基于GF-1遥感影像和relief-mRMR-GASVM模型的小麦白粉病监测
2018-08-21黄林生黄文江彭代亮丁文娟
黄林生,阮 超,,黄文江 ,师 越,彭代亮,丁文娟
(1.安徽大学农业生态大数据分析与应用技术国家地方联合工程研究中心,合肥230601;2.中国科学院遥感与数字地球研究所,数字地球重点实验室,北京 100094)
0 引 言
小麦白粉病是小麦生产过程中的主要病害之一[1]。及时有效地监测出小麦白粉病的发生对提高小麦的产量和质量具有重大意义[2]。传统的监测方法主要依靠地面调查,需要耗费大量的人力物力,不适合大区域的应用[3],遥感技术的发展使大区域的监测成为可能。特征变量提取和监测模型构建是遥感监测的 2个重要环节。目前大部分学者采用相关性分析[4]、独立样本 T检验[5]、relief算法[6]和最小冗余最大相关(minimum redundancy maximum relevance,mRMR)[7]等算法进行特征提取。尽管这些特征选择方法在特征筛选中具有较好的适用性,但单一的方法无法同时考虑到特征之间的冗余性和特征与类别之间的相关性,如relief算法没有考虑特征之间存在的冗余性[8],mRMR算法则无法体现不同特征对分类作用的差异[9],而上述已有的研究并未考虑这种不足。将relief和mRMR算法结合使用,可有效弥补2种算法的不足,如王露等[10]利用遥感图像,通过 relief算法结合mRMR算法实现了对地物的分类,且分类精度高于只用relief算法和 mRMR算法的分类精度。Zhang等[9]利用relief算法和mRMR算法对数据集进行降维,在基因选择研究中也取得了较好的效果。
此外,建模方法的选择直接影响监测模型的效果。支持向量机(support vector machine,SVM)是一种基于统计学习理论的模型构建方法[11],通常用在模式识别、分类及回归分析等问题中。黄林生等[11]利用SVM建立了小麦白粉病的监测模型。胡根生等[4]利用粒子群(Pso)优化的最小二乘支持向量机(least squares support vector machine,LSSVM)建立了小麦蚜虫的监测模型(Pso-LSSVM)。但是,运用这种算法时,如何有效选择核函数、确定参数等问题仍然存在争议。传统的网格寻优(grid search,GS)算法效率低,计算量大,花费时间长,效果并不理想[12]。而遗传算法(genetic algorithm,GA)擅长解决全局最优化问题,算法鲁棒性强,且过程简单,在进行快速搜索时可与问题的领域无关,扩展性好[13]。
