基于头颈部轮廓拟合直线斜率特征的奶牛跛行检测方法
2018-08-21宋怀波何东健
宋怀波,姜 波,吴 倩,李 通,何东健
(1. 西北农林科技大学 机械与电子工程学院,杨凌712100 2. 农业农村部农业物联网重点实验室,杨凌 712100 3. 陕西省农业信息感知与智能服务重点实验室,杨凌 712100)
0 引 言
跛行是导致奶牛高淘汰率与低产奶率的重要原因,预防跛行的发生对于奶牛业的健康发展尤为重要。奶牛跛行疾病会导致牛奶产量和生殖的损失[1]。随着奶牛养殖规模的不断扩大,人工检测奶牛跛行的难度也越来越大。因此,为了减少治疗成本,开展奶牛跛行的早期检测是目前最佳的解决方式,对于提升奶牛养殖业的现代化水平具有重要的研究意义。
在奶牛跛行检测研究方面,众多学者进行了研究并取得了一批研究成果。针对奶牛跛行对其身体负重程度不一样的现状,Pastell等[2]提出了一种利用测量奶牛质量分布来检测奶牛跛行的方法,当2个阈值LWR (ratio of weight to legs, LWR)和NRS(numerical rating scores, NRS)分别大于3与3.5时可用于检测奶牛跛行,该方法避免了环境因素对奶牛跛行检测的影响,但该方法粗略地评估了奶牛质量与奶牛跛行之间的关系,在奶牛质量与奶牛跛行对应关系之间会存在较大的误差。
为减少上述误差对奶牛跛行检测的影响,Chapinal等[3]提出了奶牛腿部质量检测与步态评估的方法来检测奶牛是否跛行。上述方法均是以测量单个奶牛质量或者测量奶牛蹄肢质量为前提的奶牛跛行检测方法,一般情况下,在测量过程中可能会引起被测奶牛的应激反应,导致数据误差增大。由于现代奶牛业的规模化养殖多为室外开放环境,奶牛数量较多,上述检测方法可能会引起检测成本的增加。在养殖场中,监控摄像头每天可捕获大量的奶牛视频数据,Magee等[4]提出了重采样冷凝与多流循环隐马尔可夫模型相结合的奶牛跛行检测方法,通过对奶牛目标跟踪与时间建模,取得了较好的跟踪结果,但该方法在环境鲁棒性方面较弱,长时间检测效果差。Zhao等[5]采用局部背景拼接的方法在复杂环境下建立了背景模型,分离、提取效果较好,但该方法对环境、视频画质敏感,不利于推广应用。Poursaberi等[6]提出了利用测量奶牛后背曲率来检测奶牛跛行的方法,检测跛行的平均正确率达到了96.55%。
重度跛行奶牛因其症状比较明显,通过饲养员进行观察即可发现。早期轻、中度跛行的检测更为重要。但不难发现,在奶牛养殖场规模较大的情况下,对于突发的重度跛行奶牛,受到奶牛数量的影响,可能难以及时发现,导致预防与治疗不及时,会引起养殖场不必要的经济损失。更重要的,为了解决奶牛早期轻、中度跛行的及时检测,本研究中将样本分为正常、轻度跛行与中重度跛行 3类,以期为现代大规模奶牛养殖提供跛行奶牛的在线实时检测问题,尤其是为轻度跛行检测提供一种可靠方案。
