基于Spark的高维数据相似性连接
2018-08-21成小海
成小海
(天津工业大学 计算机科学与软件学院,天津 300387)
0 引 言
高维数据相似性连接不仅可以用于分类,而且还可以用于预测,在文本分类、聚类分析、预测分析、模式识别、图像处理等领域应用广泛。但高维数据相似性连接仍是一个非常具有挑战性的工作,主要有以下两个原因。首先,数据集的规模非常大(数百万或数十亿的对象);其次,数据集的维数足够高(数千或数万)。因此不可能直接对数据集进行操作,必须借助有效的方法来降低数据集的维数,从而进行数据集间的运算[1],其中用的最多的就是结合Hadoop框架[2-9]进行分布式运算。
近年来,有学者不断地对高维数据的相似性连接进行了研究和优化。例如,戴健等[7]整合MapReduce框架,提出了分布式网格概略化KNN joins(DSGMP-J)和基于MapReduce的voronoi diagram下的KNN joins(VDMP-J);马友忠等[8]结合Hadoop集群的分布式特性和SAX的降维技术,提出了向量随机生成id的方式进行SAX转换,虽然可以起到分布式计算的效果,但在运算过程中由于复制多份数据和相同id向量的重复计算导致内存消耗较大;刘雪莉等[10]提出了实体数据库上相似性连接算法ES-joins,用于解决字符串模糊匹配的相似性连接问题;刘艳等[11]利用Δ-tree进行高维数据相似连接;周健雯等[12]使用R*树的自相似性连接。
由于Spark具有运算速度快、易用性好和通用性强等优点,并且可以高效地处理大规模数据集,因此文中采用基于Spark的相似性连接,对原有基于MapReduce的方法进行改进,优化其中的计算步骤,同时结合Spark强大的RDD算子,以提高计算速度。
1 相关工作及背景知识
1.1 Spark框架
Spark诞生于加州大学伯克利分校AMP实验室,是一个基于大数据的分布式并行计算框架。由于其先进的设计理念,从2013年成为Apache孵化项目后,先后扩展了Spark SQL、Spark Streaming、Mllib、GraphX和SparkR等组件,逐渐成为大数据处理一站式解决平台。Spark框架提供了多种资源调度管理,通过内存计算、有向无环图等机制保证分布式的快速迭代计算,同时引入了RDD的抽象保证数据的高容错性。
RDD是一个分布式的内存抽象概念和只读分区记录的集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据父子RDD中的继承关系重新进行计算。Spark的创建、转换、控制和行为等操作都是来自对RDD的操作。
1.2 与MapReduce的比较
Spark是对MapReduce分布式大数据处理的借鉴,并对其进行了内存框架优化,使其具有更强的数据处理能力。
(1)Spark将中间过程放进内存,迭代效率明显提高。而MapReduce将中间计算结果保存在磁盘中,如果多个Reduce将会严重影响程序的运行速度。Spark支持有向无环图的分布式计算,中间运算结果保存在内存中,使其整体效率明显提升。
(2)Spark容错性高。Spark使用了RDD操作,可以在计算时通过CheckPoint实现容错。
(3)Spark在Shuffle时不是所有情况都进行排序,而MapReduce在此阶段需要花费大量时间来排序。
(4)Spark更加通用。Spark提供的数据操作类型有很多种,一般较为通用的是转换操作和行动操作两种类型。而Hadoop只提供Map和Reduce两种操作。
因此,为了让集群高效工作,可以尝试使用Spark框架来处理高维相似性连接问题。
结合SAX技术来降低向量的维数,并通过计算SAX表示之间的距离来提高过滤效果。这样可以减少候选对,节省计算成本。
2 问题定义
2.1 高维向量的PAA表示
