双通道卷积神经网络在文本情感分析中的应用
2018-08-28戴月明吴定会
李 平,戴月明,吴定会
(江南大学物联网工程学院,江苏无锡214122)(*通信作者电子邮箱lplp12@126.com)
0 引言
随着互联网技术和各大电商平台的快速发展,网络购物变得越来越简单也越来越流行,用户对于各类商品的评价也变得越来越频繁,对于网络购物的体验不同层次的消费者也提出了不同的需求。高效快速地对消费者的评论进行分析和统计,更加深入地了解消费者的需求,成为众多电商平台提升自身平台竞争力的重要方式。
文本情感分析即文本情感倾向的分析,实际就是对文本中语言态度、观点、情感倾向等信息的挖掘[1]。目前文本情感分析的主要技术方向分为两类:基于情感词典的文本情感分析和基于机器学习的文本情感分析[2]。近年来,随着互联网的发展,数据量的急剧增加,对于海量数据的处理需求也越来越高,深度学习就是在这种背景下应运而生,深度学习算法对于处理比较大的数据相比较于传统的机器学习算法有着明显的优势。2006年Hinton等[3-4]提出了深度置信网络结构,该算法在深度学习领域起了里程碑式作用。深度学习可以充分利用海量的文本数据,完全自动地学习抽象的知识表达,在计算机视觉[5]、语音识别和自然语言处理[6-7]等方向取得了显著的成绩。很多基于深度学习的模型都取得了很好的效果,其中最具代表性的有卷积神经网络(Convolutional Neural Network,CNN)[8]和循环神经网络(Recurrent Neural Network,RNN)[9],其中RNN因为其强大的上下文语义捕捉能力,在序列建模任务上表现出色,如机器翻译[10],但是RNN是一个有偏的模型,在构建整个文本语义时会倾向于后面的文本,但是实际应用中并不是所有的文本重点都放在后面,且RNN的优势是捕捉长距离的信息,对于以句子为主的文本情感分析这一任务并不适用。相比RNN模型,在文本情感分类任务中,评论语句往往很短,不用综合全局信息就可以判断评论的情感倾向。文献[11]中首次提出了CNN用于句子分类,并用实验证明了CNN算法用于句子分类的可行性,但是文章主要针对英文语料进行处理;Kalchbrenner等[12]提出了动态CNN(Dynamic CNN,DCNN)的模型,该模型采用动态K-Max池化,区别于传统的最大池化只保留一个重要信息。文献[13]提出了Seq_CNN,模型以one-hot作为卷积神经网络的输入,但是该方法造成文本表示的空间维度较高;文献[14]提出了以卷积层作为特征提取,支持向量机(Support Vector Machine,SVM)作为分类器,用于图像分类。CNN在文本情感分析中的应用主要以单通道为主,这种方法存在视角单一、不能充分地认识数据的特征的问题,双通道主要来源于计算机视觉,一幅图由RGB三个颜色通道组成,反映了图像不同状态下的特征。Kim[11]分别采用静态词向量和动态词向量作为模型的通道;但考虑到中文文本的复杂性,本文提出了把字向量和词向量作为模型的两个通道,字向量用于捕获句子的细粒度信息,词向量用于捕获句子间的语义信息,利用细粒度的字向量辅助词向量捕捉深层次语义信息。利用多尺寸卷积核,以找出合适的“粒度”,提取更充分的文本特征。经过实验验证得出,本文提出的双通道CNN(Dual-Channel CNN,DCCNN)模型泛化能力强,在情感分类方面的正确率和F1值远远高于普通卷积神经网络算法。
1 卷积神经网络
