基于偏互信息与核心向量机的煤质大数据预测
2018-08-07梁伟平牛博通
梁伟平, 牛博通
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引 言
煤的发热量是电站系统的重要参数,尤其在电站锅炉热平衡、热效率计算、确定最佳的风煤比、以及估计燃烧是否达到理论温度等过程中,煤质发热量更是不可缺少[1-2]。随着智能算法的发展,神经网络开始用于建立煤质发热量的软测量模型[3~5],但是神经网络算法训练时间长、易陷入局部最优点等缺点限制了其效果。随后基于结构风险最小化准则的支持向量机算法被引入[6~9],解决了神经网络算法的问题,但随着DCS和存储技术的发展,数据规模不断增大,一般算法直接处理大量数据会导致建模速度慢,若从大规模数据中选取小样本,会因凭借人为因素和经验主义影响模型的精度和泛化能力。另外模型的特征变量是决定一个模型是否准确和简单的重要因素,对特征变量进行分析,选出最优变量集会使模型更加准确和简单,有利于提高泛化能力[10]。
本文采用Tsang等提出的CVR算法[11],该方法利用一种计算几何中的最小闭包球理论(Minimum Enclosing Ball,MEB)与支持向量机(Support Vector Machine,SVM)相结合,使算法的计算复杂度和样本容量成正比,空间复杂度与样本容量无关[12],相比较其它SVM方法,当建模数据增加时,因受二次规划(Quadratic Programming,QP)问题的影响,模型的计算时间会随之增加,而CVR随着建模数据的增加,计算精度会有所改善(与大样本中是否包含更多的信息有关),但计算时间的增长远小于其它算法,解决了大规模数据下建模耗时的问题,弥补了建模需要根据人为经验选取小样本导致模型不准确的缺点;在特征变量选择上,利用R. J. May等提出的PMI方法分析特征变量[13],该方法基于信息熵理论中的互信息(Mutual Information,MI),通过条件期望消除了变量之间的联系,消除了输入变量的耦合关系对MI算法的影响[14],可以建立最经济简单、最大限度快速的软测量模型。
1 PMI与CVR原理
1.1 PMI
信息熵的概念由Shannon在1948年提出,是用来量化描述变量所带信息量的方法,MI又在此基础上进一步的度量了一个变量中含有的关于另一个变量的信息[15],R.Battiti等就基于互信息对神经网络的特征变量进行了筛选[16],变量之间可能的耦合关系使MI计算受到了影响。PMI方法引入条件期望,将处理后的变量再得到互信息值,解决了这一问题。
信息熵的具体计算公式为:
(1)
式中:pi为在各个取值下概率分布,n为数据个数。如果存在有向量X与Y相关,pij为X和Y的联合分布概率,则二维联合熵定义为:

(2)
那么互信息的公式为:

(3)
由于一般样本数据的概率分布未知,所以需要采用概率密度估计的方法来解决,因此实际情况下的公式变为如下:

(4)
式中:xi,yi分别为X,Y的第i个取值,f为基于n个样本数据的概率估计密度函数。
在MI的计算中,若输入X,Z之间有耦合,那么I(Y,Z) 的值会大于实际,所以用条件期望mX(Z) 和mY(Z)消除Z的影响,如下:
(5)
U=X-mX(Z)
(6)
V=Y-mY(Z)
(7)
式中:zi为Z的第i个取值。
那么X,Y的偏互信息可记为:
IPMI(X,Y)=IPMI(U,V)
(8)
概率密度估计方法采用核密度估计,这里核函数采取高斯核函数,那么概率密度函数的估计公式为[17]:
(9)
式中:d为X的维数;∑为X的协方差;h为带宽;‖x-xi‖为马氏距离。
马氏距离公式为:
‖x-xi‖=(x-xi)TΣ-1(x-xi)
(10)
带宽的选择利用高斯带宽,公式为:

(11)
式中:σ为样本标准差。
结束条件采用赤池信息量准则(Akaike Information Criterion, AIC),其公式为[18]:
(12)
式中:ri为根据已选变量计算的Y回归残差;p为已选变量个数。随选出变量的变化,TAIC逐渐减小,当不再减少时终止筛选。
最终的PMI变量选择的算法流程如下:
1)初始化S为空集,C不为空集;
2)计算C中每个变量与Y的互信息,将互信息最大的Cs移入S,并更新C;
3)若C不为空,对每一个Cj∈C,计算v=Cj-mCj(S)和计算u=Cj-mCj(S);
4)计算I(u,v),选取使I(u,v)最大的Cs,用Cs计算AIC;
5)若AIC减小,则将Cs移入S,返回步骤3,否则终止。
1.2 CVR
(1)近似MEB与CVR
给定一点集S={x1,…,xm},xi∈Rd,那么集合S的最小闭包球是指包含集合S中所有数据点的最小球,表示为MEB(S)。传统最小闭包球算法不能有效的解决d大于30的问题,因此提出了一种快速近似算法,任意给定ε>0,如果存在R≤rMEB(S)并且S∈B(c,(1+ε)),则称B(c,(1+ε))为B(c,R)的(1+ε)-近似,如下图1所示。

图1 近似闭包球
解决这个子集的问题也能得到近似的估计和正确的结果[19],并且最终的核心集中的数量与迭代的次数无关,主要与ε有关。
对于最小闭包球我们可以得到式(13):
minR2:‖φ(xi)-c‖2≤R2,i=1,…,m
(13)
φ(x)是由核函数诱导的特征映射函数,得到上式的对偶形式如式(14):
maxαTdiag(K)-αTKαα≥0,αT1=1
(14)
(14)式中:α=[αi,…,αm]T是拉格朗日乘子,0=[0,…,0]T,1=[1,…,1]T,Km×m=[K(xi,xi)]=[φ(xi)Tφ(xi)]是核矩阵。
在支持向量回归中,有训练集合{zi=(xi,yi)},其中xi为输入变量,yi为输出变量。经过核函数处理后的线性拟合方为:f(x)=ωTφ(xi)+b,采用ε-敏感损失函数,那么最优化的公式可以表示为式(15)[20]:

(15)
这里μ是控制损失函数参数的,得到对应的对偶的矩阵形式如式(16):
(16)
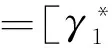
(17)
但是得到的如式(16)的二次规划问题与最小闭包球问题的式(14)的形式不同。
(2)中心约束MEB问题
现在我们对每一个φ(xi)增加一个额外的项δi∈R,如式:φ(xi)~[φ(xi)T,δi]同时约束球心的最后一维变为:c~[cT,0]T那么问题原始式变为如下:
minR2:‖φ(xi)-c‖2+δ2≤R2
(18)

maxαT(diag(K)+δ)-αTKα
s.t.α≥0,αT1=1
(19)
那么只要有最优的,就可以计算出
(20)
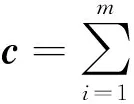
(21)
因为αT1=1,那么对于任意η∈R加入不会影响α的结果,所以有[21]:
当定义:
(22)
(23)

(24)
选择适当的η保证式(11)中的δ≥0,那么式(24)变为:
(25)
式(25)与式(14)有着相同的形式,因此利用中心约束最小闭包球问题,就可以及将ε-不敏感损失函数的支持向量机回归问题转化为最小闭包球问题。
(3) CVR算法流程
CVR算法步骤如下表所示:
①初始化选择S0,C0,R0;
②在第t次迭代中,如果没有φ(zi)在最小闭包球B(Ct,(1+ε)Rt)外,就终止训练;
③找到距离Ct最远的φ(zi),使St+1=St∪φ(zi);
④得到最新的闭包球集,计算新的Ct,Rt;
⑤迭代次数t=t+1,并返回第二步。
核心集中的向量为核心向量,通过这些核心向量可以得到原SVM问题的解。
2 数据预处理及变量分析
2.1 数据预处理
模型所用数据来自某掺煤燃烧电厂的煤质分析报告,数据包括:全水分Mt(%)、空气干燥基水分Mad(%),空气干燥基灰分Aad(%)、空气干燥基挥发分Vad(%)、收到基低位发热量Qnet, ar(MJ/kg)、收到基全硫St,ar(%)、空干基全硫St, ad(%)等7维特征变量,为了去除数据噪声,利用五点三次滑动平均法对数据进行降噪处理,部分低位发热量去噪前后的对比分布如图2所示:

图2 低位发热量去噪前后对比分布
图2表明五点三次滑动平均法有效的滤过了噪声的干扰,另外不难发现掺配煤下的煤质波动非常频繁,且波动较大。然后再利用MATLAB中mapstd工具箱对数据进行归一化处理,消除数据单位的影响。
2.2 PMI变量分析
建立 CVR软测量模型,特征变量的选取对于模型的计算复杂度、精度以及泛化能力都影响重大,特征变量之间有相关性和耦合性关系,可以利用PMI的方法分析预测模型的最优变量子集。根据PMI变量筛选的步骤,得到TAIC的变化曲线如图3所示。
特征变量初始特征集是根据最大互信息得出,各个特征变量与低位发热量的互信值如表1所示。
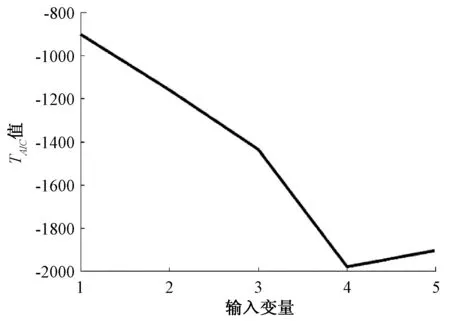
图3 PMI筛选TAIC曲线

%
全水分信息与低位发热量互信值为0.334,是与低位发热量互信值最大的变量,所以初始特征集中的第1个变量是全水分。在初始特征集的基础上PMI计算得到的第2个变量是空干基全硫,第3个变量是收到基全硫,第4个变量是空干基挥发分,当特征集加入第5个变量也就是空干基灰分时TAIC曲线由下降趋势变为上升,说明虽然空干基灰分和空干基水分虽然与低位发热量有互信息关系,但是在特征变量已经包含前4个特征的情况下,空干基灰分和空干基水分与已选特征集之间的耦合性和相关性会导致将其加入特征集之后使预测效果变差。所以选取使特征变量与预测变量互信息最强并且特征变量间耦合性最小的全水分、空干基全硫、收到基全硫、空干基灰分4个变量作为模型的输入特征变量。
3 实验仿真
3.1 模型初始参数及构建
因为核心支持向量机在处理大数据建模时对样本没有容量限制,可以利用最小闭包球的特点快速筛选支持向量,所以无需选取最优样本,因此选用去噪后的全部6 180 组煤质数据,以PMI选择后的变量为特征变量,进行仿真。
根据文献[12],模型初始参数C对预测精度与预测时间影响较小,一般可取105,膨胀系数mu则对模型影响较大,对mu利用量子遗传算法进行寻优,选择初始种群为30,转角步长为0.02,变异概率为0.1,迭代次数为30,得到当为全部输入变量时最优参数为mu=2×10-6和当变量为选择之后时的最优参数为mu=5×10-7。
初始拉格朗日参数选为1/2,剩下为0。初始核心集是先找到任意一点z0,再找到距离z0最远的点za, 距离za最远的点zb,za,zb为核心集,在第二步计算点到球心的距离时利用核函数避免了进行φ(zl)的显示计算如下式:

(26)
计算样本与球心距离时采用Smola与Scholkopf提出的一种加速方法,文中提到当样本中随机选取59个构成子集时,最远点的在其中的可能性为95%,可以大大降低时间复杂度[22],利用此方法使得随机选中点不同,所以可以利用多次计算取最优结果的方法。
为了评价模型的预测能力,选取均方差(MSE)、平均相对误差(MRE)两个指标反应模型的预测能力。
PMI-CVR算法的流程如图4所示:

图4 PMI-CVR算法流程图
算法中TAIC是一个数,将其初值设置为一个较大的数值,计算边缘概率密度时的高斯带宽取1,计算联合概率密度时d取2,判断是否为最优结果时,是利用遗传算法满足一定精度要求的条件,或着是当遗传算法的迭代次数达到设定的最大迭代次数时的最优值。
3.2 实验与结果分析
将处理后的数据随机选取6 130组作为训练样本,剩下50组为测试样本,按照上述方法建立5组随机训练样本和对应的测试样本,分别利用5组数据对CVR模型和PMI-CVR模型进行预测,模型的均方差、平均相对误差以及计算时间取 5次结果的平均值,如表2所示:

表2 PMI-CVR与CVR对比
根据表2数据发现,采用PMI的方法进行变量筛选后,预测更加平稳, PMI-CVR模型预测的平均相对误差有所降低,说明经过PMI对有耦合性的特征变量进行剔除后,模型更加准确,泛化能力强,同时输入变量的减少使模型更加简单,计算时间变短,计算更快。
两种方法中预测最好的一组预测结果分别如图5、图6所示。

