基于多数据源交叉表决的园区人员分布的方法研究
2018-08-13付鹏飞
许 斌,付鹏飞
基于多数据源交叉表决的园区人员分布的方法研究
许 斌,付鹏飞
(泛亚汽车技术中心有限公司,上海 201208)
本文通过多种数据源的采集,表决,能够较为精准地描绘出大型园区内所有人员的位置快照,进而得出某时刻园区人员的分布特征。从而形成一种交叉认证的方式,门禁数据、视频数据、Wi-Fi信号数据相结合,提升记录的准确度。弥补传统人员分布统计方法不足,为园区数字化运营提供数据支撑。
交叉验证;统计方法;优化;表决
0 引言
人流量统计技术[1]由于其广泛的应用前景在很多领域受到研究者普遍的关注,如多媒体技术、计算机视觉以及视频监控等领域,准确而实时的人流量估计可以给园区/商场的管理者提供有价值的信息,自动地管理公共场合的人流信息,动态地分配园区/商场内有限的资源(如电力资源,暖通资源,保洁资源,安全资源等),同时可以为安全控制提供重要的保证。同时积累的大量数据能够协助园区规划人员调整运营策略,新建园区规划,发现表征之下的潜在问题,更深层次地提升企业效率。但是由于实际应用中的诸多困难,使人流量统计技术仍然面临巨大的挑战。结合目前公司的实际情况,统计公司大楼或园区的人员数量,主要有以下几个方式:
(1)门禁和闸机,通过验证有效身份记录人员进出。门禁和闸机相对来说比较准确,但针对一卡多刷(一人刷卡,多人进出)的情况,可行性较低且当发生次数较多的时,准确度会有所下降。
(2)摄像头人脸识别[2],是基于离线数据处理和人脸识别的算法,实现识别效果较高的方案,但这种方案容易受到光照条件、拍摄角度以及遮挡物的影响,从而影响识别效果。
(3)WIFI探针[3],基于员工多数把手机带在身边的先验假设,使用信号三角定位算法,可以精准地定位员工位置。
(4)红外对射设备,可以有区分生命对象和无生命对象,但不能区分单人还是多人,人群密集的情况下,误差率超多60%。
总之,所获得的数据源会因为各种异常状况导致准确度下降,如门禁系统,会出现一人刷卡多人进出的情况。摄像头人脸抓拍则受限于光照条件,角度等。如果员工进入工作区域但不连接wifi,则对wifi探针来说本身就是一种样品丢失。闸机系统的准确度较高,但是本身会有部署上面的难题,如闸机很难在楼层或更小的颗粒度部署。
基于此,本文在传统企业及园区的传统基础设施的基础上,将采集到的数据集合进行处理,提出了一种处理流程和表决的方式,得出最终的人员分布统计数据。从而形成一种交叉认证的方式,可以很大程度提高记录的准确度,为后续的数据展示提供良好的基础。
1 基本理论概况
1.1 统计学习
统计学习[4]是用计算机基于数据构建统计模型并运用学习产生的模型对新的数据进行预测和分析的一门学科。统计学习主要由监督学习、无监督学习、半监督学习等组成,由于我们主要关注的是监督学习,它是统计学习的一个重要分支,也是统计学习中内容最为丰富、应用最为广泛的部分,在监督学习的情况下,统计学习的方法可以概括如下:从给定的有限训练数据出发,假设数据是独立同分布的产生的,并假设要学习的模型属于某类函数的集合,我们通常称为假设空间,应用某个评价准则,从假设空间中选取一个最优的模型,即在给定的评价准则下,选择具有最优预测能力的模型,我们把这个过程叫做模型选择[5],具体过程为:首先得到一个有限的数据集合,其次,确定包含所有可能模型的假设空间,即学习模型的集合,再确定评价准则,利用学习算法进行学习,最后根据准则选出最优的模型,最后利用学习到的模型对新数据进行预测和分析。
1.2 交叉数据验证
交叉验证(Cross-validation)[6]主要用于建模应用中,例如PCR、PLS回归建模中。在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。交叉验证的基本思想是把在某种意义下将原始数据[7](dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。常见的形式主要有Holdout验证、K-fold cross-validation和留一验证。
1.3 人员统计算法
