基于聚类判别模型的网约车鉴别研究
2018-08-03冷婷闫兴秀余健谈炜孙娴
冷婷 闫兴秀 余健 谈炜 孙娴
南京华苏科技有限公司
0 引言
在“互联网+”的政策背景和市场推动下,网约车作为一种新兴出行用车方式,迅速成为市场的宠儿,成为智慧出行的重要组成部分。
网约车即网络预约出租汽车,是一种将乘客、司机与车辆连接起来,乘客通过智能手机应用软件,预约司机接送服务的出行方式。网约车的出现,满足社会公众多样化出行需求,提升了机动车的利用效率,但是随着网约车规模的不断扩大,它带来的一系列社会监管难题也是不容忽视的。
网约车与传统的出租车既有区别又有联系。在车辆颜色与车型上,出租车一般有统一的颜色与标识,网约车则多种多样。在运营方式上,出租车可以巡游揽客、站点候客和预约接客,而网约车不可以巡游接客,只能通过网络平台为预约顾客提供服务。在监管上,出租车一般由出租车公司进行统一管理,而网约车则缺乏一定的监管机制。
初期,网约车是对出租车的补充。随着网约车专职司机的增多,网约车对传统出租车行业形成了一定的冲击,遭到了出租车司机一定程度上的抵制。此外,由于网约车平台对司机和车辆的审查并不严格,市场乱象丛生,纠纷、事故等社会问题层出不穷,网约车市场亟需规范管理。
为了管理网约车市场的乱象,《网络预约出租汽车经营服务管理暂行办法》1http://www.miit.gov.cn/n1146295/n1146557/n1146624/c5218603/content.html于2016年11月1日起施行。其中明确规定了,在运营服务中,驾驶员不得在街上巡游揽客,不应在机场、火车站等设立统一巡游车调度服务站或实行排队候客的场所揽客。
在网约车营运新规出台的大背景下,交通局作为公共出行服务管理机构,必须加强对网约车的管理。目前对网约车的管理方式是通过人工巡查的方式来进行,但这样耗费了大量的人力,因此,交通局迫切需要一种自动化的筛选方式,来帮助他们锁定嫌疑车辆,实现快速高效的执法。
手机作为现代人生活的必需品之一,与人的活动密不可分,这让使用移动运营商的数据来映射每个司机的移动行为成为可能。
出租车司机一般与出租车公司签订合同,进行手机号等个人信息备案。因此,出租车司机比较容易被辨识。但是,由于网约车司机手机号变更、一人多机等情况的客观存在,以及网约车司机个人信息的难以获取,这使得网约车司机的识别任务变得困难。
本文以手机的信令数据为基础,提取出司机的移动特征,提出了一种基于聚类的判别模型来鉴别网约车司机。该模型能够在仅知一类数据标签的情况下,判别出未知标签的数据是否归属于已知类别。
1 研究现状
网约车作为新生事物,大多学者主要把研究视角集中于网约车的监管与管理对策上,主要关注网约车平台的定价策略,使用了波动支持向量机(wave SVM)模型来预测短期内的交通需求,并据此为网约车App提供一个更加动态的需求共享平台,以保障乘客无论在何时何地都能够获取网约车提供的出行服务。以上的研究仅仅涉及了如何提升网约车的服务上,缺乏相对有效的方法把网约车快速地识别出来。
在运用大数据为交通管理服务的研究方面,大多基于GPRS的定位数据,多涉及出行目的地的预测、区域内出租车服务比率的预测应用,使用的机器学习算法主要有决策树、神经网络、支持向量机等。以上的研究利用了大数据的技术与算法,但还没能够应用到网约车识别的领域。
总的来说,国内外还缺乏一种行之有效的,使用手机信令数据,利用机器学习算法来鉴别网约车的方法。因此,本文将做初步尝试,在仅有出租车司机一类用户标签的情况下,对包括出租车与网约车混合用户的数据集进行类别判断,判别出的结果可以为网约车的监管服务。
2 数据描述
本文所分析的样例司机用户基于以下3个原始数据集:

表1 样例司机用户原始数据集表
出租车司机用户数据集为D,是数据集A、B、C的交集:

在数据集D中,随机抽取150个已知出租车司机用户作为样本集M。

数据集E是数据集C与数据集D的差集,其中包括了均使用智能手机应用软件提供出行服务的网约车司机和出租车司机。
在数据集E中,随机抽取150个未知类别的司机用户作为样本集N。
3 特征抽取
抽取以上300个用户2017年3月6日至3月19日之间两周的信令数据作为特征抽取的原始数据。
定义周一至周五的9∶00-17∶00为忙时,周一至周五17∶00-24∶00 和 0∶00-9∶00 为闲时。
抽取的特征主要包括小区切换和驻留时长两大类,如表2所示:
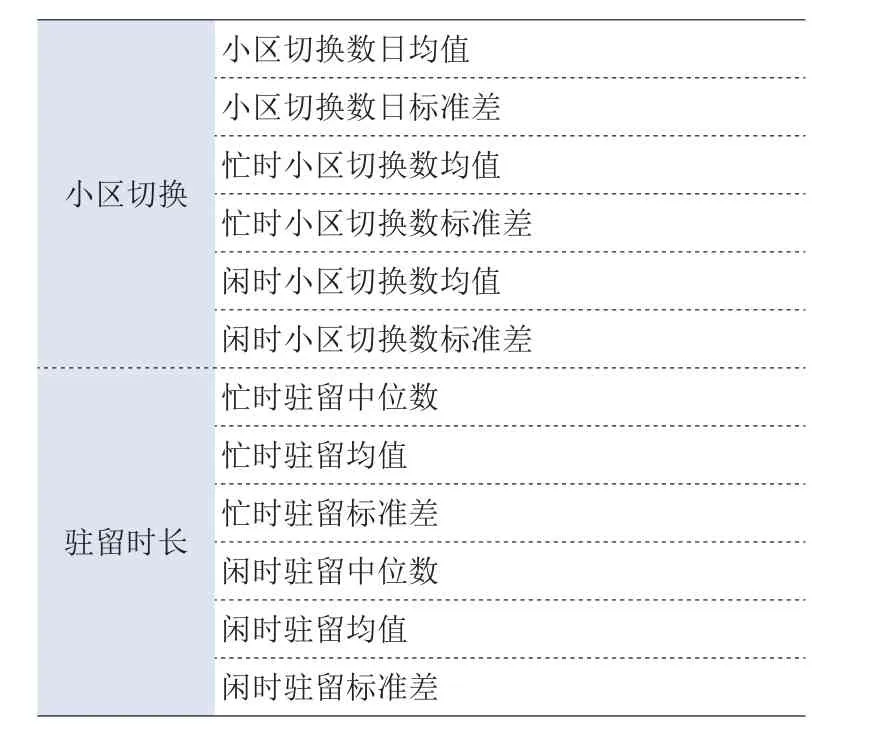
表2 特征抽取类别表
提取以上特征后,通过选取任意2维特征绘制散点图,如图1、2所示:
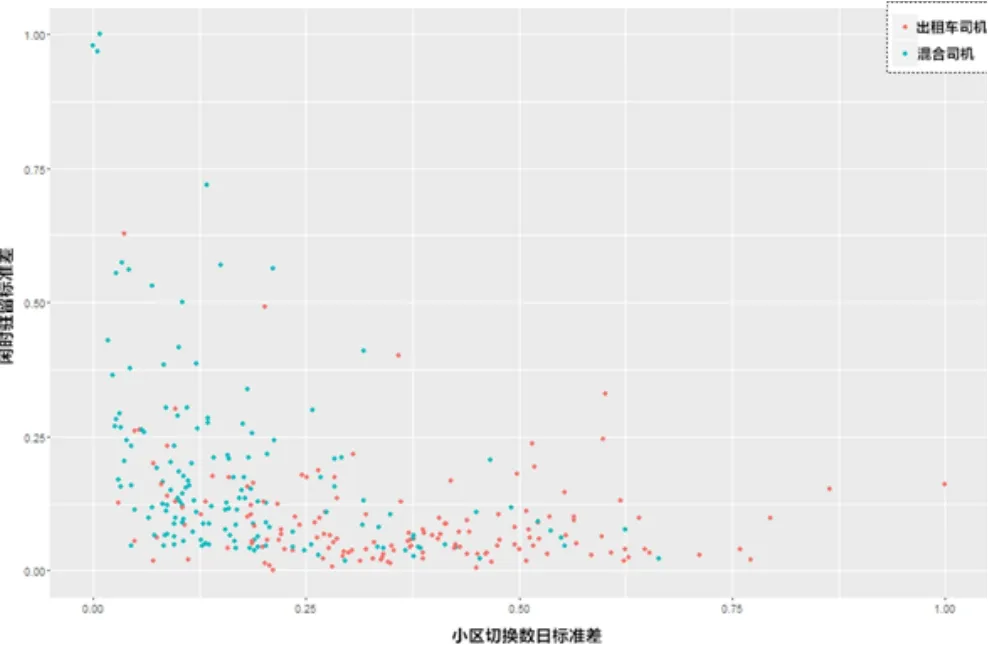
图1 小区切换数日标准差和闲时驻留标准差二维特征散点图
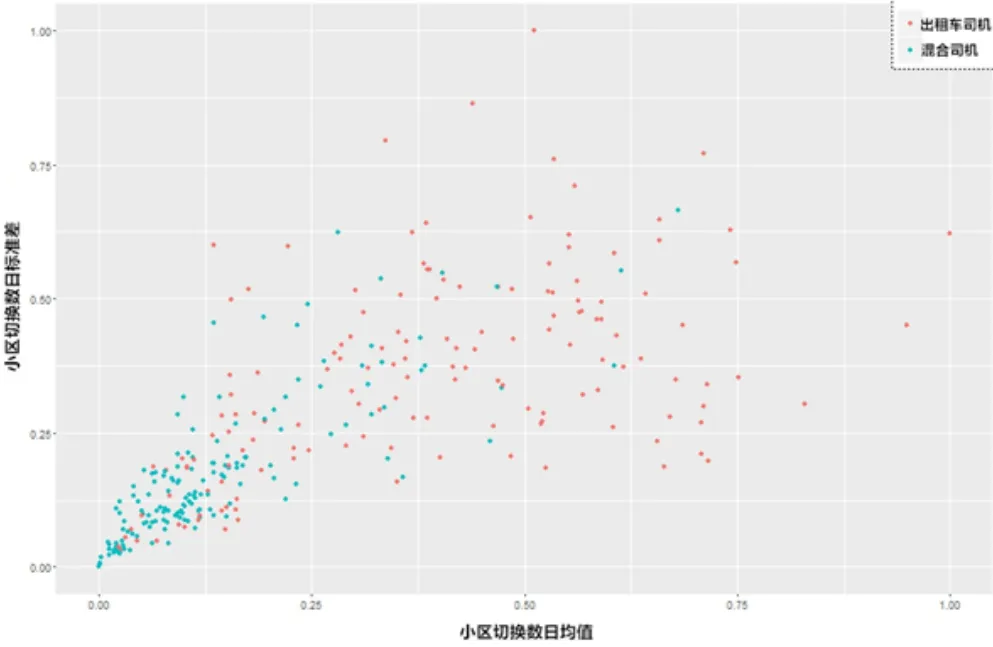
图2 小区切换数日均值和小区切换数日标准差二维特征散点图
图1中,横坐标表示标准归一化后的小区切换数日标准差特征,纵坐标表示标准归一化后的闲时驻留标准差特征;图2中,横坐标表示标准归一化后的小区切换数日均值特征,纵坐标表示标准归一化后的小区切换数日标准差特征。红色的点表示样本集M,即出租车司机,蓝色的点表示样本集N,即未知类别的司机用户;通过图1和图2,直观上,样本集M与样本集N的分布存在一定的差异性,从侧面说明特征在一定程度上反映了两类司机的行为差异。
4 特征分析
t-SNE(t-Distributed Stochastic Neighbor Embedding) 是由Laurens van der Maaten和 Geoffrey Hinton提出一种流形的(Manifold)数据降维的方法。它是在SNE的基础上发展而来的,在低维空间下使用更重长尾分布的t分布来避免crowding问题和难以优化的问题。
该算法先将欧几里得距离转换为条件概率来表达点与点之间的相似度。给定一个N个高维的数据x1,…,xN,计算概率pj|i为:

对低维度下的y_i,使用t分布后的两点相似度为:

优化的梯度为:

使用t-SNE对特征进行降维可视化:

图3 t-SNE维度特征图
图3中,红色的点表示样本集M,即出租车司机,蓝色的点表示样本集N,即未知类别的司机用户。从图3的可视化结果可以看出,基于选取的特征,两类司机的分布存在一定的差异性。
5 建模过程与结果分析
采用基于聚类的判别模型来鉴别未知的司机用户为出租车司机还是网约车司机,具体的分析流程如图4所示。
将样本集M按照8∶2随机划分为聚类训练集P与验证集Q,将样本集N作为测试集N。

图4 聚类判别模型分析流程图
对于训练集P:
第一步,进行特征数据的获取并标准归一化;
第二步,判断数据集的最佳聚类数K;
第三步,删除异常样本点;
第四步,计算聚类中心点;
第五步,计算各个样本点到各个聚类中心点的距离之和;
第六步,设定类别判定的阈值。
对于验证集Q与测试集N:
第一步,进行特征数据的获取并标准归一化;
第二步,计算数据集中各个样本点到训练集各个聚类中心点的距离之和;
第三步,根据阈值进行判断,并输出判别结果。
5.1 聚类数选择
对于训练集P,使用轮廓系数(Silhouette Coef fi cient)计算最佳聚类数K。轮廓系数是类的密集与分散程度的评价指标。
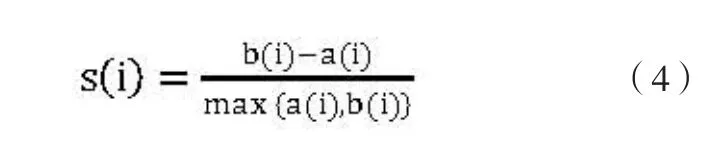
其中:
a(i)为i向量到同一簇内其他点不相似程度的平均值,即测量了组内的相似度。
b(i)为i向量到其他簇的平均不相似程度的最小值,即测量了组间的相似度。
s(i)的范围从-1到1,值越大说明组内内聚度和组间分离度相对较优。

图5 最佳聚类K判断图
图5中,横坐标表示不同的聚类数K,纵坐标表示轮廓系数。当聚类数为3时,s(i)的值最大。因此,取最佳聚类数K=3。
5.2 聚类分析
使用K-Means算法对训练集P进行聚类分析。
K-Means属于划分式聚类算法,聚类相似度是利用各聚类中对象的均值所获得一个中心来进行计算的。其主要工作过程为:首先从n个数据对象中任意选择k个对象作为初始聚类中心,对于所剩下的其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般使用均方差作为标准测度函数。
将训练集P聚成3类,得到的聚类结果如图6所示。

图6 训练集聚类结果图
在以上聚类结果的基础上,对异常点进行处理,得到108个有效采样点。其主要分布情况如表3所示。
如图7所示,由此,对于每个聚类簇,可得中心点所对应的每个维度特征值。