笔者课题组研究发现,当奶牛跛行时,奶牛头部、颈部及背部连接处也有明显的特征变化,故将其特征用于奶牛跛行检测,并进行验证。视频分析技术成本低,省时省力,并有快速响应的优势,同时避免了与奶牛直接接触所带来的一些问题。近来,视频对象跟踪[7-14]和数据分类[15-19]引起了越来越多研究学者的兴趣。因此,利用视频分析技术对目标区域或感兴趣区域进行跟踪并对其有效特征数据连续获取,这对检测奶牛跛行具有重要的意义。但目前来看还存在 3个问题:1) 奶牛连贯性运动参量获取方式可靠性不足;2) 现有奶牛视频处理方法尚未涉及奶牛连贯性运动参量与奶牛跛行之间的关系;3) 因轻度跛行奶牛特征不明显,尚难以实现奶牛轻度跛行的检测。本研究拟提出一种基于NBSM-LCCCT-DSKNN(normal background statistical modellocal circulation center compensation track-distilling data of KNN)的奶牛跛行检测算法,通过对视频中奶牛进行跟踪并提取目标奶牛的头部、颈部以及与颈连接的背部轮廓线拟合直线斜率数据,提取出大量的斜率数据经过数据清洗之后,将其放入KNN分类器中实现奶牛轻度跛行与中重度的跛行的检测,以期为诊断与预测奶牛跛行提供一种新方法。
1 材料与方法
1.1 试验视频材料
试验视频于2013年 7月至8月采集自陕西杨凌科元克隆股份有限公司的奶牛养殖场,试验对象为处于泌乳中期的美国荷斯坦奶牛。本研究共获取30头奶牛的视频片段。每头奶牛得到12段视频,共计360段视频,每段视频持续时长约为10 ~40 s,从中随机挑取6段中重度跛行奶牛行走视频,6段轻度跛行奶牛行走视频,6段正常奶牛行走视频(采集信息见表 1),本文将奶牛跛行检测任务视为分类任务,在分类任务中,类别不平衡会导致分类结果向样本多的一类倾斜[20-24],为避免类别不平衡问题,本文采用样本类别比例为 1∶1∶1。采集视频为PAL(phase alteration line)制式并保存在摄像机本地存储卡内,帧率/码率为25 fps/2000 kbps,分辨率为704 ×576像素。
视频处理平台处理器为 Inter Core i5-7200M,主频为3.40 GHz,8 GB 内存,500 GB 硬盘,算法开发平台为MATLAB 2016b。
奶牛视频信息,包含飞鸟、工人、夜间飞虫、不同天气等干扰因素,进一步加剧了奶牛跛行检测的难度。
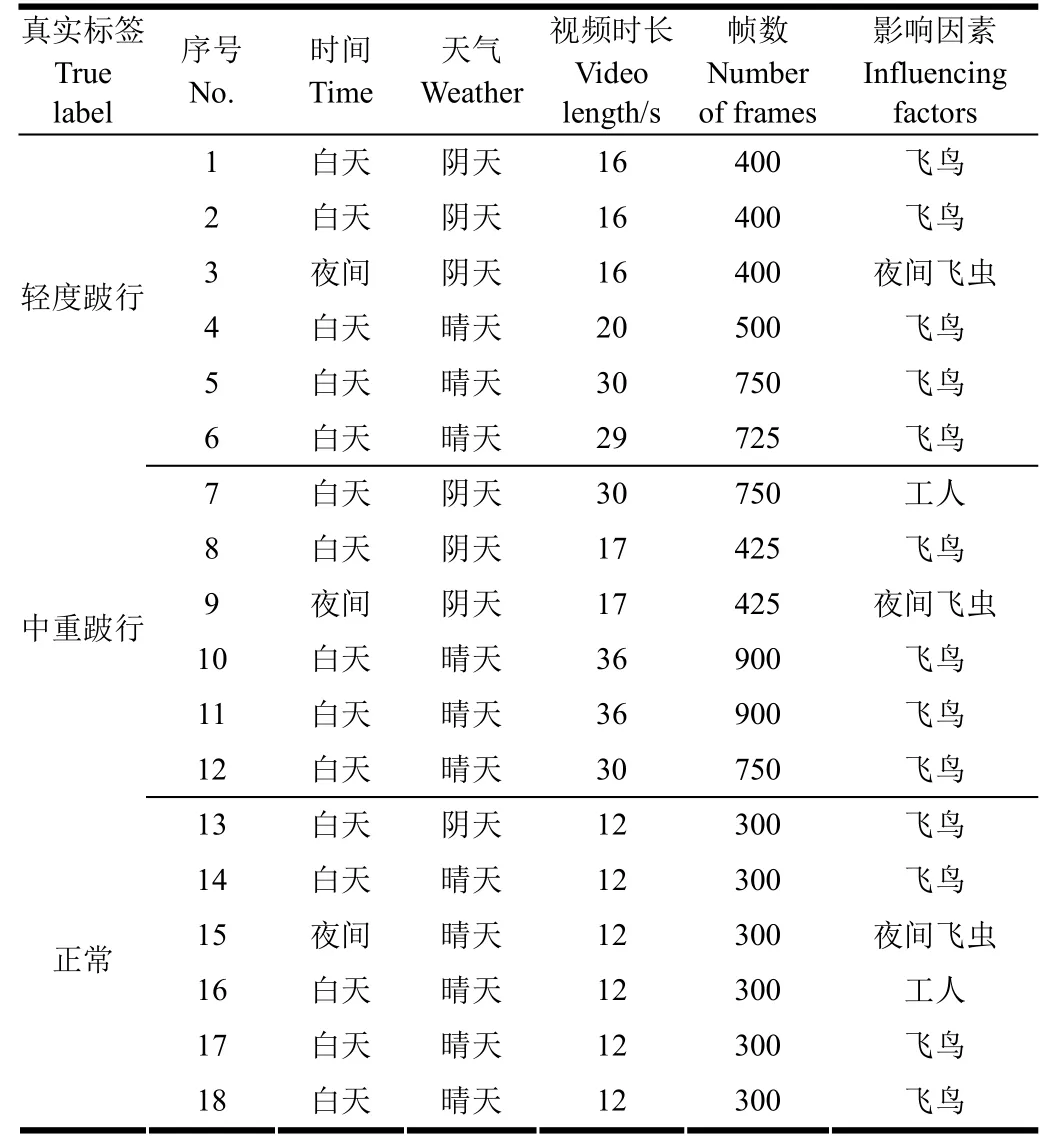
表1 奶牛视频集包含的信息Table 1 Video information of cow video set
1.2 奶牛跛行检测方法
本研究拟采用的技术路线如图 1所示。算法主要包括3部分,第一部分为NBSM模型,主要用于将目标奶牛与背景分离,获取目标奶牛像素区域;第二部分为LCCCT模型,主要用于获取奶牛感兴趣区域(region of interest, ROI),并进行局部像素点中心进行补偿,获得补偿后的感兴趣区域(compensation- region of interest,C-ROI)计算其质心并进行跟踪;第三部分用于获得跟踪区域奶牛身体上轮廓的拟合直线斜率数据,进而训练DSKNN分类器。
1.2.1 NBSM模型
在分析奶牛视频中每帧图像的像素分布特性时,发现在奶牛目标像素与背景像素大致满足双峰分布,如图2所示是视频中某一帧图像及其对应的灰度直方图,在图像的灰度值拟合曲线中有明显区域峰值,故本研究采用正态分布的目标奶牛与背景检测方法来描述像素分布的过程。
