BP神经网络结合遗传算法优化MIP工艺的产品分布
2018-08-03欧阳福生游俊峰方伟刚
欧阳福生,游俊峰,方伟刚
(华东理工大学石油加工研究所,上海 200237)
催化裂化(FCC)过程能将大量重油高效转化为汽油、柴油、液化气和低碳烯烃,因而成为炼油工业举足轻重的二次加工工艺[1]。汽油清洁化要解决的关键问题是降低烯烃和硫含量,为此,在传统催化裂化工艺基础上,国内外开发了一些能够显著降低汽油中烯烃含量的衍生催化裂化工艺[2]。MIP工艺是最具代表性的工艺,它通过设置两个反应区,不仅能降低催化裂化汽油烯烃含量,还能够通过多产异构烷烃来减少汽油辛烷值损失,因而在工业上得到广泛应用。
鉴于FCC工艺在石油加工中的重要地位,对该过程的模拟优化一直受到广泛重视。自1960年代起,科技工作者就通过建立机理模型对FCC的生产进行优化。但因为FCC工艺各操作变量之间的高度非线性和强偶联,机理模型的精度受到较大影响[3]。
人工神经网络(Artificial Neural Network,ANN)的自适应、自组织、自学习和非线性拟合能力极强,因此,它在一些复杂工业过程得到了广泛的应用,尤其在化工领域[4-9]。BP神经网络属于按误差逆向传播的多层前馈网络。本研究以MIP工业装置的大量实时数据为基础,通过建立BP神经网络模型并结合遗传算法来实现主要产物收率的优化。
1 数据收集
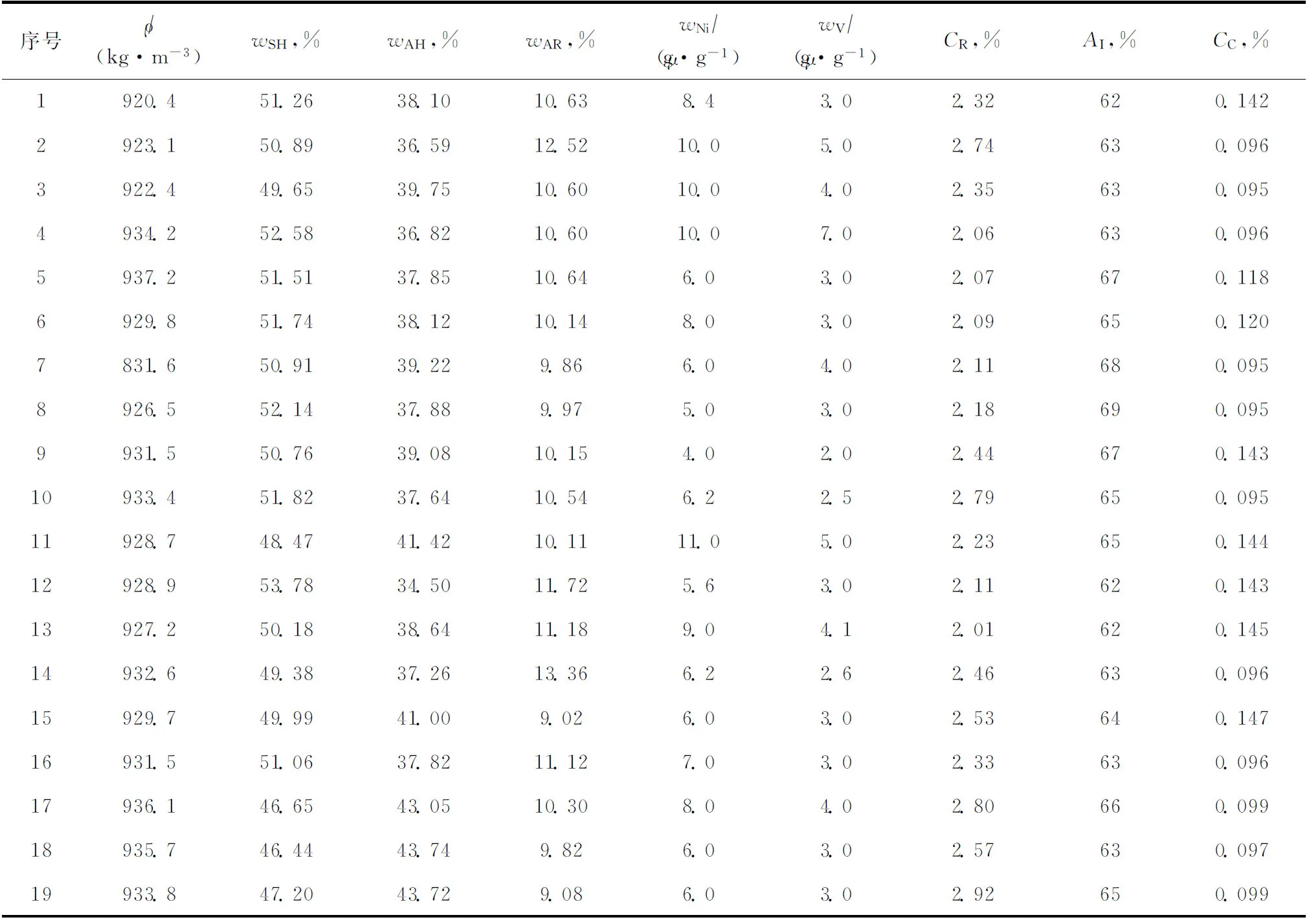
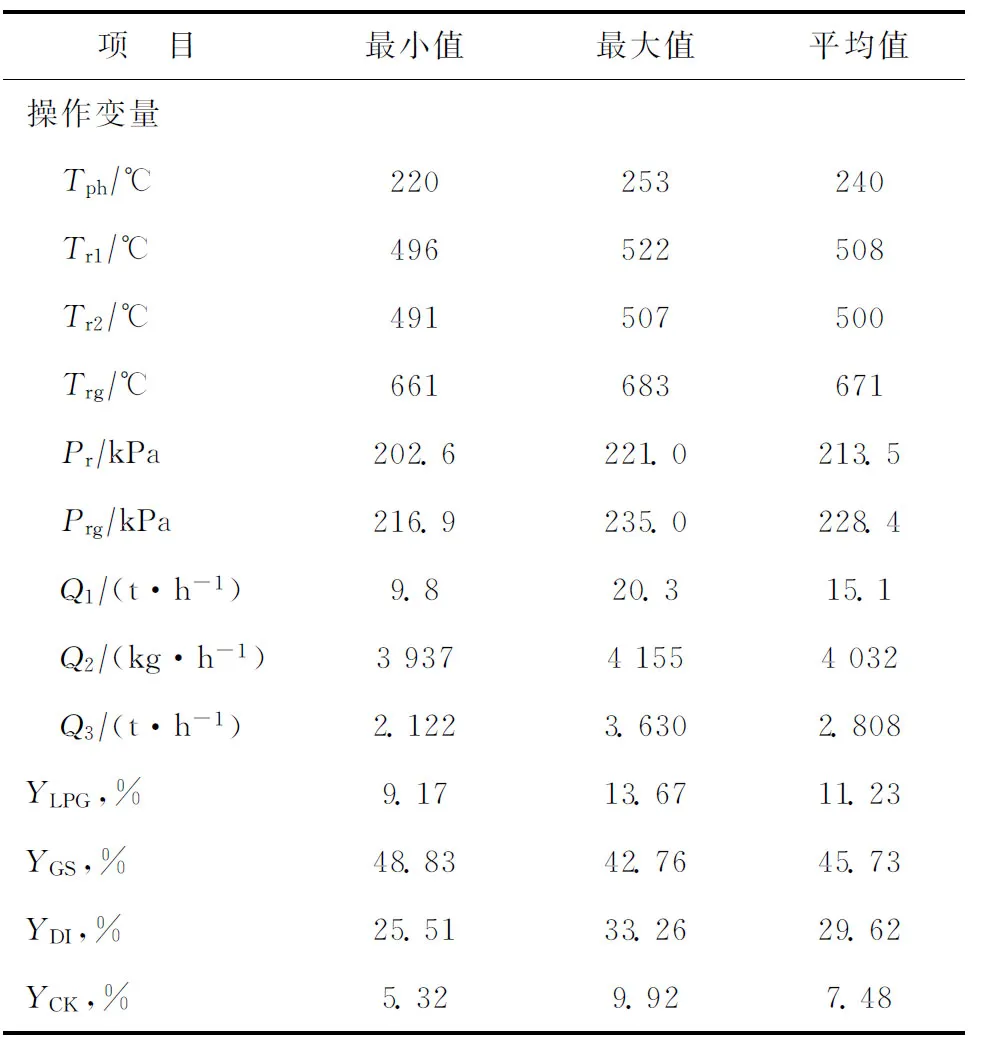
2 变量相关性分析
为了尽可能降低神经网络输入变量的维数,以及满足后续优化工作的前提,必须保证输入变量之间不相关或者相关性较弱。相关性检验方法普遍采用Pearson相关系数法[10-11],其数学表达形式为:
