基于拟态计算机的SHA512算法高吞吐量实现
2018-08-23席胜鑫张文宁周清雷斯雪明
席胜鑫,张文宁,周清雷,斯雪明,李 斌
(1.郑州大学信息工程学院,河南 郑州 450001;2.中原工学院软件学院,河南 郑州 450007;3.解放军信息工程大学信息工程学院,河南 郑州 450002)
1 引言
近年来,科学技术高速发展,与之伴随的互联网已经深深地融入人们的生活和工作中,成为不可或缺的组成部分。网络的迅速普及和信息行业的发展标志着人类已经正式跨入了信息化和大数据的时代。信息爆炸而产生的海量数据时刻充斥在日常生活当中,而其中更是不乏各种各样包含个人隐私和敏感信息的重要文件。在这些信息的挖掘和使用过程中,为了防止其受到窃取和篡改,人们通常采取加密的措施来保障其安全。哈希函数作为一类在信息安全领域广泛使用的加密算法[1,2],在网络安全方面和密码学领域具有十分重要的意义和广泛的应用。王小云教授在2005年宣布了破译SHA1的研究成果,因此美国国家标准技术研究所表示,将逐步使用先进的SHA224、SHA256、SHA384及SHA512的密码系统代替SHA1密码系统。由此可见,SHA512等算法将会广泛使用[3,4]。
2013年9月21日,世界第一台拟态计算机基于认知的主动重构计算体系PRCA(Proactive Reconfigurable Computing Architecture)原理验证样机在中国研制成功。拟态计算指的是在执行运算的过程中通过自身感知、动态选择或者生成最优效能解算结构集合。拟态计算的目标是实现高性能、高效能的计算,其实现本质是将高阶函数融入计算结构当中,通过感知程序内部的自变量动态可变地选用最优部件解决计算问题[5]。在拟态计算机处理任务的过程中,其本身可以对自变量进行感知,从而通过拟态变换的方式生成执行所需的最优效能解算结构集合。拟态计算机以配置流控制的硬件作为执行主体,其计算、存储、互联等物理执行结构属于变体部分,在执行过程中要求动态可变,最终达到“依靠动态可变的物理结构,通过软硬件结合实现高效能、高性能的计算”。
拟态计算机和通用计算机最大的不同之处就在于动态可变。在执行一个计算任务的过程当中,通用计算机会始终维持其物理结构静态不变,以软件编程的控制作为主要执行体;而拟态计算机的所有软件和硬件变体部件都是动态可变的,在实现应用处理的过程中,可以根据程序自变量动态选择最优的方案来实现各种功能等价、计算效能不同的最优解的集合[6]。因此,拟态计算机高效能、高性能的特点使它非常适合于计算密集型的大数据量处理任务。在口令恢复的运算过程中往往伴随大量的迭代运算,如WORD2013中的SHA512运算、ZIP中的SHA1运算,哈希算法的高次迭代运算量占到口令恢复算法整个流程运算量的90%以上。拟态计算机在实现口令恢复的过程中,通过识别口令恢复的需求和变化,同时感知系统中可以利用的处理资源,依据尽可能高性能和高效能的原则,认知并决策出的现场可编程门阵列FPGA(Field-Programmable Gate Arrary)对于实现SHA512等哈希函数的运算具有速度快、吞吐量高的特点。
FPGA是拟态计算机中的重要部件,它具有体系结构和逻辑单元灵活、设计开发周期短、集成度高以及适用范围宽等特点[7]。兼容了可编程逻辑器件PLD(Programmable Logic Device)和通用门阵列的优点,可实现较大规模的电路,编程也很灵活[8,9]。由于SHA512算法本身的复杂性,使用软件加密则会存在加密速度慢、占用CPU资源等诸多缺点,因此使用硬件实现算法就成为未来应用的必然选择。
