基于低秩自动编码器及高光谱图像的茶叶品种鉴别
2018-08-31靳海涛武小红沈继锋戴春霞
孙 俊 靳海涛 武小红 陆 虎 沈继锋 戴春霞
(1.江苏大学电气信息工程学院, 镇江 212013; 2.江苏大学计算机科学与通信工程学院, 镇江 212013)
0 引言
茶叶以其清热、解毒等功效深受广大消费者喜爱[1-2],但目前茶叶市场存在以次充好的现象,严重损害消费者权益,也影响经营者的管理,因此,有效、准确的茶叶品种鉴别是十分有必要的[3]。传统的鉴别方法主要是感官判别法和化学试验分析法,这些方法主观性较强、破坏性大、不易推广[4]。视觉图像技术[5]可以通过外部特征进行茶叶品种鉴别,但该方法无法获取茶叶内部的特征信息[6];光谱技术[7]因能检测样品内部特征信息,且具有速度快、成本低等优点在农副产品品种鉴别领域得到广泛关注,但光谱技术在处理数据时缺少样本的空间信息,这两种技术的侧重点不同,所带来的局限性必然会影响最终的鉴别效果。因此,如何结合各种鉴别手段,提高茶叶品种鉴别的精度是一个新的研究方向。
高光谱图像技术作为一种快速无损检测的方法,将图像技术和光谱技术结合,融合两种技术的优势,对研究对象的内外部特征同时进行检测,近些年已被广泛应用于农副产品的定性分析中[8-11]。然而,因为高光谱数据量庞大,波段繁多,且相邻波段间相关性强[12],所以对数据进行降维处理显得极其重要。随着深度学习技术的发展[13-15],自动编码器(Stacked auto-encoder,SAE)通过输出对输入的重构从而对高维数据进行特征学习,该技术已被推广到图像处理、数据分类的应用场合中[16-17],与高光谱图像技术的结合也越来越受到关注。
图1 茶叶样本 Fig.1 Tea samples
但是,高光谱图像在获取过程中不可避免地受到各种干扰,例如高斯白噪声、稀疏的冲击噪声、坏死的线条等[18-19]。这不仅使图像的视觉效果变差,更对高光谱图像的实际应用造成很大的影响。因此对高光谱图像进行去噪处理[20-21]至关重要。传统的自动编码器也常被应用于降噪处理,降噪自动编码器(DAE)[22-23]假设训练数据是干净的,它所针对的噪声是人为添加来训练的。然而,受噪声影响的真实数据是不符合上述假设的。因此,从实际的已被破坏的数据中学习深层特征,对于构建鲁棒的特征提取器来说是非常关键的。就目前所知,这种基于自动编码器的深度学习方案以前并没有被讨论过。
近几年来,低秩矩阵恢复(Low-rank matrix recovery,LRMR)的方法被引入到高光谱图像恢复领域中,取得较好的效果。LU等[24]采用低秩矩阵恢复的方法去除高光谱图像中的坏死线噪声,考虑局部的几何结构并添加了图的正则化;ZHANG等[25]基于低秩矩阵恢复的方法较为成功地去除了高光谱图像的混合噪声,其正是得益于无噪的高光谱图像数据低秩的特性。由于这些技术的优点,低秩矩阵恢复已经成功地应用于不同的场景,例如多视点学习、转移学习和字典学习[26-27]。 然而,并没有相关文献将低秩矩阵恢复与深度学习框架联系起来。
为更加有效地进行茶叶高光谱图像品种鉴别,本文联合优化自动编码器和低秩矩阵恢复,构建低秩自动编码器(LR-SAE),在自动编码器的降维基础上加入去噪处理,提取高光谱数据鲁棒判别特征,建立茶叶品种的鉴别模型。
1 材料与方法
1.1 材料准备
试验前于镇江某大型超市购买5个不同品种的绿茶:炒青茶(安徽黄山)、龙井茶(浙江)、毛峰(江苏宜兴)、云雾绿茶(浙江)、碧螺春(江苏苏州),样本如图1所示。每种茶叶取80个样本,分别放入广口试剂瓶中,并贴上标签,共计400个样本。将其密封保存立即送往高光谱实验室进行高光谱图像采集。
1.2 高光谱数据采集及处理