(1)
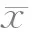

除了计算Pearson相关系数之外,还需要进行显著性检验,一般认为相关系数的假设检验P值不大于5%,则认为检验的两个变量的相关性显著成立;若P值大于5%,则认为检验的两个变量显著不相关。在Pearson法中,若相关系数为0,即相关关系不显著,检验t统计量服从自由度为n-2的t分布,其表达式为:
(2)
本研究采用SPSS软件分别计算原料油性质、再生催化剂性质和操作变量之间的Pearson相关系数(P<5%)。当P>5%时两变量之间无明显的相关性,Pearson相关系数计算结果如表4~表6所示。
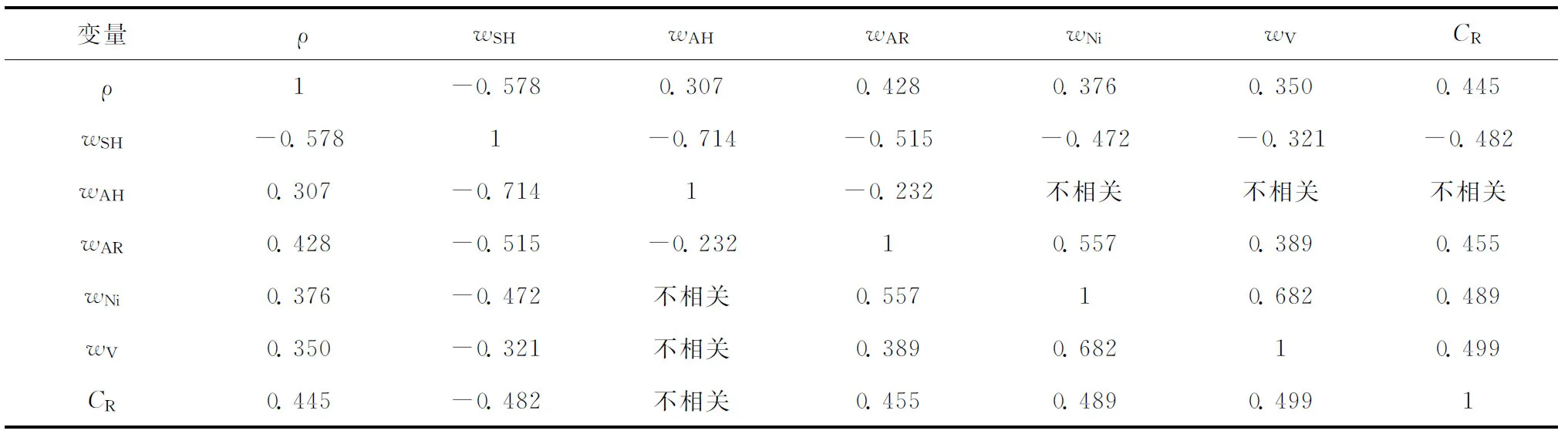
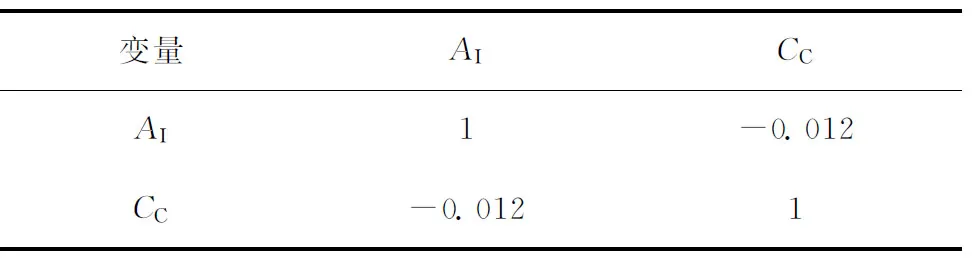
由表4可知,wSH与wAH的相关系数为-0.714,说明两者之间呈高度线性负相关,由于wSH、wAH和wAR之和为100%,因此,神经网络的建立可不考虑变量wAH。从表5可见,再生剂微反活性指数(AI)与再生剂炭质量分数(CC)之间呈低度线性负
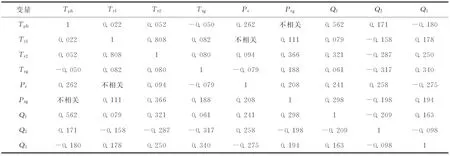
相关,这表明CC增加,则再生剂活性降低。从表6可以看出,除了原料油预热温度(Tph)与回炼油流量(Q1)呈显著线性正相关,一反出口温度(Tr1)和二反出口温度(Tr2)呈高度线性正相关之外,其余变量间均呈低度线性相关或者无明显相关性。Tr1和Tr2的高度线性正相关关系会极大地影响神经网络的学习以及后续优化工作,因此,取Tr2作为反应温度Tr,即:
Tr=Tr2
(3)