基于上述分析,本文以河北藁城的小麦为研究对象,利用 GF-1遥感影像反演得到初选特征集,将通过 relief算法结合mRMR算法筛选得到的优选特征集作为模型的输入变量,与经过 GA算法优化的 SVM(GASVM)方法建立白粉病的监测模型(relief-mRMR-GASVM),对区域尺度的白粉病进行监测,并将其结果与仅通过单一的relief算法或 mRMR算法筛选得到的特征集结合未经过优化的SVM方法和经过GS算法优化的SVM(GSSVM)方法建立的监测模型进行对比分析,同时比较了该方法与已有的3种白粉病监测方法AdaBoost[7]、Pso-LSSVM[4]和随机森林[14](random forest,RF)的优越性。。
1 材料与方法
1.1 研究区概况
本文的研究区域位于河北省石家庄市的藁城(如图1)。河北省麦区在气候分区中属于黄河流域冬小麦白粉病易发气候区[15]。该区域地势平缓开旷且全境皆平原,由于此地地势平坦,气候变化不大,以温暖湿闷为主,加之当地水肥条件好,产量高,麦田群体密度高,且是白粉病发生的典型区域[16],故可以考虑利用遥感卫星影像来对小麦白粉病进行监测。
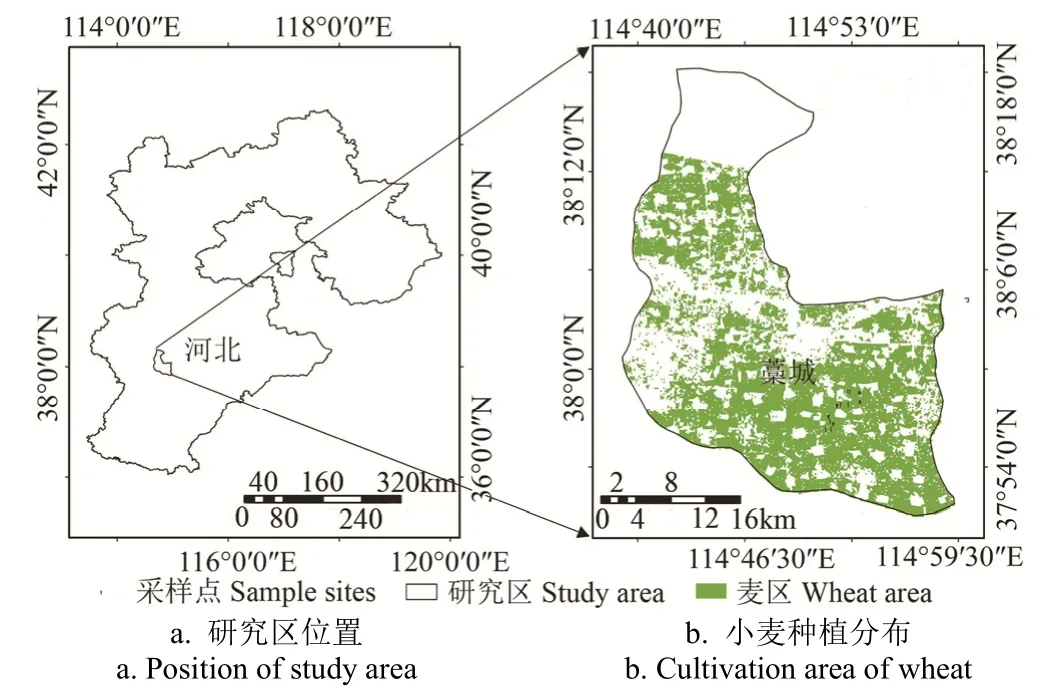
图1 研究区概况Fig.1 General situation of study area
1.2 数据获取
研究所用的数据主要包括遥感卫星影像数据和实地调查的小麦白粉病数据。考虑到研究区当时的天气、病害调查时间以及影像质量等因素,遥感数据选取了 2014年05月26日的GF-1/WFV数据。GF-1/WFV数据的空间分辨率为16 m,有蓝、绿、红、近红外4个波段,光谱范围0.45~0.89 μm。实地调查数据于2014年05月26日和27日小麦灌浆期调查获得,采用了5点调查法进行病害调查,即在每个调查点取1 m×1 m的样方,在调查点中心用全球定位系统(global position system,GPS)进行定位,样方里均匀选取5个对称的点,每点选取20株小麦进行调查,记录样方内白粉病发病情况。病情严重度采用改进的小麦白粉病“0~9级法”[17]对病害严重程度进行记录,将小麦从上到下均匀地分成 9段,根据表 1的分级标准进行分级,然后计算出病情指数[18]
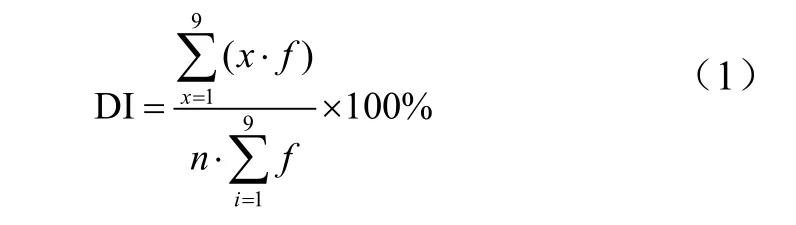
式中DI(disesase index)为病情指数,x为发病级数,n为最高级别9,f为不同发病级别的株数。
实地调查发现藁城白粉病发生严重,且南部发病严重。共获取了56个采样点数据,选取42个采样点数据作为训练样本,其余的14个样本点数据用于模型的验证。
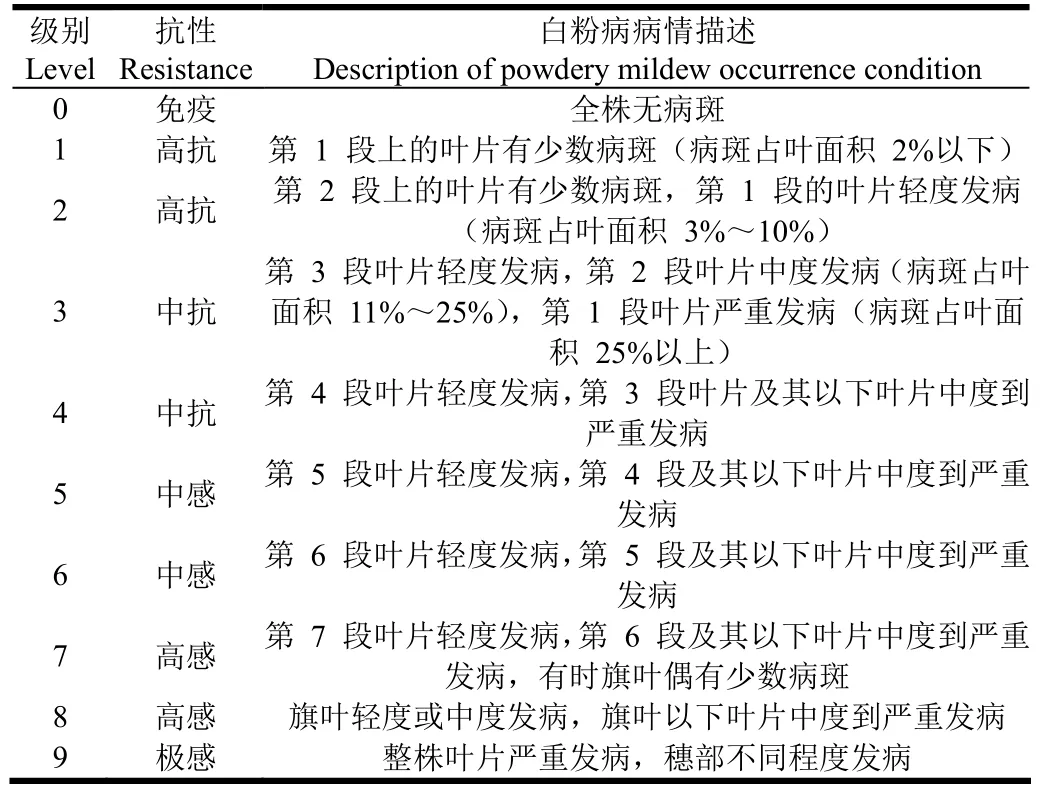
表1 小麦白粉病发生程度分级标准Table 1 Grading standards of wheat powdery mildew occurrence degree
1.3 数据预处理
