异构复合迁移学习的视频内容标注方法
2018-08-28饶文碧
谭 瑶,饶文碧,2*
(1.武汉理工大学计算机科学与技术学院,武汉430070; 2.交通物联网技术湖北省重点实验室(武汉理工大学),武汉430070)(*通信作者电子邮箱wbrao@whut.edu.cn)
0 引言
由于对用户视频的人工标注常常会出现标注缺失、不全以及标注过于主观的问题,这就导致了传统的基于文本的视频检索和分类越来越不适应当前用户视频集[1-2]。而基于视频内容的标注能够更加高效、智能地对用户视频进行检索和分类,因此它一直作为计算机视觉领域重要的研究课题[3]。目前基于视频内容的标注需要人工收集和标注大量的训练样本才能够取得较好的泛化能力和鲁棒性,然而收集和标注训练样本又是一项非常费时费力的工作,因此本文利用迁移学习的思想,从日趋成熟的互联网图像搜索引擎中获取大量的领域知识,进而将这些知识迁移到视频领域,用以完成视频标注任务。
近年来,迁移学习在多媒体内容分析领域引起了学者的广泛重视[4-7]。Redko 等[8]利用非负矩阵分解(Non-negative Matrix Factorization,NMF)技术来最小化领域间投影的距离,进而提出了一种完全无监督的领域适应方法。Fernando等[9]通过学习一个映射矩阵来对齐源域和目标域的子空间,在对齐后的共同空间中训练模型完成知识迁移。然而他们提出的领域适应方法都是假设源域和目标域的样本能够被表示成相同维度和同种类型的特征,这与本文描述的领域间异构不一致。Wang等[10]利用典型相关性分析[11-13]去获得异构特征的公共特征子空间,解决了特征空间异构的问题。张博等[14]提出了一种跨领域的典型相关性分析(Canonical Correlation Analysis,CCA)的迁移学习方法,该方法保持了领域特有特征和共享特征之间的相关性,通过选择合适的基向量组合来训练分类器,使降维后的相关特征在领域间具有相似的判别性,但是CCA是一个监督学习的过程,这也使得这种方法不是完全无监督的。杨柳等[15]提出了一种异构直推式迁移学习(Heterogeneous Transductive Transfer Learning,HTTL)的算法,该算法采用无监督匹配源领域和目标领域特征空间的方法来学习映射函数,学习到的映射函数能够将源领域数据在目标域中重新表示,该算法是一个普适性的解决方法,但是针对本文描述的特定迁移问题,并不一定能够取得良好的表现。目前有关使用互联网图像来进行视频标注的研究比较少。Duan等[3]提出了一种利用互联网图像来对用户视频进行事件识别的方法,该方法将图像特征和视频特征分开处理,并没有考虑这些异构特征之间的内在联系。王晗等[16]联合学习了图像特征和视频特征,提出了一种跨领域的结构化模型(Cross Domain Structural Model,CDSM),但是这个模型缺乏对源领域和目标领域同构后的特征空间的比较。
本文利用视频与其关键帧的对应关系,借助CCA来建立图像和视频两个异构域之间的同构链接,之后在这两个同构空间中进行子空间对齐得到最终的公共子空间。借助这个公共子空间,从图像域学习的分类器就能够直接分类视频域数据。具体的学习框架如图1所示。