上述变量相关性分析共约简2个变量:芳烃质量分数(wAH)和一反出口温度(Tr1)。约简后,神经网络建模变量如表7所示,其中输入变量共16个,包括原料油性质6个、再生剂性质2个、操作变量8个,输出变量为4个主要产物(液化气、汽油、柴油、焦炭)的收率。
3 BP神经网络的建立
3.1 BP神经网络
BP神经网络一般是按照误差进行逆向传播算法训练的三层前馈神经网络,每层包含多个神经元,神经元主要是依据激励函数进行神经元计算结果的输出。常用的激励函数为S函数和线性函数,S函数方程式如式(4)所示。
(4)
S函数一般用于隐含层神经元的激励函数,它可以将神经元的输入范围从(-∞,+∞)映射到(-1,+1),其中x为输入值,f(x)为隐含层输出值。
线性函数方程式如式(5)所示。
g(x)=x
(5)
线性函数通常用作输出层神经元的激励函数,它是用来处理和逼近输入与输出的非线性关系[12],其中x为隐含层输出值,g(x)为输出层输出值。
3.2 BP神经网络模型结构
本研究采用L-M算法来训练BP神经网络[13]。采用214组样本,随机选择172组作为神经网络训练样本,其余作为验证样本,采用MATLAB平台来建立神经网络模型。
建立BP神经网络的关键是确定隐含层神经元的个数。神经元个数太多,训练时间长,还容易出现过拟合;神经元个数太少,学习效果差,训练次数必须增加。隐含层神经元个数计算式如(6)所示。
(6)
式中:H为隐含层神经元个数;m为输入层神经元个数;n为输出层神经元个数;L为1~10之间的常数。
由式(6)可以得到BP神经网络隐含层神经元的个数范围为[6,15],但由于BP神经网络的大量并行分布结构和非线性动态特性,实际计算隐含层神经元个数时往往难以取得理想效果。为寻找最优的网络结构,将隐含层神经元个数从6依次增加到25来建立相应的BP神经网络,并随机选择172组样本对BP神经网络模型进行训练,然后用其余的42组样本作为验证样本,对模型进行检验,比较每次验证样本的均方误差,结果见图1。从图1可见,最佳隐含层神经元个数为20,因此,本研究按16-20-4的结构来搭建BP神经网络。