获取的 GF-1/WFV影像需要经过辐射定标,大气校正,并结合Landsat 8影像数据进行正射校正等预处理。GF-1影像辐射定标公式如下:
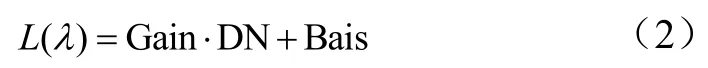
式中 L(λ)为辐射亮度值(W/(m2·sr·μm)),Gain 为增益系数,Bias为偏置系数,DN为观测灰度值,Gain和Bias都由中国资源卫星应用中心提供。
辐射定标完成后,采用ENVI5.1软件中的 FLAASH大气校正模块将影像的辐射亮度转为反射率,最后对图像进行裁剪获得所要研究的区域的影像。
预处理完成后利用最大似然分类法提取小麦的种植面积,小麦种植面积分类图见图1b。
植株感病时会出现明显的冠层结构变化及水分变化,从而引起近红外波段反射率改变[19],色素的含量和活性也会降低,导致可见光区域的反射率增加,同时发生红边蓝移的现象[20],所以红波段和近红外波段与病害有较显著的相关性且对特定波段反射率进行组合、变换,能够加强健康样本与非健康样本两者之间的差异[21]。本文选取14个在病害监测研究中常用的特征变量[1,4,11,21],包括4个反射率波段(蓝、绿、红、近红外)以及10个由红波段和近红外波段或者搭配其他波段进行组合、变换而来的植被指数(表2)作为白粉病监测模型的初选特征因子。
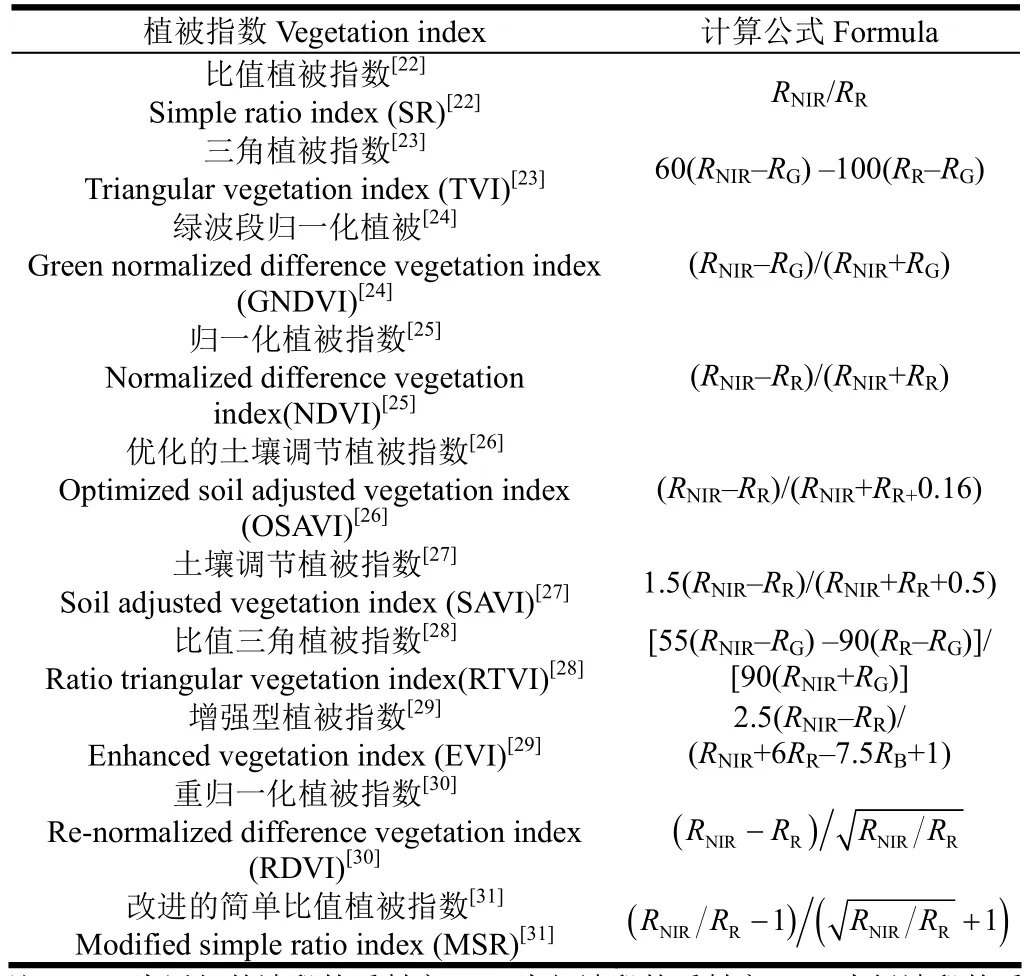
表2 宽波段植被指数Table 2 Vegetation index of wide band range
1.4 特征变量选取算法
1.4.1 relief特征降维算法
relief算法是一种特征权重算法,通过计算特征与类别之间的相关性的大小来对特征赋予不同的权重,当特征的权重小于设定的阈值时就会被移除[8]。relief算法从初选的特征集中随机选择一个样本a,然后在同类样本集中寻找一个最近邻样本 H,在不同类样本集中寻找一个最近邻样本M,样本a在特征l的权值w表示为[32]:
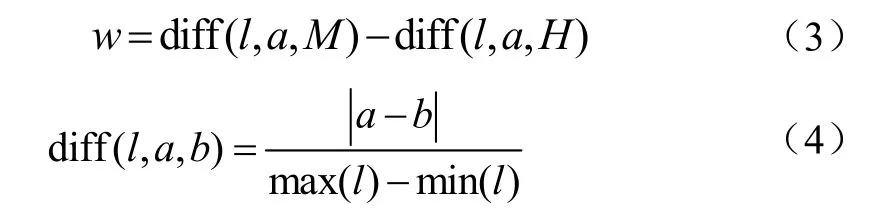
式中diff(l, a, b)表示样本a和b在特征l上的距离,max(l)和min(l)分别是l的上界和下界。
1.4.2 mRMR算法
mRMR算法是基于信息理论的典型特征降维算法[9],该算法主要是从经过relief算法筛选的特征中找出与病害类别具有最大相关性且相互之间具有最少冗余性的 n个特征。利用互信息[18]衡量特征子集中特征与特征之间、特征与小麦发病情况之间的相关度。互信息I(x,y)为:
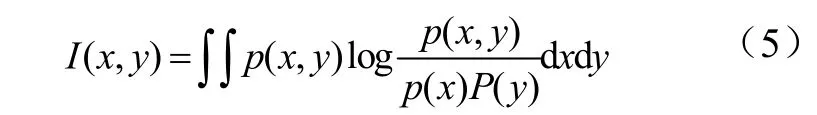
式中 p(x)为变量 x的概率,p(y)为变量 y的概率,p(x,y)为x,y的联合概率。
特征集中特征与特征的相关度为:
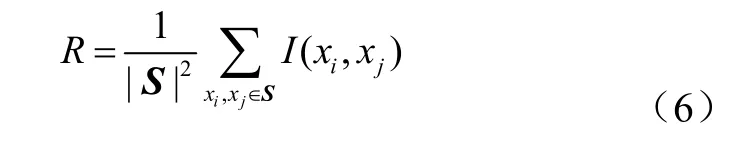
