基于模糊C均值聚类及群体智能的WSN分层路由算法
2018-08-27包开阳马皛源
戚 攀,包开阳,马皛源
(1.中国科学院 上海高等研究院,上海 201210; 2.中国科学院大学,北京 100049)(*通信作者电子邮箱maxy@sari.ac.cn)
0 引言
当前,无线传感器网络(Wireless Sensor Network, WSN)在很多领域得到了大量的应用,比如环境监控、病患管理、工业自动化[1]。它的主要功能是借助大量部署具有无线通信能力的传感器节点并自组织形成网络,最终将传感器节点感知到的信息进行处理后通过无线通信方式发送至基站,从而使监测者了解监测区域的信息。然而廉价微型的传感器节点的存储、计算能力通常非常有限,特别是由于使用电池供电,节点自身能量有限,在战场火场等应用环境下又不可能及时地更换电池进行能量补充[2],因此,在能量有限的前提下,要有效地延长网络的生存时间就需要一个能量高效的无线传感网路由算法。在已有的众多能量高效路由算法当中,基于分簇的分层路由已经被证明是提高网络能量利用效率最有效的技术之一[3]。
现有的分层路由算法大部分都借鉴了低功耗自适应分簇(Low Energy Adaptive Cluster Hierarchy, LEACH)路由算法[4]的思想。LEACH的核心思想是将传感网进行分区,每个分区内所有传感器节点成为一簇,每簇选取一个节点作为簇头。每次收集信息时先由普通节点将感知到的信息发送至所属分簇的簇头,簇头将接收到的数据进行融合去除冗余后通过单跳或者多跳的方式发送至基站。这样一次完整的数据采集过程称为一轮,网络的生存时间通过运行轮数来计算,称为生命周期。
基于分层路由算法的机制,设计一个能量高效分层路由算法需要解决三个关键问题:1)分簇;2)簇头选取;3)消息发送路径。LEACH算法采用的“簇头随机,就近入簇,单跳至基站”的解决方案。由于簇头是随机选取的,完全没有考虑节点的剩余能量和簇头的个数,LEACH算法有可能选取低能量的节点作为簇头,簇头节点相对于普通节点要消耗更多的能量,这样就容易导致低能量节点过快地死亡,形成“死区”。LEACH算法在成簇的时候是通过普通节点就近入簇的方式完成的,这样就容易形成不均匀的“极大、极小簇”,其中的“极大簇”的簇头节点负载过大,容易死亡。在LEACH算法中簇头通过单跳的方式直接与基站通信,在距离较远的情况下簇头的能量消耗会急剧地增加。此外,LEACH算法每轮都需要重选簇头,新簇头被选出来后都需要进行广播告知新簇头信息,浪费了大量能量。针对LEACH算法存在的这些问题,后续出现的分层路由算法提出了很多解决方案。改进的低功耗自适应分簇(Improved Low Energy Adaptive Cluster Hierarchy, I-LEACH)路由算法[5]将检测区域均匀地分为五个分区,每个分区内的所有节点成为一簇,在一定程度解决了成簇不均匀的问题,但分区方式过于简单,没有考虑网络内节点具体的分布情况和相对于基站的位置。能量高效的非均匀分簇(Energy-Efficient Uneven Clustering, EEUC)路由算法[6]在选取簇头时考虑了节点相对于基站的位置,离基站近的节点有更大概率担任簇头;但是没有考虑簇头相对于簇内普通节点的位置,没有优化簇内通信的能量消耗。