基于无锁数据结构的FIFO队列算法
2018-08-17俊昌
俊昌, ,
(1.南京邮电大学 计算机学院,南京 210023; 2.江苏省大数据安全与智能处理重点实验室,南京 210023)
0 概述
近年来,随着多核处理器的广泛应用,高速应用程序的并行化飞速发展[1-4]。其中一种可行的并行化方法为流水线并行化,即多核处理器中的一个处理器核心完成较大任务中的第一阶段子任务,然后将该任务传递给另一个核心,该核心负责完成下一阶段的子任务处理。
由于现代商用多核处理器中普遍缺乏硬件支持的核间通信机制[5],因此当前研究大多采用基于软件实现的无锁队列[1-2,6-7]作为流水线的核间通信机制。然而,现有无锁队列算法在设计时均假设数据的到达速率处于稳定状态,如果输入数据到达速率波动较大,队列将频繁地趋于空或趋于满,从而导致无锁队列性能急剧下降。因此,在真实应用场景中,采用流水线并行技术的软件性能往往急剧下降。
针对数据到达速率不稳定的实际应用场景,本文提出一种新的无锁队列TinyQueue。当数据到达速率较低时,自适应地减小队列大小,以减少内存占用;而当数据到达速率较高时,则自适应地增加队列大小,以避免数据丢失。
1 相关工作
无锁队列被广泛地应用于多线程程序中,并且也有大量关于并发无锁队列的研究[8-11],其中大部分研究都集中在多生产者多消费者队列。然而,由于需要避免ABA问题,因此这些无锁队列性能都不甚理想。
作为一种特殊情况,单生产者单消费者队列是实现高速核间通信很好的解决方案[1-2,6-7,12],因为它从根本上避免了ABA问题。此外,这些队列的实现通常采用批处理来利用CPU高速缓存提高队列的吞吐量。Lynx[13]是一个SPSC队列,其降低了入队操作和出队操作的检查开销。但Lynx的主要设计目标是增加队列的吞吐量,相比之下,TinyQueue更适用于实际应用场景中数据到达速率波动较大的情况。
另一种通信的方法是基于硬件队列[14-15],它们从硬件层面上提供入队操作和出队操作的指令,以减少基于软件队列的开销。然而,因为硬件队列的状态必须通过上下文切换来保留,所以需要对处理器和操作系统进行修改。目前它们也主要存在于仿真器中,对于商用处理器而言还不支持这种功能。
2 TinyQueue基础算法
TinyQueue基于以下基础算法(算法1和算法2),其中整个队列是一个无限数组,使用head和tail来标识包含有效数据的部分。最初,每个单元格data[i]为空,初始值为ELEMENT_ZERO。
算法1基础算法入队操作
变量:value (将被插入队列的数据)
1.if(data[head]!= ELEMENT_ZERO ) {
2.return BUFFER_ FULL;
3.}
4.data[head]= value;
5.head ++;
6.if(head > QUEUE_MAX_SIZE ) {
7.head = 0;
8.}
9.return SUCCESS
算法2基础算法出队操作
1.if(data[tail] == ELEMENT_ZERO ) {
2.return BUFFER_EMPTY;
3.}
4.temp = data[tail];
5.data[tail] = ELEMENT_ZERO;
6.tail ++;
7.if(tail > QUEUE_MAX_SIZE) {
8.tail = 0;
9.}
10.return temp;
算法1是入队操作的伪代码。入队操作首先读取head指向的单元格的值(第1行)来检查队列是否已满。如果该值等于ELEMENT_ZERO,即该单元格不包含有用的数据,则可以插入数据。此时若该单元格已经准备好接收数据,入队线程会将数据插入到该单元格中(第4行)且head递增。若head超出了队列长度,则将head置为0(第6行~第8行)。
算法2是出队操作的伪代码。出队操作首先读取tail指向的单元格的值并与ELEMENT_ZERO进行比较,检查队列是否为空(第1行)。如果tail指向的单元格的值等于ELEMENT_ZERO,表示数据不能出队,返回BUFFER_EMPTY。否则,出队操作读取tail指向的单元格的值(第4行),然后将ELEMENT_ZERO写入该单元格中,表示数据成功出队(第5行)且tail递增,如果tail的大小超出了队列长度,则将tail置为0(第7行~第9行)。
