基于深度神经网络的行人头部检测
2018-08-23刘正熙熊运余
陶 祝,刘正熙,熊运余,李 征
(四川大学计算机学院,四川 成都 610000)
1 引言
行人检测已经成为计算机视觉领域最主要的研究方向,也是目前深度学习必不可少的研究项目。行人检测的准确性对安防、智能视频监控系统的发展有极其重要的意义。虽然当前的检测精确率以及速率都已经取得较好的成果,但行人检测依旧面临着许多挑战,如大场景下有多人出现时,两人及两人以上互相遮挡的情况较为寻常,要将行人一一准确地检测出来,仍然比较困难。
为了解决这些难题,从根本方法出发,依据行人的身体部件建模,如人的头、头肩等模型可以区分人和其他物体。起初研究行人检测时,采用基于背景的建模方法,如经典高斯背景模型[1],其结果只能把前景和背景分离开,根据分离出的前景,人为地判断运动目标的类别,该方法易受背景变化的干扰,适合背景单一的目标检测;而基于运动目标建模的方法,首先提取目标的特征,根据特征训练模型,同时实现目标的分类与定位,提高了检测的准确率,并能检测出除了人、车以外的更多物体类别,适合复杂场景多目标检测。
基于目标建模的方法,首先提取、检测或跟踪目标的明显特征,经典的描述特征如尺度不变特征变换SIFT(Scale-Invariant Feature Tranforma)、Haar-like、方向梯度直方图HOG(Histogram of Oriented Gradient)等,均为目标检测中常用的特征。Dalal等[2]将HOG与线性支持向量机SVM(Support Vector Machine)结合,建立了较早的行人检测经典模型。Ren等[3]提出了稀疏编码直方图,从编码特征的角度实现目标检测。Vondrick等[4]将图像的HOG特征进行可视化,发现了基于HOG特征的检测方法中出现的错误正样本问题。Felzenszwalb等[5,6]提出的部分形变模型DPM(Deformable Part Models)是基于部件的目标检测方法,分别提取人的头部、四肢和躯干这几个部分的特征,并以整个身体为中心,根据四肢与躯干的距离判断目标是否为行人,该方法的检测精度达到了行人检测的巅峰。曾接贤等[7]根据DPM模型,提出了针对交通场景的行人检测。最近出现的区域选择与卷积神经网络相结合RCNN(Regions with Convolution Neural Network features)[8]检测模型,首先选取大约2 000个区域,在这些可能区域中,用卷积神经网络提取目标的特征,输入图像通过五个卷积层及对应的池化层后,得到一个多维的特征向量;接着用全连接层将这些特征结合,最后通过Softmax层分类输出;其中卷积层采用的是AlexNet[9]网络框架的卷积层,其底层实现环境为Caffe[10]框架。卷积神经网络掀起一股深度学习热潮,DPM的研究者也尝试对其进行改进,将提取HOG特征这一步转换为用深度金字塔层DeepPyramid[11]网络层实现,其精度和速率甚至超越了目前的RCNN。He等[12]提出了空间金字塔池化层网络SPP-net(Spatial Pyramid Pooling net),对RCNN进行改进。上述基于RCNN模型的检测方法,采用选择函数选取大量候选区域,操作用时较多,He等进行进一步改进,提出Fast-RCNN(Fast-Regions with Convolution Neural Network)、Faster-RCNN[13,14],利用卷积神经网络选取候选区域,将区域选择与特征提取结合为一体,极大地提高了检测速率,实现了实时检测;Liu等[15]提出的单发多重检测器SSD(Single Shot Multibox Detector),不再采用“二段式”中先选取区域、再提取特征的方法,而是直接从图像中筛选检测框,使得目标检测性能比Faster-RCNN网络更高。
以上行人检测算法和框架,针对行人整体的检测效果已难以超越,但在大场景下,人数多于两人之后出现的遮挡,以及背景较为丰富时出现的误检等问题尚未解决。针对当前目标检测所面临的难题,本文所做的主要工作有:
(1)从INRIA、PASCAL-VOC、MICROSOFT COCO等公开数据集,以及从真实监控视频中抓取行人的头和头颈部,包括正面、侧面以及背面作为训练正样本,训练出H-Neck(Head-Neck)模型,同时搜集不包含行人的负样本作为后期的测试集样本。
(2)采用Faster-RCNN网络原型实现检测。先通过五层卷积层对目标实现多层丰富特征的提取,对最后一个卷积层提取的特征图Feature Map,采用空间金字塔池化层池化,得到固定大小的特征向量,输入全连接层,从时间上改善了网络的性能。
(3)分析实验结果:训练得到的模型既可以检测行人的头部,解决部分遮挡,同时能够通过行人头部的朝向,来判断行人的大致流动方向;该信息不仅有利于景区人流量统计,同时也能够解决行人间遮挡严重时所出现的粘连问题。
(4)将本文实验所得结果与目前行人检测准确率最高的DPM模型检测结果进行比较。
2 方法
2.1 卷积神经网络提取目标特征
卷积神经网络CNN(Convolution Neural Network)是一种前馈神经网络,是当前计算机视觉包括图像识别、图形图像处理等领域最有效的提取特征并实现分类的网络结构。Faster-RCNN是一种深度神经网络,也是当前精度较高的目标检测方法。该网络将区域建议网络RPN(Region Proposal Network)和Fast-RCNN融为一体,利用RPN为Fast-RCNN的检测提供位置信息,不再使用选择函数Selective Search[8]筛选区域,且RPN与Fast-RCNN共享五个卷积层的输出结果,使得检测的速率无限接近实时。本文在Faster-RCNN的基础上,加入空间金字塔池化层,对所有卷积层输出的特征向量进行池化,采用的是多种尺度的池化窗口,每一个窗口都要对每一个目标区域进行计算,最后的结果为所有窗口的特征向量之和。
CNN中的隐藏网络层数,以及每层需要的神经元数这两个重要参数,是根据多次预测加上实验验证后得到的,针对大型的、多类别的图像数据集中的目标进行检测时,网络层的参数越多,网络性能越好。Faster-RCNN包含了两种网络结构:VGG16网络[16]和ZF网络[17]。VGG16网络的层数远多于ZF网络的,其主要区别为卷积层数的划分,图1和图2分别为VGG16网络和ZF网络的卷积层结构。由于本文检测涉及到的样本集不大,且实验结果表明,本文数据集使用小型的ZF网络和使用大型VGG16网络训练的模型并无差异,而VGG16网络的训练过程更加耗时,所以本文采用ZF网络原型训练模型,只使用五个卷积层提取目标特征。
在ZF网络的前5个卷积层中,第一层包含96个大小为7*7*m的卷积核(m为输入图像的通道数);第二层包含256个大小5*5*n的卷积核(n表示当前卷积层的输入通道数);第三层包含384个3*3*n的卷积核;第四层包含384个3*3*n的卷积核;第五层包含256个3*3*n的卷积核。后面三层的每一层之后都加入激活函数层处理输出结果;该卷积层结构与AlexNet[18]相似,但每一层的卷积核数量不同。
合适的激活函数有利于加快算法的收敛速度,最常用的也是本文网络中运用的激活函数为:ReLu(Rectified Linear unit)函数,如公式(1)所示。
φ(x)=max(0,x)
(1)
激活函数主要作用于卷积层的输出值,将线性分类器转换为可以对更复杂目标分类的非线性函数。