能量负载均衡的簇头选取(Leader Election with Load balancing Energy, LELE)路由算法[7]在选取簇头时考虑了节点的剩余能量,剩余能量大的节点更容易当选簇头。基于最优簇数和改进引力搜索的(Optimal Number of Clusters and Improved Gravitational Search, ONCIGS)路由算法[8]在簇头与基站的通信过程中采用簇头间多跳转发的方法,避免了簇头与基站距离过大时单跳通信造成的巨大发射能耗。经过修改的低功耗自适应分簇(MODified Low Energy Adaptive Cluster Hierarchy, MODLEACH)路由算法[9]为了避免每轮都需重选簇头的问题,使用了一种使用阈值控制簇头重选的方法,只有当簇头节点的剩余能量下降到设定的阈值以下时才会触发簇头重选。
以上的这些研究针对分簇路由算法的三个关键问题提出了一些非常值得参考的解决方法,但是也还存在一些问题。比如LELE算法和EEUC算法的分簇结果不够合理,ONGIGS算法对簇头选取的考虑还不够全面。经过分析后,为了尽可能地降低网络能耗并延长其生命周期,本文提出一种基于模糊C-均值(Fuzzy C-Means, FCM)聚类和群体智能算法(人工蜂群(Artificial Bee Colony, ABC)算法、蚁群优化(Ant Colony Optimization, ACO)算法)的WSN分层路由算法(WSN hierarchical routing algorithm based on Fuzzy C-Means clustering and Swarm Intelligence, FCM-SI)。在分簇阶段,针对网络的实时情况动态地确定最优分区数量,并通过FCM实现网络动态均衡的分簇;在簇头选取阶段,使用节点的剩余能量、节点到基站的距离、节点到所在分簇内其他节点的平均距离三个特征作为参数构造适应函数,采用人工蜂群算法计算每个分簇内最适合担任簇头的节点的位置;在簇间路由阶段,将最小能量消耗作为目标函数,采用最擅长执行路径的蚁群优化算法搜索最小消耗的簇间多跳数据转发路径。仿真结果显示,FCM-SI可以明显地降低网络能量消耗,延迟第一个节点和最后一个节点的死亡时间,有效地延长了网络的生命周期。
1 系统模型
1.1 网络模型
本文对传感网网络作出如下假设:
1)节点随机分布在监测区域内,所有节点静止不动,基站位于监测区域外;
2)节点数为N,监测区域面积为M×M;
3)所有节点的能量相等并且有限,基站能量无限;
4)节点可以感知自身位置,且可以根据相互间的距离控制发射功率;
5)所有节点具有相同属性和性能,都可以担任普通节点或者簇头,簇头节点会进行数据融合去除冗余。
1.2 能量模型
本文使用了和经典的LEACH算法相同的一阶无线电模型。设Eelec为节点每发送或接收1比特消息消耗的能量;εfree为节点放大器在自由空间模型下的传输增益,εmulti-path为放大器在多径衰落模型下的传输增益;l为消息长度,单位为比特;d为消息传输距离;dgate为传输距离阈值,当消息传输距离小于dgate时采用自由空间模型,否则使用多径衰落模型。一个节点经过距离d的发送l比特数据的传输功耗为:
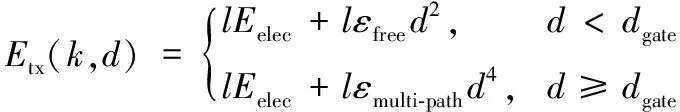
(1)
接收l比特数据功耗为:
Erx(l)=lEelec