CNN是一种经典的前馈神经网络,主要受生物中感受野的概念启发而提出。CNN早期的应用主要是在计算机视觉领域,并在计算机视觉领域取得了很大的成功。随后大量学者把它应用于自然语言处理,卷积神经网络可以学习到句子中抽象的特征且无需人工干预,学习到的特征可以单独使用,作为其他分类器的输入或者直接进行情感分类任务。它的多层结构能够发现句子内部更高层次抽象特征并且在可接受时间范围内完成训练,所以卷积神经网络更适合句子级的情感分类任务。CNN的结构主要有三个方面的特性:局部连接、权值共享和下采样。传统的神经网络都采用全连接的方式,这使得网络参数巨大、训练时间较长,卷积神经网络的出现解决了这一问题。对于文本来说,局部的信息往往包含的特征比全局更多,通过局部连接可以提取数据的初级特征;在CNN中,同一个卷积核,其所有的神经元权值都相同,一个卷积核只提取一种特征。局部连接和权值共享减少了神经元的连接数目,这大大降低了神经网络的训练难度。一个普通的卷积网络,主要包括卷积、池化、全连接三个部分,一般卷积层直接和输入连接,通过卷积层获得特征之后,如果直接使用这些特征训练分类器,需要面临着巨大的计算量,容易造成网络的过拟合。因此,通常采用下采样来减小网络的规模,用池化操作实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个文本进行表示,经过池化进一步降低了计算的复杂度。
2 词向量与字向量
现有的产品评论文本类型多样,传统的文本表示和基于统计的方法,仍停留在对词汇的表层处理,比如词袋模型(Bag-Of-Words,BOW)或者是向量空间模型(Vector Space Model,VSM),这样的浅层模型默认单词之间相互独立,只包含词频信息,忽略了文章的上下文信息,无法表达相关性,对文本的语义表达造成了极大的损失,词向量的出现避免了使用传统特征表示产生的一些问题。鉴于CNN中较低层次相当于“特征提取器”,卷积神经网络能够学习到句子中的抽象特征并且无需人工干预。本文针对这点,采用细粒度的字向量辅助词向量(Word2Vec)捕捉更深层次的语义信息。
词向量因为其在捕捉语义信息和句法信息方面的强大功能,在自然语言处理中引起了极大关注,所谓词向量就是通过神经网络训练语言模型,并在训练过程中生成一组向量,这组向量中的每个词用n维向量表示。对于文本情感分析这类任务而言,数据量小,所以相对而言一个轻量级的模型便可以达到一个很好的处理结果。但是在训练卷积神经网络时参数量通常很大,为了避免模型陷入过拟合的危险,本文采用预先训练的词向量来减轻过拟合问题。文献[15]提出,在大规模的语料上训练得到的词向量可以改善模型的性能。
字向量作为中文处理的基本单位,在中文文本分析中起着重要作用,使用字向量的目的主要是为了解决未登录词的问题,比如:“这个房间高大上”分词的结果为“这个/房间 /高大/上”,这个句子中“高大上”为一个词,分词后把它切分为两个词,这样导致分词后的词组反而改变了句子的语义信息。为了减弱分词后带来的问题,模型的另一个通道采用字向量作为输入,通过细粒度的字向量辅助词向量捕捉深层次的语义信息。
3 双通道卷积神经网络
在中文文本处理中,每个句子可以切分成很多字或词,隐藏层的每个节点与输入的每一个局部区域连接,为了将文本中词与词、字与字之间的信息加入到文本建模过程中,实现对评论中每个局部信息进行建模,分别采用词向量和字向量作为两个不同的模态,将文本中的词序等信息通过卷积,池化等操作融入文本向量中。
DCCNN模型主要包括三个部分:第一部分采用京东等电商平台的大量评论分别训练词向量和字向量,使得模型可以更接近训练样本的分布。第二部分根据中文文本的特点设计两个通道的卷积神经网络,把词向量和字向量作为不同的通道,主要应用于处理不同环境下所产生的不同数据的融合。词向量在语义方面的刻画更精细些,字向量更能反映文本的基本特征。第三部分通过不同尺寸的卷积核,发现句子内部更高层次抽象的特征,以提取更优质的文本特征。本文采用的双通道卷积神经网络模型结构如图1所示。