式中S为特征集合,|S|为该特征的样本个数,xi、xj分别为特征i和特征j中的特征变量,I(xi,xj)为特征i与特征j之间的互信息。
特征集中的特征与类别之间的相关度为:

式中z为目标类别,I(xi,z)为特征i和目标类别z之间的互信息。
根据差准则组合式(6)、(7)即得到mRMR的特征选择标准:

1.4.3 relief-mRMR算法
relief算法运行效率高,通过计算特征的权重,能够对分类能力强的特征赋予较高的权重[8],但relief算法不考虑特征之间存在的冗余性,不能去除冗余特征。仅仅通过relief算法得到的候选特征集虽然与小麦白粉病有较高的相关性,但是由于特征之间可能存在的冗余性反而会对模型的精度造成不利的影响。mRMR算法能够得到特征之间具有最小冗余性且特征与目标之间具有最大相关性的特征集,但mRMR算法计算复杂度高,计算量大,它在相关性方面的准确性要低于relief算法,而且无法得到明确的权重大小,提取出的特征集无法体现不同特征对分类作用的差异[9],可能会导致对白粉病区分度好的特征被误删。因此提出relief算法结合mRMR算法(reliefmRMR)来对初选特征进行降维处理,通过利用relief算法筛选出与白粉病相关性高的候选特征集,提高区分度好的特征的权值,同时减少了mRMR算法在计算上的负担,再利用mRMR算法去除候选特征集间的冗余特征,得到最优的特征集。
1.5 监测模型的构建方法
本文通过GA算法优化的SVM来构建小麦白粉病的遥感监测模型。SVM的基本思想[13]就是寻找一个最优超平面,使得该超平面在保证分类精度的同时最大化超平面的两侧。在SVM分类器中,独立的超平面可以定义为

式中 ω表示法向量,决定了超平面的方向;x表示特征向量;k表示偏移量,决定了超平面与原点的距离。
通过引入正则优化项和松弛变量ξ,将式(9)转化为

式中C为惩罚因子,n为特征维数,y为目标类别。
引入拉格朗日乘子求解此约束优化问题,最后得到SVM的决策函数为
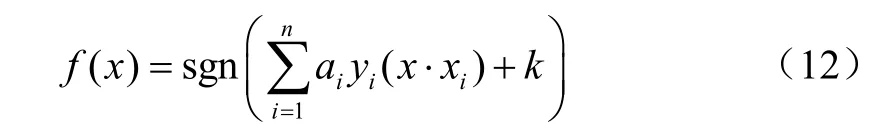
式中ai是拉格朗日乘子,yi(x·xi)是核函数。
径向基核函数在非线性拟合方面具有较好效果[33],因此本文选用径向基核函数作为SVM的核函数,影响监测模型精度的2个模型参数是惩罚因子C和径向基核函数参数γ。传统的参数选取方法多是采用反复试验的方法确定。目前常用GS(gird search)算法得到最优的参数,但这种方法效率低,工作量大[13]。GA(genetic algorithm)算法的优点在于解决全局最优问题,而且鲁棒性强,在进行快速搜索时可与问题的领域无关,扩展性好。本文利用GA算法的优点对惩罚因子和核参数进行优化,利用GA优化SVM[34]建立小麦白粉病监测模型的步骤如下:
1)初始化种群。