(2)
由式(1)可知:
(3)
设定Eelec=50 nJ/b,εfree=10 pJ/(b·m2),εmulti-path=0.001 3 pJ/(b·m4)。簇头进行数据融合消耗的能量为n·m·EDA。其中n为分区的节点数;m为每个节点发送的消息长度,单位为比特,EDA=5 nJ/(b·signal)。
2 FCM-SI
2.1 动态分簇
为了降低簇内普通节点与簇头通信的能耗,本文使用了模糊C均值聚类进行分簇,成簇均匀并优化了簇内节点与簇头间的距离。由于网络状态随着运行不断变化,存活节点数会逐步减少,导致最佳簇头数也是动态变化的。为了取得最佳的网络性能,在网络运行的过程中根据网络当前状态动态地控制簇头数。
2.1.1 模糊C均值聚类
模糊C均值(FCM)聚类是一种无监督聚类算法,这个聚类方法由Dunn在1973年首次提出[10],并在1981年由Bezdek[11]改进之后已经成为了一种常用的模式识别方法。FCM的目标是使得数据点到所属分类中心的距离的和最小化,利用FCM的这一特性将其应用到无线传感网的分簇当中,就可以将网络中的节点分为几个最紧密的簇,优化簇内节点到簇头间的相互距离,有效地降低簇内通信消耗的能量。不同于常见的C-均值和K-均值聚类这种非此即彼的硬划分方法,FCM是一种模糊划分方法,这使得FCM能处理复杂的数据分布情况[12]。该聚类算法的目标函数为:
(4)
其中:xi为第i个数据点;cj为第j个聚类中心;uij为数据点xi相对于分类j的归属度;m为权重系数,一般按照经验值取为2;N为数据点数量;C为分类数量;‖xi-cj‖为数据点xi到聚类中心cj的距离,一般采用欧氏距离。聚类的过程就是通过迭代使目标函数最小化的过程。每次迭代,归属度矩阵的更新公式为:

(5)
聚类中心坐标的更新公式为:

(6)
迭代结束条件为:

(7)
其中:k为迭代步数,ε为迭代终止阈值。算法的具体步骤描述如下:
1)输入数据点集合X={x1,x2,…,xi,…,xN}T和分类数量K,并初始化归属度矩阵U(0)。
2)第k次迭代:按式(6)使用归属度矩阵计算聚类中心坐标C(k)。
3)按式(5)更新归属度矩阵U(k)、U(k+1)。
4)如果满足式(7)的条件则停止迭代算法完成;否则转到第2)步继续迭代。
2.1.2 基于FCM的动态分簇
由于FCM需要先确定分类数量,应用到网络分簇就需要在分簇之前根据网络特征确定最合理的簇头数量。根据上面介绍的网络模型和能量模型,整个网络运行一轮消耗的能量[13]为:
Eone_round≈N(E·l+εfree·l·M2/(2πk))+
(8)
其中k为簇头数。对k求偏导,并令其值为零,可求得使得功耗最低的最优簇头数为:
(9)

由式(9)可知,最优簇头数与存活节点数的开方成正比。在初始节点数为100、监测区域长宽为100 m的初始条件下可求得最优簇头数为5。然而随着网络的不断运行,开始出现死亡节点,存活节点数开始下降,最优簇头数也对应减少,需要再次分簇;例如当存活节点数减少到81时,最优簇头数变为4,直到最终整个网络只有一个簇。
另外,不同于很多分层路由算法每一轮都需要重新分簇,在本文提出的FCM-SI规定一个节点的剩余能量大于最小簇头能量ECH_min才有可能当选为簇头:
ECH_min=Eone_round+Eselect+Edivide
(10)
