基于集成注意力层卷积神经网络的汉字识别
2018-08-21武子毅刘亮亮张再跃
武子毅,刘亮亮,张再跃
(1.江苏科技大学 计算机学院,江苏 镇江 212003;2.上海对外经贸大学 统计与信息学院,上海 201620)
0 引 言
目前,卷积神经网络已成为解决复杂视觉识别问题的重要技术和方法,在手写数字识别[1]、英文字母识别[2]等方面得到了有效应用。汉字图像识别是字符识别的重要方面,由于汉字形状的特殊性,大大增加了汉字图像识别的难度。
文中概述了目前汉字识别研究的基本情况,分析并探讨了卷积神经网络在处理多分类识别问题过程中的功能性质,以及在具体汉字识别应用中存在的问题。针对相似或相近汉字“微小特征”在深度学习自动特征提取过程中可能被过滤掉而造成识别错判的问题,借鉴卷积神经网络技术,对AlexNet模型[3]的机构进行改造,通过引入注意力层(attention layer)[4],加强对汉字“微小特征”的关注与提取能力,以提高汉字识别的准确率。
1 相关工作
传统语言文字种类识别包括“特征提取”和“特征分类”两个步骤。分类器是特征分类的主要工具,常用的有K近邻[5]、支持向量机[6-7]和BP神经网络[8]等。特征提取的方法可划分为基于统计特征[9]、基于符号匹配[10]和基于纹理特征三大类别[11]。基于统计特征和基于符号匹配这两大文种识别算法都需要以准确的文本行划分和字符分割为前提,因此对图像噪声鲁棒性较差。基于纹理特征的文种识别将同一类文字图像看作同一类纹理,这样就能用纹理分类的方法来解决文种识别问题,其中,小波共生直方图的方法[12-13]在小波分解的基础上进行共生直方图的计算,通过提高特征维数,从而使识别率大大提高。
基于卷积神经网络的识别方法主要研究卷积层、池化层和全连接层对识别结果的影响。文献[14]用分段最大池化层(multi-pooling)代替最大池化层(max-pooling),该方法将池化层的滤波器分段,在每一段里动态地取若干个最大值。这种方法对汉字图像的局部变化或破损鲁棒性较好。文中采用准确率较高的小波共生直方图方法和分段最大池化层的方法作为评估基准。这两种方法在传统方法和卷积神经网络方法中汉字识别效果较好。
2 集成注意力层的卷积神经网络