Figure 1 Convolutional layers of VGG16图1 VGG16网络的卷积层
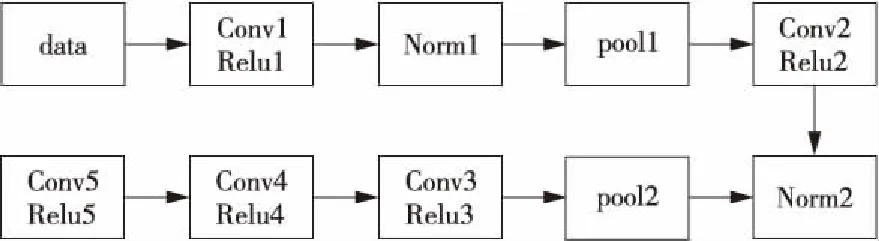
Figure 2 Convolutional layers of ZF图2 ZF网络的卷积层
2.2 实验模型介绍
2.2.1 DPM
DPM是当前针对行人检测精度最高的模型,该方法改进了对行人整体提取HOG特征的思想,将人体拆分成躯干、头部和手臂四个部分,提取每一个部分的HOG特征,以躯干为中心,称其为ROOT,其余部位称为Parts,并计算ROOT到各个Parts之间的距离分数,经实验得出分数阈值,若手臂和头到躯干的距离分数在阈值之内,则判断目标为行人。利用DPM模型实现行人检测时提取的特征可视化如图3所示。