奶牛视频中每帧图像的像素分布特性中奶牛目标与背景像素分布规律如图3所示。帧图像像素点按照式(1)映射在极坐标中获得到图 3a。本文将图像帧中的内容视为奶牛目标与背景,且背景像素一定比目标像素数目多,故在极坐标中帧图像像素会呈现增-减-增-减的状态。拟合曲线极径总体变化状态呈现增-减-增-减,表明帧图像像素分为目标奶牛像素与背景像素2部分。
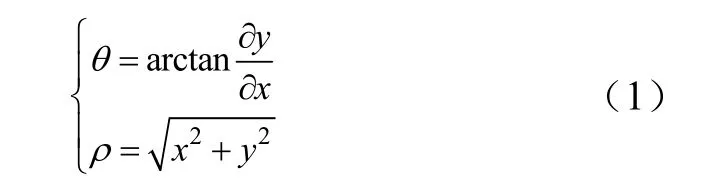
式中x为灰度值,y为灰度值所对应的像素数,θ为极角,ρ为极径。

图1 基于NBSM-LCCCT-DSKNN的奶牛跛行检测方法流程图Fig.1 Flowchart of lameness detection for dairy cows based on NBSM-LCCCT-DSKNN model
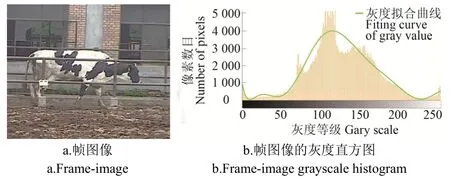
图2 帧图像及其灰度直方图Fig.2 Frame-image and its grayscale histogram
图3b是像素在羽状图的分布规律,折线表示灰度值所对应的像素点数量,由于只将图像内容视为奶牛目标与背景 2部分,且背景在图像中所占比例远大于奶牛占图像的比例,由图3b中发现折线密集区域也由2个部分组成,折线密集区域和折线稀疏区域分别对应目标奶牛像素与背景像素。
将帧图像目标奶牛像素与背景像素分布可近似为 2个正态分布的叠加,如式(2)、式(3),其中包括背景正态分布与目标奶牛正态分布2部分,并根据式(2)计算重率比。其中Pb是灰度直方图中最大值与图像中所有像素的比值。重率比是区分帧图像像素分布当中的背景像素和目标奶牛像素的依据,当第一个正态分布所对应的重率比小于第二个正态分布所对应的重率比且小于1,说明第二正态分布重率比越接近1,其越可能属于背景像素点的分布。
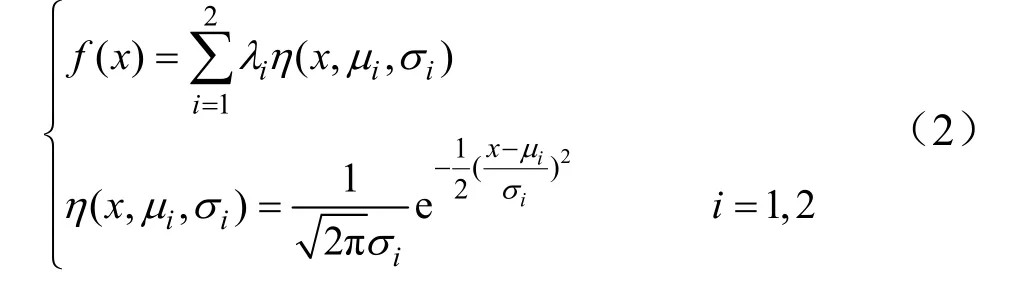
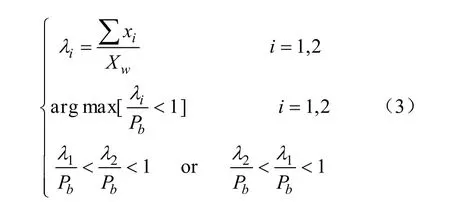
式中x为灰度图像像素点;μi、σi分别为正态分布的均值和方差;λi为2个正态分布分别所占比重;∑xi为对应正态分布的像素点数目;Xw为图像中像素点总数。
在奶牛发生跛行时,奶牛头颈部区域会发生较大幅度的变化,因此,其头颈部区域(前半部像素区域)的完好分割有利于后期跛行行为的检测,而奶牛躯干及臀部区域(后半部像素区域)与之无关。图 4为模型各阶段处理的结果,可以发现,由于奶牛头颈部的运动幅度大于奶牛躯干及臀部区域的运动幅度,且NBSM模型对运动幅度大的区域敏感,在利用NBSM模型进行奶牛目标分离时,奶牛前部区域较为完整,因此可通过该特征将奶牛前半部像素区域提取出来。为了使奶牛身体前部像素区域更加完整,拟利用LCCCT模型进行处理。
1.2.2 LCCCT模型
局部循环中心补偿跟踪模型LCCCT用于补偿通过正态分布背景统计模型分离得到的不完整的奶牛像素区域,并进行奶牛身体前部区域的跟踪,该模型主要由局部循环中心补偿算法、质心跟踪算法2部分构成。
基本形式:给定二维目标循环矩阵
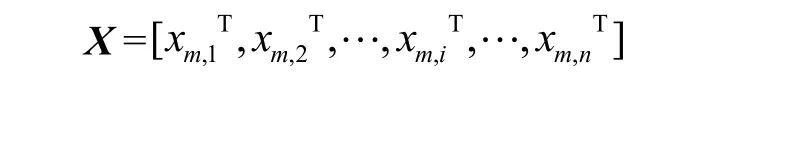
xm,iT与卷积窗口矩阵G进行卷积运算,卷积结果ym,iT为卷积中心所对应的循环矩阵X中的数值进行补偿。