为了探索选择何种模型最适合处理这类汉字图像数据集,选择了5种卷积神经网络模型,经过试验发现,使用AlexNet网络模型精确度最高,网络数较少,所以文中选择结构相对简单的AlexNet处理汉字图像数据集。
2.1 AlexNet网络模型
识别对象为文字图像,处理过程包含的参数有:输入图像的像素大小为x1×x2,滤波器的像素大小为f1×f2,卷积移动步幅为s像素,在每一边添加白边的像素大小为p,则卷积操作后图像的像素大小为x1×x2。x1和x2的关系如下:
(1)
例如Conv1,输入的图片像素大小x1=227,卷积滤波器的像素大小f=11,卷积移动步幅s=4,每一边添加白边的像素大小p=0,这样经过卷积计算后会形成像素大小为55×55的图片((227-11)/4+1=55)。本层共有96组卷积滤波器,则在本层输出的是55×55×96大小的图片。然后使用ReLUs激励函数进行映射。最后,经过步幅s=2、滤波器大小f=3的最大池化操作后,每一边添加白边的像素大小p=0,数据大小为27×27×96((55-3)/2+1=27),这样就完成了Conv1。以此类推,Conv2~Conv5需要注意的是,在Conv2中在数据周围加了p=2像素的白边,在Conv3~Conv5数据周围加了p=1像素的白边,以便在池化操作时数据大小能够被整除。
数据经过5个卷积层后与4 096个节点进行全连接,再用Tanh激励函数进行映射,最后设置将输出值减半,完成全连接层FC1。FC1和FC2的神经元个数有4 096,FC3的神经元个数为3 755,相当于训练目标的3 755个汉字类别。
表1和表2分别列出了每层配置的参数数据以及每次计算后的数据大小(Data_Size),其中每条数据都为三通道,在实际计算中需乘以3。为了便于数据显示,这里采用实际默认形式。表中Num_Filter为卷积滤波器个数,Padding为补充的白边大小,Filter_Size为卷积滤波器大小,Stride为滤波器移动的步幅,Activation为激励函数,Kernel_Size为池化滤波器大小,Kept_Prob为Dropout步骤中输出值被削减的比例。
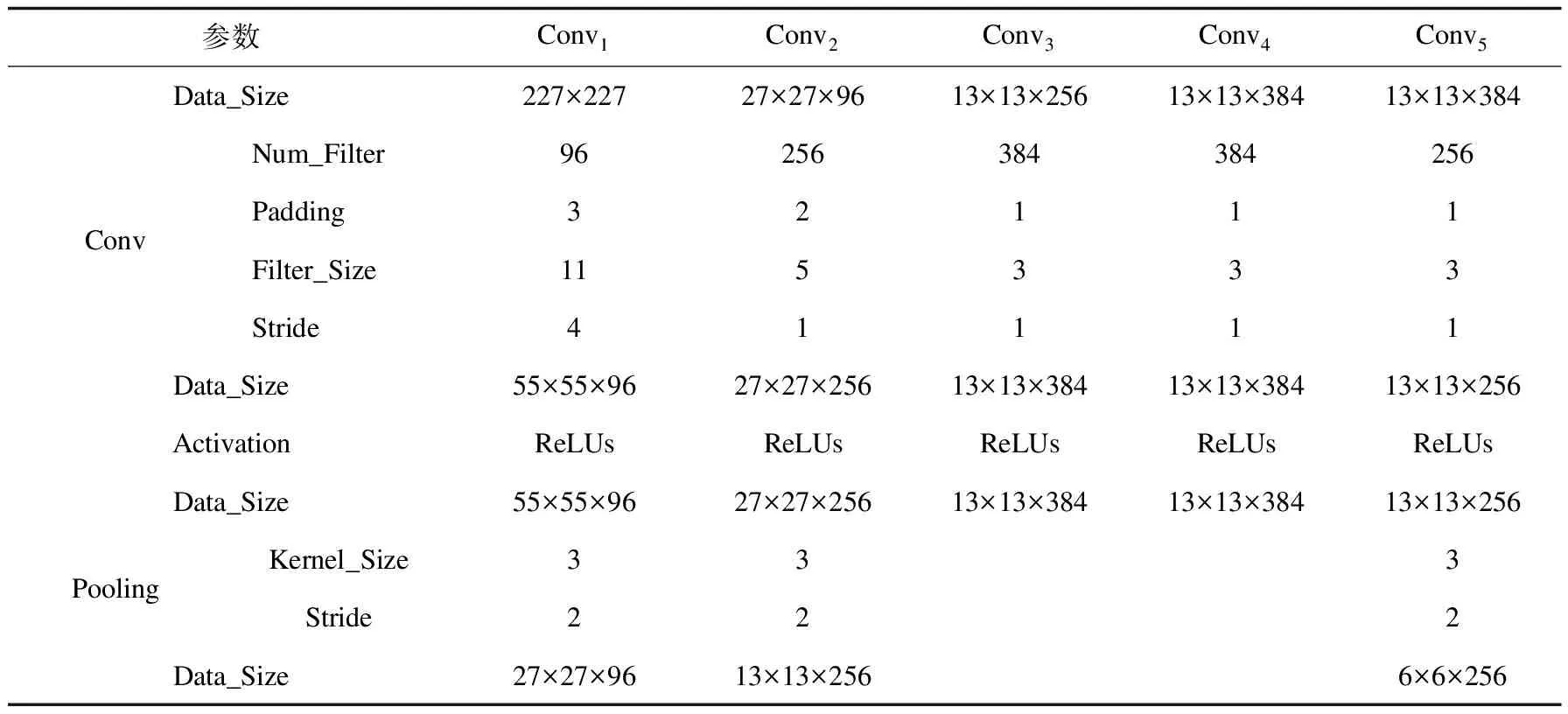
表1 Conv1~Conv5配置详细信息和数据大小

