基于用户位置信令在城市交通规划中应用的大数据模型挖掘
2018-08-03赵越王瑜孙宏刘芳琦鲍丽娜兰婷
赵越 王瑜 孙宏 刘芳琦 鲍丽娜 兰婷
中国联合网络通信股份有限公司江苏省分公司
0 引言
随着我国社会经济快速发展和人民生活水平不断提高,我国城市化发展进程加快,城市人口的增长、机动车拥有量的增加、城市形态的变化以及社会活动数量和规模的增加给国内的大、中城市的交通状况及其管理系统增加了越来越重的负荷,交通需求与供给之间的矛盾也变得越来越突出,因此需要大力推进城市交通信息化的发展。
另外一方面,随着智能移动终端的普及,运营商手中实时采集海量用户信令数据,通过这些用户信令信息可以对用户进行精准定位,从而实现对OD矩阵、居住地就业岗位分布、客流集散地人流数据的分析。
1 定位算法模型研究
1.1 基于MR三角定位算法
终端与小区间距离的计算是定位算法准确与否的关键因素。Tadv(时间提前量)是网管直接统计的由于终端与基站间距离导致的时间差,不受阴影衰落与穿透损耗等因素影响,精度更高。因此在LTE MR数据中,主服务小区Tadv,尽量都用Tadv计算得到距离;在主服务小区没有Tadv的情况下,才用RSRP测算距离。
MR中Tadv取值0~1282,1个Tadv等于78米,因此距离= Tadv值×78米
MR中的邻区由于没有Tadv,因此只能用RSRP计算距离。采用RSRP计算距离的方法分为2类,如下所述:
(1)FDD:参考信号功率(dBm)= dlRsBoost + pMax/10 -Round(10 × Log(dlChBw/10 × 5 × 12) / Log(10), 2)
(2)TDD:参考信号功率(dBm)= dlRsBoost + pMax/10- Round(10 × Log(ChBw/10 × 5 × 12) / Log(10), 2)
根据链路预算公式,可通过路径损耗计算得到接入距离:
S=10^((路 径 损 耗 (dB)-161.04+7.1×LOG10(20)-7.5×LOG10(20)+(24.37-3.7×(20/天 线 挂 高 (m))^2)×LOG10(天线 挂 高 (m))-20×LOG10(频 点 (GHz))+(3.2×(LOG10(11.75×UE 高度 (m)))^2-4.97)+3×(43.42-3.1×LOG10(天线挂高 (m))))/(43.42-3.1×LOG10(天线挂高(m))))
其中,路径损耗计算如下:
路径损耗(dB)= 参考信号发射功率(dBm) -参考信号接收电平RSRP(dBm) -穿透损耗(dB) -阴影衰落(dB))-基站馈线损耗(dB) +基站天线发射增益(dBi)+终端天线接收增益(dBi)-终端接收线缆与人体损耗(dB)。
(1)判断采样点的各导频中(包含服务小区和邻小区)RSRP最强的导频是否为室内小区:若是,则直接将采样点定位在室内小区所在的位置半径50米内随机撒点;若否,则采样下述定位算法进行定位。
(2)对于室外定位,是一个平面几何问题,关键点在于在平面上确定一点的信息量是否充足。
(3)对于不重合点小于3个的情况,在平面上确定一点的位置是“信息不充分的”,因此需要结合小区天线方位角作最大可能性判定,本算法中用算法拟合选取的规则,以可能的位置点来作为定位点。
(4)对于不重合点大于等于3个的情况,信息量是冗余的,可以充分的利用信息的冗余量,求出趋近于真实点的位置。不同算法的关键在于用冗余数据修正数据准确性方式的不同。其中,最小二乘法是数学上比较好的逼近方法。
(5)已知n个节点的坐标,及它们到未知节点D的距离,确定节点D的坐标。
1.2 基于OTT位置GPS数据定位
(1)关键字匹配算法
不同APP的HTTP表头中URI包含的经纬度信息表达方式不尽相同,传统处理方式是对关键字逐项迭代匹配,找到表头经纬度字段提取,单条记录多次匹配,如图1所示。
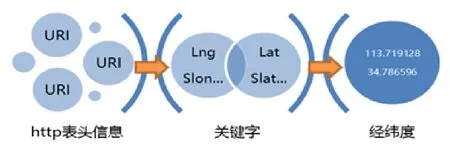
图1 关键字匹配算法图
(2)特征数据匹配算法