PAA[13]是一种维数降低技术,广泛应用于时间序列处理和轨迹相关问题研究。它就是将原始高维数据等间距分割为较低的维数,利用定义2给出的距离计算公式计算出原始向量的近似距离。文中使用的向量是序列无关向量,维度的顺序不会影响欧几里得距离的计算结果。在需要的时候,可以重新排列向量的维度顺序,然后用分段聚合近似表示高维向量。
2.2 高维向量的SAX表示
SAX[8,14-16]也是一种维数降低技术,其主要是先将原数据规格化,使其服从高斯分布,然后离散化并用PAA表示,最后转化为字符串。该方法具体的变换步骤举例如下:
(1)将原始时间序列R={R1,R2,…,Rn}规格化为均值为0、标准差为1的标准序列;
(2)将其离散化为x个相等大小的范围,每个范围内的数据都用定义2中的PAA表示;
(3)通过查表1确定其所在的区间,并将每个区间用不同符号编号,表示形式为R={A1i,A2i,…,Axi}。

表1 从3-8等分区划分的高斯分布查找表
图1为原始向量R用SAX表示后的模型。

图1 时间序列R的SAX表示
定义1:高维相似性连接。给定两个n维数据集R和S,假设R和S中的所有点都在n维空间中,已知距离阈值为ε,则在R和S上的相似性度量是计算所有点对组成的集合(Ri,Si)使得DE(Ri,Si)≤ε,其中Ri∈R,Si∈S和DE代表欧几里得距离。如果将R和S看作同一数据集,则进行自相似性连接。文中也主要使用自相似性连接进行实验。
定义2:PAA表示。给定一个n维向量R,将其维数进行等分,令N为等分后的维度,RN1,RN2,…,RNN是N个维度表示,其中有关系Rn=RN1∪RN2∪…∪RNN和Ri∪Rj=∅。则向量R用PAA表示为Rn=(RN1,RN2,…,RNN)。
定义3:聚合度λ。假定R的维数为n,将其用PAA表示后的维度为N,则聚合度λ就定义为λ=n/N。
文中首先将原始高维向量进行规格化。假设原始向量为R,其中均值为μ,标准差为σ,则规格化公式为:
Ri'=(Ri-μ)/σ
(1)
给定两个向量R和S,它们的欧几里得距离为:
(2)
它们的PAA表示后的距离可以定义为:
(3)
在文献[15]中已经证明,PAA表示DP的距离是原始欧几里得距离DE的下限,也就是说:
(4)
给定两个向量R和S以及它们的SAX表示Rs和Ss,可以定义新距离:
(5)
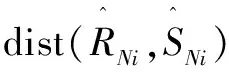
容易证明,SAX表示(MINDIST)之间的距离是PAA表示DP之间的距离的下限,并且DP是欧几里得距离DE的下界;根据传递性,MINDIST是欧氏距离的下边界近似:
(6)
3 高维相似性连接在Spark上的实现
高维相似性连接是文中讨论的主要问题。看似简单,但由于维数较大和数据量较多,导致计算成本呈指数倍增加。如何用较短的时间和较小的代价得到正确的结果是文中进行研究的目的。以下是高维相似性连接在Spark集群上实现的详细过程。
具体流程如图2所示。

图2 高维数据相似性连接在Spark上的流程
(1)数据预处理。主要通过map操作对数据进行规格化处理,使每一行数据都表示为均值为0、标准差为1的标准序列。首先通过集群将分布式读取到的每一行数据计算其均值μ和标准差σ,然后根据规格化公式,使其标准化,最后返回标准化后数据。
(2)生成SAX键值对。将预处理中计算出的标准序列结合预先设定的聚合度λ,表示出相应的PAA集合。然后将生成的数据集用SAX表示,最后将生成的集合通过键值对返回。具体过程见算法1。
(3)将具有相同SAX表示的键值对聚合。该步骤主要是通过RDD算子的groupByKey函数实现。
(4)进行笛卡尔积运算。将上一步中SAX表示后的RDD数据集通过cartesian函数实现自连接,返回通过Key-value表示后的SAX对。这个步骤保证数据集中每两个SAX表示后的数据集可以碰面一次。
(5)精化候选向量对。该步骤是计算出满足阈值的相似连接对。主要通过map函数比较上一步中返回的键值对中满足阈值的key-value对,然后计算value中符合条件的原始数据对之间的距离。