图1 异构复合迁移学习框架Fig.1 Heterogeneous compound transfer learning framework
1 问题描述
本文研究的目标是提出一种异构直推式迁移学习方法,用于解决将互联网图像的知识迁移到用户视频领域并完成标注任务的问题。异构直推式迁移学习是在源域中有标注数据,而在目标域中没有标注数据的知识迁移问题[17]。
假设有一个带标注的图像域和一个无标注的视频域,图像域和视频域的特征空间不相同,但是它们预测的类别空间是相同的。定义图像域(源域)为Ds=(χs,P(xs));视频域(目标域) 为Dt=(χt,P(xt))。xs和xt分别表示源域和目标域的样本数据,P(xs)和P(xt)分别表示源域数据的特征空间χs和目标域数据的特征空间χt的分布。另外,本文定义Y是源域和目标域共同的类别空间。其中,x={,n是源域样本ss的数目,这里∈ Rds,ds表示源域图像特征的维度;xt={,nt是目标域样本的数目,这里∈ Rdt,dt表示目标域视频特征的维度;Y={,这里∈R,c代表源域和目标域的类别个数。
2 异构空间的同构化
由于当前大量的领域适应方法是基于这一假设:源域和目标域的样本数据能够表示成同种类型、同一维度的特征。也就是说,这些方法适用于同构化空间内的知识迁移。然而,本文研究是一个异构空间下的迁移问题,无法直接利用当前较为成熟的领域适应方法。受到文献[10]的启发,本文采用典型相关性分析来学习两个映射矩阵ωs∈Rdc×ds和ωt∈Rdc×dt,其中dc是同构空间的维度,任意源域和目标域的样本数据都能够分别通过这两个映射矩阵投影到相应的同构空间上,之后就能够在同构空间上解决具体的领域适应问题。
2.1 同构空间
本文使用典型相关性分析(CCA)方法来学习两个映射矩阵。CCA广泛应用于非自然语言的知识迁移中,传统的CCA方法通常是有监督的,但是本文中视频域的数据都是无标注的,因此不能直接使用CCA来将源域和目标域进行同构化。然而,结合本文所研究的具体问题,可以利用视频和其关键帧的对应关系,为CCA提供一种监督信息。为了得到更具普适性的解决方案,也可以利用一定数量的带标注目标域和源域数据之间的对应关系来实现同构化。给定n个样本对{(,),(,),…,(,)},其中∈Rds和∈ Rdt分别表示源域图像(或目标域视频关键帧)和视频样本数据,记Xs=[x,…]∈ Rds×n,Xt= [,,…,]∈ Rdt×n。CCA的目标是学习两组基向量ws∈Rds和wt∈Rdt,使得线性组合u=Xs和v=Xt之间的相关系数最大,即:

其中:Css=∈ Rds×ds和 Ctt=∈ Rdt×dt分别表示 Xs和Xt的自相关矩阵;Cst=Xs∈ Rds×dt表示 Xs和 Xt的协方差矩阵,并且有Cst=。
2.2 问题求解
使用Lagrange乘子法,构造Lagrange函数:


结合式(3)~(5)可将原问题等价转化为以下特征值问题:
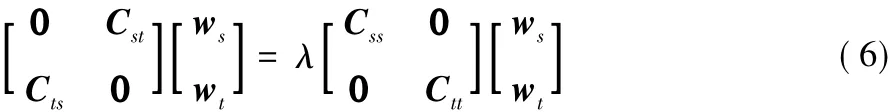
取dc=min(rank(Xs),rank(Xt)),映射矩阵的前dc个特征值对应了dc个基向量,即所求解的ωs和ωt。
3 同构空间下的对齐化
经过第2章的同构化操作,可以得到同构空间下的源域和目标域数据:

目前解决这类同构空间下知识迁移的方法有很多,本文结合当前子空间对齐的思想,提出了一种基于最小代价的子空间对齐模型。在这个模型中,本文提出了一个代价函数,用来表示源域和目标域特征空间向共同子空间投影的代价,通过最小化代价函数,可以得到子空间对齐的矩阵。最终,可以将源域特征翻译到目标域特征空间中,也就完成了从源域到目标域知识迁移的过程。
3.1 特征降维
为了尽量避免过拟合问题,并且加速模型的收敛,本文对源域和目标域的数据进行特征降维。常用的降维方法有主成分分析(Principal Component Analysis,PCA)和非负矩阵分解(NMF)。Yang等[18]在标准的NMF基础上提出了正交投影的非负矩阵分解(Orthogonal Projective NMF,OPNMF)。Redko等[8]在 MNIST数据集上应用 PCA、标准 NMF和OPNMF得到分解后矩阵的稀疏值分别是:0.2994、0.4912和0.5400。由此可以看到,正交约束确实能够提高稀疏性,而稀疏性的提高对于数据去噪有着重要意义,所以本文选用OPNMF来完成特征降维。OPNMF定义如下:

其中:X∈Rm×n是输入矩阵;U∈Rm×d是分解得到的基向量矩阵;d是最终降到的目标维数。
Xs和Xt经过OPNMF特征降维后分别得到两个基向量矩阵 Us∈ Rdc×d和 Ut∈ Rdc×d。
3.2 子空间对齐模型
考虑到源域和目标域投影到公共子空间的代价,提出一种最小化代价函数:

其中:U*是Us和Ut共享子空间的基向量矩阵;Hs和Ht分别是Us和Ut分解得到的矩阵。
由Frobenius范数的正交不变性,可以重写式(8)如下:

根据式(9)可以得出最优化的结果是:

至此,可以得出子空间对齐的转换矩阵M=Hs,使得Ut=UsM。通过转化矩阵M,源域的特征能够被翻译到目标域的特征空间中。
3.3 问题求解
使用Lagrange乘子法,构造Lagrange函数:

其中,Λ1和Λ2是引入的拉格朗日乘子,这是两个对角矩阵。
为了解决上述问题,引入3个辅助函数G(U*,U*')、G(Hs,Hs') 和 G(Ht,Ht'),它们满足:

定义如下:

通过构造:
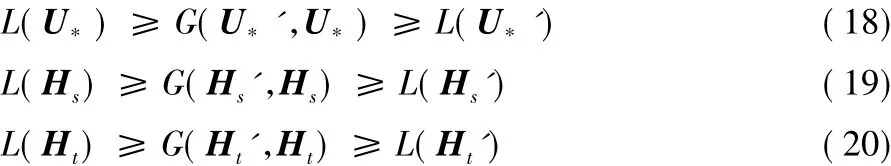
使得能够迭代地应用式(15)~(17)来得到一个闭合解。
首先求解U*的迭代更新公式:
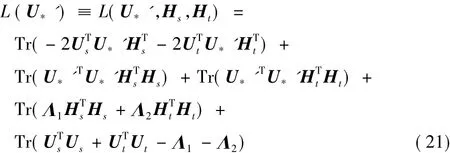
构造辅助函数:
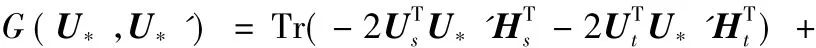
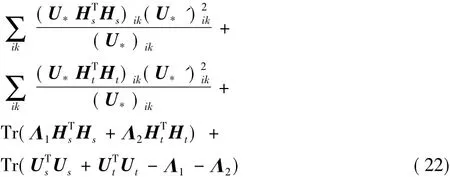
其中式(21)放大到式(22)是利用引理1得来。引理1[18]对任意矩阵 A ∈,W ∈和 W'∈,有:

式(24)即为U*的迭代更新公式。继续求解Hs的迭代更新公式:
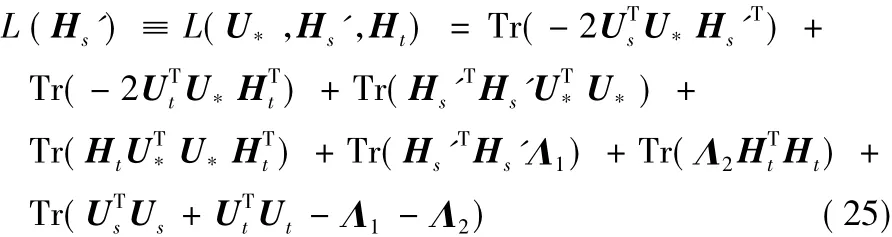
构造辅助函数:

使用KKT(Karush-Kuhn-Tucker)条件有:
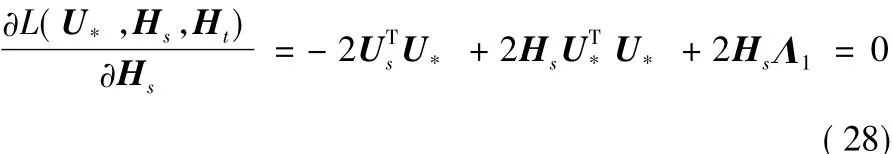
可得:Λ1=(UsHs-U*)TU*。由式(9)最优化结果U*=UsHs,有Λ1=0,因此Hs最终的迭代更新公式为:
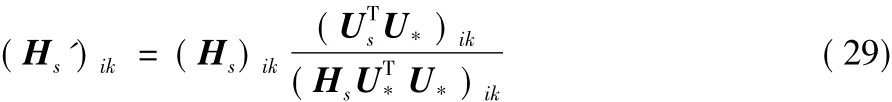
由于对称性,易得Ht的迭代更新公式为:

至此,最小化代价函数得以求解,相应地,转换矩阵M也得以求解。
3.4 模型算法
由于图像域和视频域的异构性,本文提出了一种基于异构复合迁移学习 (Heterogeneous Compound Transfer Learning,HCTL)的视频标注方法,该方法利用CCA将原本异构的特征空间同构化,之后构造源域和目标域向共同空间投影的最小代价函数,以此习得子空间对齐的转换矩阵,最终将源域的特征翻译到目标域的特征空间中,完成问题中的知识迁移。具体的算法步骤如下。
算法1 异构复合迁移学习(HCTL)算法。
输入 源域数据集Xs,源域数据集Xt,源域标签集Ls,迭代次数niter;
输出 预测目标域标签集Lt。
1) 由CCA习得两个映射矩阵ωs和ωt
2) Xs← ωsXs
3) Xt← ωtXt
4) Us←OPNMF(Xs)
5) Ut←OPNMF(Xt)
6) for i←1 to niterdo

7) Ss=XsUsHs
8) Tt=XtUt
9) Lt=Classifier(Ss,Tt,Ls)
3.5 性能分析
通过最小化代价函数可以得到子空间对齐的转换矩阵M,结合3.4模型算法的第7)步,有:

因为Ut是正交分解而来,满足UTtUt=I,可以重写式(31)为:

定义A=UsM,再结合3.4节模型算法的第8)步,可得:

由此可以看出A=UsM就是将源域特征翻译到目标域特征空间中的转换矩阵。
受Fernando等[9]工作的启发,可以通过证明A存在一个上界来说明提出的对齐转换矩阵M具备稳定性和防过拟合性。
引理2[8]对任意向量x,有‖x‖≤B。是Cn正交分解后的前d个特征向量,是与前d+1个特征值(λ1>λ2>… >λd>λd+1>0)相关的的期望值,Hn和H分别是和非负矩阵分解得来的。对任意,至少有1-δ概率有:

根据引理2,可以推导出定理1,定理1表述如下。
定理1 Usn(Utn)是样本大小ns(nt)的源域(目标域)的正交映射算子,而Us(Ut)是与前d+1个特征值λs1>λs2>… >>(>>… >>)相关的Usn(Utn)的期望值,Hs(Ht)和Hsn(Htn)分别是Us(Ut)和Usn(Utn)非负矩阵分解得来的。至少有1-δ概率有:
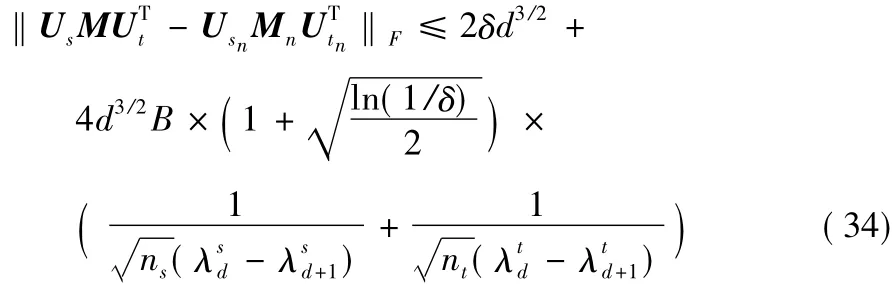
其中,Mn=Hsn。
证明:

通过定理1可以发现A存在一个上界。
4 实验结果与分析
4.1 实验数据和特征
本文采用两个真实世界的用户视频数据集来检验和评价HCTL方法。
Kodak数据库:该数据库包含了真实用户上传的195个视频,并且这些视频带有正确的标签。该视频数据库按照事件类别可分为 6 大类:birthday、parade、picnic、show、sports、wedding。
CCV数据库[19]:该数据库是由哥伦比亚大学收集的用户视频数据集,其中包含了4659个训练视频和4658个测试视频,并且所有视频都被正确标注为20个大类。由于本文研究的是有关视频事件的标注,因此排除掉CCV数据库中的非事件视频(如 beach、bird、cat、dog 和 playground),并且为了方便处理,本文将一些子类进行了合并。最终形成了以下11个事件类别:basketball(bask)、baseball(base)、biking(biki)、birthday(birt)、graduation(grad)、parade(para)、performance(perf)、soccer(socc)、sports(spor)、swimming(swim)、wedding(wedd)。
对于图像数据,本文通过互联网图像搜索引擎来获取。具体来说,就是将前面提到的两个视频数据库中的事件名作为关键字在互联网图像搜索引擎中进行检索。对于每一类事件,本文选择前300张图片作为初始源域数据集。
针对每一张源域图像,本文提取其128维尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)特征来作为图像特征。而对于每一个视频,结合2.1节空间同构的需求,则提取两种特征:视频特征和关键帧(图像)特征。对于Kodak和CCV数据库中的视频数据,本文分别提取96维的梯度方向直方图(Histogram of Oriented Gradient,HOG)特征和144维的时空兴趣点(Space-Time Interest Point,STIP)特征作为其视频运动特征。另外,从每个视频中随机选取7个关键帧并提取其SIFT特征来作为关键帧(图像)特征。
4.2 实验设置
在本文实验中,采用词袋模型来表示图像和视频特征。具体来说,先提取所有图片的SIFT特征并且利用k-means方法将这些特征进行聚类,得到2000个聚类中心,之后通过统计每一张图片中SIFT特征在这2000个聚类中心出现的词频来将图片特征量化为一个2000维的词频特征。同样地,对于Kodak和CCV数据库中的视频特征也采用上述方法分别得到2000维和5000维的视频特征。
针对某一个事件,实验选择前面收集的300张图片作为正样本,然后随机从其他事件中选择300张图片作为负样本。而对于视频样本,从Kodak数据库选择全部195个视频作为训练样本,并且从CCV数据库选择筛选后的训练视频来作为训练样本。
为了验证本文提出的HCTL方法,本实验将设置两种与标准的支持向量机(Standard Support Vector Machine,S_SVM)方法、领域适应支持向量机(Domain Adaptation SVM,DASVM)方法[20]、HTTL 方法、CDSM 方法、领域选择机(Domain Selection Machine,DSM)方法[3]、异构源域下的多领域适应(Multi-domain Adaptation with Heterogeneous Sources,MDA-HS)方法[21]和判别性相关分析(Discriminative Correlation Analysis,DCA)方法[22]之间的对比实验。第一种是在目标域(视频域)数据完全无标注的假设情况下进行的,用以说明HCTL方法在无监督学习下的表现;第二种是用少量的带标注目标域(视频域)数据来辅助训练目标分类器,用以说明3.2节的子空间对齐迁移学习模型在少量的带标注数据的训练下的表现,这里的带标注数据是从目标域中随机选取的,根据Kodak和CCV数据集大小的不同,选取的数量分别为{5,10,20}和{20,50,100},并且为了防止选择的偶然性,在本实验中会独立重复3次,然后以这3次的均值作为最后的实验结果。S_SVM方法和DASVM方法是对分类和领域适应下分类的基础方法,通过实验对比能够得出HCTL方法的有效性。HCTL方法是综合了HTTL方法和CDSM方法在解决此类问题中存在的缺陷而提出的,因此在此设置对比实验来证明HCTL方法在此类问题上具有更好的表现。DSM和MDA-HS方法是当前使用互联网图像完成视频标注经典的解决方法,而DCA是近年来表现最好的异构领域适应方法,通过对比实验能够说明HCTL方法的效果。