考虑关键字匹配算法的局限性,进行改进研究,引入特征数据匹配算法,根据URI数据结构进行经纬度特征数据值匹配(例如长春市边界为:(127.05~124.6,45.2~43.29)数据只需进行N次特征匹配就能定位到经纬度信息,如图2所示。
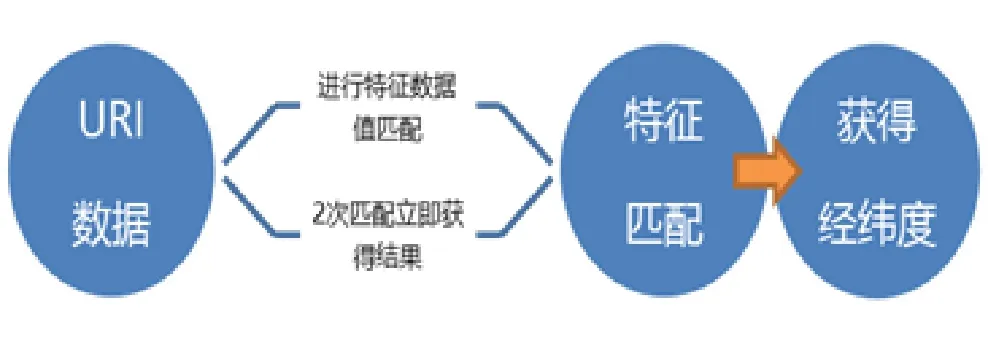
图2 特征数据匹配算法图
2 城市规划数据模型建立
2.1 城市网格化实现方案
在用户位置数据挖掘前,首先需要对城市进行网格化分,将城市按照相应算法切割成足够小的网格,对应可以将用户位置规整地划分到分解的网格中。Geohash算法其实就是将整个地图或者某个分割所得的区域进行一次划分,由于采用的是base32编码方式,即Geohash中的每一个字母或者数字(如wx4g0e中的w)都是由5bits组成(2^5 = 32,base32),这5bits可以有32种不同的组合(0~31),这样我们可以将整个地图区域分为32个区域,通过00000 ~ 11111来标识这32个区域,可以根据需要进行多次划分,根据GEOHASH编码不同精度,计算出来的网格大小不同。
本文采用将用户经纬度数据进行GEOHASH编码,然后按七位归类划分网格。有一个重大缺点就是GEOHASH不能实现所有最近位置编码前辍越接近的规律,而出现相离几米的用户出现在两个网格中。我们系统的实现时,采用地图系统对小区进行PIO、AIO取样分析,然后通过磁力聚合原理,将相同属性,相近距离的小区划成一组网格,最近通过中心点计算,最后形成网格,这样在位置分析时,网格更有意义,路径计算也更加合理。
2.2 位置数据模型构建方案
城市规划中,按目标人群分为工作地和居住地。工作地、居住地可以根据时间维度、驻留维度进行划分。工作地居住地的提取是位置分析里一个比较基础与重要的功能,算法上可以采用简单的方式通过上下班时间归类提取数据满足一些需求。职住数据也是很多其他位置分析的基础数据,如果质量不好,直接影响其他业务的分析结果,不管其他业务的算法有多好。在较高数据精度需求中,就需求改进、优化职住地址提取算法,并加入机器学习算法。上下班时间段停留数据作为基本的数据,系统在以下几个方面做了算法优化处理:家庭地址变化识别及快速切换,公司地址变化识别及快速切换,中长期出差人员识别及历史数据保留,无职人员识别,办公及生产区域识别,居住小区识别,在职人员活跃度识别,加班人员识别。
以上所有算法都比较复杂,并需要很大的计算资源,所有识别过程采用机器学习,数据逐步修正与完善,后期的准确性都建立在前期的学习模型上。由于通信业务白天是高峰期,晚上数据量比较少,系统在资源分配及编排上,晚间启动更多的学习进程,保证不影响每10min粒度的报表数据输出。
(1)人员工作地分布情况
工作地计算口径:最近30天内,在工作日(周一~周五)的工作时间段内(10:00~16:00),在网格内停留时长大于3小时的天数〉=15天的目标,且工作日(周一~周五)的休息时间段内(22:00~05:00),在网格内的停留时长大于3小时的天数<=8天,则判断目标的工作地在该网格。
(2)人员居住地分布情况
居住地计算口径:最近30天内,在工作日(周一~周五)的工作时间段内(10:00~16:00),在网格内停留时长大于3小时的天数<=8天的目标,且工作日(周一~周五)的休息时间段内(22:00~05:00),在网格内的停留时长大于3小时的天数>=15天,则判断目标人员的居住地在该网格。
(3)居住地工作地人员迁移情况
出发时间:早晚高峰时,最后一次离开O的时间
到达时间:早晚高峰时,第一次到达D的时间,若无则默认为凌晨0时起每5min作为一个时间间隔,统计在这5min内从O出发的用户,最终到达D,每条轨迹的人数,所用时间分布等信息;
早高峰:6:30~9:30
晚高峰:17:00~19:30
加班时段:21:30~24:00
(4)网格内人员迁移情况
统计每个网格当前的用户,10min后的分布情况,以及到达用时,在当前网格逗留时长。
(5)区域实时人数
统计每10min内,当前区域下用户数。
(6)人员迁移路径
统计口径:6∶30~21∶30 之间{网格 ID1,…,网格IDn}:到达时间:离开时间。