图7 聚类簇维度特征值图
5.3 用户行为特征分析
以特征为横坐标,特征值为纵坐标,绘制折线图,查看三个聚类中心点的分布,如图8所示。

图8 聚类中心点分布图
由图8可知,以上三个聚类簇在6个指标上差异性较大:忙时小区切换数均值,忙时小区切换数标准差,闲时小区切换数均值,闲时小区切换数标准差,小区切换数日均值,小区切换数日标准差。
分别绘制三个类别样本在以上6个特征上的分布箱形图(见图9)。
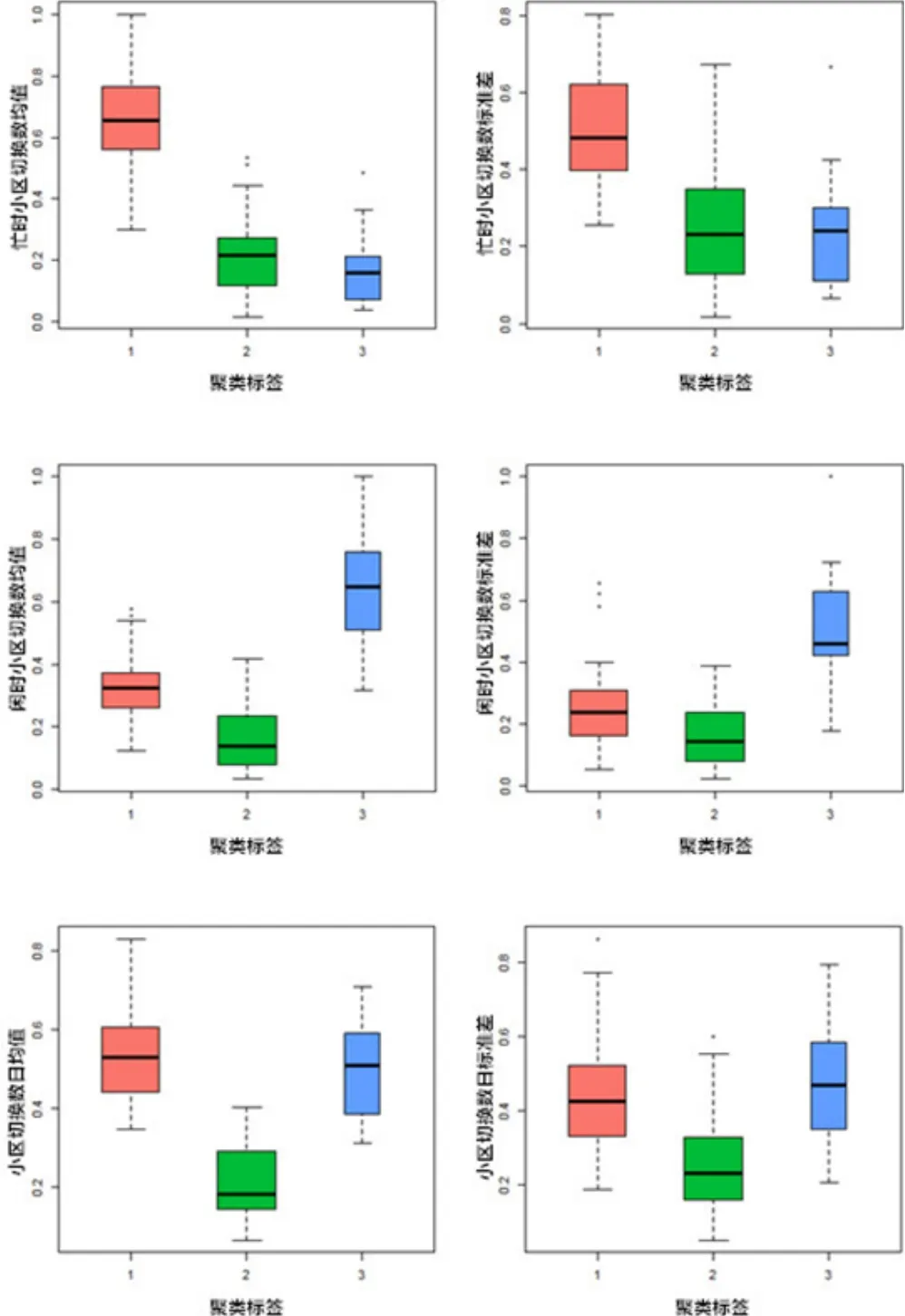
图9 特征分布箱形图
图9中横坐标为各个类别,每个箱形的下边缘表示最小值,上边缘表示最大值,箱子的底部表示四分之一分位,箱子的顶部表示四分之三分位,箱子中间的线表示中位数。箱子的宽窄表示了该类别样本数的多少。总的来说,箱形图表示了各个类别中样本的分布情况。
可以看出,在上述的6个特征上,cluster1与cluster2的整体趋势比较相近,且cluster2对应的特征值均低于cluster1相对应的特征值;但cluster3和cluster1在趋势上整体相反。具体来说,有以下几点:
(1)对于cluster1中的司机,有以下结论:
忙时小区切换数均值指标最高,说明该类出租车司机在周一至周五的9∶00-17∶00,即白天活动最为频繁;闲时小区切换数均值指标较低,说明该类出租车司机在周一至周五17∶00-24∶00和0∶00-9∶00,即夜间活动较少;小区切换数日均值指标最高,说明该类出租车司机整体活动较为频繁。因此,该类出租车司机是具有典型出租车活动行为特征的司机。
(2)对于cluster2中的司机,有以下结论:
忙时小区切换数均值指标较低,说明该类出租车司机在周一至周五的9∶00-17∶00,即白天活动不太频繁;闲时小区切换数均值指标也较低,说明该类出租车司机在周一至周五17∶00-24∶00和0∶00-9∶00,即夜间活动也不太频繁;小区切换数日均值指标同样较低,说明该类出租车司机的整体活动不频繁。可以看出,该类出租车司机切换小区次数相对较少,也就是说更偏向于在某些区域进行驻留待客,因此,从行为特征的角度来说,和网约车司机驻留待客的行为比较类似。
(3)对于cluster3中的司机,有以下结论:
忙时小区切换数均值指标较低,说明该类出租车司机在周一至周五的9∶00-17∶00,即白天活动不太频繁;闲时小区切换数均值指标较高,说明该类出租车司机在周一至周五17∶00-24∶ 00和0∶00-9∶00,即夜间活动比较频繁;小区切换数日均值指标较高,说明该类出租车司机的整体活动趋于频繁。可以看出,该类出租车司机具有昼伏夜出的特点,因此,从行为特征的角度来说,和典型网约车司机昼伏夜出的特点也比较类似。
总体来看,cluster1中的用户具有典型的出租车司机行为特征,cluster2和cluster3中的用户虽然是出租车司机,但在行为特征上和网约车司机比较类似。
5.4 阈值设定
计算训练集P中各有效样本点x到各个中心点的距离之和,并排序,绘制增量图,如图10所示:

图10 样本点到各中心点距离之和增量图
图10中,x轴表示训练样本序号,y轴表示样本点到各个中心点的距离之和。
由图可看出:
当x < 101时,距离的增长速度较为平缓;
当x > 101时,距离的增长速度较快;
由此得出:
x = 101为样本集中的拐点。因此,将其对应的距离,即y值设置为分类的阈值:

5.5 结果输出
对既包含网约车司机又包含出租车司机且没有类别标签的混合数据集,本文采用以上基于聚类和阈值相结合的方法来判断未知标签的样本的类别归属。
当测试集中的样本点到三个聚类中心点的距离之和大于阈值时,即判断该样本点为网约车司机,反之,则判定该样本点为出租车司机。
对验证集Q和测试集N进行判定,得到的结果如表4所示:

表4 聚类模型判定表
(1)由此可见:
对于验证集Q中的30个样本,根据该模型判断,有23个司机用户属于出租车,取得了76.7%的召回率。
对于测试集N中的150个样本,使用基于聚类的判别模型,发现有97个司机用户属于出租车,即64.7%的司机被判别为出租车司机,35.3%的司机被判别为网约车司机。
(2)更进一步:
对测试集N中被判定为出租车的97个用户,根据其到三个中心点的距离进行分类,得到进一步的分类结果,汇总结果如表5所示:
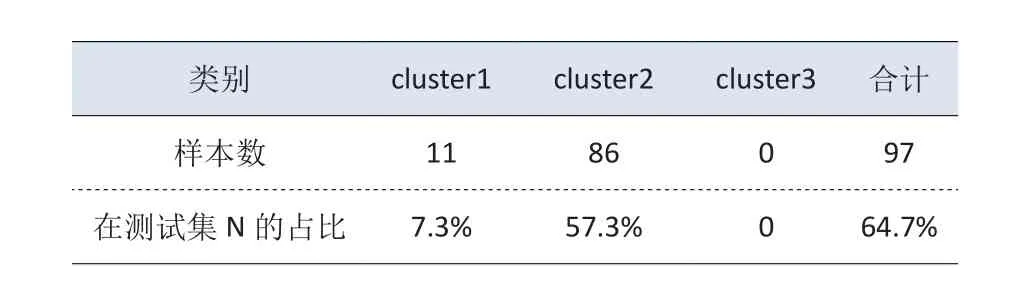
表5 中心点距离阈值判定表
因此,由以上分类结果可以看出,测试集N中仅仅7.3%的司机为典型的出租车司机,57.3%的被判断为出租车的司机在行为特征上和网约车司机较为类似。
6 结论与改进措施
本文利用移动运营商提供的手机信令数据,提取出可以映射司机移动行为的特征,并提出了一种基于聚类判别的模型,在拥有出租车司机单类别标识样本的情况下,对出租车与网约车混合用户的数据集进行类别归属的判断。鉴别出的结果在一定程度上能够为交通执法部门打击非法网约车进行服务,帮助他们快速定位嫌疑车辆,降低执法的人力成本,提升工作效率。
本研究是使用手机信令大数据与机器学习算法模型对网约车司机进行判别的初步尝试,还存在一些不足。例如受用户样本数所限,建模的数据规模还偏小。未来的研究中还有一些问题需要解决和改进:增加除了移动行为特征外的其他数据特征,如主流的、提供预约出行服务的手机App使用数据;增加对比样例,提升分析结果的置信度。