其中:Eone_round为簇头运行一轮所需的能量,Eselect为广播一次重新选择簇头的控制包的能量,Edivide为广播一次重新分簇的控制包的能量。在FCM-SI中,当某个簇头节点的能量达到动态阈值时,该簇头(编号i)会向其他所有簇头广播一个控制包,通知其他簇头运行三参数人工蜂群(ABC)算法重新选择簇头。Eselect就是广播这个控制包需要的能量。在新的簇头被选取出来后,如果这些新的簇头都和原来的都是同一批就说明当前网络中某个分簇内部已经没有节点适合成为簇头,那么簇头(编号i)需要向其他所有节点广播一个控制包,通知所有节点开始重新分区。Edivide就是广播这个控制包需要的能量,所以,只有剩余能量大于最小簇头能量ECH_min的节点才能当选为簇头。然而一旦FCM完成一次分簇后,那么直到下一次分簇之前每个簇包含的节点都不再变化。这样就有可能出现某个簇内的所有节点的剩余能量都不足以担任簇头的情况,这种情况下也需要再次分簇。
所以触发网络重新分簇的条件是出现以下两种情况之一:1)存活节点数下降到最优簇头数需要变化时;2)某个簇内的所有节点的剩余能量都小于担任节点的最小能量时。当触发重新分簇后,再次运行FCM生成新的分簇,这样就完成了整个网络生命周期内的动态分簇过程。
2.2 簇头选取
在网络的初始化阶段,最初由基站在每个分簇内随机选取一个候选簇头。同一分簇内的每个节点都可以相互感知对方的位置和能量信息。随后,由候选簇头采用ABC算法选取正式的簇头。候选簇头完成簇头选取后要广播一短信息,将簇头的坐标、簇头所属的分簇编号以及簇头的ID告知所有节点。普通节点收到广播信息后通过自身所属的分簇编号与簇头进行匹配入簇,簇头节点也需要相互存储其他簇头节点的位置和编号,用于簇头间消息传递路径的计算。
2.2.1 人工蜂群算法
人工蜂群(ABC)算法[14]是一种受自然界中蜜蜂采蜜行为启发的群体智能算法,蜂群中的蜜蜂分为不同的几个工种,每个工种承担不同的工作,在工作的过程中完成信息的交流和分享,从而在有限的时间复杂度内大概率找到问题的最优解。这个算法在解决全局优化问题方面展现出了非常强的能力。
ABC算法将人工蜂群中的蜜蜂分为三种:雇佣蜂、跟随蜂和侦察蜂。雇佣蜂搜索蜜源并与跟随蜂分享蜜源信息,比如蜜源的花蜜量,蜜量大的蜜源代表具有更大的适应值,代表更好的解。完成和所有雇佣蜂的蜜源信息分享后,跟随蜂会按照一定概率挑选一个蜜源并基于这个蜜源寻找新的蜜源,蜜源的蜜量越大被跟随蜂选择的概率也就越大。侦查蜂的作用是随机地寻找新的蜜源,一旦侦查蜂和跟随蜂找到了新的高质量蜜源就会转换成雇佣蜂。
在算法的初始化阶段,ABC首先生成包括三种蜜蜂的种群和它们的蜜源位置。雇佣蜂的数量和跟随蜂的数量相同,每个雇佣蜂对应一个蜜源。每个蜜源的位置称为一个解,蜜源的蜜量是这个解的适应值。每个解xi(i=1,2,…,n)是一个d维的解向量,n是蜜源的数量。每只雇佣蜂会记住当前对应蜜源的位置并生成一个新的蜜源,如果新发现的蜜源的适应值要好于旧蜜源,雇佣蜂将会存储新蜜源的位置坐标并删除旧蜜源的位置坐标;否则继续保持旧蜜源的位置坐标不变。雇佣蜂寻找新蜜源的公式如下:
xij′=xij+rij(xij-xkj);i≠k,r∈[-1,1],
j∈[1,2,…,d]
(11)