图1 双通道卷积神经网络模型结构Fig.1 Dual-channel convolutional neural network model structure
3.1 DCCNN 模型构建
DCCNN模型的构建主要由四个部分组成,分别为查找层、卷基层、池化层以及合并层。
1)查找层:首先采用Word2Vec训练词向量,通过预训练的词向量和字向量可以避免直接训练词向量带来的参数过大问题,一定程度上避免过拟合。假设词向量的维度为k,每个评论的长度为n,Xi为第i个词的词向量,所以一个长度为n的评论可以描述为:

其中:⊕表示连接操作符;Xi:i+j表示词向量Xi,Xi+1,…,Xi+j组成的特征矩阵。对于输入的评论数据,根据其索引值,从预训练的词向量中,查找出对应词的词向量,生成词向量矩阵。
2)卷积层:卷积层的主要目的是通过卷积操作实现对文本数据的局部感知,本文通过使用不同尺寸的卷积核对输入的词向量与字向量进行卷积运算,以尽可能地捕获更多的上下文信息。本文分别使用了卷积核h=3,h=5和h=7三组不同的卷积核,假设:b为偏置项,Wh表示不同尺寸的卷积核对应的权重矩阵,Wh∈Rh×k。D1和D2分别表示词向量通道和字向量通道,卷积后的输出为Chi,代表不同的卷积核输出的结果,计算公式如下:
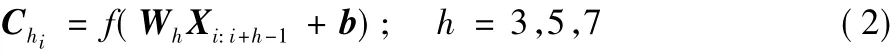
为提高训练收敛速度,激活函数f采用Relu函数[16]。
本文使用步幅s=1的卷积,当卷积核在评论为n的文本上滑动结束后,共得到n-h+1个输出,所以最终生成的一个特征图为:

其中C为不同卷积核卷积后生成的特征图集合。
3)池化层:为了生成固定维度的特征向量以及减弱卷积操作之后带来的数据维度过高问题,往往加入池化操作。本文采用最大池化,对每个通道单独执行池化操作,经过最大池化操作后,模型忽略弱的特征并提取出具有代表性的情感极性特征。最大池化公式如下:

其中C(2)为经过不同卷积核最大池化后生成的特征图集合。
假设每组卷积核的数量为m,最终池化后输出的特征集合为C(3),C(3)定义如下:


3.2 DCCNN 模型训练
合并层输出的特征向量将作为最后sigmoid分类器的输入,最终输出情感类别的预测值的定义如下:

4)合并层:把两个通道D1和D2所提取的特征序列进行串联,整合出全局信息,形成最终的文本向量集合C(4)。

由式(8)可知Loss≥0,假设训练样本的标签为y=1,可知Loss=-ln(),当≈1时,此时Loss=0;当训练样本标签为y=0时,可知Loss=-ln(1-),当≈0时,此时Loss=0。所以当损失值接近0时,训练样本值和实际输出值越接近。模型训练通过Adam算法[17]最小化目标函数,通过反向传播算法进行参数更新。
4 实验结果及分析
4.1 数据集与模型参数设置
本实验采用的语料集主要包括路由器、计算机、手机等相关电子产品相关的中文语料库以及谭松波老师整理的书评,酒店评论等,经过人工整理,共收集26 925条评论数据,类别已经给定,其中积极评论13578条、消极评论各13338条。数据集网址为:https://pan.baidu.com/s/1o9pYXYi。为了验证本文算法的有效性,选取其中80%作为训练语料,20%作为测试语料。实验计算机环境为:Intel Core i7-4790CPU@3.60 GHz,内存 8 GB,Linux 操作系统。
本文所提模型的参数设置如表1所示。