员工每次刷卡,会产生一条包括有员工ID号,卡机ID号,刷卡时间等信息的时序数据,存入卡机系统数据库中。通过在每个卡机刷卡、记录刷卡时间和位置、查询卡机系统数据的方式,我们可以利用人工刷卡探测的方法将卡机ID信息与建筑出入口的地理位置对应起来,建立起映射关系。由此可以从刷卡记录,获悉刷卡人所在的园区内地理位置。通过同步卡机数据库,匹配卡机地理位置信息,可以得到园区内所有人最近刷卡位置表(后简称表1)。根据表1中位置信息进行分类汇总,便可得知各楼或各层人数情况。但对每客户端、每次请求都进行分类汇总操作是不经济的,故增加人数统计表(后简称表2),后台程序定时对表1进行分类汇总,结果数据存入表2中;前端展示时直接使用表2中的结果数据,减少系统负担,提高响应速度。
2 系统设计
本系统基于传统企业及园区的传统基础设施,如门禁/闸机,CCTV监控,和WIFI探针系统,将采集到的数据集合进行处理,提出了一种处理流程和表决的方式,得出最终的人员分布统计数据,具体设计主要包括以下模块。
2.1 数据存储模块
门禁/闸机刷卡、人脸抓拍一体机以及wifi探针三个采样系统均拥有自身独立的MySql存储数据库保存原始数据集,不仅彼此独立也便于采集模块与其他应用集成[6]。从而保证关键数据源字段的一致性,此外本文的数据处理后台需要定时抓取三个采样系统数据源的数据库。
2.2 数据结构
Source Data Architecture源数据结构如表1所示Target Data Architecture目标数据结构如表2所示。
表1 Source Data Architecture源数据结构

Tab.1 Source Data Architecture source data structure
表2 Target Data Architecture目标数据结构

Tab.2 Target Data Architecture target data structure
2.3 数据采集模块设计
首先对企业园区的楼层进行单位统计区域的划分。以便于基于划分统计区域和统计时间片统计出每一个区域的实时人数。原始数据采集获取主要包括3个部分。即闸机/门禁刷卡系统、人脸抓拍一体机以及Wifi探针等。通过以上三个部分数据收集模块收集员工特征信息,即:
基于门禁/闸机刷卡,从而确定卡片序号和员工ID一对一映射的关系,如刷卡事件发生时,可以确定员工的ID。
基于人脸抓拍一体机,通过员工的图片数据库,对员工进行人脸识别并进行神经网络训练,提取员工体貌特征。
基于wifi探针,wifi连接系统开放域账号登录,当员工使用域账号连接wifi的时候,可获取员工的ID。
对于访客,本文关闭门禁/闸机和wifi探针采样通道,即不计入采集模块的数据库。采用人脸抓拍一体机的无监督学习,自动总结访客特征。对于未注册的人脸时,将数据归为其他人员,记录训练后的面部特征,给特征分配随机ID用于后续匹配和去重。
2.4 同步处理
鉴于采集模块的记录内容无法直接使用,因此本文采用数据处理服务器对采集模块的数据进行同步处理,频率为5分钟/次。采集模块的每个子模块(门禁/闸机,自拍一体机以及wifi探针)需要开放数据字段接口,子模块的字段接口需具有一致性。
以ID为主键,第一次同步为全量同步,通过数据分析服务器的数据库驱动客户端查询采集模块的数据,获得数据后插入本地的数据库中。其后每5分钟执行一次增量备份,即只同步比数据分析服务器库中记录ID更大的数据条目。如此即可生成了一张原始数据条目表,如表3所示。
使用间隔5分钟,将一天的时间切割成1440段时间片,数据分析服务器从上表1中,生成每个时间片中的人员位置快照。结合实际经验,对某个员工来说,每个时间片中的位置是唯一的。同时最新的记录时间则记录的员工的最新位置信息如表4所示。
表3 原始数据条目表

Tab.3 Original data entry table
表4 最新位置信息表

Tab.4 Latest location information table
2.5 系统调优和表决
因系统目前使用刷卡地理位置表征员工实时位置,但是刷卡数据为离散化追踪信息,本质上是对用户实时位置的一种离散化抽样与边信道估计。当因楼层仅有进门卡机无出门卡机、员工跟随他人进入等原因,致使抽样频率降低、样本减少时,系统数据的实时准确性必然降低[8]。但通过员工部门、行为习惯调查、历史运营数据等先验知识,可以进一步对位置数据进行插值优化(去重和表决),尽可能提升运营管理的准确度[9]。