图5 CVR低位发热量预测
图6 PMI-CVR低位发热量预测
3.3 不同算法对比
利用经过PMI选择后的特征变量为输入特征变量,分别采用CVM和LSSVM两种算法进行建模。建模的样本数量以1 000为步距,分别建立 1 000~6 000 6组数据规模下的预测模型,每种样本规模下分别进行5次建模,得到的5组数据的平均值作为该样本规模下的结果, 两种方法的误差趋势和建模时间上的趋势,随着样本的增加两种方法建模误差对比图如图7所示。
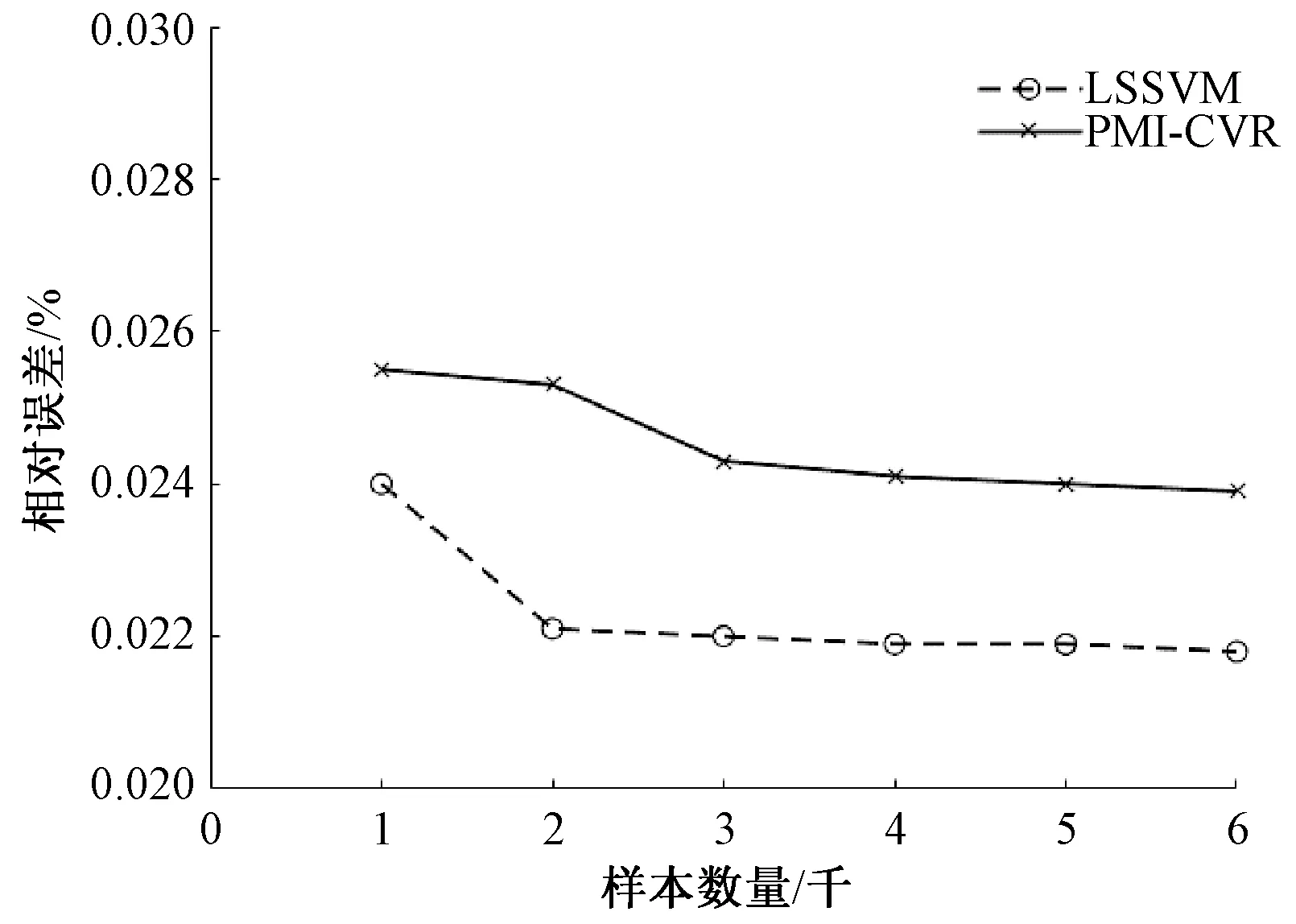
图7 CVR与LSSVM建模误差对比
随着样本的增加两种方法建模计算时间如图9所示:
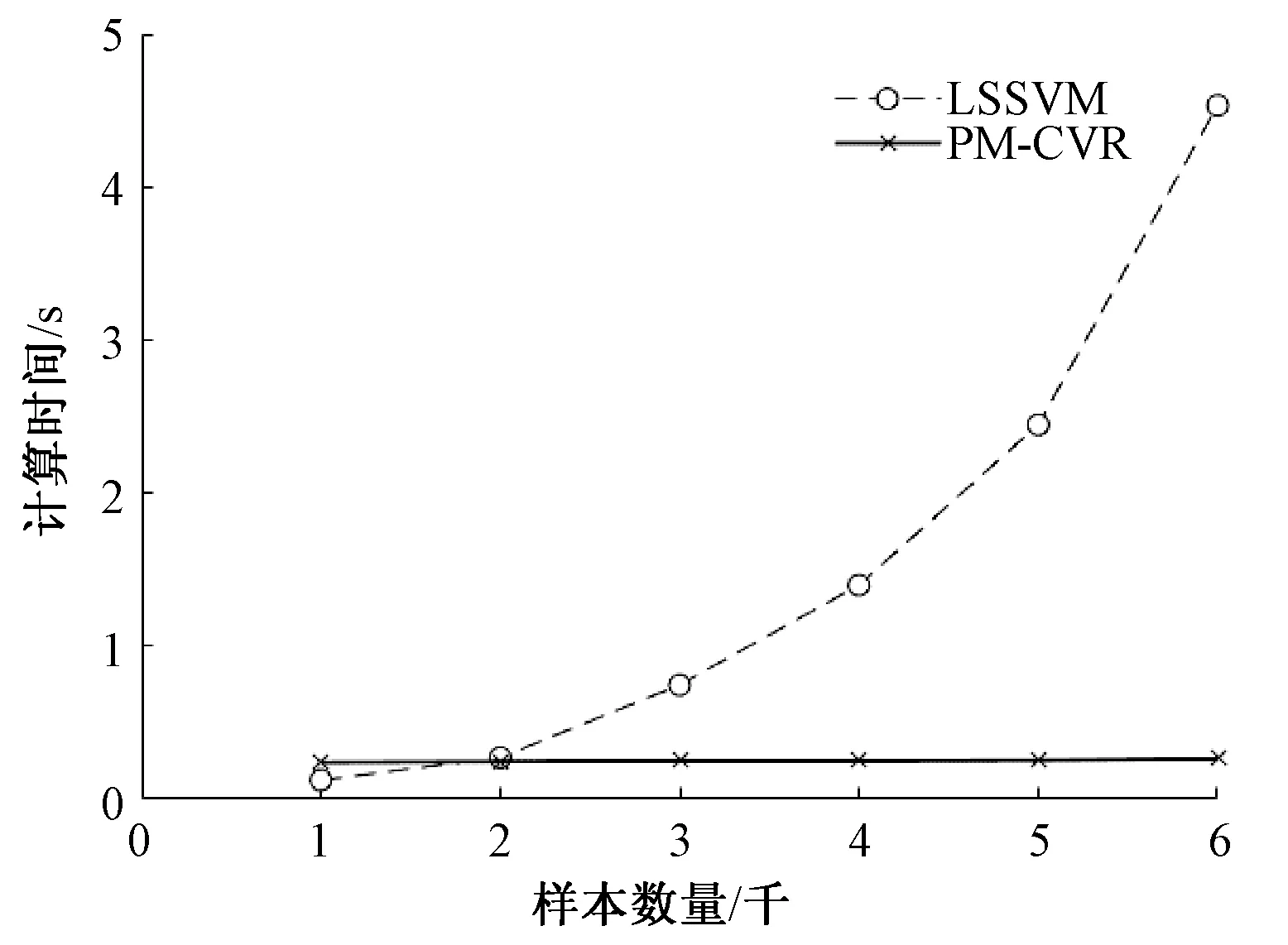
图8 CVR与LSSVM建模时间对比
对比图7与图8,当建模样本规模增加时,PMI-CVR与LSSVM的建模相对误差相差不到0.005,但是建模时间上LSSVM耗时增加明显,而PMI-CVR建模的时间变化很小。
4 结论
本文利用偏互信息与核心支持向量机相结合,在大规模煤质数据下建立了PMI-CVR模型,相比未经过PMI处理的CVR模型,PMI-CVR更加简单,计算结果泛化能力更强;在相同的输入特征变量下,随着样本数据量增加的PMI-CVR模型比LSSVM模型计算更快,同时在准确度上二者相差不大,所以PMI-CVR对大数据的处理能力更强。最终PMI-CVR的低位发热量预测模型相对误差为0.025,计算时间为0.272 s,证明该模型在大规模数据下更加有优势。