值得注意的是,该基础算法仅适用于单生产者单消费者循环队列,所以,即使在没有Compare-and-Swap(CAS)原语保护的情况下,将数据插入head指向的单元格中也是安全的。
3 TinyQueue核心算法
TinyQueue基于算法1和算法2,其设计思想如图1所示。当数据到达速率较低时,队列趋于空,如果此时生产者位于消费者后面且两者都不会访问队列的后半部分,TinyQueue会自适应地将队列大小减半,以减少其内存占用,提高缓存命中率;当数据到达速率较高时,队列趋于满,如果此时生产者位于消费者前面,TinyQueue会自适应地将队列大小增加一倍,以避免数据丢失。

图1 TinyQueue算法原理
3.1 数据结构和全局变量
算法3是TinyQueue的主要数据结构。每个队列都会创建一个TinyQueue实例,其中:data是指向预分配的循环数组的指针;traffic是一个有符号整数,用于计算队列full/empty单元格数,每当入队操作因为队列满失败时,traffic减1,每当出队操作因队列空失败时,traffic加1。因此,traffic的大小可以反映数据到达频率的波动情况,即可以用它来决定是否需要增加或减小队列的大小;变量size用来表示队列的大小,TinyQueue会预先分配一个MAX_SIZE大小的数组,其中MAX_SIZE等于100 000,但TinyQueue会根据traffic自动选择预分配数组的第一部分;变量head和tail分别指向入队线程将要插入数据的单元格和出队线程将要提取数据的单元格。值得注意的是,要减小队列大小时,变量head和size必须同时更新,所以将其封装在结构体cas_info中。由于每个变量长度都是32位,因此cas_info是一个64位的字,在64位对齐的服务器上,其更新操作是原子的。
算法3TinyQueue数据结构
1.struct cas info {
2.head:Indicator of enqueue (32-bits integer);
3.size:Size of the cyclic array (32-bits integer);
4.};
5.struct tinyqueue {
6.info:instance of struct cas_info;
7.//缓存行(cache line)对齐
8.tail:Indicator of dequeue (32-bits integer);
9.//缓存行(cache line)对齐
10.traffic:Statistical counter of empty and full cases;
11.//缓存行(cache line)对齐
12.data:pointer to cyclic array;
13.};
3.2 TinyQueue入队操作
TinyQueue入队操作(算法4)基于算法1。入队操作首先检查队列是否已满(第3行)。如果队列已满,则traffic加1(第4行)并返回BUFFER_FULL;否则,入队操作将head赋值给局部变量temp(第7行)且head递增。如果head大于或等于size(第9行),表示head指向TinyQueue循环数组的尾部,入队操作将比较traffic与预定义阈值ENLARGE_THRESHOLD的大小来判断是否需要增加队列的大小(第10行)。若traffic较大,入队操作将队列大小增加1倍即变量size乘以2(第11行),然后将traffic置为0;若traffic较小,则说明不需要调整队列大小,入队操作将head置为0,使其指向队列的第一个单元格(第15行),然后保存数据并返回SUCCESS。
算法4TinyQueue入队操作
变量:value (将被插入队列的数据)
1.//局部变量
2.temp:local variable to buffer value of info.head
3.if(data[head] != ELEMENT_ZERO ) {
4.traffic++;
5.return BUFFER_FULL;
6.}
7.temp = info.head;
8.info.head ++;
9.if(info.head > info.size ) {