2)将经过relief-mRMR算法筛选后的样本数据分为训练样本和验证样本。本文实地调查数据有56个点,将其中42个点的样本数据作为训练样本对每组参数进行训练,其余的14个点作为验证样本,计算出输出值与期望值的平均相对误差。
3)对种群进行选择、交叉、变异运算。
4)判断是否满足初始设置的最大遗传代数 100,满足条件时得到最优的惩罚因子和核参数。
5)用参数优化后的SVM模型对河北小麦白粉病进行监测。
2 结果与分析
2.1 特征变量的选取
通过relief算法计算出初选的14个特征与类别之间的权重分布,如图2所示。
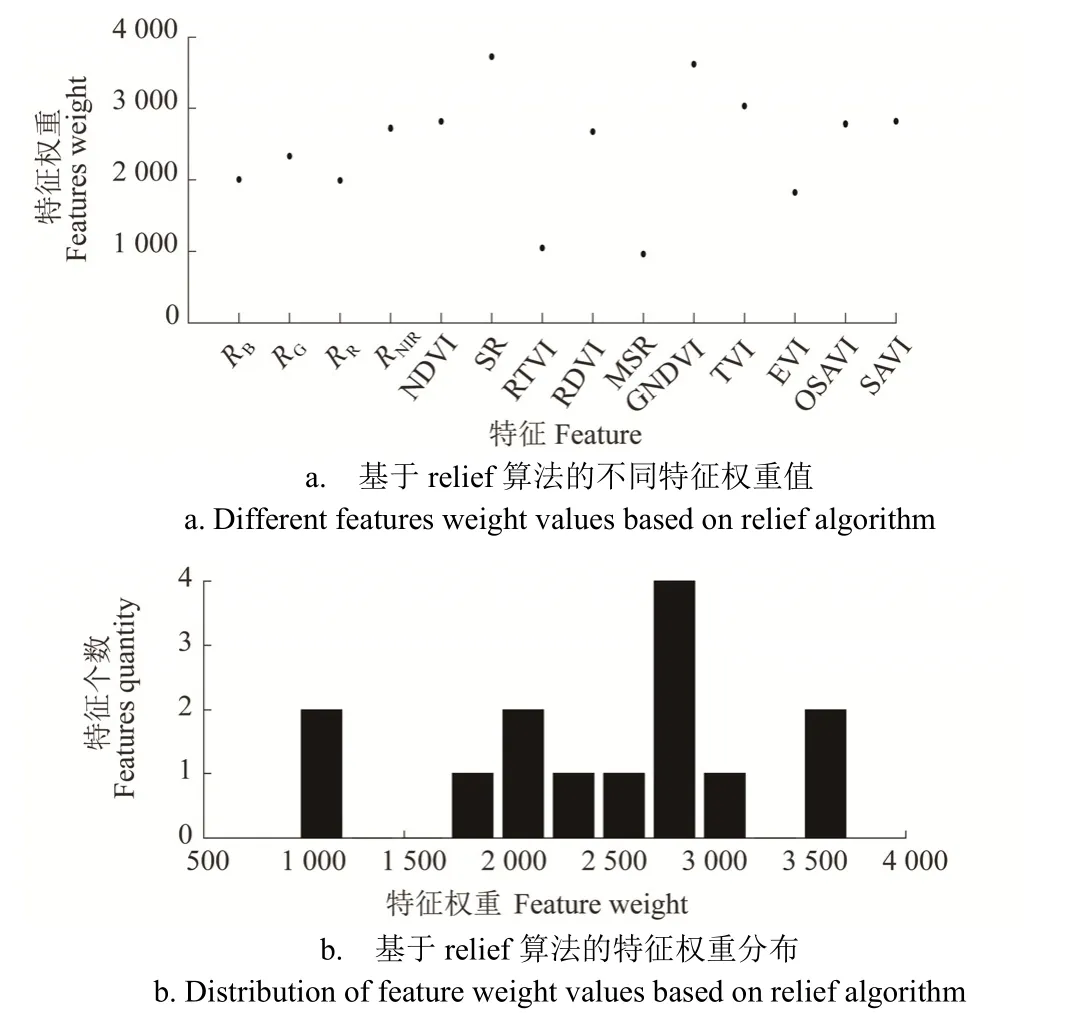
图2 relief算法特征权重计算结果Fig2 Calculation results of feature weight by relief algorithm
为使筛选出的特征变量的数量不至于过多,将权重阈值设置为2 500,筛选出满足条件(≥2 500)的8个特征作为mRMR算法的候选特征集,然后通过mRMR算法进一步筛选得到最优的特征变量SR、NIR、NDVI作为第1组特征集,同时选取relief算法得到的权重最大的3个特征SR、GNDVI、TVI作为第2组特征集,选取单独采用mRMR算法得到的最优的3个特征TVI、RTVI和RDVI作为第3组特征集。对比不同方法筛选出的特征变量,SR、NIR、NDVI和GNDVI[21-22,24-25]主要表征植被受病害胁迫后的长势和植被覆盖度变化,RDVI[31]主要表征不同高低植被覆盖度下的生物量信息,TVI和RTVI[23,28]表征了胁迫引起的生物组分含量变化。而从病理的角度,由于受白粉病侵染后叶片表层孢子菌落发展的影响,作物的冠层结构受到破坏,导致红边及近红外波段产生较大响应[19]。因此,相比后2组特征,relief-mRMR算法筛选出的特征更偏重于反映这种长势及冠层结构信息的变化。
2.2 病害监测模型的构建
本文通过relief算法、mRMR算法和relief-mRMR算法筛选的最优特征变量,结合未经优化的SVM、经过GS算法优化的 SVM(GSSVM)和 GA算法优化的 SVM(GASVM)共建立了9种小麦白粉病监测模型,分别为relief-SVM模型、mRMR-SVM模型、relief-mRMR-SVM模型、relief-GSSVM 模型、mRMR-GSSVM 模型、relief-mRMR-GSSVM模型、relief-GASVM模型、mRMR-GASVM模型和relief-mRMR-GASVM模型。
2.3 不同特征降维方法对应模型精度对比分析
采用独立的样本数据对模型进行验证能够更好地体现实际模型的精度[5]。本文结合2014年05月26日和27日的实地采样点数据对 9种模型进行了评估,同时对其他学者提出的几种白粉病的监测方法进行了对比分析。表3列出了3种特征选择算法结合3种建模方法建立的白粉病监测模型的性能对比。