算法1:Generate key-value pairs
line=>{
1.numbs<-line.substring(0,line.length-1).split(“ ”)
2.for i<- 0 until numbs.length do
3.numi <- numbs(i).toDouble
4.sum += numi
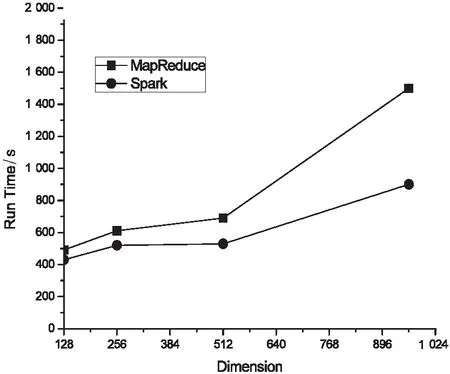
5.if k 6.if i 7.k=k+1 8.else 9.// Express by piecewise aggregate approximation 10.pp=sum/k 11.sax+=Util.getSax(pp) 12.else 13.pp=sum/k 14.sax+=Util.getSax(pp) 15.sum=0;k=1 16.//return key-value pairs 17.(sax, f.toList) } 该实验在hadoop2.6.1集群的基础上部署了Spark1.6.1,程序用Scala编写,编译器为IDEA2016。这个集群包含10个节点,每个节点的配置如下:核数为4,内存6 GB,磁盘500 GB,操作系统为Linux CentOS release 6.2(Final)。其中1个为Master节点,其余9个为Worker节点,实验中使用的数据是从HDFS中读取并将计算结果写入HDFS中。 使用的数据集来自文献[13],选用了其中的部分数据。其中256维和512维数据集通过960维数据生成,各维度向量均采用20万条数据进行测试。 分别在Spark和Hadoop平台上测试了相同数据集在不同条件约束下的运行时间。 为了验证改进算法的有效性,分别从三个角度进行了测试,即维数改变对实验结果的影响、聚合度λ改变对实验结果的影响和阈值ε改变对实验结果的影响。所有实验都是基于相同硬件配置,对原有Hadoop集群和优化后Spark集群的运行时间的比较。 首先,比较Hadoop平台和Spark平台在设置默认聚合度λ和阈值ε的前提下,只改变维度大小对所需时间的影响情况,其中设置λ为16,ε为0.1。实验结果如图3所示。 由图3可以看出,两种平台对相同数据集维度的执行时间是不同的。基于Spark平台的运行时间更短,与原有基于Hadoop平台的算法相比平均可缩短10%~20%。并且数据维度越高,优势越明显。 其次,分别改变聚合度λ和阈值ε的设定参数,分别测试对实验运行时间的影响情况,其中用到的数据集维度默认为128维。改变聚合度λ可以改变生成分段聚合近似数据集的维数,从而影响符号聚合近似表示数据集的生成维数。改变阈值ε可以控制计算相似度的多少,从而影响所需的计算时间。实验结果如图4和图5所示。 图3 不同维度两种框架运行时间对比 图4 两种框架在不同聚合度λ下的运行时间对比 图5 两种框架在不同阈值ε下的运行时间对比 由图4可以看出,虽然聚合度越大,运行时间越小,但当聚合度增加到一定值的时候,会看到运行时间反向增加。这是因为在进行实际向量间运算时,由于内部向量维数较大,增加了运算成本。但在同等条件下,Spark计算平台的时间减小更多,运行效率更高。 由图5可以看出,改变阈值ε对实验结果的运行时间有一定影响。阈值越大,花费的时间越多,但基于Spark的优化速度还是有明显的优势。 随着数据量规模的增加,相似性计算成本也将随之变大。单独使用一台机器已经无法满足相似性计算的性能、时间等各方面的要求。提高高维数据间的相似性连接效率是必须面对的课题。文中主要针对高维数据集相似性分类算法进行了优化和改进,使用SAX方法对数据集进行裁剪,该方法减少了数据之间不必要的距离计算时间。结合现有大数据框架分布式并行计算的特点,可以很好地提高高维数据相似性连接效率。通过实验发现,使用Spark框架的高维数据集相似性连接算法具有显著的性能优势。4 实 验
4.1 实验配置
4.2 实验结果分析


5 结束语