10.if( traffic > ENLARGE_THRESHOLD ) {
11.info.size = info.size * 2;
12.traffic = 0;
13.}
14.else {
15.info.head = 0;
16.}
17.}
18.data[temp] = value;
19.return SUCCESS;
3.3 TinyQueue出队操作
TinyQueue出队操作(算法5)基于算法2实现。出队操作首先检查队列是否为空(第5行)。如果队列为空,traffic减1并返回EMPTY(第6行);如果队列不为空,出队操作将tail赋值给局部变量temp(第9行),tail递增(第10行)。若tail等于size(第11行),则说明tail指向TinyQueue循环数组的尾部,出队操作将比较traffic与预定义阈值SHRINK_THRESHOLD的大小来判断是否需要减小队列大小(第14行)。SHRINK_THRESHOLD是一个负整数(例如-50),用来表示队列EMPTY的情况。若traffic较小,则出队操作将局部变量size除以2(第19行)使队列大小减半,然后更新全局共享变量size(第25行),强制入队操作和出队操作使用新的队列大小,然而,减小队列大小仍然存在一些易错点;若traffic的值较大,则说明不需要调整队列的大小,出队操作将tail置为0,使其指向队列的第一个单元格。最后,出队操作从单元格中提取数据(第37行),将ELEMENT_ZERO写入单元格中(第38行)并返回。
算法5TinyQueue出队操作
1.//局部变量
2.temp:local variable to buffer value of tail
3.temp_value:local variable to buffer value of data pointed by tail
4.info_tmp,info_tmp_new:local instances of structure info
5.if(data[tail] == ELEMENT ZERO ) {
6.traffic--;
7.return BUFFER_EMPTY;
8.}
9.temp = tail;
10.tail++;
11.if(tail >= info.size ) {
12.count = 0;
13.tag1;
14.if(traffic <= SHRINK_THRESHOLD) {
15.info_tmp = info_tmp_new = info;//原子的读取
16.if(count LOOP THRESHOLD ) {
17.goto 34;
18.}
19.if(info_tmp.head <= info_tmp.size / 2 ) {
20.info_tmp_new.size /= 2;
21.}
22.else {
23.goto 34;
24.}
25.if(CAS(&info,info_tmp,info_tmp_new)) {
26.traffic = 0;
27.goto 34;
28.}
29.else {
30.count++;
31.goto 13;
32.}
33.}
34.tag2;
35.tail = 0;
36.}
37.temp_value = data[temp];
38.data[temp] = ELEMENT_ZERO;
39.return temp_value;
3.4 TinyQueue增加队列大小操作
由算法4和算法5可知,入队操作和出队操作每次都需要先读取size的值来检查它们是否到达TinyQueue循环数组的尾部。因此,TinyQueue增加队列大小的基本思路是:如果size乘以2,那么入队操作和出队操作可以使用的循环数组的大小也会增加1倍。但是在算法设计中应保证其正确性和无锁性。图2展示了增加队列大小时可能发生的2种情况:
1)生产者在消费者后面(图2标为不安全)。在这种情况下,通过改变size的值来改变队列的大小是不安全的。因为消费者线程会读取新的size,然后使用未插入数据的单元格,进而产生错误。