2.3 基于流式大数据处理机制
位置数据是一组顺序、大量、快速、连续到达的数据序列,一般情况下,数据流可被视为一个随时间延续而无限增长的动态数据集合。
普通流数据具有四个特点:
(1)数据实时到达;
(2)数据到达次序独立,不受应用系统所控制;
(3)数据规模宏大且不能预知其最大值;
(4)数据一经处理,除非特意保存,否则不能被再次取出处理,或者再次提取数据代价昂贵。
用户信令数据流的独特性主要有:
(1)数据相对实时性;
(2)数据到达次序在短周期内无顺序性;
(3)数据规模宏大,但由于用户数与每天的使用频率有一定规律,数据能够进行估算。
(4)在进行位置分析时,由于算法复杂,并且要求较快的处理速度,中间数据不能采用
普通方式进行存储。
流式大数据处理框架:
(1)Apache Storm,在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑。这个拓扑将会被提交给集群,由集群中的主控节点分发代码,将任务分配给工作节点执行。
(2)Apache Spark Streaming,核心是Spark API的一个扩展,在处理前按时间间隔预先将其切分为一段一段的批处理作业。
通过对当前业务系统的分析,都不太适合需求,原因如下:
(1)系统结构复杂;
(2)部分不太完善,实际使用中有不少BUG;
(3)不适合进行位置路径处理;
(4)当前业务分析时带有庞大的内存数据,不适合分布方式高速处理,能发低下;
(5)完成本业务需求中的数据需要庞大的计算机硬件资源;
结合位置信令特点,此次数据模型挖掘采用基于容器技术的微服务系统,平台采用Golang开发的微服务系统再运行于基于Kubernetes加框的容器系统中完成流数据处理及其本业务系统中的所有服务。
由于位置信令流的独特性,在流式处理前,需要进行一次基于内存计算的预处理。信令信息数据收集过程中,在5-10min内的数据,上无序数据,在进行流式处理前,需要对数据进行准确性排序处理,由于数据量非常大,系统采用10min延迟入库,按分钟切片排序,然后再汇合成正确时序的数据流。
2.4 位置信令数据抖动处理
何为抖动,指某用户在两个或多个小区基站中间时,可能由于无线信令原因,或者其在一个小小范围的距离之间移动时,会频繁的产生不同的位置信令,我们在对网格进行磁力聚合处理后,会自动处理部分数据,但不能完全达到合理,我们通过对该用户的持续位置采样,能够分析出该用户的信令特征,如果数据抖动注册时,能够将抖动产生的信令数据进行过滤,保证用户路径的稳定性与合理性。
抖动数据处理学习服务。在抖动处理中,利用了机器学习技术,系统能够完成该区域多用户持续性采样学习,从而进行更准确的数据处理。
数据处理的过程就也是学习的过程,随着系统不停运行,数据处理能够得到持续优化。
当然这个学习过程也是非常耗费计算资源的,这里也充分地展示了基于弹性微服务架构的一个优势,在流处理时,将初步判断有抖动嫌疑的数据送到一个学习微服务,这个微服务可能在云计算中的其他节点,学习后的结果再阶段性加入到流处理过程中。当学习负荷比较大时,可以按预先进行的容器编排设置启动多个学习服务,学习服务负荷小的时间,再把资源释放出来。还有一个重要的容错特征,系统始终会保持一个或多个学习服务,即使其中一台主机崩溃时,也会在短时间不到1min内在其他主机自动部署新的学习服务。
3 总结与展望
通过将挖掘后数据进行整合呈现,实现了交通OD的全局实时感知,可以细化到每个OD每条道路,每个交通小区,实现对交通治理的数据决策支撑。通过数据挖掘,某地市出行距离在5-10km的人群最多,达到32%,私家车出行的比例达到48%。

图3 城市数据大脑—交通态势实时感知图
通过一个月内人员出行轨迹的分析计算,可得出公交快7线路的运力配置与客流高峰分布有差异。快7沿线职住分布及客流覆盖率如下图:

图4 快7沿线职住分布及客流覆盖率图
快7沿线客流总需求及公交运力时间分布(早高峰)如下图:
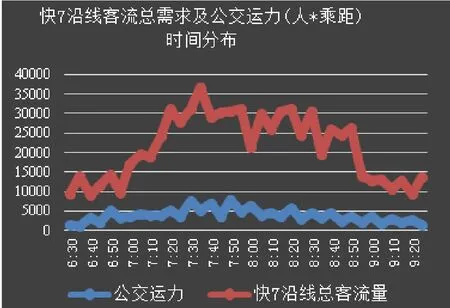
图5 快7沿线客流总需求及公交运力时间分布(早高峰)图