Figure 3 Feature visualization based on the DPM model图3 DPM行人检测模型的特征可视化结果
2.2.2 行人头颈(H-Neck)模型
行人检测主要面临的两大难题分别是检测用时问题以及由于遮挡出现的误检、漏检问题。随着深度学习一系列目标检测方法的崛起,如SSD、Faster-RCNN等,检测的实时性已不再是难题。对于遮挡问题,主要出现在常见的行人检测中,大场景下多个人相互遮挡,姿态各异,无论是DPM还是当前深度学习的方法,都不能将被遮挡的行人检测出来。视频监控中出现较多的遮挡情况是行人的某些身体部位被挡住,如分别走在前后的行人,只能看见其中一个人的整个身体,而另一人下半身几乎全被遮挡;或者是多人坐在一起时,某些人大部分身体被遮住,只能看见头部;其他情况如被其他物体遮挡等,都是大场景下常见的遮挡类型。若行人头部已被遮挡完全,则只能结合检测和跟踪来识别。本文提到的模型主要解决行人的头颈部位被遮挡的情况,模型可视化如图4所示。

Figure 4 Visualization of the H-Neck model 图4 行人头颈模型的可视化结果
2.2.3 不同方向行人头部(DD-Head)模型
大场景下视频背景较为复杂,目标数量众多,行人姿态各异,目标精确跟踪始终是计算机视觉领域的一个巨大挑战。例如在旺季的景区,只能用普通“人头计数”方法统计行人数量,跟踪起来十分困难。本文通过对正面、侧面、背面的行人头部建模,得到不同方向头部DD-Head(Different Direction-Head)模型,运用该模型,行人运动的方向得到较为准确的判断,对于后续的跟踪研究而言,明确前进方向后,运用该模型也可以减少行人靠近时出现的跟踪错误。行人正面、背面、侧面的头部示例如图5所示。

Figure 5 Examples of people’s head in different directions图5 不同方向的行人头部示例
3 训练
本文的训练样本主要来源于INRIA行人数据库、PASCAL-VOC数据库以及从摄像头录取下来的真实视频中截取的图片样本。样本需符合大场景两人及两人以上同时出现的情况。分别截取行人正面、侧面、背面的头颈(H-Neck)部位作为训练正样本,同时也将整个行人作为正样本之一;从三个数据库中筛选5 000张图片,样本像素大小分布在100~1 900pix不等。根据训练需求,将样本中的目标信息转换为文档保存。为了避免过拟合现象,在五个卷积层以及池化层之后的第一和第二个全连接层后使用Dropout方法。神经元由卷积之后得到的特征集(Feature Map)组成,卷积神经网络每一层都会产生大量神经元(Neurons),特征集输入到全连接层后的计算公式为公式(2)和公式(3):

(2)

(3)

(4)

(5)