2)生产者在消费者前面(图2标为安全)。在这种情况下,当生产者到达当前循环数组的尾部时,生产者通过改变size来增加队列大小并使用新分配的单元格是安全的。因为在生产者向新的单元格插入数据前,消费者不会超过生产者使用新分配的单元格。针对此种情况的具体实现在算法4中已给出(第9行~第17行)。

图2 增加队列大小的情况
3.5 TinyQueue减小队列大小操作
由于TinyQueue是一个高速无锁队列,因此很难通过减小size来减小队列大小。图3展示了收缩队列时可能遇到的2种情况:
1)生产者位于消费者前面(图3标为不安全)。在这种情况下减小队列大小是不安全的。因为生产者可能会将数据插入到TinyQueue不会使用的队列后半部分。
2)生产者位于消费者之后(图3标为安全)。在这种情况下,当消费者到达队列尾部时,如果生产者位于队列前半部分,消费者通过改变size来减小队列大小是安全的,但减小size和检查生产者是否在队列前半部分必须是同时的原子操作。为了实现这一点,本文将变量size和head封装为一个64位结构体(算法3中的cas_info),其可以通过CAS指令原子的更新。因此,本文做了一个符合现实的假设,即TinyQueue队列大小最大不超过232。但当消费者尝试减小队列大小时,若生产者一直位于队列前半部分,会使消费者一直不断尝试减小队列大小。为了避免这种潜在的活锁问题,本文设置了一个阈值LOOP_THREASHOLD,当消费者尝试次数大于LOOP_THREASHOLD时,消费者就会放弃。

图3 减小队列大小的情况
在算法5中,出队操作首先读取结构体info(第15行),然后检查其是否已经多次尝试减小队列大小。如果尝试次数已经大于LOOP_THREASHOLD,那么将会放弃出队(第16行)以避免活锁问题。否则,检查head是否小于队列大小的一半(第19行)来判断生产者是否位于队列前半部分。如果生产者位于队列前半部分,入队操作引入新的变量info_tmp_new,并将info_tmp_new.size的值减半(第20行)。否则,减小队列大小和出队操作都是不安全的。如果入队操作可以减小队列大小,那么它将尝试使用CAS指令来更新size(第25行),从而保证以下2个操作都是原子的:1)确保生产者没有移动到将要移除的数组的下半部分;2)size减半。如果CAS指令成功,则出列操作将traffic置为0并返回(第26行)。否则,count递增,并返回到开始位置再次尝试(第30行)。
4 性能评估
本节将会对TinyQueue的性能与现有的最佳解决方案FastForward、MCRingBuffer和B-Queue的性能进行对比。
4.1 实验设置
在Dell R730服务器上进行性能评估。该服务器配有2个Intel Xeon E5-2609处理器,每个处理器包含8个CPU内核,最高频率可达1.7 GHz。每个CPU内核有32 KB的一级数据缓存,32 KB的一级指令缓存和256 KB的二级缓存。同一处理器上的8个CPU内核共享20 MB的三级缓存。2个处理器间通过2条6.4 GT/s的QPI链路相连。该服务器使用128 GB DDR4内存,运行64位的Ubuntu 16.04,其内核版本为Linux kernel version 4.4.0。TinyQueue使用GCC 5.4.0编译。
实验中,生产者将1013条数据插入到队列中,消费者将按顺序读取这些数据。每个线程都将绑定到一个专用的CPU上,并且生产者线程和消费者线程分别运行在不同的CPU上。为了获取入队操作和出队操作的执行时间,使用X86中基于硬件的时间戳计数器来记录RDTSC寄存器执行1013次入队操作和出队操作所需的CPU周期。单个入队或出队操作的时间可通过总CPU周期数除以1013减去工作负载时间求得。值得注意的是,读取RDTSC寄存器并不是一个序列化指令,这意味着总CPU周期数会存在一些偏差。尽管如此,因为总CPU周期数需要除以1013,所以笔者认为单个入队操作或出队操作的时间偏差可忽略不计。对于其他的统计信息(如缓存未命中率),本文使用Linux Perf 获得。每条数据通过30次实验获得。
4.2 理想平台性能测试
在理想测试平台上对4种无锁队列进行了性能测试。在实验中,生产者线程执行while循环,并且在每次迭代中都会尽可能快地将数据插入队列中。当队列满时,生产者线程将休眠1 μs避免和消费者线程冲突。队列大小设置为2 048。