SHA512在FPGA中已经有实现,也产生了很多不同的实现方案。Algredo-Badillo等人[2]采用了不同级数的流水线对SHA512算法进行优化,并对不同的方案进行了分析。Rote等人[3]采用了环形流水线的方式,对SHA2算法进行了实现,提高了算法的吞吐率。文献[10]通过对关键运算部分进行分解,采用中间变量进行预计算,实现了SHA512迭代部分的并行计算处理,提高了运算速度。文献[11]通过循环打开和路径优化两大硬件优化技术,在保持较小面积和相似主频的情况下,提高了加密速率。文献[12]在关键计算路径上进行了加法器结构的优化,并且实现了分组数据输入与循环运算的并行进行,减少了加密一个分组所需的时钟周期数,提高了加密效率。文献[13]采用数据流可重构的设计思想和方法设计了一种新的硬件结构实现多种哈希函数,注重降低资源的消耗。鉴于目前芯片技术突飞猛进的发展,使用更多的逻辑资源来换取运算时间的降低,以提升运算性能已经十分普遍。本文将介绍使用全流水线结构在拟态计算机中实现SHA512算法,同时也对加法运算进行优化,达到增加工作频率和并行化的目的,从而提高SHA512的计算速度和效能。
2 SHA512算法简介
SHA512算法可以将任意长的输入消息串(长度不超过2128bit),通过一系列操作转化为固定长的输出串,且转化过程不可逆,如图1所示。
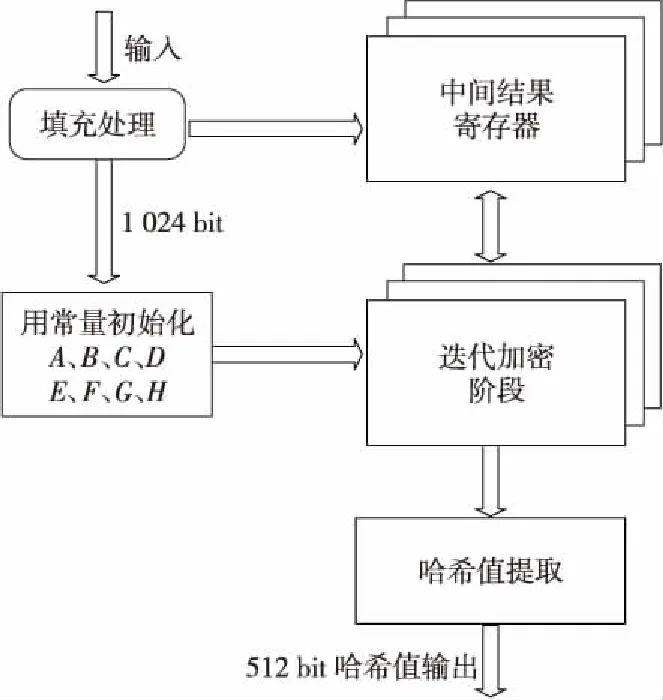
Figure 1 Whole process of SHA512 algorithm图1 SHA512算法整体流程
算法的具体流程如下:
(1)填充。
SHA512算法的运算过程是以1 024 bit(16×64 bit)为单位进行的,因此需要对输入消息串进行数据填充处理。第一步填充的字符串高位为1,其余位为 0,使其满足:填充后的字符串长度模1 024后余896 bit;第二步填充(即长度填充),长128 bit的长度值(以bit为单位)附加在经过数据填充后的消息后,使得消息的最终长度为1 024位的整数倍。
(2)迭代加密阶段。
SHA512是对长度为1 024 bit的数据块进行处理,因此需要将输入的数据每1 024 bit分成一块。分块之后就可以对每块数据按下述方法依次进行处理(这里以一个1 024 bit的数据块进行说明):

Figure 2 Calculation of Wt value and register shift图2 Wt值计算和寄存器移位
步骤1将1 024 bit的消息块分成16个64 bit的字M0,M1,…,M15。
步骤2按如下公式计算Wt:
Wt=Mt(0≤t≤15);
Wt=σ1(Wt-2)+Wt-7+σ0(Wt-15)+Wt-16(16≤t≤79)。
步骤3令A=H0,B=H1,C=H2,D=H3,E=H4,F=H5,G=H6,H=H7(H0~H7为固定常数)。
步骤4Fort=0 to 79(Kt为固定哈希值)

T2=Σ0(A)+Maj(A,B,C);
H=G;
G=F;
F=E;
E=D+T1;
D=C;
C=B;
B=A;
A=T1+T2。
步骤5令H0=A+H0,H1=B+H1,H2=C+H2,H3=D+H3,H4=E+H4,H5=F+H5,H6=G+H6,H7=H+H7。
所有消息块处理完后得到的8个64 bit变量H0~H7构成512 bit的数据,就是SHA512算法输出的散列值。
上述计算过程中使用的一些逻辑函数和常数说明如下:
Ch(x,y,z)=(x∩y)⊕(x∩z);
Maj(x,y,z)=(x∩y)⊕(x∩z)⊕(y∩z);
σ0=ROTH1⊕ROTH8⊕SHR7;
σ1=ROTH19⊕ROTH61⊕SHR6;
Σ0(x)=ROTH28⊕ROTH34⊕ROTH39;
Σ1(x)=ROTH14⊕ROTH18⊕ROTH41;
ROTRn(x)=(x≫n)∪(x≪w-n);
SHRn(x)=x≫n。
3 算法优化
SHA512算法迭代加密阶段,步骤2中计算Wt,从计算公式可看出,W0~W15无需计算,可直接输出,从W16开始,需要经过计算方可输出。分析计算公式可以发现,输入计算模块中的Wt-2、Wt-7、Wt-15、Wt-16随着每步的执行向后移动一个字。因此,可以使用 16个64位寄存器,从第17步开始,每一步寄存器里的数据都向右移动一个字的长度。如图2所示,这样每一步以后,上述4个字Wt-2、Wt-7、Wt-15、Wt-16也将发生相应的变化,然后再将该步计算所得Wt输出补充到最后一个寄存器中。
3.1 加法运算优化
从上述算法描述可以看出,SHA512最关键的计算是步骤4的哈希迭代运算,SHA512每1 024位数据块需要80个时钟周期才能完成处理。并且在每轮的哈希计算中,SHA512涉及一个6个数相加和一个7个数相加的加法运算。如图3所示,在每轮的哈希计算中,B、C、D、F、G、H的值无需计算,分别由上一轮的A、B、C、E、F、G直接赋值得到,几乎没有电路上的延时。而A涉及7个数相加,还有一些异或运算,这就大大增大了关键路径上的延时,使整个算法的运行频率降低。因此,要提高哈希函数的运算速度可以从提高算法的工作频率着手。而提高算法的工作频率,可以通过减少算法实现的关键路径的长度,减少关键路径的延时来实现。加法在FPGA 的实现中要比位操作的延时大得多,因此本文基于进位选择加法器CSA(Carry Select Adder)的原理对加法进行优化。CSA方式是根据如下特性做出的:如果Result=A+B+C,则有S=AxorBxorC;Ca=((AandB) or (BandC) or (AandC))≪1;最后结果为Result=Ca+S。
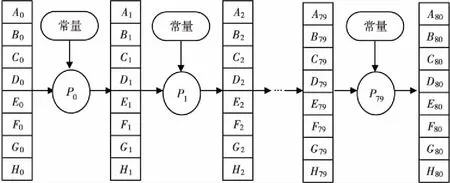
Figure 4 80-stage fully pipelined architecture图4 80级全流水架构示意图

Figure 3 Schematic diagram of single step iterative processing of SHA512 algorithm图3 SHA512算法单步迭代处理示意图
从A、E的赋值运算可以看出,A的赋值运算共由7个加法计算构成,E的赋值运算共由6个加法计算构成。为了对加法进行优化,本文根据CSA原理,定义了如下方法:
CSA(a,b,c)=(axorbxorc)+(((aandb) or (bandc) or (aandc))≪1);
CSA4(a,b,c,d)=CSA((axorbxorc),(((aandb)or(bandc) or (aandc))≪1),d);
CSA5(a,b,c,d,e)=CSA4((axorbxorc),(((aandb)or(bandc) or (aandc))≪1),d,e);
CSA6(a,b,c,d,e,f)=CSA4((axorbxorc),(((aandb) or (bandc) or (aandc))≪1),(dxorexorf),(((dande) or (eandf) or (dandf))≪1));