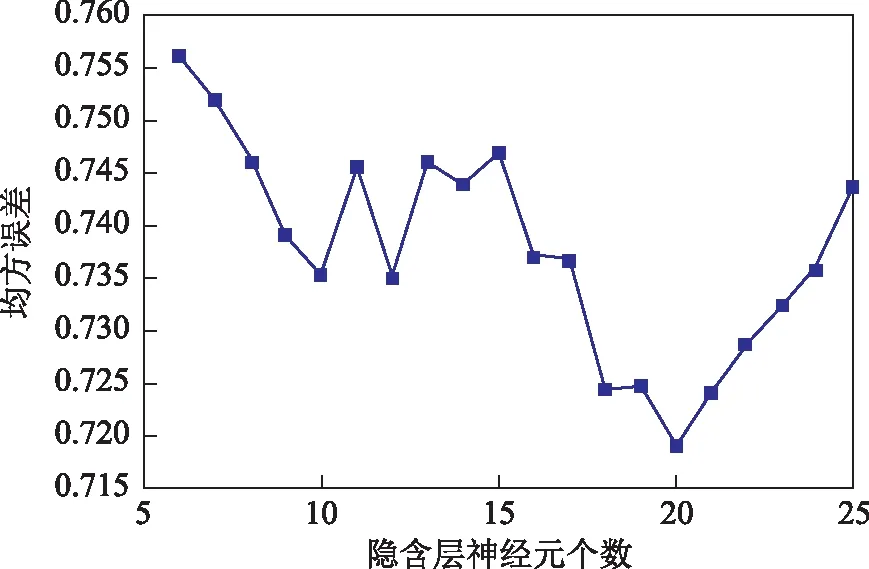
图1 隐含层神经元个数与均方误差的关系
3.3 BP神经网络预测结果
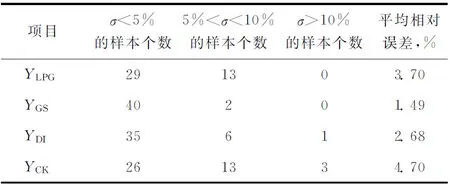
采用42组样本对所建立的BP神经网络进行验证,得到的相对误差(σ)见表8。由表8可以看出:相对误差小于5%的样本占多数;液化气和汽油收率的相对误差都小于10%;柴油和焦炭收率的相对误差只有4组样本超过10%;汽油收率的平均相对误差最小,其中只有两组样本超过5%,其余均未超过5%;液化气、汽油、柴油和焦炭收率的平均相对误差都小于5%,说明所建立的神经网络模型具有良好的预测性。
4 产品收率优化
4.1 汽油收率优化
以前面建立的BP神经网络为基础,采用遗传算法[14-15](Genetic Algorithm,GA)来优化汽油收率。个体编码方式为实数编码,每个个体均为一个实数串。在优化汽油收率时,采用20个初始种群,并设定进化代数为50。计算极值时将BP神经网络预测值作为个体适应度值,其计算式为:
Fi=yGS,i
(7)
式中:Fi为个体i的适应度值;yGS,i为神经网络模型对个体i的汽油收率预测值。
个体选择概率Pi的计算式为:
(8)
式中:Fi为个体i的适应度值;k为系数;N为种群数目;Pi为个体i的选择概率。
采用交叉操作来产生新个体[16],交叉概率为0.6~0.9;变异操作可以为种群提供新的基因,变异概率为0~0.1。本研究选择的交叉概率为0.6,变异概率为0.05。以36,39,42组验证样本的LIMS数据为基础,即在保持原料油和再生剂性质不变的情况下,寻找汽油收率最优时的操作条件。寻优区间为各变量的可操作范围,其数值和寻优结果见表9。从表9可以看出,通过操作条件的优化,汽油收率具有一定的上升空间。