表1 DCCNN参数设置Tab.1 DCCNN parameter setting
4.2 评价标准
本文对文本情感分类的评价标准主要从分类的正确率和F1进行度量。对于给定样本容量为N,样本xi的实际标签为yi,分类标签为^,正确率(Accuracy)计算公式为:
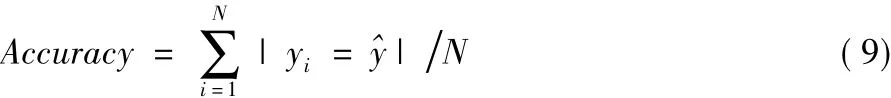
F1为精准率和召回率的调和平均值,假设精准率为P,召回率为R,具体计算公式如下:

其中:TP表示被分类器正确分类的正例数据;TN表示被分类器正确分类的负例数据;FP表示被错误地标记为正例数据的负例数据;FN表示被错误地标记为负例数据的正例数据。
4.3 实验步骤
实验步骤如下:
1)首先对原始文本应用结巴分词。
2)采用Word2Vec训练词向量,语料采用爬虫爬取的各大电商的评论数据,训练词向量的语料。
3)把词语转换成词序列,经过处理后的数据,每个词都有唯一索引。
4)把带索引值的词语输入词向量表中,查找出对应词的词向量,生成矩阵作为模型的输入。
5)把原始文本转化成单个字存储。
6)采用Word2Vec训练字向量,语料为训练样本集。
7)把字转换成字序列,经过处理后的数据,每个字都有唯一索引。
8)把带有索引的字输入字向量表中,查找出对应字的字向量,生成矩阵作为模型的输入。
9)采用式(8)的损失函数,开始训练模型。10)采用测试集评估模型性能。
4.4 模型对比结果
实验一 为了验证DCCNN算法的有效性,采用DCCNN算法与以下几种经典算法进行对比:
1)逻辑回归分类算法(Lg):采用Word2Vec训练词向量,句子向量采用词向量的平均值,逻辑回归分类器进行情感分类。
2)静态词向量(Static_CNN)[11]:模型训练过程中,词向量保持不变。
3)非静态词向量(Non_Static_CNN)[11]:模型训练过程中,词向量会被微调。
4)随机初始化词向量(Rand_Static)[11]:模型训练过程中,词向量随机初始化。
5)多通道卷积神经网络(S_Non_CNN)[11]:采用静态词向量和非静态词向量两个通道进行卷积运算。
6)CNN+SVM:采用CNN作为特征提取器,SVM作为分类器。
7)Seq_CNN[13]:以 One-hot作为 CNN 模型输入,进行卷积运算。
这里主要采用回调函数,选取测试集正确率最高的作为模型的正确率和F1值。模型名称以及其正确率和F1值结果如表2所示。
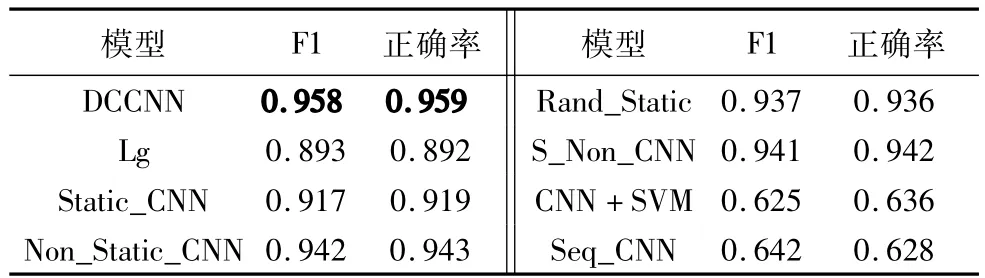
表2 不同模型下的分类结果Tab.2 Classification results under different models
从表2可以看出:DCCNN的正确率和F1值分别取得了0.958和0.959。CNN+SVM 和Seq_CNN取得了相对较低的分类结果,这是因为Seq_CNN的输入特征忽略了句子的语义信息,SVM对于卷积后提取的大量特征,学习能力欠佳;Non_Static_CNN在实验中取得了仅此于DCCNN算法的F1和正确率,说明通过具体任务微调的词向量可以取得更好的效果;S_Non_CNN多通道模型在F1和正确率上分别取得了0.941和0.942的结果。可以看出本文提出的DCCNN双通道模型是有效的,在F1和正确率上比S_Non_CNN提升了1.7个百分点。DCCNN通过引入字向量通道,可以扩大特征的覆盖范围,提取更加丰富的语义信息。