(1)闸机处数据调优
当接收到的刷卡信息来自一楼大厅闸机时,由于需要等待和乘坐电梯,员工不会立刻进入其部门所在楼层;此时,将对应员工数计入大厅人数计数。另由于东西层大厅不连通,可将东西侧刷卡人员归纳到各自刷卡的大厅中,进一步提升准确性。
(2)楼层数据调优
当员工乘坐电梯到达工作楼层,并刷卡进入部门区域时,其最新的刷卡位置可作为判断其所在楼层的准确依据。但如果因楼层玻璃门未关闭,或一人刷卡多人同时进入楼层,此时无法通过该层刷卡记录获取楼层字段信息,相当于损失了采样点,导致人员位置和各层人数出现误差。此时,可以使用该员工的门卡号查询其部门信息与工位信息,再映射到所在楼层。此映射是一个柔性校正过程,基于大多数员工主要活动楼层为部门所在楼层这一假设,支持该假设的依据为日常运营统计数据先验知识。
(3)调优
三种采样源有个是相互印证的过程,这也是绝大多数情况。但不可避免地会出现单个数据源样本丢失情况,下表5就是针对单个数据源的样本丢失进行插值。
表5 调优数据表

Tab.5 Tuning data table
通过表决调优,我们就可以记录了每个时间段每个人的位置信息。
(4)整体流程和系统数学算法
系统步骤如图1所示。
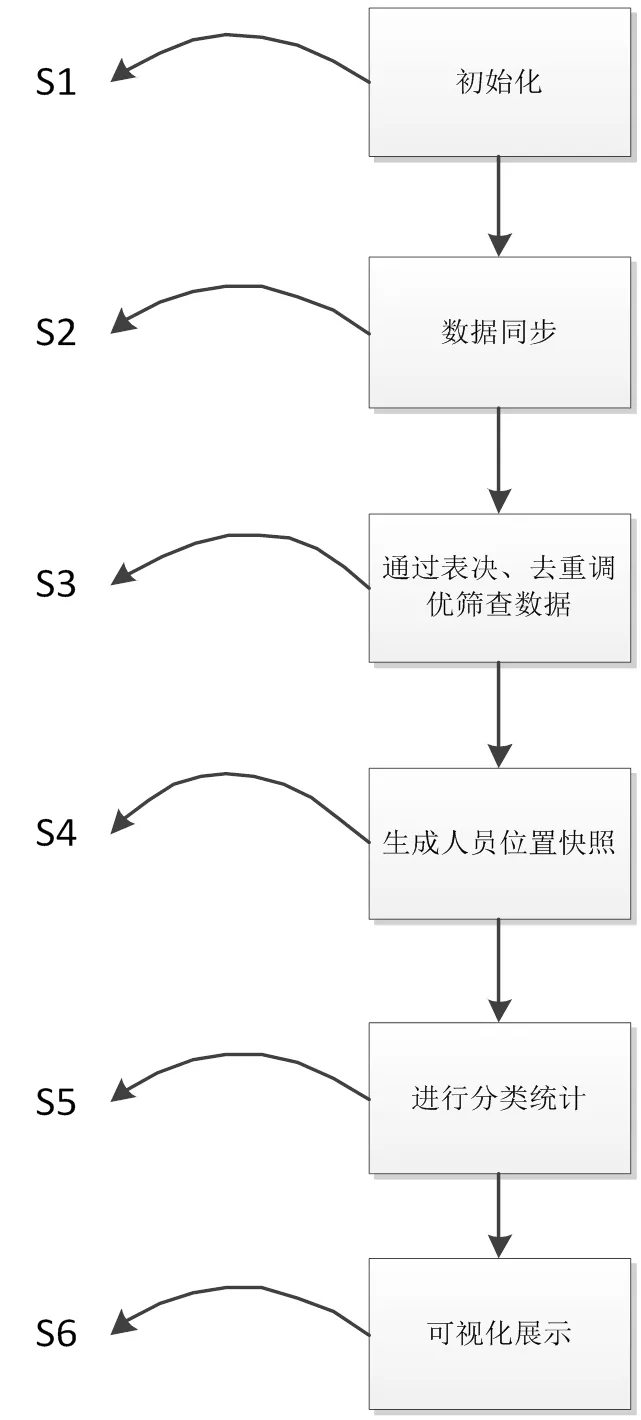
图1 系统步骤图
(5)数学算法
A1初始化
A1.1 定义CardID为在第栋建筑的第层的第个采样设备(闸机/抓拍一体机/wifi探针)所记录的员工ID
A1.2 建立表1a,其中存储的数据为CardID- Door,即,在第栋建筑的第层的第个闸机录入过的员工ID;
建立表1b,其中存储的数据为CardID-Video,即,在第栋建筑的第层的第个抓拍一体机录入过的员工ID;
建立表1c,其中存储的数据为CardID-Wifi,即,在第栋建筑的第层的第个Wifi探针录入过的员工ID;
A1.3 建立表1,其中表1为表1a,1b,1c进过表决插值、调优以后的集合。表1中,CardID- Access,CardID-Video,CardID-Wifi,统一抽象为CardID
A1.4 定义N为第栋建筑的总人数,并将其存储于表2中。
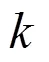
A1.7 令大厅的对应的值为1;
A2. 读取当前时刻T;
A2.1 如果TT≥D,那么
A2.2¬T;
A2.3 获取CardID;
A2.4 如果=1,那么
A2.4.1 查询用户的部门信息得到,,,并更新CardID;
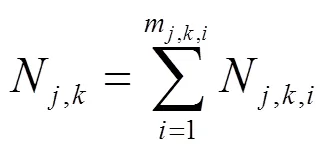

A2.7 如果T=0,那么
A2.8.1 清空表1,表2;
A2.8 跳转到步骤A2。
(6)数据可视化
数据可视化[10]采用一般的B/S架构,使用诸多现代浏览器服务技术python, flask, gunicorn, nginx等。其中还包括了WebGL的3D渲染技术。因这部分通用技术不是本文的核心,故不加赘述。
(7)敏感信息处理
本文的方法依赖于员工的行为记录,实际上涉及到了员工身份、部门信息、行为记录等敏感信息,这些信息都不应对外公开[11]。本方法在实例中使用了展现层和持久化层分离的做法。对数据持久化层做了严格的底层网络安全部署。同时使用了单向加密技术,对于高度机密的信息进行HMAC-SHA256的加密方法,进行先加密再持久化。从而实现底层和应用层对于敏感信息的双重保护。
3 结论
本文在企业及园区的传统基础设施的基础上,采用成本最小的方式,将采集到的数据集合进行处理,提出了一种处理流程和表决的方式,得出最终的人员分布统计数据。从而形成一种交叉认证的方式,可以很大程度提高记录的准确度,为后续的数据展示提供良好的基础[12]。园区管理人员可以在集中监控大屏上看到整个楼宇的人员密集度分配,同时可以查询到具体楼层的人数。最终显示的人数是集合了门禁数据,人脸抓拍一体机和wifi探针定位技术交叉认证的最终结果,在数据的可靠性上大于任何一个单一数据源的分析结果。在泛亚园区的实际测试中,其可靠度高达90%。通过分析,主要的误差来源于员工不把手机带在身边,同时另外两个采样源丢失了一个的时候。导致系统认为员工的手机所在位置即员工所在位置。