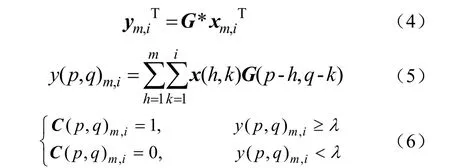
式中p,q代表像素点在图像中的位置,xm,iT为二维矩阵,尺寸大小为3×3,卷积窗口G采用3×3的归一化平均矩阵,Y=[ym,1T;ym,2T;··;ym,iT;··;ym,nT]为结果矩阵,λ为给定阈值,由于卷积矩阵G是一个二维矩阵,尺寸大小为3×3,且矩阵中每一个元素均为1/9,即进行均匀卷积,故λ取值为卷积结果的0.5倍,C为补偿结果矩阵。

图3 帧图像像素分布规律Fig. 3 Frame-image pixel distribution law
循环矩阵进行上式(4)~(6)计算时,可将补偿区域最大化,故而需要将所提取得到的奶牛身体前部像素区域矩阵进行循环矩阵化,如式(7)所示。

式中P、Q是排列矩阵,T是目标奶牛身体前部像素区域矩阵。
循环矩阵与卷积窗口矩阵卷积过程如图 5所示,图5a中卷积窗口矩阵G与循环矩阵X中子矩阵块xm,iT进行卷积运算,得到ym,iT结果矩阵的子矩阵块,在图5b中,得到的 ym,iT进行阈值判别,若 ym,i(p,q) 大于等于给定阈值λ,则C(p,q)m,i=1;若ym,iT(p,q)小于λ,则C(p,q)m,i=0。上述过程可以达到像素区域补偿的目的。

图4 模型各阶段处理的效果Fig.4 Effect of each stage of model
对 NBSM 模型处理过的图像按式(6)进行循环矩阵化,卷积窗口矩阵G与处理过后的循环矩阵进行滑动卷积,得到卷积之后的结果矩阵Y,即将所有像素进行增强处理,通过判别函数来判别当前图像中的像素是否为孤立的像素区域,若是,则进行归零处理,若否,则进行保留,最终得到补偿结果矩阵C,即图4c。从图4c可以发现,LCCC算法对目标奶牛区域保留了奶牛身体前部的形状,补偿了奶牛身体前部区域丢失或损失的像素区域,同时,由于在算法中加入了孤立像素区域的抑制策略,对于非完整的奶牛后部像素区域,可以进行较好地去除处理,在保证前部像素完整性的前提下起到了抑制后部像素区域的效果,为进行奶牛身体前部区域的跟踪奠定了基础。
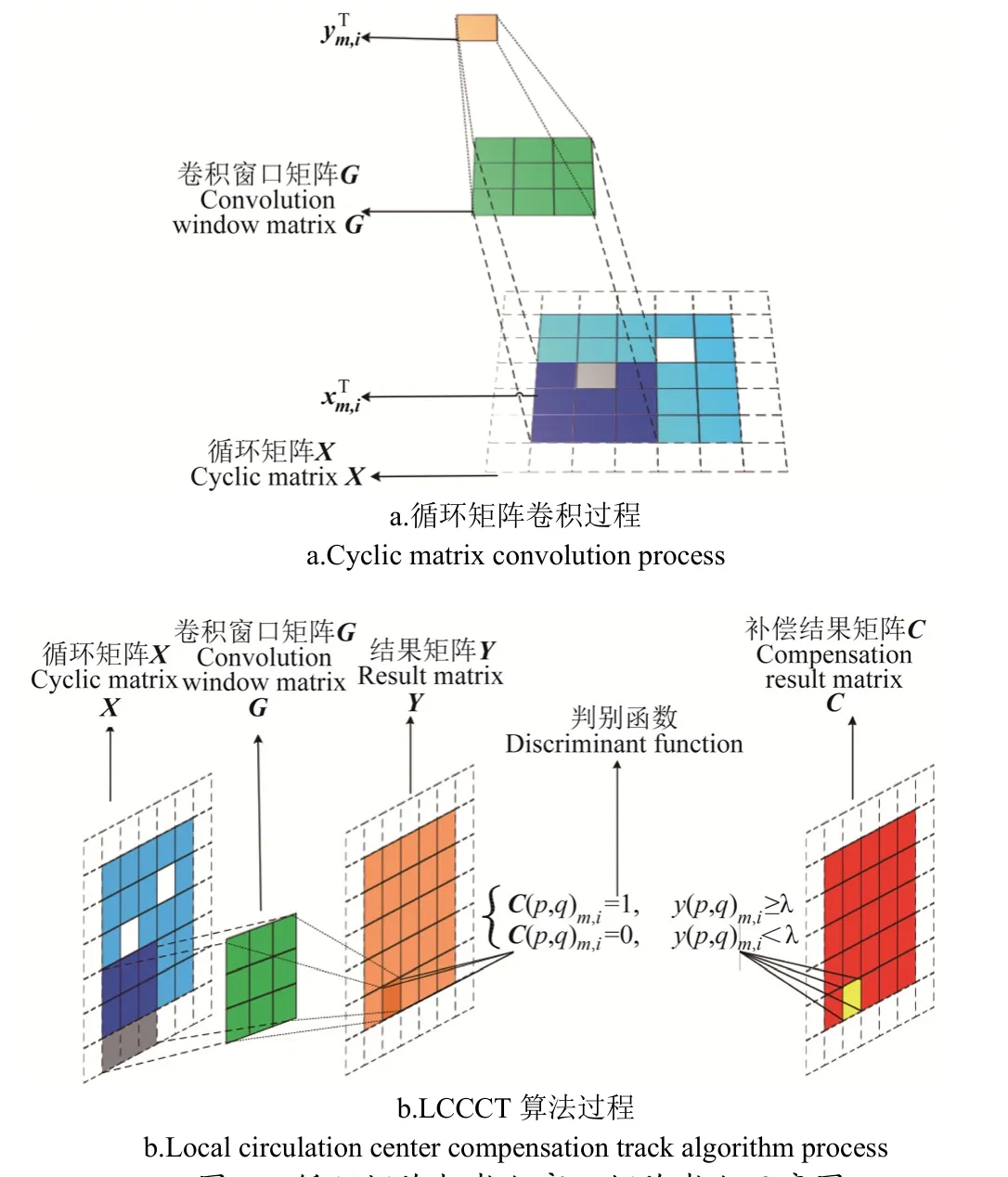
图5 循环矩阵与卷积窗口矩阵卷积示意图Fig.5 Cyclic matrix and convolution window matrix convolution
将局部循环中心补偿算法处理过的图像视为新的图像f(x,y),由于补偿后的新图像中只有奶牛前部像素区域一个目标,不受每次提取目标部分大小的影响,即可根据式(7)计算补偿后的目标奶牛像素区域的质心,根据质心的变化进行奶牛身体前部跟踪。
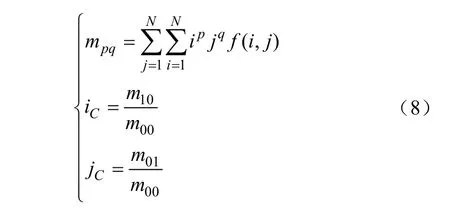
式中mpq是图像f(x,y)的p+q阶矩;m10、m01为其1阶矩、m00为其0阶矩;iC、jC分别为图像f(x,y)的质心横坐标和纵坐标。
为了验证跟踪效果,利用表1所述视频进行了测试,结果表明,视频1-17均可以准确跟踪,仅视频18因奶牛运动幅度过小而导致跟踪失败的问题,表明跟踪算法对普通运动幅度奶牛的跟踪效果具有普遍意义。
