一种异步执行改进三维重构的并行方法
2018-08-06孟腾腾徐克辉
刘 镇,孟腾腾,徐克辉
(1.江苏科技大学 计算机科学与工程学院, 镇江 212003) (2.中国船舶重工集团有限公司 第七二四研究所, 南京 211153)
随着虚拟现实技术的不断发展,人机交互方式的三维场景摆脱了传统文本图像的信息交流方式,虚拟购物、虚拟教学、远程可视化等虚拟现实技术不断得到普及[1].与此同时,可编程图像处理器GPU编程技术的成熟,以及其强大的并行计算和浮点运算能力为图像处理的加速提供了编程基础.面对越来越大的处理规模,以及越来越高的用户体验,如何提高实时性成为计算机图像系统的研究热点.获取传统三维模型需要大量采集数据且借助于建模工具.近年来发展的结构光法和运动恢复结构法(structure from motion, SFM)均可进行三维模型重建.结构光法适合于室内高精度重建,目前商业产品比较多,相对复杂;SFM方法比结构光方便,但精度差些,其主要用于无人机对大型建筑建模.针对这一现状,文中提出了一种基于多目视频流的并行化三维重构方法,该方法中移动终端和服务端异步执行,终端对多目视频流并行解码,服务端对传回的关键帧进行特征提取、立体匹配,最后,将计算的视差结合投影矩阵恢复三维场景.
1 基于多目视频流的并行化重构方法
分布并行化重构方法整体流程如图1.

图1 分布并行化重构方法整体流程Fig.1 Overall workflow of distributed parallel reconstruction
1.1 终端节点执行码流解码
H.264视频编解码包括提取层(network abstraction layer, NAL)和解码层,其串行解码框架如图2.

图2 H.264串行解码框架Fig.2 Frame of H.264 serial decoding
文中以NVIDIA Jetson-TK1作为终端节点实现对H.264基本档次码流的解码,主要提取视频这种密集型数据结构中的关键帧(I帧).其解码策略以CPU为主导进行码流分析、熵解码与重排序[2],GPU负责帧间预测、变换解码和环路滤波等.图3给出了CPU、GPU协同处理示意,即GPU在处理第N帧的模块时,CPU同时解析第N+1帧的数据,充分利用碎片时间,达到更高的处理效率,同时将得到的I帧传回服务器端.