表1列出了在同一CPU(2个线程运行在同一CPU上)和跨CPU(2个线程运行在不同的CPU上)每个操作所需的CPU周期。实验中使用Perf分析无锁队列的缓存行为(选择一级数据缓存命中率进行分析)。

表1 理想测试平台上的最高性能
表1的数据是4种队列在理想测试台上达到的最佳性能,每个入队或出队操作最少只需要十几个CPU周期。为了进一步研究不同的无锁队列在理想测试平台上的性能,本文统计了队列的缓存行为。一级缓存缺失率一列数据表明4种无锁队列都具有较高的一级缓存命中率。造成这种情况的原因在于在理想测试平台上,无锁队列工作集很小,几乎所有的内存访问都可以通过一级缓存进行。
然而,在真正的应用程序中,无锁队列的工作集通常会很大,数据传入速率也会大幅波动。在这种情况下,无锁队列的工作集就不能全都保存在一级缓存中,从而会导致容量缓存未命中和一致性缓存未命中。例如,对于本文使用的E5-2609处理器,一次一级缓存命中需要2个CPU周期,一次二级缓存命中需要10个CPU周期,一次三级缓存命中需要40个CPU周期,一次存储区访问则需要200个CPU周期。显然,单独的三级缓存命中会妨碍无锁队列实现最高性能。也就是说,在理想测试平台上性能优异的无锁队列在实际应用中的性能可能会有所下降。这一点笔者将在下文中进行论述。
4.3 真实平台性能测试
为了评估TinyQueue在实际应用中处理传入数据突发性的能力,在真实测试平台上对其进行了性能测试。在该测试平台中,用户每次从队列中检索一条数据并等待85个CPU周期(一条10 Gb/s的链路处理一个数据包的时间)来模拟工作负载。为了模拟实际应用中的突发事件,生产者线程在每次迭代中都会执行以下操作:1)休眠一段时间(处理单条数据的时间乘以突发数据的大小)以模拟批处理过程中网络设备中断;2)尽可能快地插入数据。
图4显示了入队或出队操作所需的平均CPU周期数。可以看出,当突发数据较小时(例如小于2 048),不同的无锁队列的性能是相似的。但是随着数据大小的增加,FastForward、MCRingBuffer和BQueue的性能会急剧下降,但TinyQueue的性能几乎不变。
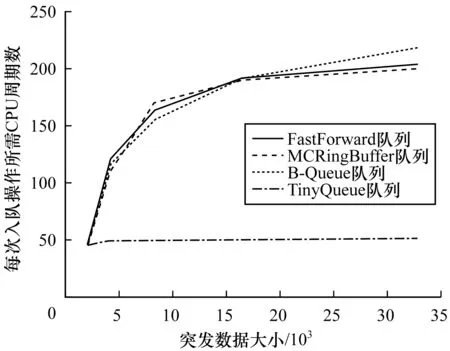
图4 真实平台上不同无锁队列的性能表现
为探究TinyQueue在真实测试平台中表现更好的原因,将突发数据的大小设置为4 096。表2列出了不同无锁队列的性能。由同一CPU列和跨CPU列的数据可知,TinyQueue的性能明显优于其他3种队列。其中最小长度列和最大长度列的数据分别表示系统运行时队列的最小长度和最大长度(这里只列出了TinyQueue的队列长度,因为其他队列不能随时改变它们的队列大小)。由实验数据可知,当数据到达速率较高时,TinyQueue可以将队列增加到65 536个单元,以处理数据的突发性,而当数据到达速率较低时,TinyQueue也可以将队列减小到256个单元。真实平台上的性能测试结果表明,由于TinyQueue可以自适应地调整队列大小,因此其具有最高的一级缓存命中率(99.20%)和最低的三级缓存未命中率(0.07%)。通过减小队列大小,TinyQueue可以大大减小缓存缺失率,从而提高队列的整体性能。

表2 真实测试平台中各无锁队列的性能
值得注意的是,在该真实测试平台上,所有队列的性能都比在文献[1,6]中所采用的理想测试平台中的性能要差(在理想测试平台中,一次入队或出队操作通常需要10 ns),其原因在于在该真实测试平台中,本文更真实地还原了实际应用中数据的接收处理场景。正如文献[1]指出的,在这样的测试平台上测试一个队列的性能比在理想测试平台上测试更有价值。
5 结束语
本文提出一种适用于多核处理器中流水线并行化的高效无锁队列TinyQueue。当数据到达速率较低时,TinyQueue可以自适应地减小队列大小,保持较小的内存占用,提高缓存命中率;当数据速率较高时,TinyQueue可以自适应地增加队列大小,以避免数据丢失。因此,即使在输入数据频率波动较大的实际应用中,TinyQueue仍能在较少的CPU周期内完成一次入队或出队操作,保持较好的性能。由于TinyQueue的性能可以通过实时系统调度器进一步优化,因此下一步将对此进行研究。