CSA7(a,b,c,d,e,f,g)=CSA5((axorbxorc),(((aandb) or (bandc) or (aandc))≪1),(dxorexorf),(((dande) or (eandf) or (dandf))≪1),g)。
因此,A的赋值运算使用CSA7,E的赋值运算使用CSA6。从上述的方法描述可以看出,A的赋值运算由原来的7个加法计算变为2个加法计算,E的赋值运算由原来的6个加法计算变为2个加法计算,减少了关键路径上加法计算的数量,也就大大减少了关键路径上的延时。
3.2 全流水线结构

Figure 5 80-stage pipeline in SHA512 algorithm 图5 SHA512算法80级流水线
如果某个设计的处理流程可分为若干步骤,而且整个数据处理是“单流向”的,即没有反馈或者迭代运算,前一个步骤的输出是下一个步骤的输入,可利用流水线技术来提高处理的并行度。在SHA512最核心的80轮迭代运算中,如图4所示,单步运算有着结构上的相似性,每一轮数据都是上一轮运算的结果,并且没有反馈。因此,本文采用全流水线技术增加并行程度。为了将吞吐量提升至最高,通过打开循环并且加入中间寄存器,把80轮循环迭代运算的每一轮作为流水线的一级,构建了一个80级的全流水线。在80级的全流水线中,每一级对应传统的80轮迭代运算中的一轮运算。为了提高对公共寄存器的使用率,本文构建了一个80级的全流水线。如图5所示,在第一个时钟周期,第一组64 bit数据进入第一级流水线进行处理;在第二个时钟周期,第一组数据处理完后传递到第二级,与此同时第二组64 bit数据进入第一级;每一个时钟周期都按照这样的流水线处理方式处理。从每一组数据的处理来看,每一组数据都需要80个时钟周期进行处理,但在整个80轮流水线处理过程中,每一个时钟周期都能计算出一组数据。因此,平均计算一组数据只需要一个时钟周期,大大提高了数据处理速度,保证了整个系统以较高的频率工作。
综上所述,全流水线结构的SHA512算法可以通过如下方法来计算:
步骤1明文经过预处理之后,按照1 024 bit为单位进行分组。
步骤2将需要处理的1 024 bit数据块分成相应的16个64 bit字W0,W1,…,W15。
步骤3令A0=H0,B0=H1,C0=H2,D0=H3,E0=H4,F0=H5,G0=H6,H0=H7(当处理第一分块时,H0~H7为固定常数,否则为上一分块输出结果)。
步骤4在一个时钟周期内对n从0~79同时做下列运算:
Wt=σ1(Wt-2)+Wt-7+σ0(Wt-15)+Wt-16,t≥16;
Bn+1=An;
Cn+1=Bn;
Dn+1=Cn;
Fn+1=En;
Gn+1=Fn;
Hn+1=Gn。
步骤5令H0=A80+H0,H1=B80+H1,H2=C80+H2,H3=D80+H3,H4=E80+H4,H5=F80+H5,H6=G80+H6,H7=H80+H7。
步骤6所有的1 024 bit数据分块处理完之后,最后的H0~H7就是散列值输出。
4 算法实验
本文在ISE Design Suite软件上使用Verilog硬件描述语言实现了设计的SHA512算法,仿真结果正确,编译综合通过,并且下载到Xilinx公司的Virtex6系列XC6VLX550T器件中进行测试,芯片运行正常,测试结果正确。如表1所示,本文所实现的芯片的最大工作频率为130 MHz,吞吐量达133 120 Mbits/s,是文献[2]的130倍,是文献[3]的56倍,是文献[12]的102倍,是文献[13]的92倍,加密速率得到了很大的提升,优于以往的实现结果。

