mushroom数据:共有事务8 124条,项目26个;②Groceries数据:共有事务9 835条,商品169件;③pumsb数据:共有事务49 046条,项目711件。
实验的运行环境是Intel(R)CoreTMi3-4170CPU@ 3.70 GHz,8 GByte 内存,操作系统为Windows 7 旗舰版,所有算法使用EclipseSDK(Version: 4.2.2&Java1.7.0)编程实现。
实验1表3为改进前后的2种Can树在3个数据集上所生成的节点数量的对比。结果表明,由数据量顺序排序生成的Can树规模都小于由字典序排序生成的Can树。具体而言,Can树的节点数平均减少33.7%,最多减少56.9%。可见使用数据量排序可以有效减小Can树的规模。
实验2对于mushroom数据集,基础数据量定为2 000,每次使用不同增量进行试验,试验结果如图3所示。从图3中可以看出,在增量挖掘时(图3中后4组),FP-Growth所花时间高于Can树挖掘时间,而在所有基于Can树的算法中,本文的算法在时间效率上又优于基于字典序的Can树算法以及FCCAN算法。
对于Groceries数据集,基础数据量定为1 000,每次使用不同增量进行试验,实验结果如图4所示,从图4中可看出,基于字典序的Can树算法和FCCAN算法在事务量增加较多后(后3组),其时间效率反而不如FP-Growth算法,而本文的算法依然优于所有其他算法。

表3 2种Can树在3个数据上生成的节点数量对比
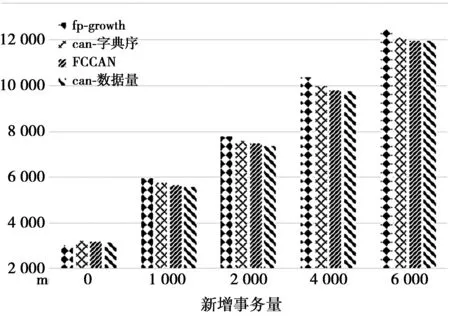
图3 mushroom挖掘时间对照Fig.3 Time comparison onmushroom

图4 Groceries挖掘时间对照Fig.4 Time comparison onGroceries
对于pumsb数据集,基础数据量定为5 000,每次使用不同增量进行试验,试验结果如图5所示。很明显,所有Can树算法均优于FP-Growth算法,并且本文的算法最优。
从以上3个数据集的对比可看出,基于字典序的Can树算法和FCCAN算法存在不稳定性[11],而本文提出的基于数据量排序的Can树算法在处理增量挖掘时具有很好的稳定性。
综上,本文提出的基于数据量排序的Can树算法在空间效率和时间效率上好于现有的Can树算法,同时具有了较好的稳定性。

图5 pumsb挖掘时间对照Fig.5 Time comparison onpumsb
4 结束语
本文针对动态数据中的关联规则挖掘,使用数据量顺序替代字典序和字母序对数据进行预处理,提出了一种基于数据量排序的Can树,并基于新的Can树对原有Can树的建树和挖掘方法进行优化,实验结果表明,本文提出的方法能够有效降低Can树的规模,提高增量关联规则挖掘的效率。这种方法还可运用在分布式、多源数据等多种环境中,这将是本文下一步的研究工作。