图2 高光谱成像系统结构图 Fig.2 Configuration diagram of hyperspectral imaging system 1.移动平台控制器 2.高光谱图像摄影仪 3.光纤 4.卤素灯光源 5.处理器 6.样本 7.移动平台
本试验所采用的高光谱成像系统结构如图2所示,主要包括光纤、2个光纤卤素灯(2900型,Illumination Technologies, USA)、高光谱图像摄影仪(ImSpector V10E, Spectral Imaging Ltd., Oulu, Finland)、移动平台控制器(北京光学仪器厂,中国)和处理器等部分。高光谱图像摄影仪中的摄像机为CCD相机,光谱仪为可见-近红外光谱仪,光谱范围为431~962 nm,光谱分辨率为2.9 nm,图像分辨率为1 628像素×1 125像素。
采用直径6.4 cm、高0.7 cm的塑料圆形器皿均匀放置茶叶样品,将圆形器皿放置在移动速度为2.1 mm/s的移动平台上进行数据采集,将光源与样本距离设置为6 cm,相机镜头距样本12 cm。
感兴趣区域(ROI)是样本图像中选取分析的重点区域,感兴趣区域的选取对后续的试验质量至关重要。如图3a所示,为系统扫描得到的茶叶样品高光谱图像,本文统一提取高光谱图像中心区域100像素×100像素部分为感兴趣区域。图3b为茶叶样本高光谱数据。
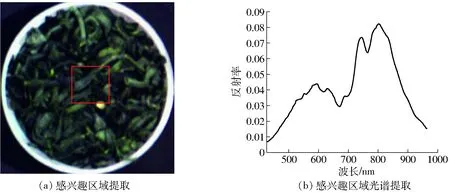
图3 感兴趣区域提取与分析 Fig.3 Extraction and analysis of region of interest
高光谱图像数据的采集使用Spectral cube软件平台(Spectral Imaging Ltd., Finland);ROI提取采用ENVI. 5.1(Research System, Inc., USA);最终试验模型训练是在CPU为Intel Core i5 3230M 2.60 GHz、内存为8 GB的Windows 10系统下,利用Matlab R2014b软件完成的。
1.3 低秩自动编码器
1.3.1SAE深度模型
自动编码器(AE)自RUMELHART等[28]初次使用之后,就广泛应用于特征学习。自动编码器主要由编码器和解码器两部分构成,在对输入数据进行学习时,其目的是通过编码和解码将输入数据在输出中重构出来。从某种程度而言,AE是一个小型的深度学习模型,该模型主要包括输入层、隐含层和输出层3部分。
假设无标签训练样本x,自动编码器的编码任务是将输入的训练样本通过非线性映射函数映射到隐含层,其数学表达式为
h=f(x)=sf(Wx+bh)
(1)
式中h——隐含层激活值
sf——编码激活函数
W——输入层与隐藏层之间的权值矩阵
bh——输入层与隐藏层之间的偏移向量
自动编码器的解码任务是将激活值h逆向转换成对输入x的重构y,其数学表达式为
y=g(h)=sg(W′h+by)
(2)
式中y——激活值反向变换成对原始输入的重构
sg——解码激活函数
W′——隐含层与输出层之间的权值矩阵
by——隐含层与输出层之间的偏移向量
平均重构函数为
L=‖x-y‖2
(3)
通过不断修改参数来最小化平均重构函数L。对于最小平均重构L,y就可以被认为保留了原始数据的大部分信息[29]。
实际应用中,多采用包含多个隐含层的自动编码器网络进行数据处理,即堆叠自动编码器(SAE)。通过引入神经网络天然的非线性,SAE更适用于高光谱数据处理等非线性任务。
1.3.2低秩矩阵恢复
当高光谱图像受到高斯白噪声的微小扰动时,含噪的高光谱数据Y∈Rn×b可以分解成一个低秩的矩阵X和一个微小扰动的矩阵E,低秩矩阵恢复的目的就是以一种最优手段将Y分解出含尽量少噪声的X和噪声矩阵E。
当矩阵E服从独立同分布的高斯分布时,可用经典主成分分析通过奇异值分解来完成数据降维[25],即求解优化问题
(4)
式中Emin——矩阵E的最小范数
‖·‖F——矩阵范数r(·)——矩阵的秩
然而,当数据中存在比较大的噪声或异常时,E的元素为任意大小,此时主成分分析的效果不够准确。针对这种情况,恢复低秩矩阵X成为一个双目标优化问题。
(5)
式中 ‖·‖0——矩阵0范数,为矩阵中非零元素的个数
E0min——矩阵E的最小0范数
通过引入折中因子λ,并对目标函数进行松弛,将双目标优化问题转换为单目标问题
(6)
式中E1min——矩阵E的最小1范数
‖·‖*——矩阵核范数,为矩阵奇异值之和
‖·‖1——矩阵1范数,为矩阵元素绝对值之和
式(6)也称鲁棒主成分分析法[30],使用增广的拉格朗日乘子法[31](Augmented Lagrange multipliers,ALM)解决上述优化问题,先将其转换为等价问题