实验二 SVM在2002年首次被Pang等[18]用于情感分析中,实验二分别采用BOW+SVM算法、Word2Vec+SVM算法与DCCNN算法作对比。其中BOW+SVM算法表示:采用BOW表示文本特征,SVM作为分类器;Word2Vec+SVM算法表示:采用Word2Vec训练词向量,采用词向量的平均值作为句向量,SVM作为分类器。不同算法正确率以及F1值结果如图2所示。
由图2可以看出,在评论情感分类实验中,采用Word2Vec+SVM算法性能高于Bow+SVM算法,这是因为传统的BOW忽略了句子的语义信息,所以采用SVM分类结果相对较差,经过Word2Vec训练词向量,获取句子的语义信息,使得SVM分类性能明显提高。在实验中可以看出,DCCNN模型的正确率以及F1值都明显优于采用SVM分类器,这说明浅层机器学习算法在数据量过多的情况下,拟合能力有限,DCCNN模型在评论的情感分析中是有效的。
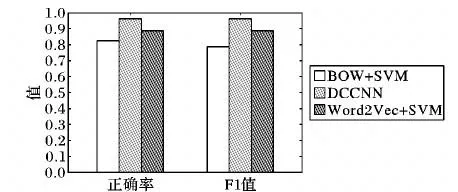
图2 不同算法分类结果Fig.2 Classification results of different algorithms
4.5 迭代次数
在实验中,为了表示不同模型下文本情感分类的效果,采用折线图统计了在不同迭代次数下各模型的正确率和F1值,结果如图3所示。
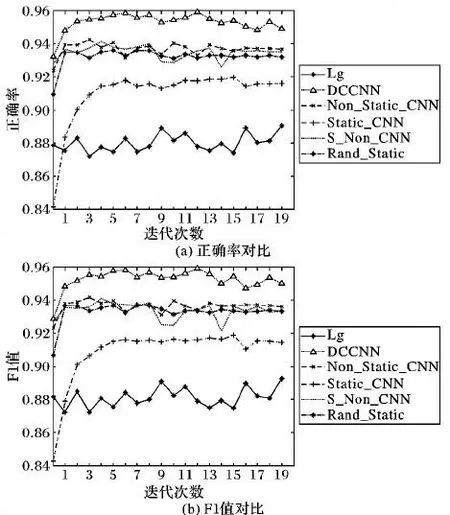
图3 不同模型在不同迭代次数下的分类结果对比Fig.3 Comparison of classification results of different models under different iterations
由图3可以看出:Lg模型正确率和F1最低,其正确率和F1值大约在0.88左右;S_Non_CNN模型的正确率波动幅度较于其他模型较大,导致出现这种情况的原因可能是静态词向量通道的词向量质量较差;DCCNN算法情感分类正确率和F1值一直高于其他算法,且波动幅度较小,在迭代次数为12时,DCCNN模型取得了最高的正确率和F1值,其值超过0.95,此时为了避免模型的过拟合,可以停止迭代。
5 结语
本文结合中文评论语料特点,针对浅层机器学习忽略句子的局部语义特征等问题,提出了一种新的文本情感分析方法DCCNN模型。该模型分别在字向量和词向量两个不同的通道上进行卷积,利用细粒度的字向量辅助词向量捕捉深层次的语义信息,以此得到更优质的特征,从而提高文本情感分类的正确率。从实验结果可看出,本文提出的双通道卷积神经网络在文本情感分类上具有更高的正确率和F1值。卷积神经网络在文本情感分析的应用中还存在许多问题,如何将模型应用于实际的工程中,将是下一步的工作重点。