Table 1 Performance comparison with others in the literature
本文还在Xilinx公司的Virtex6系列XC6VLX550T开发板上实现了另外几种SHA512算法。如表2所示,NoP_NoCSA代表1级流水线并且没有加法运算优化;NoP_CSA代表1级流水线并且经过加法运算优化;P_NoCSA代表80级流水线并且没有加法运算优化;P_CSA代表80级流水线并且经过加法运算优化(即本文算法)。另外,本文计算吞吐量的公式如下所示:
(1024×130×80)/80=133120 Mbi/s
其中吞吐量为T,数据块大小为B,时钟频率为f,流水线级数为N,计算延时为d,则可以得出本文全流水结构的SHA512算法实际实现所达到的吞吐量为:
由NoP_NoCSA和P_NoCSA对比可以看出,虽然P_NoCSA的频率比NoPNoCSA的低,并且P_NoCSA占用的LUT(Look-Up-Table)和寄存器都是No_NoCSA的20倍,但是P_NoCSA的吞吐量却是No_NoCSA的60倍。因此,本文采用的全流水线结构增加了同时处理数据的能力,极大地提高了数据吞吐率。由NoP_NoCSA与NoP_CSA对比可以看出,两者的LUT和寄存器占用的数量很接近,但是NoP_CSA的频率却比NoP_NoCSA高50 MHz。因此,本文采用的加法运算优化,对于提高工作频率,降低一个周期内的运算延时,是非常有效的。
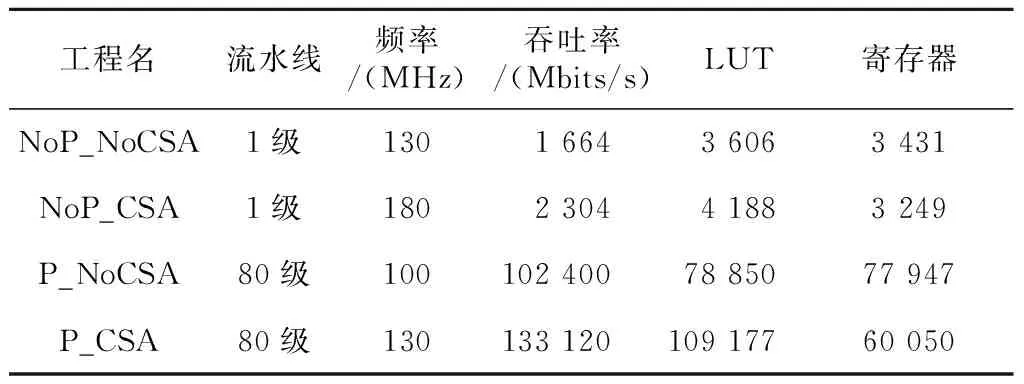
Table 2 Comparison of different implementations
综上所述,P_CSA 与NoP_NoCSA对比,P_CSA占用的LUT和寄存器数量分别是NoP_NoCSA的30倍和20倍,但数据吞吐率是NoP_NoCSA的80倍。本文采用全流水线结构和加法运算优化,虽然占用了一定数量的资源,但是数据吞吐率得到了极大的提高,因此本文对于SHA512算法的优化方案是值得采纳的。
基于拟态计算机高效能的特点,本文随机选取一个加密SHA512文件,与IBM M3(在M3上安装了HashCat)进行比较,分别测试性能,并通过功耗仪来测量任务破解过程中的功耗。本文引入能效比来评测不同平台的效能高低。假定平台的能效比为E;M代表性能,即口令回复中的破解速度;P代表各平台运行时的功耗,则平台的能效比为:
拟态计算机与IBM M3 平台能效比如表3所示。

Table 3 Comparison of energy efficiency ratios
从表3的数据可以看出,破解同一个SHA512加密文件时,虽然拟态计算机的功耗是M3服务器的三倍多,但是拟态计算机的能效比是M3服务器的一百多倍。
5 结束语
本文给出了SHA512算法基于拟态计算机的全流水线实现方案,通过使用全流水线结构和对加法运算的优化,提高了工作频率,吞吐率也得到了极大的提高,在130 MHz时钟频率下数据吞吐率达133 120 Mbits/s。
另外,通过理论分析和实验验证,虽然本文的实验方案占用了一定数量的资源,LUT和寄存器的使用量分别是1级流水线的30倍和20倍,数据吞吐率却是1级流水线的80倍。最后,为了验证拟态计算机高效能的特点,本文通过实验与IBM M3进行了能效比测试。实验表明,拟态计算机的能效比远高于通用服务器的。