其中rij是一个随机系数,也就是用另一个蜜源对当前蜜源的第j维分量作用,从而完成在当前蜜源周围的搜索。当所有的雇佣蜂完成一次发现和位置更新后,就会与跟随蜂分享蜜源信息。跟随蜂得到蜜源信息后会按照一定概率选择一个蜜源,具体的概率计算公式如下:

(12)
其中fitnessi是解xi的适应值,可以看到一个适应值更大的蜜源将会吸引更多数量的跟随蜂。选择蜜源之后,跟随蜂同样要按照式(11)搜索新的蜜源。如果经过多次发现后,在规定的有限的步骤内某一个蜜源的适应值没有改善,那么将丢弃这个蜜源,蜜源对应的雇佣蜂身份改为侦察蜂。新出现的侦查蜂按照如下公式发现新的蜜源:

∀i∈(1,2,…,n)
(13)
其中:lb,ub分别为解的第j分量的上下界,r是一个-1到1之间的随机数。如果新产生的解的分量超过了上下界,那么直接取值为被超过的界值。
综上,ABC算法的流程如下:
1)初始化蜜源和雇佣蜂的位置坐标xi(i=1,2,…,n)。
2)雇佣蜂根据式(11)发现新蜜源,并计算适应值,执行贪婪算法更新蜜源位置。
3)跟随蜂根据雇佣蜂分享的信息按照一定概率选择蜜源,并使用雇佣蜂同样的方式发现新蜜源。
4)如果某个解达到废弃条件即达到最大发现次数(本文定义为20)后解没有改善,则根据式(13)产生新解。
5)判断是否达到终止条件即达到最大迭代次数(本文定义为20),如果达到输出最终解;否则返回步骤2)。
使用ABC算法的关键在于适应函数的定义,也就是怎样去衡量一个解的优劣,将ABC应用到簇头的选取需要结合无线传感网的具体特征去定义适应函数。下面将介绍FCM-SI定义适应函数并完成簇头选取的过程。
2.2.2 基于ABC的簇头选取
FCM-SI在选取簇头时主要考虑了节点的三个特征:节点的剩余能量、节点到基站的距离、节点与其所在簇内的普通节点之间的紧密程度。由于簇头节点需要担任更多的数据收发和融合任务,相对普通节点需要消耗更多的能量,所以一般情况下选择剩余能量多的节点作为簇头能有效地改善网络能量均衡性能。另外,簇头到基站的距离越小,簇头将数据发送至基站消耗的能量也相应越小;簇头到所在分簇其他节点的平均距离越小,担任簇头后普通节点发送数据给它时消耗的能量就会越小,所以簇头的选取问题就是一个通过改变节点位置(选取不同的节点)来改善上述三个参数指标的多参数优化问题,针对多参数优化求解,ABC算法是一种低复杂度的高效的求解方法。一个簇内包括的每个节点都是一个可能解,基于上述三个参数构造一个适应函数,计算节点担任簇头的适应值并将每个节点都建模为一个ABC算法中的蜜源模型,就可以采用ABC算法在簇内搜索最适合担任簇头的节点,从而完成簇头选取。基于以上分析,本文将簇头选取的适应函数定义如下:
fitness(i)=af1(i)+bf2(i)+cf3(i)
(14)

(15)

(16)

(17)
其中:a,b,c为权重因子,控制三个参数的重要程度;f1是候选节点的剩余能量与所属簇内所有节点的平均能量的比值,体现了剩余能量对簇头选取的影响;f2为候选节点到基站的距离与所属簇内所有节点到基站距离的平均值的比值;f3为候选节点到所属簇内其他节点距离的平均值与其他节点担任候选节点到其他节点距离平均值的比值,体现了簇头节点在区间内与普通节点的紧密程度。f2、f3体现了节点位置对簇头选取的影响。其他参数中:n为节点i所在分簇的节点总数,Eres(i)为节点i的剩余能量,dtoBS(i)为节点i到基站的距离,d(j,k)为节点j到节点k的距离。在网络的初始化阶段定义a=b=c=1/3,也就是三个参数的重要程度相同。然后随着网络的运行,节点能量不断地降低,成为更加重要的瓶颈参数,所以随着网络的运行将f1的权重动态增大。本文将a、b、c定义为:
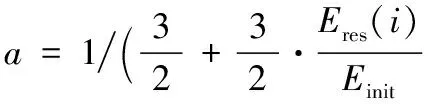
(18)
b=c=(1-a)/2
(19)
可以看到,经过以上的定义之后,随着网络的运行f1的权重从1/3动态增加到2/3,剩余能量大的节点有更大概率成为簇头,有利于优化整个网络的能量负载均衡。
2.3 簇间多跳路径搜索
为了降低簇头能耗并均衡簇间负载,采用改进的蚁群优化算法搜索簇头至基站的最优路径,簇头与基站通信时,会沿着搜索到的最优路径簇间多跳将数据转发至基站。
2.3.1 蚁群优化算法
和人工蜂群算法相同,蚁群优化(ACO)算法[15]也是一种启发式群体智能算法,该算法主要是受到蚂蚁种群的觅食行为的启发。自然界中的蚂蚁在自身没有视觉也没有其他外界信息的情况下可以通过个体间释放信息素进行消息传递,协作搜索蚁巢到食物源之间的最短路径,构成了一种典型的集体寻优行为。该算法尤其擅长解决路径搜索类问题,已经被成功地应用于求解旅行商问题这类NP(Non-deterministic Polynomial)问题,取得了非常好的实验效果。经过研究发现,蚂蚁在搜寻食物源时,会在经过的路径上释放信息素,没有视觉能力的蚂蚁通过感知周围的信息素决定行动的方向,并有更大概率向信息素浓度高的方向移动。信息素会随着时间逐步挥发,一般情况下,在单位时间内越短的路径经过的蚂蚁越多,该路径上的信息素浓度也越大,吸引更多的蚂蚁。由于这种正反馈机制,经过一段时间后所有的蚂蚁都将选择这条最短的路径[16]。
初始化时,所有路径的信息素浓度初始化为τ0,蚂蚁种群数量为m。蚂蚁被随机地投放在某个起点位置,然后开始逐个遍历位置点,直到将所有位置点遍历完毕。位于位置点i的蚂蚁下一步向位置点j移动的概率为:
(20)
其中:τij(t)表示i、j之间路径的信息素浓度,等于i、j之间的距离的倒数;α表示信息素的相对重要程度;β表示启发式因子的相对重要程度;Jk为下一步可以选择的目的地合集,起到禁忌表的作用。所有的m只蚂蚁都完成一次遍历后,找出其中最短的路径,按照路径长度更新信息素,信息素更新公式为:
τij(t+1)=(1-ρ)·τij(t)+Δτij
(21)
(22)
(23)
其中:Q为正常数,Lk表示本次遍历到的最短路径的长度,ρ为挥发因子。也就是只有属于最短路径的边上的信息素会得到加强,正是这个正反馈机制使得ACO有着比模拟退火和遗传算法更快的收敛速度。
2.3.2 基于ACO的多跳路径搜索
在无线传感网中节点的发射功率与发射距离成正相关关系,簇头间多跳转发路径长度越短,一般情况下消耗的能量也越小,所以ACO非常适合用于搜索最小能耗簇间转发路径,降低网络能耗。此外,为了使得网络的能量负载更加均衡,同时将簇头节点的剩余能量也考虑到路径搜索的过程中,使得搜索到的路径有更大概率经过剩余能量高的簇头节点,避免低能量簇头承担过多转发任务过快死亡。将簇头节点的剩余能量考虑进ACO的信息素项中后,信息素项的形式为:

(24)
其中Eres(j)为簇头j的剩余能量,那么ACO融合剩余能量参数后的转移概率计算公式为:
(25)
蚂蚁通过改进后的转移概率公式搜索簇间多跳路径,簇间通信通过搜索到的路径进行,在减少能耗的同时也兼顾了能量负载均衡。
