基于评价分类的可信QoS服务选择方法
2018-08-21夏薪棋刘茜萍
夏薪棋,刘茜萍
(南京邮电大学 计算机学院,江苏 南京 210003)
0 引 言
随着科技的发展与网络的兴起,计算机软件的相关服务逐渐增多[1]。然而,满足相同功能需求的服务也越来越多。为了使得用户有更好的体验,一些服务商家不仅需要考虑服务本身的功能需求,还需要考虑服务的非功能需求。可信问题是当前服务选择面临的一个重要问题,不能解决可信问题,就无法从相似的服务集中选择出更好的服务。一个服务的好坏可以使用QoS(quality of service)[2-4]来衡量。历史用户给出的反馈信息可以用来计算服务的QoS,现实中这些用户反馈的可信性是难以保证的。某些用户给出的虚假好评或者恶意差评影响了QoS计算的准确性[5-7]。除此之外,用户的个人主观评价习惯对评价数据也有一定的影响。以往的研究往往认为可信的实体做出的服务评价是完全合理可用的[8-12],但实际并非如此,考虑到用户的评价习惯对评价数据的影响,可信用户给出的主观评价可能与实际情况存在一定偏离,对这些偏离评价进行甄别并修正,将可以准确有效地选择出更适合用户需求的服务。
文中提出一种基于评价分类的可信QoS服务选择方法。基于历史用户对服务的反馈评价,充分考虑用户评价习惯对评价的影响,将评价的服务属性详细分类为中立评价、宽容评价、挑剔评价、恶意评价,并进一步对可信用户的偏离评价数据进行修正,以减少用户评价习惯对服务评价的影响。这里偏离评价主要包括可信用户的宽容评价和挑剔评价。
1 相关研究
近年来,服务选择的相关研究取得了一定成果。熊润群等[13]设计了三维QoS模型,并结合层次分析法设计出了QoS偏好感知算法与副本选择算法,进而获取QoS排序。唐朝刚[14]对QoS的服务选择问题进行了研究,设计出了top-k的服务选择查询技术。
然而以上这些研究没有考虑QoS描述信息的可信性。对此,姚建华等[15]使用多种服务的非功能属性计算服务的QoS,并使用聚类方法提高服务的QoS可信性。刘昕民等[16]使用D-S证据理论计算服务的QoS可信度。杨丹榕[17]结合贝叶斯理论和粗糙集理论对QoS的属性进行了可信度评估和权重计算,并通过QoS度量模型选择出优质的服务。
这些传统的服务选择方法,多数都是基于历史用户的反馈评价剔除恶意用户,然后直接使用可信用户的评价数据进行QoS的计算,进而以QoS值的高低完成服务选择。直接将可信用户的反馈数据用来计算综合QoS具有不合理性。因为现实生活中确实存在这种情况,某些用户对服务的不同属性具有不同的评判标准,这是由他们的评价习惯造成的。有些用户或许对服务的某种属性要求很挑剔或者很宽容。总的来说,这些用户是可信的,因为他们并没有恶意的评价,而是由于个人的评价习惯不同导致评分的不合理。如果不对这些用户的评价进行详细的分类,那么直接使用剔除后所得的可信用户数据也有失公正合理性。
为了保证数据具有更好的合理性,需要充分考虑用户的评价习惯对数据的影响。对此,文中提出了一种基于评价分类的可信QoS服务选择方法,分析用户的历史评价并将其详细分类为中立评价、宽容评价、挑剔评价和恶意评价。剔除恶意用户并筛选出值得信赖的可信用户评价,并对得到的用户数据做进一步的修正处理,以削弱用户的主观个人评价习惯对QoS数据正确性的影响,从而选择出更合理更优质的服务。
2 基于用户评价分类的可信用户获取
历史用户的反馈评价是描述候选服务质量的重要依据。基于历史用户的反馈将评价详细分类,从中甄别出具有参考价值的可信用户反馈评价。
2.1 历史用户评价信息描述
一个服务应该具有多个非功能属性,历史用户在使用服务后都会对服务的各非功能属性给出具体评分值,即历史用户的反馈评价。
相关定义如下:
定义1(S,U,A,P):U表示历史用户集,U={u1,…,ui,…,um};S表示所有用户使用过的服务集合,S={s1,…,sj,…,sn};A表示服务的属性集合,A={a1,…,ak,…,al};P表示历史用户的具体评分值,P={Pi,j|Pi,j为用户ui关于服务sj的评价向量,Pi,j=
2.2 历史用户评价分类及可信用户获取
如果某个历史用户给出的反馈评价向量明显偏离该服务的总体评价向量,那么这个反馈评价向量就有可能是虚假好评或者恶意差评。考虑到用户的评价习惯对数据的影响,有的用户对某种属性是偏宽容的,那么他给的评分可能较总体评分高,相反地,用户对某种属性是偏挑剔的,那么他给的评分可能较总体评分低。这里将用户的评价分为四类:中立评价、挑剔评价、宽容评价、恶意评价,其具体计算过程如下:
首先计算每个服务的每种属性的一个具体平均评分值,即所有用户对某个服务的某种属性的评分值总和除以用户的个数之和。相关定义如下:


(1)




(2)