图4d为在18段奶牛视频中(除视频序号为18的奶牛视频)随机选取一段奶牛视频跟踪试验效果可以看出,跟踪奶牛身体前部区域均能准确跟踪其位置,为提取奶牛身体前部上轮廓线奠定了基础。
1.2.3 数据清洗
数据清洗(data cleaning)是对数据进行重新审查和校验的过程,用于删除重复信息、纠正错误数据并提供数据一致性[25-28]。数据清洗按功能主要分为4类:1)解决不完整数据的方法;2)错误值的检测及解决方法;3)重复记录的检测及消除方法;4)不一致性的检测及解决方法。
本文采取数据清洗方法是异常值检测混合模型[29]。将对所有未清洗的数据集中的每一个数据计算其评价函数的值(本研究采用马氏距离函数[30]),根据评价函数值来判断当前数据是否为异常点值。具体过程为:1)初始化:在时刻t=0,令Gt包含所有对象,而Bt为空;令ѱ(Gt, Bt)为好坏观测点划分的评价函数(马氏距离);2)对属于Gt的每个点 xt,将 xt从 Gt移动到 Bt,产生新的数据集合Gt+1和Bt+1,计算ѱ的新的评价函数的值;3)计算差值:△=ѱ(Gt+1, Bt+1)-F(Gt, Bt);4)若△<c,将观测xt分类为异常,其中c是给定阈值。
阈值c的取值采用的是3σ准则[31],经过上述数据清洗算法,可将大部分异常点或强影响点剔除,为提高分类器的分类精度奠定基础。
1.2.4 线性斜率K最近邻分类器模型
对提取出来的目标奶牛身体前部像素区域,进行Sobel算子轮廓边缘提取,并利用傅里叶描述子进行边缘平滑[32],然后将奶牛身体前部像素区域中线以下设为0,该过程可以提取目标奶牛身体上部轮廓线,并进行线性拟合,得到拟合直线斜率。
本文对身体上部轮廓线定义为:奶牛身体上部轮廓线是从奶牛头部的鼻尖起始,超过颈部线结束。若提取的轮廓线属于定义的区域范围,则认为是有效的轮廓线,超出此范围区域则认为提取的是异常或具有强影响的轮廓线。奶牛低头、抬头以及左右转头等动作会影响头颈部拟合直线的斜率。但每一类奶牛的拟合直线斜率都存在不同的斜率范围,故而对检测结果没有影响。
如图6为所示获取轮廓拟合直线处理过程及效果。
每一段视频中都有大量的目标奶牛头、颈及背部连接处的轮廓线的拟合直线斜率数据,可将其作为分类特征值进行奶牛跛行的识别及检测。
对18段奶牛视频进行处理,获得头部、颈部及背部连接处的拟合直线斜率数据集。试验采用加噪法,增加样本的多样性,从而可以检测算法对环境鲁棒性的强弱。对于 3类(正常奶牛、轻度跛行奶牛、中重奶牛跛行)18个样本数据集按Bootstrap抽样法[33-37]随机分3层抽取3次,将抽取到不重复的样本作为训练样本,剩下样本作为测试样本,所得到的训练样本集约占总数据集的63.2%。
本研究采用 K最近邻分类器(K-nearest neighbor,KNN)进行数据分类[38]。KNN 算法的思路是:如果一个样本在特征空间中的 K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
该方法在定类决策上只依据最邻近的一个或者几个样本类别来决定待分样本所属的类别。由于KNN方法主要靠周围有限的邻近样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。本研究在利用KNN算法时采用的距离度量方式是标准欧几里得距离[39],无距离加权函数,K值为3,即轻度跛行奶牛、中重度跛行奶牛、正常奶牛3类。