3 实验仿真与结果分析
为了验证FCM-SI对网络性能的改善,本文采用了Windows平台下的Matlab 2012a版本对FCM-SI、基于蚁群优化的LEACH(LEACH based on ANT, ANT-LEACH)算法、基于人工蜂群优化的LEACH(LEACH based on ABC, ABC-LEACH)算法和I-LEACH算法进行仿真分析。仿真网络环境设定如下:网络覆盖面积为100 m×100 m,节点数为100,基站位置位于(50,175)。网络环境参数如表1,其他算法参数如表2。

表1 网络环境参数
3.1 成簇结果
FCM-SI与其他三个算法的成簇结果对比如图1所示。可以看到,ABC-LEACH算法使用了ABC算法选择簇头,使得簇头的位置比较合理;但是,由于ANT-LEACH是通过先随机产生簇头,普通节点再入簇的方法成簇,簇的数量和大小都不确定,不均匀的分簇容易导致网络的负载不均衡。I-LEACH算法使用了均匀分区的方法进行分簇,使得簇的大小比较均匀,数量也更加合理;但是,由于该算法在选择簇头时只考虑了节点的剩余能量,导致选出的簇头的位置不够合理。ABC-LEACH对LEACH算法的主要改进是在簇间路由阶段使用ACO搜索多跳路径,在成簇阶段的表现则没有进行优化,成簇的均匀性和簇头的位置都不够合理。本文提出的FCM-SI使用了FCM聚类算进行分簇和三参数的ABC算法选取簇头,成簇的均匀性和簇头的位置比起三个比较算法都更加合理。

表2 算法参数
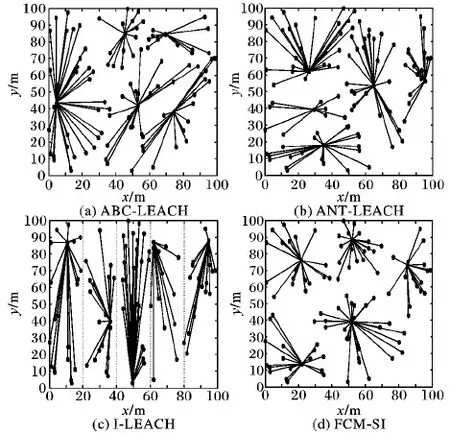
图1 成簇结果对比
3.2 动态分簇
网络的动态分簇过程如图2所示。很多算法通过计算的最优簇头数在初始化确定簇的数量并在后面的运行过程中一直沿用不再改变;但是随着网络的运行,开始出现死亡节点,存活的节点数也就是网络规模是不断变化的,与网络规模直接相关的最优簇头数也应该是动态变化的,所以,FCM-SI采取了动态分簇的策略,根据网络的实时情况,动态地调整最优的簇头数量。图2显示了随着网络运行,存活节点数开始减少,簇头的数量从最初的5个动态地调整为1个的过程。
3.3 网络生命周期
一般将从网络开始运行到最后一个节点死亡(Last Node Dies, LND)期间的运行轮数称为网络的生命周期,此定义下的FCM-SI与另外三个算法的生命周期对比结果如图3所示。由图3可知,ABC-LEACH、ANT-LEACH、I-LEACH、FCM-SI的生命周期分别为624轮、689轮、799轮、1 031轮。相比三个比较算法,FCM-SI分别延长了65.2%、49.6%和29.0%的生命周期。

图2 动态分簇过程
除了将网络生命周期定义为LND之外,根据网络的具体应用要求,也有研究将网络运行截止到出现第一个死亡节点(First Node Dies, FND)的运行轮数或者网络运行截止到一半节点死亡(Half Node Dies, HND)的运行轮数定义为网络生命周期。FCM-SI与三个对比算法在FND、HND和LND三种定义下的生命周期表现如图4所示。可以看到,在三种生命周期定义下,FCM-SI都大幅度地延长了网络的生命周期。
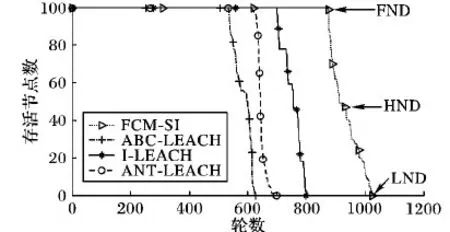
图3 生命周期对比