经过五个卷积层之后,本文采用SPP(Spatial Pyramid Pooling)处理卷积的最后结果,SPP结构如图6所示。根据图片大小选取多个尺度、不同大小的池化窗口,分别对卷积之后产生的Feature Map池化,每个窗口都要对图像中所有目标进行池化,因此得到的是相同维数的向量,将所有窗口的结果相加,由此得到一个固定大小和维数的向量,接着输入到fc6,即第六个网络层,也是第一个全连接层,全连接层的作用为将卷积层所提取的特征映射到样本标记空间,将不同特征与类别相对应。若按图6中的方式划分池化窗口,池化后输出的结果为(1*1+2*2+…+n*n)*256维的向量。在Faster-RCNN网络结构中,Fast-RCNN与RPN交替对目标进行训练,共分为两个阶段,每个阶段Fast-RCNN迭代30 000次,RPN迭代60 000次;整个网络结构如图7所示。训练过程运行环境为Ubuntu14.04,Matlab 2014a,GPU版本为GTX1080。
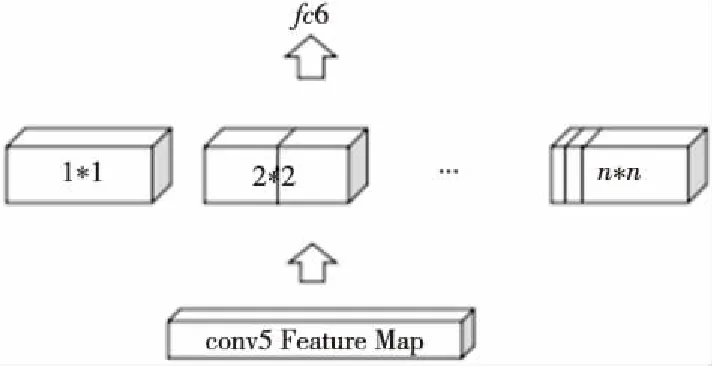
Figure 6 Spatial pyramid pooling layer图6 空间金字塔池化层结构
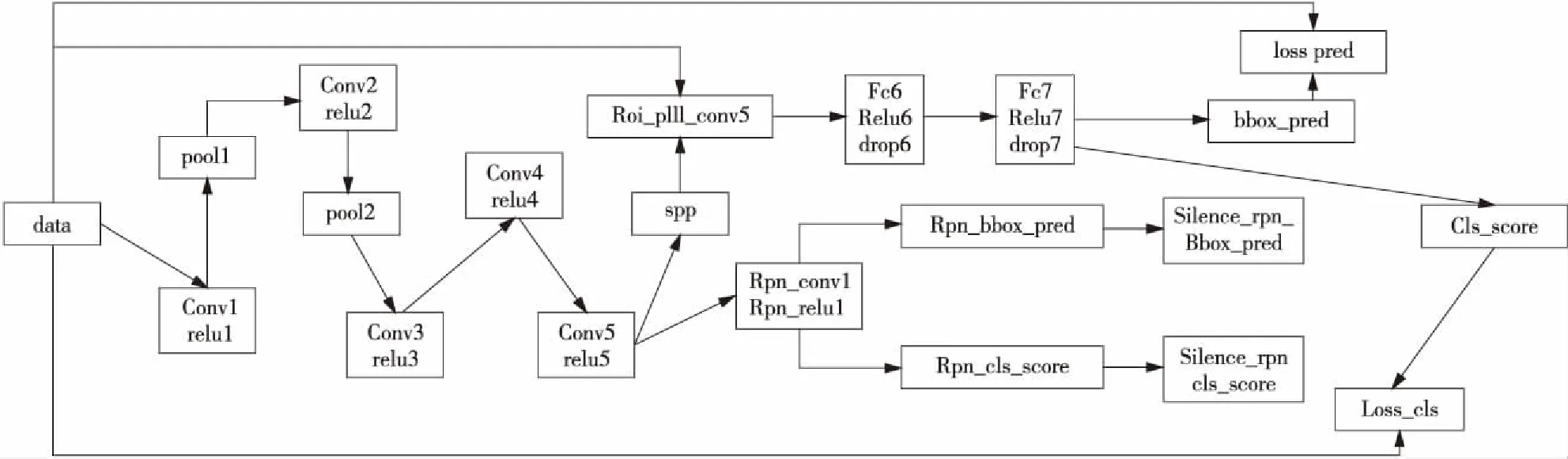
Figure 7 Net structure of ZF图7 ZF的网络结构
4 实验及结果
根据输入的测试图片,可以捕获卷积神经网络提取特征的中间过程,以下为测试阶段,输入一张测试集样本中的图片,经过多个卷积层提取特征后,并输入到全连接层,在网络最后一层输出针对该图像的检测结果。将第一个卷积层的卷积核分布进行可视化,结果如图8b所示。