图3 CPU、GPU协同处理示意Fig.3 CPU, GPU collaborative processing
1.2 服务器端算法原理及改进策略
为了提高服务端重构效率,文中采用CUDA(compute unified device architecture)加速尺度不变特征变换(scale invariant feeature transform,SIFT)方法.该方法充分利用CUDA合理分配主机和设备端的资源;在解决CPU和GPU数据传输延迟问题中,引入了动态CPU+GPU的类多级流水线调整策略,充分利用了CUDA架构特点,提高整体计算性能.
1.2.1 尺度不变空间特征点检测
高斯差分尺度空间[3-4]的构建、局部特征点检测、定位特征点主方向和生成特征描述符为SIFT算法的4大步骤.
对输入每一帧视频图像序列I(x,y),进行高斯滤波,则有:
L(x,y,σ)=G(x,y,σ)*I(x,y)
(1)
式中:符号*为卷积;G(x,y,σ)为尺度可变高斯函数.
(2)
式中:(x,y)为空间坐标,代表图像的像素位置;σ为尺度空间因子.对不同的尺度高斯差分核构建高斯差分尺度空间(difference of Gaussian,DOG),计算公式为:
D(x,y,σ)=L(x,y,kσ)-L(x,y,σ)
(3)
式中,系数k决定了高斯组中尺度层的数目.将DOG空间中的26个的像素点(上下及相邻区域)作为候选点,并在候选点处展开泰勒公式,计算为:
(4)
式中,v=(xyσ)T.由上式解得亚像素及亚尺度的精确坐标为:
(5)
(6)
式中,Tr(MHes)和Det(MHes)分别为该矩阵的几何行列式和与矩阵特征值相关的阈值.此外,为使特征点具有旋转不变性,为每一个特征点再计算一定领域内所有像素点的梯度,并统计梯度方向直方图,峰值为其主方向.最后,为了增强匹配的稳健性[5-6],以特征点为中心,16×16像素区域内的主方向为方向量进行分格梯度直方图统计及高斯加权,形成128维的特征描述符,接着通过比较两两之间的欧式距离获取匹配的特征点对.
1.2.2 基于CUDA的SIFT算法的改进策略
文中采用基于CUDA并行化方法加速的SIFT算法.在SIFT特征提取模块中,比较耗时的模块为建立高斯差分金字塔、定位特征点、确定关键点主方向.如图4,文中采用CUDA统一计算架构方法把逻辑性比较强,计算量比较小的计算高期核函数放在CPU主机端,而把周期性的建立高斯差分金字塔、计算极植点,提取主方向放在GPU设备端.
图5给出整体结构示意图,具体步骤:① 主机端(CPU端)进行图像输入、图像初始化、高斯核函数计算,同时将计算结果传到设备端;② 设备端(GPU端)将CPU端得到的卷积模板传入其常量存储区,建立高斯金字塔,之后传回CPU端,同时将相邻图像层之间相减得到差分金字塔;③ 在差分空间中进行特征点检测,将得到的尺度和位置信息载入GPU端,GPU端进行精确定位关键点,根据高斯权函数提取关键点主方向,然后再将关键点的信息传回CPU端;④ CPU端以特征点为中心,主方向为法向量,进行分格梯度直方图统计及高斯加权,形成128维的特征描述符.
由于CPU和GPU端进行数据传递比较耗时,采用类多级流水线和共享内存复用的方法来提高计算效率.
1.2.3 GPU端流水线调整策略
上述方法在计算任务分配过程中,充分利用了GPU优势,但CPU与GPU之间频繁的内存拷贝造成一定时间延迟,文中采用核函数异步执行的类CPU多级流水线方式提高计算效率.因为每个流内数据传输是按一定顺序执行的,而在CUDA统一计算架构下,流之间可以异步执行,文中将任务分成4个阶段,充分利用流之间异步执行特性,按类CPU多级流水线方式执行4个核函数,这一方法解决了数据拷贝造成的传输延迟问题.
1.3 特征匹配及三维场景恢复
上述SIFT算法输出的匹配关系存在部分出错率,且非常耗时,文中采用CUDA架构并行化近似最邻近特征匹配方法,将计算得到的视差,结合投影矩阵恢复三维场景.
1.3.1 基于CUDA架构改进近似最邻近特征匹配算法
对SIFT算法得到的两组128维的特征描述符V1、V2分别建立KD树,传统的KD树数据结构搜索效果很差,需要多次对其进行平衡.即在构建KD树,选择超平面时,取方差最大的维度,同时在中位数处进行分割.为了提高计算性能,最邻近特征匹配算法并不寻找严格最邻近,而是在KD树上寻找近似最邻近(approximate nearest neighbor, ANN)特征点.匹配是否被采纳采用一个优先序列查找ANN,取代传统的阀值限定,最后通过第一、二的距离比来确定是否采纳.同时V1,V2必须同时互为ANN,匹配V1,V2才被采纳[7-8].
红黑树是一种自平衡二叉树,并已广泛应用于基于搜索的程序中[9-12],包括文本挖掘和核苷酸序列匹配.对于包含n个节点的树形结构,其查询、插入和删除等操作的平均时间复杂度为O(lgn).文中方法的具体步骤如下:
(1) 在CPU端,构建包含红黑树特性的KD树数据结构,并完成数据初始化,GPU负责查找两个最邻近特征;同时,每一个线程负责一维的特征描述符匹配,则每个线柱块可以负责128维的特征描述符匹配,边缘不足128的进行补零操作,以减少判断开销.在计算最邻近特征时,使用欧式距离比较相似度,假设两个特征点用向量a,b表示,则向量a,b的欧式距离为每一维度差值的平方和的平方根,计算公式如式(7);同时,图6为GPU并行计算Li的过程,即首先将特征信息发送到GPU显存中,随后生成若干GPU线程负责相应像素的并行计算.
(7)
(2) 在每个连接点集的每个图像点和它的第一图像点之间建立联系.红黑树的键被设置为连接点集的第一图像点;当图像点不是第一个连接点时,
是不能在键值中被找到的.
(3) 创建连接点集中每个图像点和第一个像素点之间的关系.加载每个被构建的连接点并保存到密钥文件.创建这种密钥文件之后,如果两个匹配的图像点不是两个连接点集的第一个像素点,可以很容易地通过密钥文件的帮助,搜索其匹配的像素点.
通过分析上述匹配改进策略及快速查找方法,可总结出基于CUDA的并行最邻近特征匹配算法.伪代码为.