上面的数据表明,相比其他三个算法,FCM-SI可以有效地延长网络的生命周期。这是因为FCM-SI基于最优簇头数和FCM聚类算法实现了比较均匀的分簇,使得簇头的负载比较均衡。而且由于簇头与基站之间的通信是通过蚁群优化算法搜索到的最优路径多跳完成的,进一步节省了簇头节点的能量,在搜索路径时还考虑了簇头间的负载均衡,避免了某个簇头承担过多转发任务能量下降过快,这些能量均衡方法在很大程度上延迟了第一个节点的死亡时间。在选择簇头时考虑了簇头节点到普通节点的距离,减少了普通节点发送数据到簇头消耗的能量,从而在整体上减少了网络的能耗,使得FCM-SI在FND、HND和LND三种生命周期定义下的表现都是最优的,这说明FCM-SI相比三种对比算法具有更好的通用性。
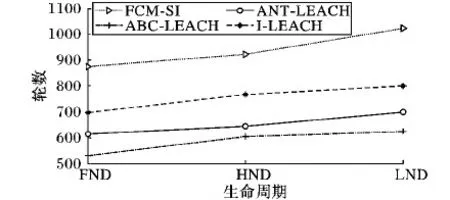
图4 三种生命周期对比
3.4 网络能量消耗
FCM-SI与另外三个算法的网络能量消耗情况对比结果如图5所示。从图5可以看出,在网络的整个运行过程中,FCM-SI的网络能量下降都是最慢的。这就说明,相对于其他三个算法,FCM-SI能明显地降低网络的能量消耗。这得益于在分簇阶段由FCM算法形成的分簇中节点到簇中心的距离是最小的,在选取簇头的时候又考虑了簇头到簇中心的距离,使得普通节点与簇头间簇内通信的能量消耗有效地降低。而簇间通信的最优路径搜索又进一步降低了网络的能量消耗。
3.5 网络数据量
无线传感网的主要功能就是感知并发送环境数据,网络的数据量是衡量网络性能的一个重要指标。FCM-SI与其他三个算法的数据发送总量比较结果如图6所示。可以看到:前期因为存活节点数都相同,四个算法的数据发送量曲线重合;后期得益于存活节点数比较多的优势,FCM-SI的信息发送总量明显多于其他三个算法。基站接收数据总量比较结果如图7所示。基站最终接收到的数据量直接影响网络对其监测区域的感知的有效程度。可以看到,从网络开始运行到最后一个节点死亡,FCM-SI的基站接收数据总量也始终多于其他三个算法。
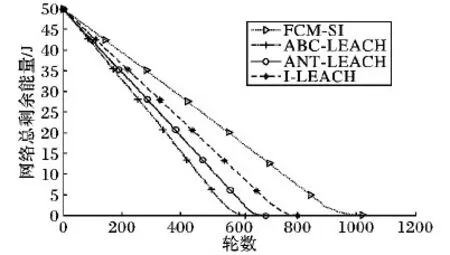
图5 网络能量消耗对比
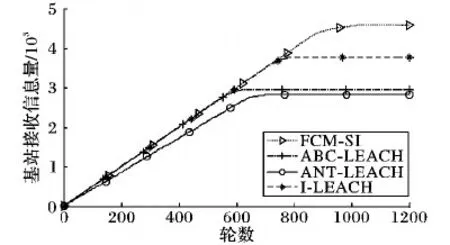
图7 基站接收数据总量对比
4 结语
针对已有的一些WSN分层路由算法在分簇、簇头选取和簇间路由搜索等方面的不完善导致网络生命周期受限、网络能量高效性不够的问题,本文提出了一种基于模糊C均值聚类和群体智能的分层路由算法(FCM-SI)。首先根据实时的网络环境计算最优簇头并利用FCM聚类算法实现实时动态的分簇;然后,采用三参数的ABC算法选取合理的簇头;最后,在簇间路由阶段采用综合考虑能量高效和能量均衡的ACO算法搜索最优簇间多跳路径。仿真结果表明,FCM-SI能有效地降低网络能耗,并改善网络能量负载均衡,明显地延长网络生命周期。虽然本文在簇头选取和簇间路径搜索的过程中都考虑到了节点的能量负载均衡,但是通过动态分簇过程还是可以看到靠近基站的节点因为承担了比较多的转发任务,能量下降速度明显比其他区域的节点要快;另外本研究是在固定规模固定节点的条件下进行,还没有考虑到网络规模和移动节点对网络性能的影响;所以,下一步的工作将集中于进一步改善网络能量负载均衡和优化算法在多种网络规模下的表现,并参考无线通信移动平台[17-18]的相关技术使算法适用于存在移动节点的无线传感网。