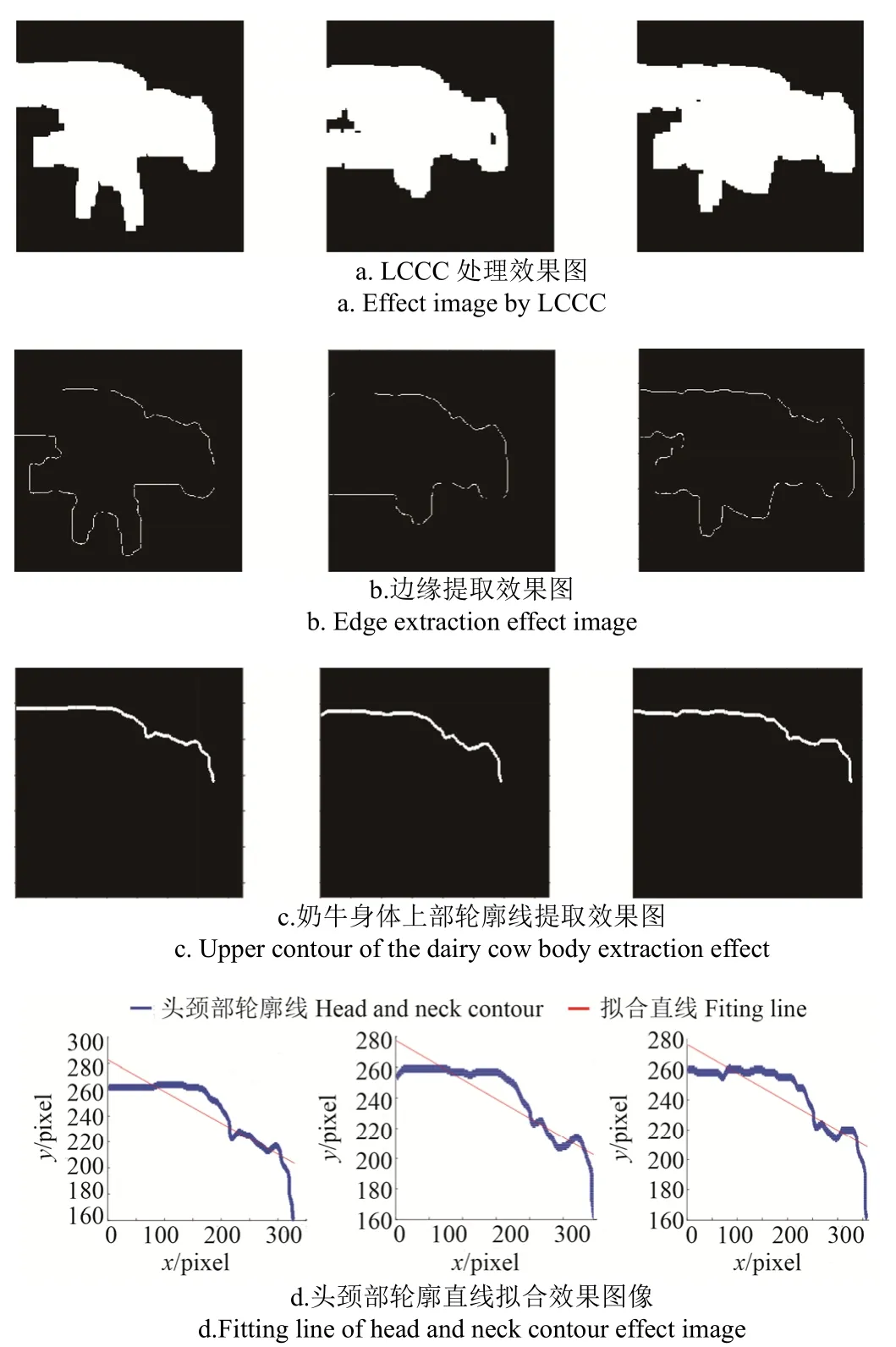
图6 获取头颈部轮廓拟合直线处理过程及效果Fig.6 Process and effect of fitting line of head and neck contour
2 试验与结果分析
2.1 试验设计
为了验证该方法的有效性,分别使用了SVM[40]、朴素贝叶斯(naive bayes, NB)[41]分类器以及KNN的分类器对奶牛头部、颈部及背部连接处的斜率数据清洗前后进行效果对比试验,本研究用10折交叉的方法在数据集上做分类测试。
2.2 使用分类算法对奶牛跛行检测的结果
2.2.1 3种分类器性能结果分析
表2为SVM、Naive Bayes及KNN在未清洗的测试数据集的试验结果比较。可以看出,SVM和Naive Bayes的平均值均达到了82.78%,但比 KNN的平均分类精确度81.67%高1.11个百分点。由于未清洗的数据集呈现复杂度高、特征值分布杂等特点,SVM和Naive Bayes这类统计性分类算法,比只将训练数据与测试数据进行距离度量来实现分类的KNN算法更加合适在未清洗的数据集上进行分类。从结果上来看,在未清洗的数据集上,3种分类器的准确率均不高,但选取奶牛头部、颈部及背部连接处特征能够进行奶牛跛行的检测。
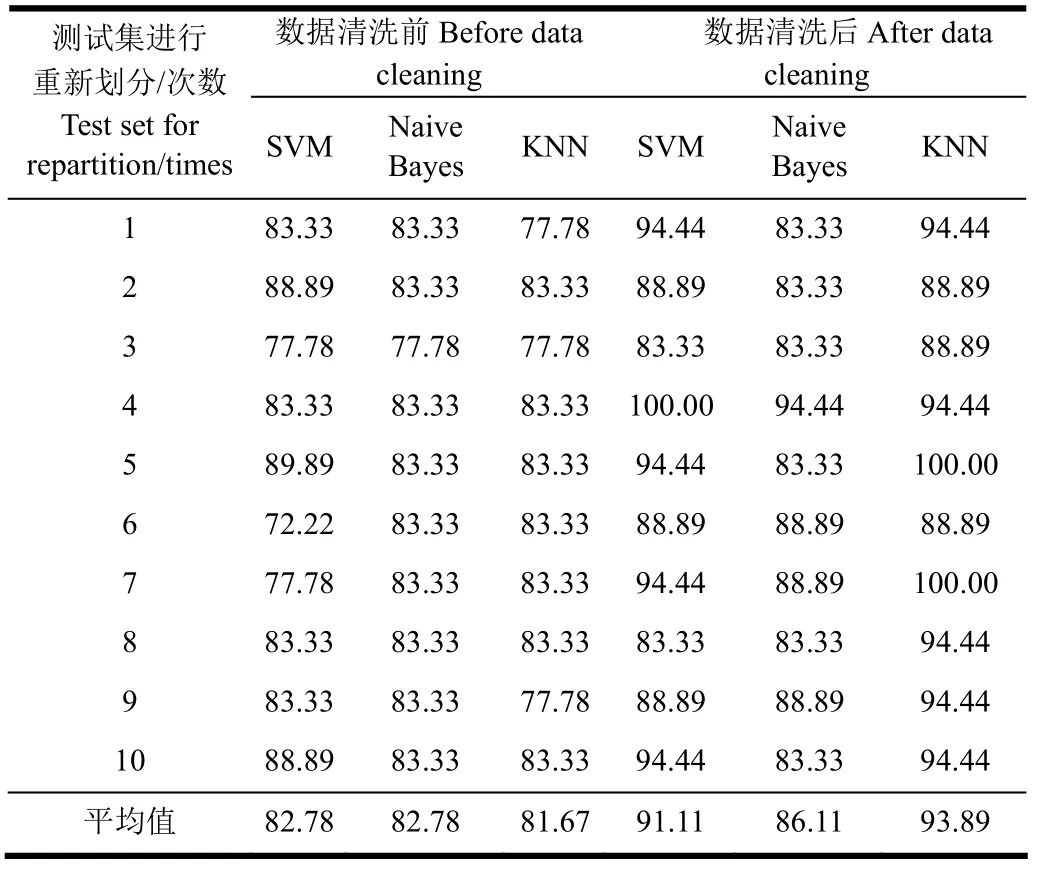
表2 SVM、Naive Bayes及KNN在数据清洗前后对测试数据集的分类正确率比较Table 2 Comparison of classification accuracy by SVM, Naive Bayes, and KNN algorithm on test data sets before and after data cleaning %
3种算法在未清洗的数据集上的训练所需时间及正确率比较如图7所示。从图7a可以看到,SVM和Naive Bayes训练所需时间很接近,SVM花费的时间要比Naive Bayes略高,主要原因是SVM算法要对未清洗的数据集作分类超平面的统计,而KNN所用时间相对较短,主要原因是KNN不需要进行模型训练而只需要进行距离度量的计算。从图7b可以看到,在未清洗的数据集上,SVM和Naive Bayes的正确率略高于KNN;试验结果说明使用SVM与Naive Bayes分类器在未清洗的数据集上将正常奶牛、轻度跛行奶牛、中重度跛行奶牛错误分类的可能性很小。
2.2.2 数据清洗后3种分类器性能结果分析
如图 8所示为正常、轻度跛行、中重跛行奶牛斜率未清洗的数据集箱图,由于奶牛行进方向不一致,得到的斜率有正有负。当奶牛由左往右行进,得到的斜率数据为负,反之为正。为了数据保持一致性及规律性,将为负的斜率数据按式(8)进行转换成正斜率数据。在图8中,每一个箱体代表一段视频中的斜率数据集,箱体中的线段为该段视频里斜率数据的中位数(中位线),奶牛低头、抬头以及转头等动作会影响头颈部拟合直线的斜率,在奶牛视频中若突然出现上述动作,则斜率会发生突变,即与其他帧图像所获得的斜率差异较大,这些突变的斜率视为异常点,即箱体外的点标记代表异常点。