图6 计算特征点欧式距离的GPU资源划分Fig.6 GPU resources division of computing the key point Euclidean distance
(4) 在上述密钥交换方法中,在确定一个新的可用连接点集合是否应与现有的连接点集进行组合时,只需要搜索红黑树而不是所有的密钥集合之间的键值图像点,搜索成本低且有效.此外,该方法只加载必要的候选连接点集并始终立即释放不必要的点集;因此,它可以保证在增加所限定的树中节点的数目和多连接点集时不增加搜索的运行时间.因此,在不违反内存容量处理时,这种方法也是可行和有效的.
1.3.2 由投影矩阵恢复三维场景

(8)
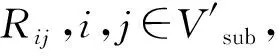
2 实验与分析
文中使用NVIDIA Jetson-TK1嵌入式开发组件作为移动终端实验节点,该设备具有4核ARM Cortex-A15 CPU、包含192个CUDA核心的Kepler GPU、2GB运行内存、8路信号输入接口.服务器端设备如下:Intel(R) Core(TM) i7-4770 3.40GHz CPU,NVIDIA Tesla K20c GPU、16GB内存,系统环境为Ubuntu14.04和CUDA6.5开发平台.
实验一,使用微软Kinect传感器和文中方法分别对室内场景建模,对比实验结果如图7,实验表明文中方法在精度上基本满足要求.

图7 建模结果对比Fig.7 Comparison of modeling results
多目并行化重构方法对单一场景多角度重构结果较理想,在进行实时场景重构时,能够基本满足及时性,但由于实验采用双目结构,实验结果存在部分阴影现象.
实验二,对标准图Tsukuba的RGB彩色图像进行了三维重构,实验结果如图8,实验结果表明,在得到多角度高清图像时,文中方法精度相比实验一的重构结果有明显提升.

图8 多角度下标准图Tsukuba的建模结果Fig.8 Modeling results of the standard chart Tsukuba under multiple angles
实验三,将文中方法和文献[5]中GPU加速SIFT算法方法进行对比实验.图9为对标准图beaver的特征提取对比实验.表1为对比实验结果.

表1 文中方法和文献[5]中GPU加速SIFT算法性能对比Table 1 Comparison of GPU accelerated SIFT algorithm performance between the proposed method and the literature 5′s method

表2 标准图Cones、Teddy、Tsukuba 及 Venus的CUDA加速匹配算法性能对比Table 2 Comparison of accelerated matching algorithm using standardFigure Cones, Teddy, Tsukuba and Venus
实验结果表明文中SIFT特征提取方法和文献[16]中方法及文献[5]中GPU加速方法三者检测精度相当,但与文献[5]中方法相比,实现了约1.7的加速比.此外并行化方法不仅提高视频数据流的处理速度,像素越高的图像加速效果越明显,同时终端节点采用了多目视频源的并行解码策略,减少了数据传输量,从而降低网络带宽的需求,由此改善了高清图像重构的及时性.表2为文中方法和文献[8]中方法对标准图Cones、Teddy、Tsukuba及 Venus进行特征匹配的对比实验,实验数据表明文中方法在CUDA架构下提升约7.1的加速比.

图9 实验结果对比Fig.9 Comparison of result
3 结论
文中提出一种异步执行改进三维重建的并行方法,该方法的并行化思想体现在两个层面:宏观层面是对服务端和终端相结合的任务级的并行化;微观层面是基于CUDA平台的编程体系结构,对各算法程序中能够并发执行的指令进行线程级的并行化.相关对比实验验证了三维重构各个子模块的并行加速效率.由实验数据可以看出文中并行方法有效提高了重建加速比.但也存在许多不足之处,因为文中主要针对复杂环境中的实时绘制方法进行改进,就实时三维点云的后期处理,并没有作深入讨论,所以文中方法仅适用于精度要求不是很高的快速建模场景.因此,以后将针对稠密点云的构建方法作更深入研究.