(7)
式中L(·)——拉格朗日函数
D——拉格朗日算子
μ——惩罚因子
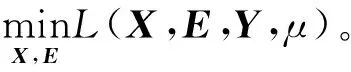
1.3.3低秩自动编码器模型
本文结合低秩矩阵恢复的去噪优势和自动编码器的降维优势,构建了低秩自动编码器模型,在自动编码器的降维基础上,添加了去噪处理。该模型的训练步骤如下:
(1)采用低秩矩阵恢复的方法,对提取出的ROI中的高光谱数据进行LR分解,得到一个低秩矩阵X和一个稀疏矩阵E,X是进行去噪处理后的目标矩阵,E是噪声矩阵。
(2)初始化自动编码器网络中权值矩阵W、偏移量b、动量m等模型参数,将低秩矩阵X作为输入进行降维训练,降低到一个较低维度。
(3)用5折交叉验证的方法将降维后的数据以4∶1的比例分成训练集和预测集输入到分类器中,进行品种鉴别。
(4)以最终的预测集准确率为依据,对自动编码器网络中W、b等参数寻优,寻找自动编码器最优参数。
整个算法模型构建算法流程图如图4所示。

图4 算法流程图 Fig.4 Flow chart of algorithm
1.4 基于线性核函数的支持向量机分类算法
支持向量机(SVM)算法[32]作为一种经典的分类算法,被广泛应用在高光谱图像的分类中,其主要思想是作一个非线性映射F(x),将输入数据空间映射到高维空间,通过寻找一个最优分离曲面,使得两类数据的间隔尽可能大,以完成分类任务。在进行训练时,要挑选合适的核函数K(x,y)=(F(x),F(y)),同时,对于样本集(X,Y),设置合适的惩罚系数c和径向量函数g,可以获得优化问题的最优解。
本文结合SVM算法和低秩自动编码器算法,将低秩自动编码器处理后的低维高光谱数据采用5折交叉验证方法进行交叉验证,以4∶1的比例分为训练集和预测集,然后和5个茶叶样本的标签集构建分类模型进行分类试验。由于本试验样本较少,基于线性核函数的SVM模型效果更优,采用灰狼优化算法对SVM分类器效果影响较大的参数c和g的设置进行优化,以期得到最优SVM分类模型。
1.5 基于Softmax模型的分类算法
Softmax回归是逻辑回归的推广,逻辑回归是处理二分类问题的,而Softmax回归是用来处理多分类问题的[33]。它是一种监督模型,表示为逻辑回归函数的形式[34]为
(8)
式中H——激活函数
z——用自动编码器模型提取出的特征表示
经低秩自动编码器提取的特征输入Softmax模型。利用有监督学习获取参数,完成模型的构建,通过分类试验对模型的参数进行微调,得到较优模型。
2 结果与分析
2.1 高光谱特征降维
通过软件ENVI 5.1计算ROI内各个像素点的反射率,并求其平均值作为每个样本的反射率,据此绘得5种茶叶样本的原始光谱曲线,如图5所示。不同品种的茶叶样本内部的有效成分(如氨基酸、多酚类和植物碱等)的含量与比例存在差异[35],这些有效成分大多存在含氢基团(C—H、O—H和N—H等),能在某些特定波长下产生倍频和合频吸收,表现为对光的吸收强度不同,即表现为不同的反射率[10],在波长为600 nm左右和760 nm左右处的波峰来看,这种差异尤其明显。