我们在实际应用中认为90%的可靠度足够满足我们管理需求。园区的管理人员通过直观的数据,可以进行智能动态决策,优化资源分配、从容应对突发事件。如调整保洁时间,增减出入口数量,调节区域照明和暖通,分配安防资源等。同时关于园区/楼宇未来的规划建设,此人员热力图也有极大的指导意义。
[1] 彭章祥. 基于视频的人流量统计技术研究[D]. 华中科技大学, 2014.
[2] 满宪金. 人脸图像识别方法的研究[J]. 软件, 2013, 34(3):136-137.
[3] 徐畅. 基于WiFi的人流量监控系统的设计与实现[D]. 北京邮电大学, 2017.
[4] 陈元, 陈文伟. 数据开采与统计学[J]. 计算机工程与应用, 2000, 36(5):15-17.
[5] 方书晴. 浅析数据挖掘的分类与预测[J]. 软件, 2012, 33(6):77-79.
[6] 张健, 马骏, 刘茉. 基于数理统计方法的城市道路环形交叉口通行能力研究[J]. 北华大学学报(自然), 2003, 4(6):541-543.
[7] 何清顶. 测量船遥测数据处理方法研究[J]. 软件, 2013, 34(3):90-91.
[8] 万林. 基于概率统计方法的基因调控网络的多层次研究[D]. 北京大学, 2009.
[9] 秦爱武, 周敏. 本地数据库在大数据量数值计算中的分布式应用[J]. 软件, 2012, 33(2):56-57.
[10] 毛俊生, 杨志清, 李国锋. 基于B/S模式的装备信息管理系统的设计[J]. 软件, 2012, 33(4):47-49.
[11] 顾德军, 伍铁军. 一种基于人头特征的人数统计方法研究[J]. 机械制造与自动化, 2010, 39(4):134-138.
[12] 齐劲松, 王伟, 吴成富,等. 三余度飞控计算机交叉数据链系统设计[J]. 测控技术, 2007, 26(5):73-75.
Study on the Method of Personnel Distribution in the Park Based on Cross-voting of Multiple Data Sources
XU Bin, FU Peng-fei
(Pan Asia Technical Automotive Center Co., Ltd, Shanghai 201208, China)
Through the collection and voting of multiple data sources, this paper can accurately describe the location snapshot of all personnel in a large park, and then obtain the distribution characteristics of personnel in the park at a certain time. In this way, a cross-authentication method is formed. Access control data, video data and wi-fi signal data are combined to improve the accuracy of records. It makes up for the deficiency of traditional personnel distribution statistics methods and provides data support for the digital operation of the park.
Cross validation; Statistical method; Optimization; Vote
TP391.41
A
10.3969/j.issn.1003-6970.2018.07.044
许斌(1968),男,硕士研究生,高级工程师,主要研究方向:数据分析,智能化运营,企业现代化管理,软件系统构架设 计;付鹏飞(1982),男,本科,中级工程师,主要研究方向:数据分析,机器视觉。
本文著录格式:许斌,付鹏飞. 基于多数据源交叉表决的园区人员分布的方法研究[J]. 软件,2018,39(7):208-212