Figure 8 Original image and the convolution kernel distribution of the first convolutional layer图8 原始输入图片及网络第一个卷积层的卷积核分布
其中图8b包含了96个小图像,代表96个不同的卷积核,在本文的网络中每一个核大小为7*7*3;卷积核则是提取特征向量的基础单元。
4.1 行人检测实验结果对比
对比表1的测试结果,并结合实验过程可知:DPM对于大场景人数较少时的行人检测准确度达到80%以上,本文H-Neck模型的检测准确率达到85%以上,样本中行人姿态复杂,不仅有直立行走,也有骑马、坐姿、骑车等情况。DPM更适合于检测直立行走的人,且对于行人大部分身体轮廓明显时的检测效果更好。若出现行人间的遮挡或是物体遮挡行人的情况,本文提出的头颈模型(H-Neck)能更加准确地检测到人的头部,由此检测到行人。实验结果同时表明:在无人的情况下即样本中可能包含其他物体,如动物、植物等,DPM和H-Neck模型都只产生很少的误检,判断是否存在人的准确率能达到95%以上。
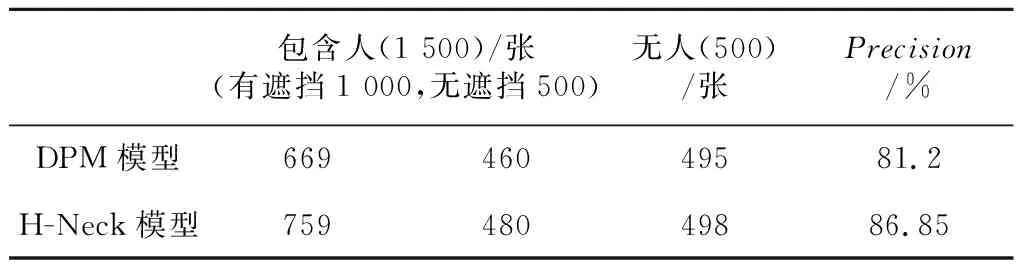
Table 1 Precision comparisonbetween DPM and H-Neck models
由图9所示的实验对比结果可知,两者对于场景中是否有人的判断准确率都达到95%以上。

Figure 9 P-R figure of DPM and H-Neck models图9 DPM模型与H-Neck模型的P-R图
为了验证H-Neck模型的稳定性,将其与更多行人检测算法作比较,对1 500张图片组成的测试样本集分别再用HOG+SVM、DPM进行检测,其检测结果和本文H-Neck模型的检测结果准确率如表2所示。

Table 2 Detection result comparison among different models
表2中,除了本文的H-Neck模型,其他几个算法的模型都是针对行人整体的检测,在训练和测试时均使用完全相同的样本集。由实验结果可以看出,HOG结合SVM的方法检测效果不佳,检测准确率远小于其他方法。其原因一方面是由于HOG特征自身的特点,易产生错误的正样本;另一方面则因为该方法对训练数据的需求量大,使用本文训练集数据不足以得到稳定的检测模型。
4.2 DD-head模型的检测结果
对大致包含500个行人的样本,用本文DD-Head模型实现行人朝向的检测,并根据检测结果判断人群流动方向,检测结果准确率如表3所示。

Table 3 Detection precision of different head directions
由表3知,在人群密集情况下,DD-Head模型对行人正面朝向的检测准确率较高,而侧面检测准确率较低,原因是行人侧面和正面的差异很小,提取特征时容易混淆正面和侧面,而相对于这两者而言,背面的特征更加独特,只有当图像比较模糊时,才会出现漏检的情况。
本文没有使用Faster-RCNN网络原有的池化层,只在五个卷积层之后使用一个空间金字塔池化层对特征向量进行处理。将样本投入新的网络结构中训练,在保证训练准确率的同时,也能保证网络的训练速率。图10为DPM与本文H-Neck模型的部分实例检测结果对比。

Figure 10 Partial detection results of DPM and H-Neck models图10 DPM与H-Neck模型的部分检测结果
5 结束语
为了解决人群密集时出现的行人身体部分遮挡造成的误检问题,本文提出了头颈(H-Neck)模型,与原来的DPM模型检测结果对比,可以在人与人相互遮挡至只剩下头部时,能准确地检测到行人头部;同时,本文针对行人头部的各个方向建模(DD-Head),能够较为准确地判断行人行进方向,更好地实现景区人流量统计;本文同时基于深度卷积神经网络Faster-RCNN框架,结合SPP-net方法的思想,用空间金字塔池化层替换原有池化层,改善了网络的训练速率。虽然针对本文数据集进行目标检测的准确率较高,但当行人中遮挡情况更为密集复杂,以及行人戴上帽子等情况下,本文的方法仍无法准确检测到目标,这都有待于后期对神经网络进一步地研究和优化。