图5 5种茶叶样本原始光谱曲线 Fig.5 Raw spectral curves of five kinds of tea samples
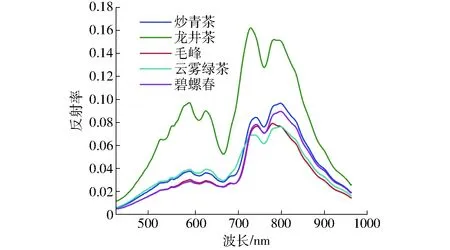
图6 5种茶叶样本平均光谱曲线 Fig.6 Average spectral curves of five kinds of tea samples
对每种茶叶样品的反射率求平均值,得到5种茶叶样本的平均光谱曲线如图6所示,在2个波峰处光谱曲线有明显的可分辨性,为茶叶品种鉴别提供了依据。
在茶叶样本高光谱数据分类之前,要对其进行去噪和降维处理。本文采用改进后的低秩自动编码器对高光谱数据进行特征学习,提取低维特征,试验中发现,SAE的深度、规模等参数都会对其最终的特征学习结果产生影响。本次试验以分类准确率为标准,选取SAE网络层数和规模2个影响较大的因子进行对比,通过结果的分析来确定最佳参数的设置。本试验中自动编码器的激活函数为sigmoid函数,学习率设置为0.2,由于SAE需将输入数据降低到一个较低维度,所以将SAE第1个隐含层神经元个数设置为300,第2个隐含层神经元个数从1取到300,得出最终的训练集和预测集准确率如图7a所示,结果显示,当第2个隐含层神经元个数为193时,预测集准确率最高为98.59%。增加SAE隐含层数量,用同样的方法在后续增加SAE隐含层训练,以最终预测集准确率为标准寻找最优的隐含层神经元个数,结果如图7b~7d所示。
每次增加SAE隐含层数量,训练获得最优隐含层神经元个数,其对应的训练集准确率和预测集准确率如表1所示。
由此可见,预测集准确率并未随着网络层数的增加而提高,当SAE隐含层个数为3,网络规模为[618-300-193-56]时,同时,原始高光谱波段数为618,经过SAE特征提取,特征数为56,SAE-SVM模型最终预测集准确率达到最大98.82%,降维效果明显。继续增加隐含层个数,提高了网络复杂度,加大了训练成本,然而最终提取输出的特征数差别并不大,且最终预测集准确率有减小的趋势,故本文选择4个自动编码器进行堆叠级联为SAE,应用于最终模型。
2.2 分类结果验证
根据SAE、LR-SAE、SAE-LR(对SAE输出层进行低秩矩阵恢复处理)降维模型处理之后的低维特征高光谱数据,采用5折交叉验证的方法,分别采用SVM分类器和Softmax回归模型进行分类建模,得出训练集和预测集的准确率如表2所示。
首先采用SAE对高光谱数据进行降维,对得到的低维特征数据分别应用SVM和Softmax分类器建模,经过灰狼优化算法,最优c=33.86,最优g=0.86,SAE-SVM模型预测集分类准确率最高为98.82%,同时,SAE-Softmax模型预测集分类准确率为97.99%,较高的分类效果说明了采用深度学习自动编码器模型对于高光谱数据的高效特征提取能力。

图7 低秩自动编码器降维结果 Fig.7 Results of dimension reduction with LR-SAE

隐含层个数神经元最优个数模型规模训练集准确率/%预测集准确率/%2193[618-300-193]99.2398.59356[618-300-193-56]99.8898.82437[618-300-193-56-37]99.8298.33527[618-300-193-56-37-27]99.5696.87
注:模型规模表示SAE各层神经元个数,如[618-300-193]表示输入层有618个神经元,该网络包含的2个隐含层神经元个数分别是300、193,并以最后一个隐含层作为整个网络的输出。

表2 各模型分类结果 Tab.2 Results of each model classification
从2个分类器角度分析,对于SVM分类器来说,经过SAE降维处理之后,高光谱数据由618维降到56维,最终训练集准确率为99.30%,预测集准确率为98.82%,而经过LR-SAE降维之后,高光谱数据由618维降到31维,维度更低,最终训练集准确率高达99.75%,预测集准确率高达99.37%,与SAE降维后的数据分类准确率相比,LR-SAE处理过后的数据的分类准确率有一定的提升,验证了去噪处理的有效性,通过低秩矩阵恢复的处理,提取了原始高光谱数据的低秩少噪声甚至无噪声的鲁棒特征。
对于Softmax回归模型而言,SAE降维之后的预测集准确率为97.99%,而应用改进之后的LR-SAE降维之后的预测集准确率高达99.04%,从另一个角度验证了LR-SAE降维模型去噪处理的有效性。
同时,无论是SVM分类器,还是Softmax回归模型,与对SAE输入层进行低秩矩阵恢复处理的效果相比,对SAE输出层进行低秩矩阵恢复处理的效果略差,这是由于经过SAE降维后的数据中,数据的物理意义弱化,信号与噪声的界限没有原始数据那么明显。
3 结束语
以茶叶品种鉴别为研究背景,针对高光谱数据信息量大、维度高的问题,本文提出了一种新的高光谱数据降维方法,该方法应用深度学习中的自动编码器模型,将其处理非线性数据的优势应用于高光谱数据的降维中,结合低秩矩阵恢复,建立了低秩自动编码器(LR-SAE)降维模型。首先采用SAE、LR-SAE和SAE-LR模型分别对茶叶高光谱数据进行降维,在得到的低维特征的基础上分别建立SVM和Softmax分类模型,对5个茶叶品种进行分类。试验结果显示,低秩自动编码器处理高光谱数据,将最初的618维数据降低到较低维度,并将获得的低维特征用于分类建模, LR-SAE-SVM预测集分类准确率高达99.37%,LR-SAE-Softmax预测集分类准确率达99.04%,效果优于改进前的SAE算法。改进之后的低秩自动编码器为高光谱数据的降维提供了一种更加高效的方法,尤其是对于含噪声较大的高光谱数据,对高光谱图像分类来说具有重要的实际意义。