本实验使用平均准确率(Average Precision,AP)来作为评价的标准,并且将mAP(mean AP)作为所有事件的平均AP值。
4.3 结果分析
在目标域无标注数据的假设前提下,将HCTL方法与4.2节提到的7种方法在Kodak和CCV数据库上进行对比实验,实验结果如图2所示,并且在表1中列出了在这两个数据库上的mAP结果。
通过分析图2可以得出,没有任何一种方法能够在所有的事件上都取得最好的效果,导致出现这一现象的原因可能是不相关源域的图片影响了较好分类器的学习过程。从表1可以看出,所有方法在CCV数据库上取得的标注准确率均显著低于Kodak数据库,这可能是因为CCV数据库中包含的事件类别更多并且也更为复杂,但是本文提出的HCTL方法在这两个数据库上均取得了最好的mAP结果,这也表明了HCTL方法的稳定性。
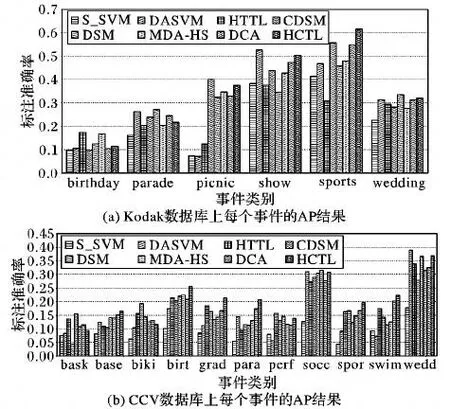
图2 不同方法在不同数据库上每个事件的AP结果Fig.2 Per-event AP of different methods on different datasets
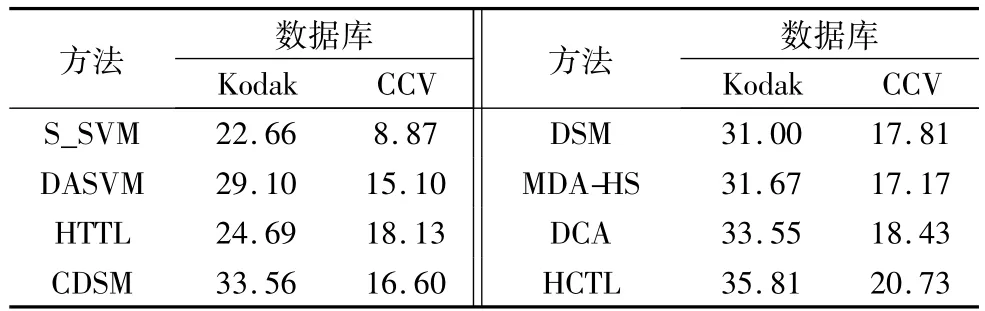
表1 不同方法在Kodak和CCV数据集上的mAP结果 %Tab.1 mAP results of different methods on Kodak and CCV %
在Kodak数据库上,本文提出的HCTL方法在标注效果mAP上比 S_SVM、DASVM、HTTL、CDSM、DSM、MDA-HS和DCA 方法相对提高了 58.03%、23.06%、45.04%、6.70%、15.52%、13.07%和 6.74%;而在 CCV 数据库上,分别相对提高了 133.71%、37.28%、14.34%、24.88%、16.40%、20.73%和12.48%,这也验证了HCTL方法的有效性。
在第二种对比实验的设置下,本文将HCTL方法与4.2节提到的7种方法在Kodak和CCV数据库上进行对比,实验结果分别如表2和表3所示。
从表2和表3可以得出,随着带标注目标域数据数量的增大,标注的mAP结果有了显著的提升,这也验证了HCTL方法的有效性。另外,综合表1~3可以看出,加入少量的带标注的数据可以使得迁移模型在分类准确率上有较大的提升,出现这一结果的原因可能是3.2节的子空间对齐迁移学习模型只能利用领域间相似的知识来完成分类标注任务,但是加入少量的带标注数据后,迁移模型能够利用这部分目标领域的知识将源领域大量相似的知识更加准确地迁移过来。
最后,本文实验设置了从视频中提取不同数量关键帧的对比实验,用以说明帧数对标注效果mAP的影响,实验结果如图3所示。
从图3可以看出,当帧数提高到7帧时,mAP显著提升,但是继续增加帧数,mAP只有很小的提升。因此,本文实验设置从视频中提取的关键帧数为7。

表2 在Kodak数据库上,不同方法使用不同数量标注数据的mAP结果 %Tab.2 mAP results of different methods using different number of labeled data on Kodak %

表3 在CCV数据库上,不同方法使用不同数量标注数据的mAP结果 %Tab.3 mAP results of different methods using different number of labeled data on CCV %
5 结语
本文提出了一种异构复合迁移学习(HCTL)方法用以解决将知识从互联网图像迁移到用户视频,最终在视频领域完成基于内容的标注。实验结果表明,HCTL方法采用的先同构再对齐的复合迁移思想是有效的。在同构化过程中,CCA需要监督信息,本文方法借助视频和其关键帧的天然对应关系可以提供这种信息,并且针对更一般化的问题,本文方法也可以使用一定数量带标注的目标域和源域数据来完成,但是后者不是一个完全无监督的过程。另外,本文方法没有考虑多源域情况下的知识迁移问题,为了习得更好的目标分类器,下一步可以研究多源域下的视频内容标注问题。