(3)
定义5(α,β):α表示较小阈值,β表示较大阈值,且α≥0,β≥0。
评价分类定义如表1所示。

表1 评价分类定义表
对所有属性都进行类似的处理,进而得到用户对各属性的评价类型。如果存在某个属性上的恶意评价,那么此用户的评价参考价值较小,此用户将被认定是不可信用户,因而将这些用户从历史用户集中剔除,剩余的用户便是可信用户。
然而,考虑到用户的主观评价习惯对评分值的影响,即便是可信用户,其评分也可能出现偏离的情况,需要对用户的偏离评价数据进行修正,具体方法见下节。
3 基于可信用户评价数据修正的服务选择
由于可信用户主观的评价习惯使得他们的评分值与实际客观值可能有所偏离,在使用用户评价进行服务选择之前需要修正可信用户的偏离评价数据。
3.1 修正可信用户的偏离评价
如果某个用户对服务的某种属性是偏宽容的,那么这个用户给出的评分值相对正常评分值将会偏高,这样就和服务的真实评价有所偏离,同样地,某个用户对服务的某种属性是偏挑剔的,评分值就会偏低。上一节基于恶意评价筛除了恶意用户,从而得到了可信用户集,对每一个可信用户而言,需要遍历所有评价数据并对其偏离评价数据进行修正。这里给出一个偏离度的概念,偏离度就是宽容评价或挑剔评价偏离中立评价的幅度。修正数据的目的是缩小偏离度,使得偏离评价与合理评价相接近,从而使可信用户的数据参考价值更高。偏离度定义如下:
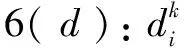

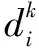
(4)
利用式1~3计算用户的评价类型,从而完成可信用户的筛选,利用式4计算出偏离评价的偏离度,这些偏离评价数据影响了服务选择质量。因此,需要修正这些偏离评价,可信用户的原始偏离评价数据在不同的情况下减去或者加上偏离度,就得到了相对合理的可信评价数据。
修正结果定义如下:
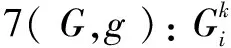
下面给出修正偏离评价的计算公式:
(5)

3.2 基于修正后评价数据的服务选择方法
基于上一节修正后的评价数据计算各服务的QoS具体值。计算历史用户对各服务的评价向量与相对应的服务基准向量之间的相似度,历史用户的评价向量与服务基准向量的相似度越小说明该用户对该服务反馈评价的参考价值越小,然后将得到的相似度以权重的形式进行量化,最后基于历史用户的反馈评价与量化后的权重计算得到各服务的QoS具体值,从而完成服务选择的目标。
相关定义如下所示:

向量间相似度的计算方法有很多种。其中,欧几里得相似方法能更好地表达用户历史评价向量与基准向量的相似程度。文中采用欧几里得相似方法来计算向量间的相似度。计算历史用户ui的评价向量Pi,j与Cj的相似度,计算公式如下:
(6)
计算出用户评价向量Pi,j与基准向量Cj的相似度后,将相似度转换成参考权重,然后再计算候选服务最终QoS评分值。计算候选服务的QoS评分值qosi的公式如下:

(7)
最后,计算出每个服务的QoS值,最大QoS值对应的服务则是最适合目标用户的服务。具体算法如下所示:
算法:基于用户评价分类的可信QoS服务选择方法。
输入:sj,ak,pi,j,k,α
输出:QoS(服务综合质量)值最高的服务s
1.for eachsj
2.for eachak

4.for eachak

6.Cj=getAllAttr(Ek)
7.for eachuj
8.for eachak



12.for eachak


15.similarity(Ri,j,Cj)//相似度计算并做权重量化
16.for eachsj
17.calculateQos(sj)//服务选择
18.s=sort(sj)
4 实例分析
以餐厅服务类为例,这里有10个候选服务以及10个消费过这些服务的用户,选取服务态度、价格、上餐速度三个指标作为服务的属性,反馈评价向量表如表2所示。

表2 反馈评价信息表
4.1 历史用户评价分类及恶意用户剔除
Step1:利用式1计算各服务属性的平均值,得到属性的均值向量,这里以属性1为例:
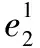


4.2 修正偏离评价数据
只需要修正宽容评价以及挑剔评价的数据。按上节分类结果,需要修正用户1的属性3,用户3的属性1,用户4的属性2,用户7的属性1。利用式3求出偏离度d(保留一位有效数字)。
用户1属性3:

用户3属性1:


4.3 基于修正数据的服务选择方法
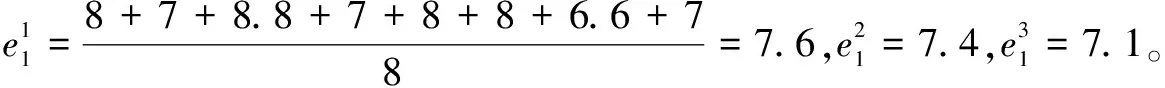

5 结束语
文中提出了基于评价分类的可信QoS服务选择的方法,充分考虑了用户个人评价习惯对服务评价的影响。首先基于历史用户对服务的反馈评价,将用户的评价详细分类。然后在评价分类的基础上剔除恶意用户,并进一步修正可信用户的非中立评价数据。最后在这些修正后数据的基础上,完成服务选择。通过实例验证表明,基于用户评价分类的可信QoS服务选择方法可以选择出优质的服务。
目前没有考虑用户对服务属性的喜好权重,今后的研究方向将进一步探讨如何结合机器学习来确定用户对服务属性的个性化权重。