其中,第 1、2、5组中重度跛行奶牛、轻度跛行奶牛以及正常奶牛的箱图虽然有交叠区域,但中重度跛行奶牛的箱体中位线均在其箱体图的 50%以下,轻度跛行奶牛的中位线基本保持在同一水平线,正常奶牛的中位线均处于上述2者中位线之上,具有明显的区分度。第4组视频箱图里,中重度跛行奶牛箱图分布发生异常,是由于在该段奶牛视频里的奶牛跛行程度严重且发生了多次的低头、抬头以及转头等动作,即异常点增多,常规斜率数据点减少,但在第4组视频中箱图仍然可以发现,3类奶牛箱图中位线区分明显,不影响奶牛跛行的检测结果。发现正常、轻度跛行、中重跛行奶牛斜率未清洗的数据集中均存在异常点,这些异常点会影响分类器的分类准确率。将异常点剔除,即将奶牛抬头、低头等行为的干扰影响消除。

式中xi为负的斜率数据, xi*为新的正斜率数据
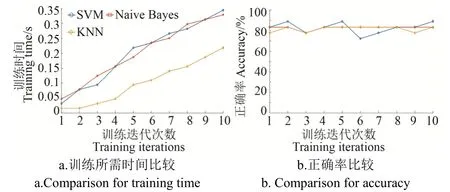
图7 未清洗的数据集上训练所需时间及正确率比较Fig.7 Result of comparison for training time and accuracy on uncleaned data sets
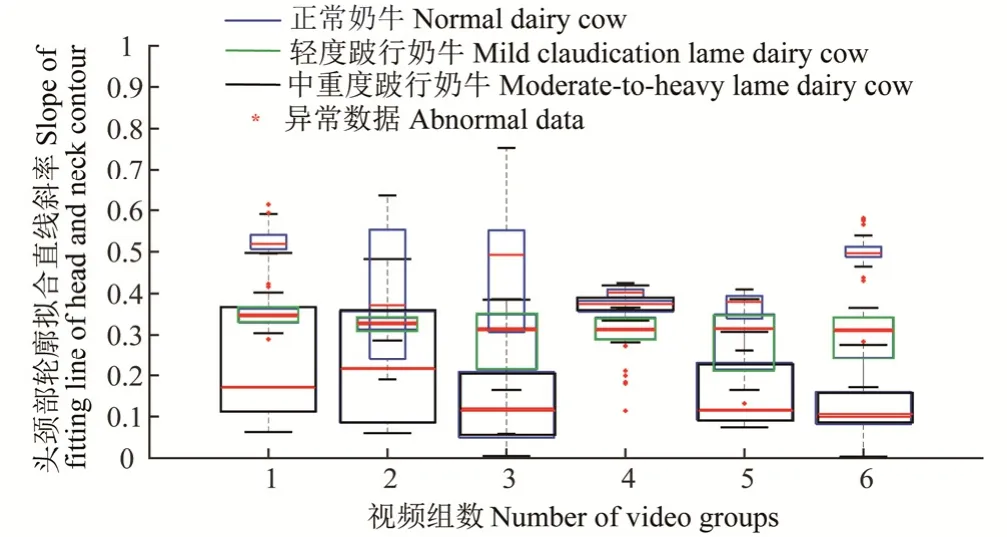
图8 正常、轻度跛行、中重跛行奶牛未清洗的斜率数据集箱图Fig.8 Boxplot of uncleaned slope data set for normal, mild claudication, moderate-to-heavy lame dairy cows
针对清洗之后的新数据,进行SVM、Naive Bayes以及KNN分类算法的试验,试验结果见表2。
虽然SVM和 KNN的平均值分别达到了91.11%和93.89%,但KNN的平均分类精确度高出SVM分类精确度2.78个百分点,而Naive Bayes的分类精确度,相比未清洗的数据上进行分类精度虽有增长,但在此次试验结果中是分类精度最低的分类器。由于新数据集具有较少的强影响点或者没有异常点,所以KNN这类只进行距离度量来实现分类的算法要优于SVM和Naive Bayes这类统计性分类算法,在新数据集上KNN算法更加合适进行分类。但从分类结果上来看,在清洗之后的新数据集上,3种分类器中的SVM与KNN的准确率均较高。
3种算法在清洗之后的数据集上的训练所需时间及准确率比较如图9所示。从图9a可以看到,SVM训练所需时间很长,而Naive Bayes训练所需时间次之从图9b可以看到,在新的数据集上,KNN的错误分辨率明显高于SVM和Naive Bayes,KNN的平均正确率接近94%。试验结果说明使用KNN分类器将在未清洗的数据集上将正常奶牛、轻度跛行奶牛、中重度跛行奶牛错误分类的可能性很小,且因为时间是以秒计算,实际应用中在大量数据的情况下KNN训练所需时间的优势非常明显。

图9 在数据清洗后数据集上训练所需时间及正确率比较Fig.9 Result of comparison for training time and accuracy on cleaned data sets
2.3 斜率异常点值或强影响点对分类结果的影响