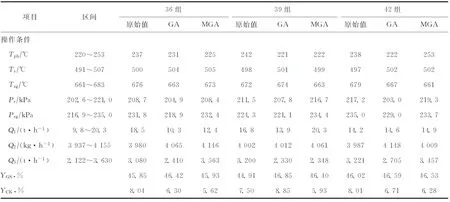
注:GA表示仅优化YGS,MGA表示同时优化YGS和YCK。
4.2 汽油收率和焦炭收率的同时优化
在上述优化汽油收率的过程中并未考虑对其它产品收率的不利影响,尤其是焦炭产率,虽然影响焦炭产率的主要因素是原料的残炭,但操作条件对生焦的影响也比较大。从表9可以看出,汽油收率提高后,第二组样本(第39组验证样本)的焦炭产率较原始值增大。因此,在提高汽油收率的同时需要考虑对焦炭产率的影响,这属于多目标优化问题[17]。
对于催化裂化反应-再生系统,最终的目标是要得到尽可能大的汽油收率和尽可能小的焦炭产率,相比之下,汽油收率相对重要些,所以整个优化问题就可以转变成多目标优化问题,可以采用如下数学描述:
maxf(xi)=YGS
(9)
(10)
f(xi)=N1(xi,2),g(xi)=N1(xi,4)
(11)
s.t.xi∈S
(12)
式中:xi为输入变量,共16个;S为可行域;N1为训练好的神经网络;N1(xi,2)表示汽油收率是神经网络4个输出值中的第2个输出值;N1(xi,4)表示焦炭产率是神经网络4个输出值中的第4个输出值。
在汽油收率和焦炭收率多目标优化的过程中,神经网络N1采用前面训练好的BP神经网络;可行域S为操作变量的范围,其中原料油性质和再生剂性质的值保持不变,操作条件的变化范围与仅汽油收率寻优时一样,遗传算法参数设置和GA单纯优化汽油收率不一样的是进化的代数由50变为100。