从表3中可以看出,在SVM、GSSVM和GASVM 3种方法模型中,relief-mRMR算法筛选特征所建监测模型的精度和Kappa系数均高于relief算法和mRMR算法单独筛选特征所建模型。relief-mRMR算法筛选出的特征与GASVM、SVM 和 GSSVM 建立的监测模型精度比传统 relief算法筛选特征所建模型的精度分别提高了 14.3个百分点、7.2个百分点和7.1个百分点,比传统mRMR算法筛选特征所建模型的精度分别提高了14.3个百分点、14.3个百分点和14.2个百分点。对比SVM、GSSVM和GASVM 3种模型方法所建模型可以看出,GASVM 方法建立的监测模型精度高于SVM 和 GSSVM 方法建立的监测模型精度,其中relief-mRMR-GASVM 模型的精度最高,总体精度比relief-mRMR-GSSVM和relief-mRMR-SVM模型的总体精度分别高出 7.2和 21.4个百分点,且 relief-mRMR-GASVM 模型的总体精度、用户精度、制图精度均为85.7%,Kappa系数为0.714,为所有模型中最高。以上结果说明 relief-mRMR算法能够更加有效地筛选出反映小麦的长势与发病情况的特征,其筛选特征所建模型优于relief算法和mRMR筛选特征所建模型。GASVM方法建立的监测模型优于未经优化的SVM和GSSVM方法建立的模型精度,relief-mRMR算法结合GASVM方法建立的白粉病监测模型可以有效提高模型监测精度,这与Zhang等[9]和王露等[10]的研究结果一致。
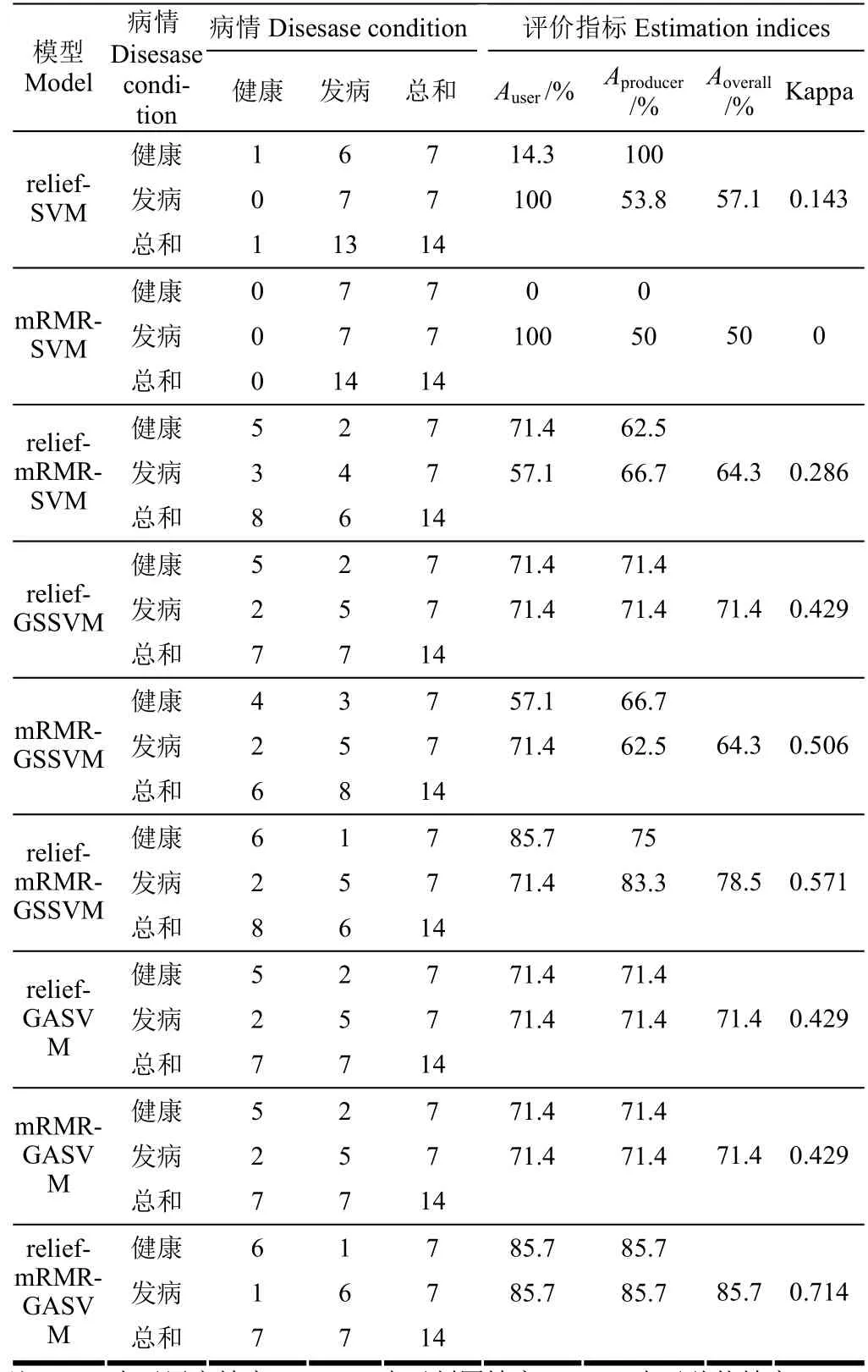
表3 模型分类精度对比分析Table 3 Accuracy analysis of different classification for models
2.4 不同模型精度对比分析
为进一步验证本文建模方法的优越性,研究以relief-mRMR算法筛选特征作为输入变量,分别用已有的3种白粉病监测方法AdaBoost[7]、Pso-LSSVM[4]和RF[14]构建监测模型,并将其结果与relief-mRMR-GASVM模型结果进行对比分析。4种监测方法的具体验证结果如表4所示。可以看出采用GF-1数据结合relief-mRMR-GASVM模型的监测精度高于其他几种方法的监测精度,其监测精度比AdaBoost方法、Pso-LSSVM方法和RF分别高出21.4、14.3和7.1个百分点。这一结果显示已有的3种方法在本文中并未表现出同已有文献[4,7,14]中一致的较优的结果,导致这一结果的原因可能与不同研究中的样本数据的数据源不同有关,本文所用遥感影像为空间分辨率更高的 GF-1影像数据,其他已有研究所用数据均为Landsat-8 TM数据[2,4,14],GF-1影像数据的信噪比等指标要低于Landsat TM数据,且不同的传感器在光谱覆盖范围和光谱响应上均存在差异[35],由不同传感器的光谱响应函数、信噪比及混合像元效应引起的差异对模型精度的影响仍需要下一步探讨。