表2 FC1~FC3配置详细信息和数据大小
2.2 注意力网络
在卷积神经网络中,如果想把注意力放在图像中的某个部位,那么就可以对目标区域赋予更高的权重,达到关注该区域的目的。图1(a)为部分形相似汉字以及被圈出的“微小特征”。可以看到,汉字的“微小特征”区域大多都在汉字的上下左右以及四个斜对角八个区域。为了提高这些区域的权重,可以将汉字图像与注意力图(attention map)进行滤波处理。注意力图如图1(b)所示,图中以上下左右和斜对角八个权值为1的白色中心点向四周扩散,权值越来越小,直到变为黑色,权值为0。

图1 部分形相似汉字的“微小特征”以及注意力图

图2 注意力网络原理
虽然在滤波处理后,关注的区域得到了加强,但是没有保留原始区域,因为原始区域权值为0。所以可以将原始图片正常进行卷积操作后与滤波处理后的图片相加,这样既增强了目标区域,又保留了原始区域。注意力网络原理如图2所示。这里把图像数据x与注意力图进行滤波得到H(x),然后与通过两层卷积层计算后的数据F(x)直接相加,获得最终数据y(y=F(x)+H(x)),最后再对该数据进行后续的计算。这样就达到增强数据的“微小特征”的目的。
2.3 基于注意力层的卷积神经网络
AlexNet网络由三组卷积神经网络(Group1、Group2和Group3)和两个4 096节点的全连接层组成。Group1和Group2都包含了一个卷积层和一个池化层,Group3包含了三个卷积层和一个池化层。Conv1~Conv5是卷积层,Pooling是池化层。FC1~FC3是全连接层。
接下来把注意力层融合到AlexNet中。为了提高模型训练中对汉字图像八个区域的权重,选择在Group1和Group2相对深层的两个位置添加注意力层,将两个注意力层分别与Conv2和Conv3~Conv5并联,融合后的网络结构如图3所示。
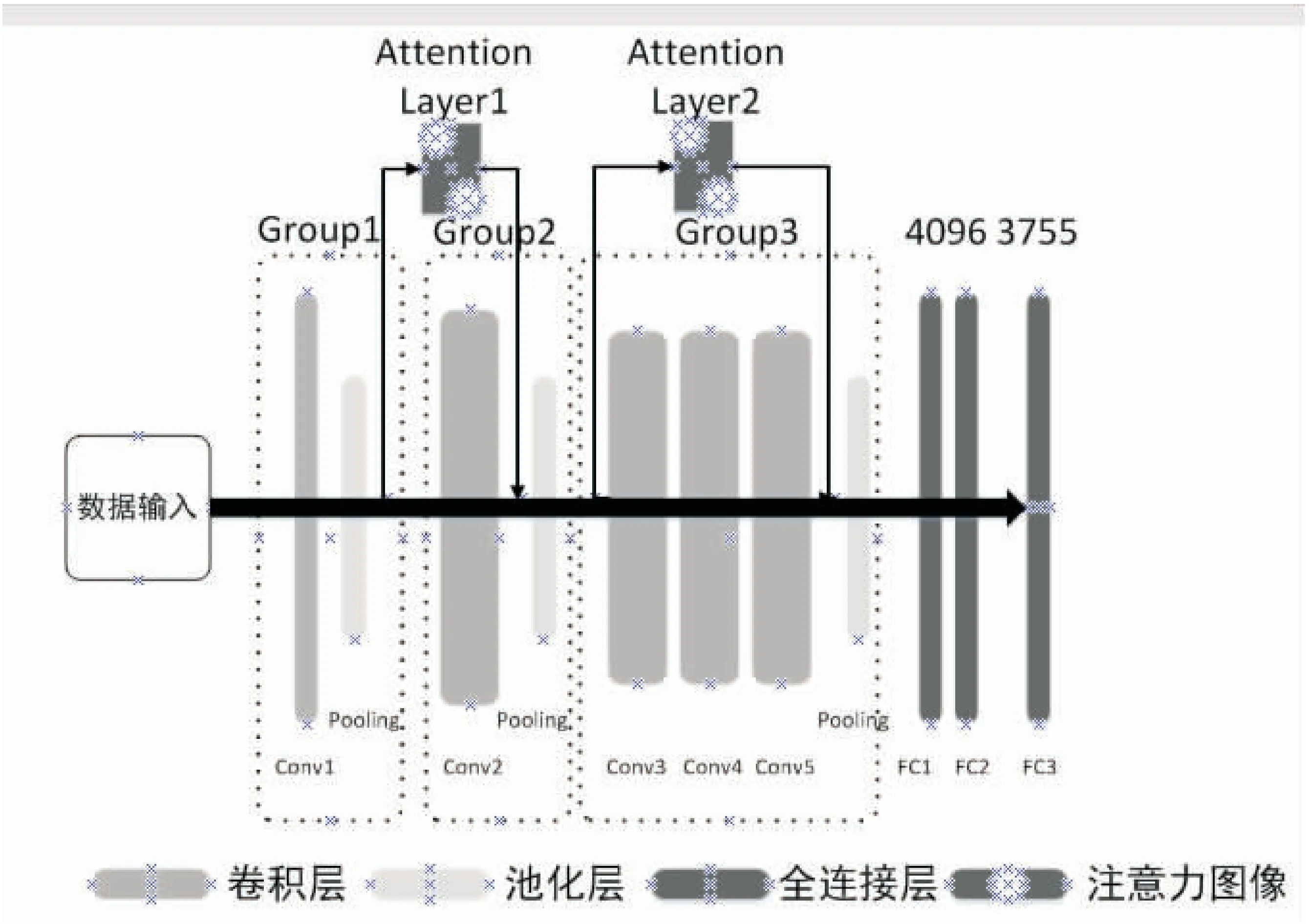
图3 AlexNet+Attention Layer网络结构
步骤如下:
(1)输入一张227×227像素大小的三通道汉字图片,经过Group1计算得到大小为27×27×96的图像数据x1。