本文提出的算法通过奶牛头部、颈部及背部连接处的拟合直线斜率能够检测到奶牛跛行的种类,包括正常奶牛、轻度跛行奶牛、中重度奶牛 3类,在不同环境影响下通过本文提出的算法进行了环境鲁棒性的试验,结果如图10所示。
数据清洗将未清洗的斜率数据中的异常突变值进行了剔除,通过减少异常突变值的方式,得到的奶牛跛行类型概率平均提高了10.00个百分点,可以发现该算法在晴天、阴天以及白天与夜间均能得到正确结果,表明该算法具有较好的环境鲁棒性。
获得头部、颈部及背部连接处的拟合直线斜率数据的未清洗的数据集中,存在强影响点值与异常点值,这两种数据会影响分类器的分类准确度。产生这两类点是由于局部循环中心补偿算法的局限性,算法由于数学关系决定了其只适用于各像素位置间距较小的情况,而出现这类情况根本原因是奶牛整体运动幅度过小导致的。如图 11a~图 11c所示,这类像素位置间距较大的情况LCCCT算法效果不明显。
由于这一原因,在奶牛跛行跟踪的过程中,容易将跟踪区域平移,将目标区域错过。图11a所示,跟踪框偏离了目标跟踪区域,图11b~图11e提取了偏离目标跟踪区域的像素区域,并进行了上轮廓线的提取,导致图11f中拟合直线误差非常明显,无法表达此时可奶牛头部、颈部及背部连接处真实斜率数据,即所得斜率数据也是异常点数值或强影响点数值。这类情况所产生的数据会导致分类器的分类准确率降低。
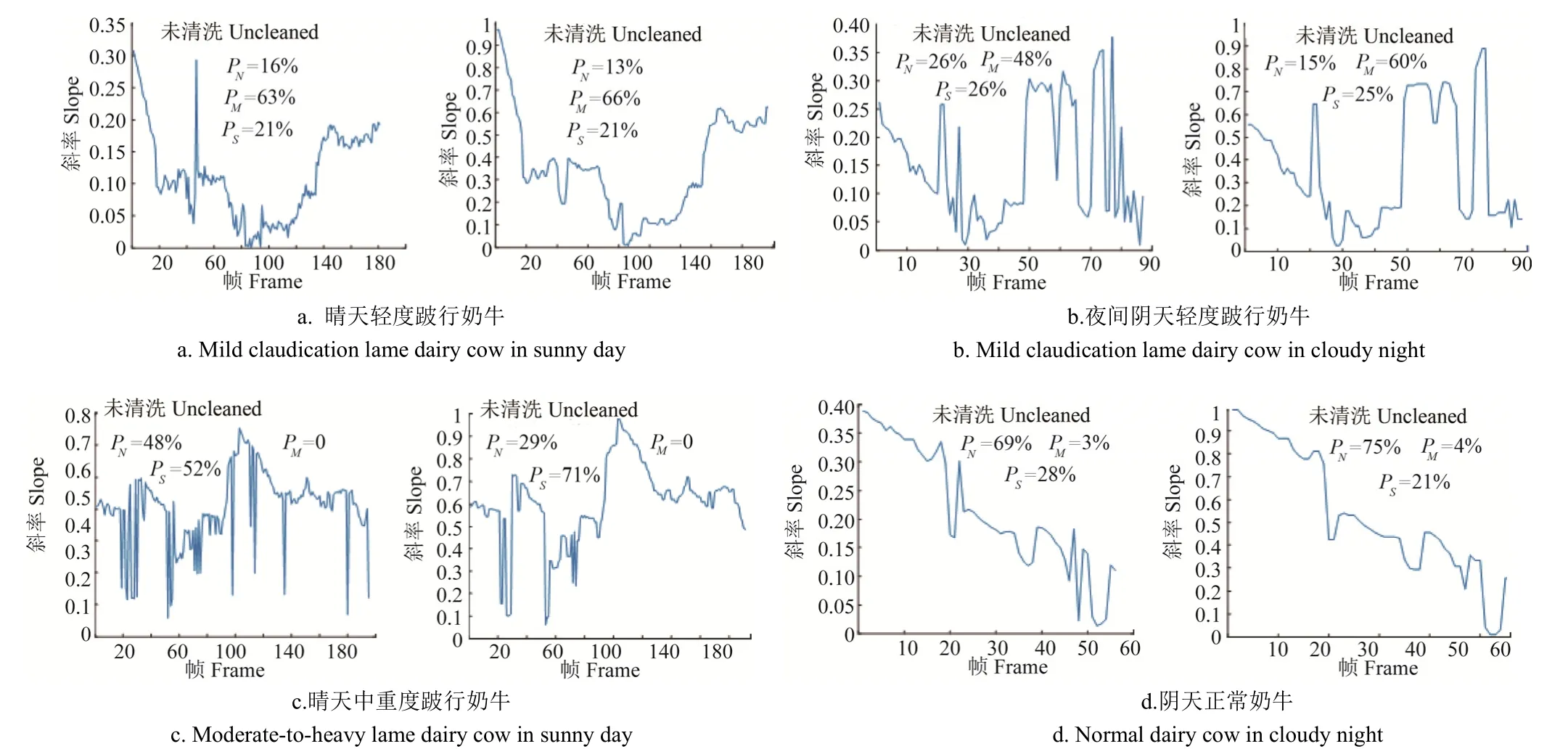
图10 数据清洗前后算法环境鲁棒性试验结果Fig.10 Results of algorithm environment robustness test before and after data cleaning
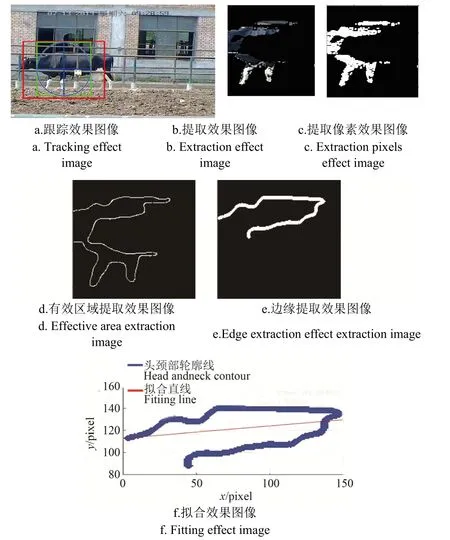
图11 产生奶牛斜率异常点或强影响点的情况Fig.11 Produce a point of abnormal cows or strong impact point of the situation
3 结 论
为了解决现有人工跛行检测存在的不够及时,难以发现问题,本研究基于视频分析技术,利用NBSM-LCCCT-DSKNN模型实现了奶牛跛行检测,所取得的主要结论如下:
1) 利用文中算法提取出未清洗的头颈部斜率数据,在SVM、Naive Bayes以及KNN算法进行跛行的分类检测对比可以发现中,SVM与Naive Bayes分类算法准确率相同且最高均为82.78%,表明选取奶牛头部、颈部及背部连接处特征检测奶牛跛行是有效的、可行的。
2)在清洗后数据集上进行跛行的分类检测,在SVM、Naive Bayes以及KNN算法进行跛行的分类检测对比中,SVM 与 Naive Bayes分类算法准确率分别为 91.11%、86.11%,KNN算法分类准确检测率达到了94.44%,表明在数据清洗的基础上进行奶牛跛行分类有助于提升其分类精度。KNN算法训练时间明显小于其他二者算法的训练时间,其更适合进行奶牛跛行检测。
3)由于在局部循环中心补偿算法中其循环矩阵的局限性,进行跛行的分类检测过程时,数据集中的异常点与强影响点均会降低奶牛跛行分类准确检测率;本文算法能够对正常奶牛、轻度跛行奶牛、中重度跛行奶牛进行准确的跛行判断,但未能对运动幅度过小、存在其他异常行为的奶牛做出正确的分类检测,尚需进一步深入研究。