表4 不同白粉病监测方法验证结果Table 4 Validaiton results of different powdery mildew monitoring methods
2.5 研究区小麦白粉病监测
采用研究区2014年05月26日遥感影像,以单个像元为基本处理单元,3个SVM监测模型为9个模型中最低,精度最高只有64.3%,无法应用到对白粉病的监测中。因此本文用利用3种特征选择算法分别结合GSSVM和GASVM模型方法得到2014年05月26日的小麦白粉病发生发布情况如图3所示。
从监测结果分布图中可以看出2种mRMR算法建立的模型监测的结果显示白粉病轻度发生,与实地调查时的严重发生偏差较大,relief算法和relief-mRMR算法建立 的 4 种 监 测 模 型 relief-GSSVM(图 3a)、relief-mRMR-GSSVM(图 3c)、relief-GASVM(图 3d)和relief-mRMR-GASVM(图3f)在空间分布上大致相同,南部发病情况比北部发病情况严重,与实际调查情况相符,发病面积占总体面积的百分比依次为44.5%、62.1%、62.4%和60.4%。图3a与其余3幅图相比发病面积较少,与实地调查的小麦白粉病严重发生存在偏差。对比图3a、3c、3d和3f可以发现,图3a和图3d的监测结果中白粉病发病区分布较零散。而小麦白粉病是由布氏白粉菌引起,该病菌具有繁殖快,传播面积广的特点,一般不会零散发生[18],因此图3a和图3d的监测结果与小麦白粉病的特点相悖,而图3c和图3f的监测结果更符合小麦白粉病发生特点,可信度更高。
图3c和图3f在大体上表现出一致性,但在细节上存在差异,观察图3c和图3f两幅局部监测结果图(分别为图3g和图3h)可以发现图3h中分为健康的区域在图3g中被分为发病。
图3h中小麦健康与发病地块之间分布比较均匀,而图3g则大多表现出整块的区域全为发病区域,只有少数地块表现出均匀分布,比较两幅局部监测结果图可以发现 通 过 relief-mRMR-GSSVM模 型 和relief-mRMR-GASVM监测的整体趋势与实际相符,但在细节部分,relief-mRMR-GASVM模型的区分能力要优于relief-mRMR-GSSVM模型,relief-mRMR-GASVM模型在局部的监测中仍适用。