同样以36,39和42组验证样本的LIMS数据为基础,汽油收率和焦炭产率的多目标寻优结果见表9(MGA表示同时优化汽油收率和焦炭产率)。由表9可知:第36组验证样本多目标优化与单纯的优化汽油收率相比,反应温度上升,回炼油量增加,汽提蒸汽量增加,这有利于增加汽油收率,而反应温度的上升和回炼油量的增加也会导致焦炭产率的上升,但是预提升蒸汽量的增加会降低原料油的反应深度,从而减少汽油和焦炭产量,优化的结果是回炼油增加以弥补反应深度降低的影响,同时汽提蒸汽量的提高也会减少焦炭产率,因此总体来说,多目标优化的结果是汽油收率降低,而焦炭产率大幅度降低;第39组验证样本多目标优化结果是:降低反应温度,提高反应压力,同时增加汽提蒸汽量有利于减少生焦;第42组验证样本多目标优化结果是:原料油预热温度有较大幅度的上升,这有利于原料油的雾化,使原料油与催化剂的接触更充分,可减少生焦。但是原料油预热温度的大幅提高意味着再生温度的降低,这样才能保证反再系统的热平衡维持在一定的范围内,同时预提升蒸汽量增加,反应深度降低,所以与原始值相比,虽然汽油收率略有下降,但焦炭产率明显降低。虽然多目标优化后的汽油收率比单目标优化后的汽油收率略有减小,但是焦炭产率有较大幅度下降,优化结果比较理想。
5 结 论
(1)采用Pearson相关系数法约简了原料油中芳烃含量和操作变量中一反出口温度2个变量,降低了神经网络模型输入变量之间的相关性和输入变量的维数。
(2)以约简后的16个变量为基础,建立了16-20-4的BP神经网络模型,模型具有良好的预测性。
(3)所建立的BP神经网络模型与遗传算法相结合优化了仅汽油收率最大和汽油收率最大+焦炭产率最小时的操作条件,这些操作条件与催化裂化的工艺实际情况相符。与单纯优化汽油收率相比,多目标优化虽然汽油收率略有下降,但是焦炭产率显著降低,对于实际生产操作的优化具有较大的指导意义。