(2)将数据x1与注意力图进行滤波,形成Attention Layer1,得到数据H1(x);然后与原本经过Conv2计算后的数据F1(x)相加得到y1(y1=F1(x)+H1(x));最后通过池化计算得到数据x2。
(3)将数据x2与注意力图进行滤波,形成Attention Layer2,得到数据H2(x);然后与原本经过Conv3~Conv5计算后的数据F2(x)相加得到y2(y2=F2(x)+H2(x));最后通过池化计算完成Group3。
(4)将Group3输出数据输入至全连接层,最后把第一步输入的图像分类至某一个汉字类别,完成模型训练和识别。
3 实 验
3.1 汉字数据集
文中使用的数据集由3 755类汉字图片组成,每一类汉字有45个样本,共计168 975个样本,每个样本数据大小为227×227。在实验中,使用90%(150 200)的图像进行训练,即每一类汉字有40个样本图像进行训练,5个样本用于测试。
3.2 实验结果与分析
使用Tensorflow[15]库来实现卷积神经网络模型。文中使用的GPU为一块NVIDIA GTX970图形处理器。实验将批量大小(batch size)设置为64,全部样本训练次数(epoch)设置为30,则迭代次数总共为79 207次,全程学习率不变,均为0.001。在模型训练的每一轮迭代中,神经网络层参数都会更新,这些参数主要是卷积滤波器的参数。按照图3的网络结构进行训练,训练结束后将模型保存,这样就可以使用该模型来识别汉字图像了。
将数据集的10%作为测试集,通过比较测试图像结果与图像标签来计算识别结果,计算平均识别率。此外,还将测试结果与评估基准进行比较,结果如表3所示。

表3 模型对比 %
从表中可以看出,基于卷积神经网络的方法比基于特征的方法效果好10%;基于注意力层的卷积神经网络相比基于分段最大池化层的卷积神经网络保留的有效信息更多;只要迭代次数足够多,卷积神经网络对于处理多分类问题的效果还是不错的。
4 结束语
文中使用AlexNet加上注意力层对3 755类汉字图片数据集进行了实验。实验结果表明:普通的卷积神经网络会丢失汉字“微小特征”,注意力层可以有效弥补这一点;卷积神经网络可以处理多分类问题,但是会增加训练难度。文中的研究可以为后续的在线识别汉字图像模型提供参考。