结合白粉病实地调查情况和 9个监测模型的评价结果、不同白粉病监测方法验证结果以及空间分布结果可以看出,relief-mRMR算法在白粉病的监测中可以提取较优的特征集,GF-1数据结合relief-mRMR-GASVM模型在整体趋势、发病特点、局部细节上都与实际情况较为一致,能够真实地反映出小麦白粉病的发病状况,可用于日常的生产中对小麦白粉病实时监测的需求中,通过准确获取白粉病的发病状况、空间分布特征来有计划的提供防治依据,减少产量损失。
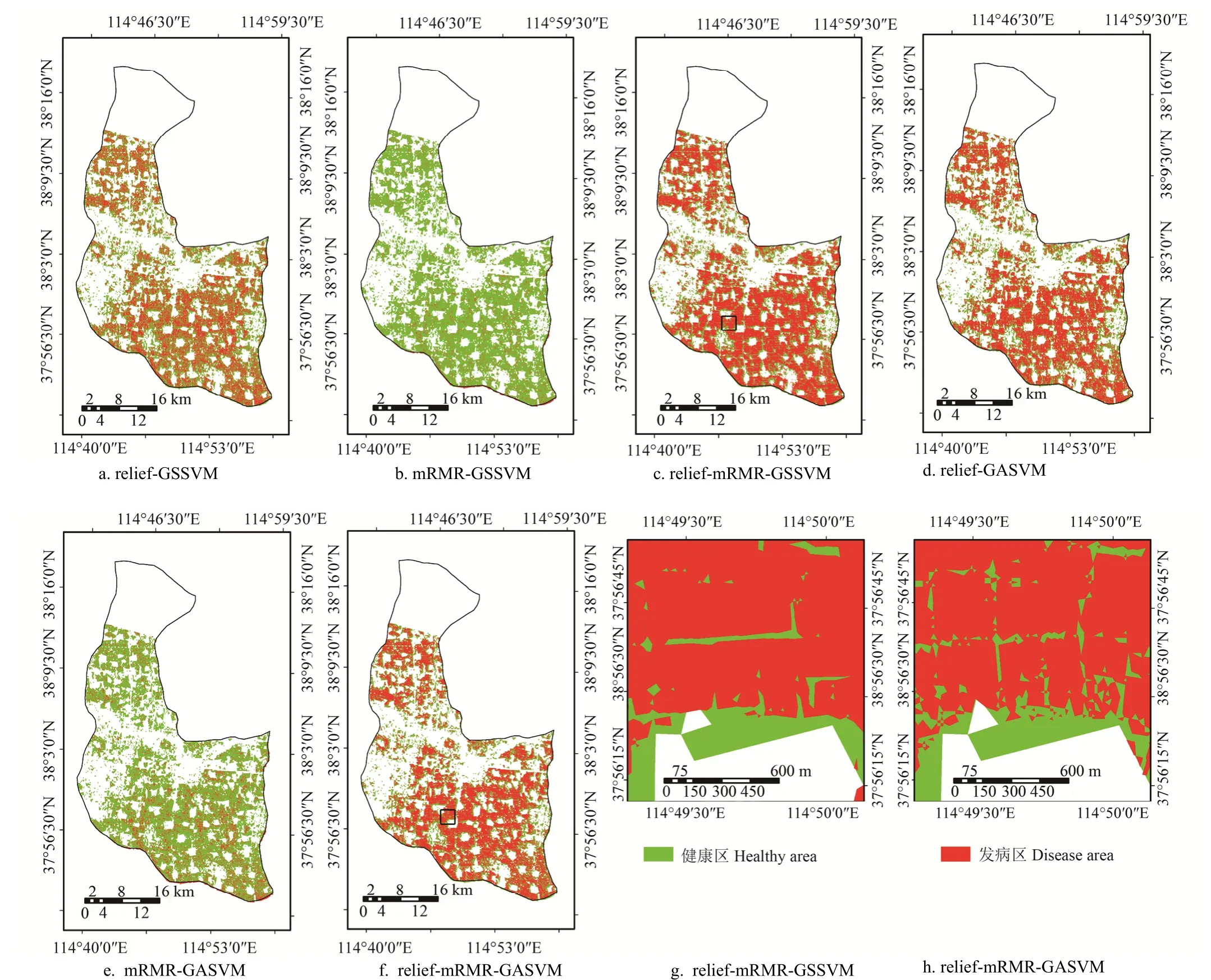
图3 小麦白粉病监测结果空间分布图Fig.3 Monitoring spatial map of wheat powdery mild
3 结 论
本文利用GF-1遥感数据建立了小麦白粉病的监测模型,通过 relief-mRMR(minimum redundancy maximum relevance)算法筛选出 3个特征变量 NIR(near-infrared reflectance)、SR(simple ratio index)和 NDVI(normalized difference vegetation index)作为模型的输入变量,与GASVM建立白粉病的监测模型,对河北藁城的小麦白粉病发生情况进行监测,并将其结果与仅通过relief算法和mRMR算法筛选后的特征与未经优化的 SVM(support vector machine)和GSSVM建立的监测模型进行对比分析,同时比较了该方法与已有的 3种小麦白粉病监测方法 AdaBoost、Pso-LSSVM(least squares support vector machine)和RF(random forest)的优越性,
1)SVM、GSSVM和GASVM 3种不同模型方法中,通过 relief-mRMR算法建立的模型精度均高于仅通过relief算法和mRMR算法建立的模型精度,说明relief和mRMR 2种算法结合,在选出与病害发生相关性大的特征的同时可有效去除特征之间的冗余性,从而获得更优的特征集。
2)relief-mRMR算法结合GASVM方法使得监测模型 的 精 度 从 relief-mRMR-SVM 的 64%和relief-mRMR-GSSVM的 78.5%提高到 85.7%,且relief-mRMR-GASVM 模型的 Kappa系数(0.714)为 9个监测模型中最高。说明relief-mRMR-GASVM方法可以提高小麦白粉病模型的监测精度,同时使得监测模型的一致性得到改善,进一步加深了模型在实际应用中的可靠性。
3)relief-mRMR-GASVM方法的监测精度较已有的3种白粉病监测方法AdaBoost、Pso-LSSVM和RF方法分别提高了 21.4、14.3和 7.1个百分点。说明本文提出的GF-1影像数据结合relief-mRMR-GASVM模型的方法较已有监测方法更适用于小麦白粉病的监测。
