用R语言分析关键词集共现网络研究
2018-07-26王婧怡江苏大学科技信息研究所江苏镇江212013
袁 润 李 莹 王 琦 王婧怡(江苏大学科技信息研究所,江苏 镇江 212013)
网络是相互连接的事物的集合。为了科学地研究网络,数学家利用图(Graph)这一术语来形式化地描述网络,从而派生了网络分析理论。网络分析的萌芽可以追溯到1735年欧拉对著名的柯尼斯堡七桥问题的求解。此后,网络分析便在很多领域得到了应用和发展。科尼希系统地奠定了网络分析的数学基础;基尔霍夫利用网络分析解决了复杂电路的计算和分析难题;凯莱借助网络分析理论开展了分子结构的研究工作[1]。与此同时,社会学家利用网络展现社会群体中的互动关系,运用网络分析量化研究社会结构问题,从此产生了社会网络分析这一独特的学术领域。
20世纪90年代以来,由于统计学和计算机科学两个领域研究者的推动,复杂网络分析和建模得到快速发展。统计学家提出了“复杂系统”这个概念,网络分析成为解决复杂系统问题的重要途径。计算机科学家的研究解决了网络分析中的概念化问题,提出了有效的解决大型网络的计算、存储、可视化等问题的理论和方法,在互联网和社交网络的开发和应用当中发挥了关键作用。
网络分析在很多不同领域的复杂系统问题的研究中都被证明是有效的。例如,计算生物学对基因、蛋白质、化合物相互作用系统的研究;工程学研究如何更好地部署传感器网络;金融学利用网络模型分析银行之间的相互影响;营销领域运用“疾病的传播”模型推销产品;神经科学利用网络分析探索与癫痫有关的脑电变化规律;政治学研究一个群体的投票偏好在面对内外部影响时如何变化;公共卫生领域借助于网络模型研究传染病在人群中的蔓延,以及如何最有效地进行传染病控制。
网络分析在文献计量学中也有着广泛的应用。邱均平等[2]运用网络分析法研究博客之间的社会网络关系;袁润等[3]利用社会网络分析方法研究了图书馆学论文的合著现象;赵丽娟[4]介绍了社会网络分析的基本理论及其在情报学中的应用;赵蓉英等[5]开展了基于社会网络分析方法的国内外信息计量比较研究,从文献计量和社会网络分析的视角对社会化推荐研究进展与发展趋势演化进行了研究;陈扬森[6]等基于关键词共现网络分析了国内外社交媒体研究热点。网络分析可以发现隐藏在真实关系网背后的关系,它对于了解一个研究主题的成熟度、知识结构、研究规模等状况具有十分重要的意义[7]。
本文运用社会网络分析理论,借鉴关键词共现分析方法,采用R语言编程创建了关键词集共现网络,绘制了期刊关键词集共现网络图,开展了基于关键词集的知识发现探索性研究。
1 关键词集及其分析流程
关键词源于英文“Keyword”,最初特指单个媒体在制作使用索引时所用到的词汇。关键词是学术论文不可缺少组成部分,是论文主要内容的浓缩,是作者精炼出的概括论文主题的词汇,通过“关键词”读者可以迅速地了解论文的主要内容。关键词是表达文献主题概念的自然语言词汇,在正式发表的学术论文中一般都附有关键词。一篇学术论文的关键词一般有3~8个,这些关键词既反映了研究成果的核心内容,又提供了重要的检索途径[8]。
关键词集是关键词集合的简称。为了开展文献计量研究,通常按照一定的原则收集关键词,从而形成关键词集合。关键词集是一定数量文献的所有关键词的集合,是这些文献精华的浓缩。李文兰等[9]在《中国情报学期刊论文关键词词频分析》一文中认为,“学术研究领域较长时域内的大量学术研究成果的关键词的集合,可以揭示研究成果的总体内容特征、研究内容之间的内在联系、学术研究的发展脉络与发展方向等”,关键词集值得深入研究。
已有学者在学术论文中将一定数量的关键词定义为关键词集,并利用关键词集开展相关研究。例如,闵超等[10]在《基于关键词交集的学科交叉研究热点分析——以图书情报学和新闻传播学为例》一文中将两个学科的核心期刊论文规范化的关键词的交集定义为1个关键词集,从该关键词集中获取两个学科的高频交叉关键词及其共词矩阵,在此基础上通过词频分析和社会网络分析探讨两个学科交叉研究热点领域的整体特征。苏新宁等[11]在《2000-2009年我国数字图书馆研究主题领域分析——基于CSSCI关键词统计数据》一文中将2000-2009年数字图书馆研究论文的关键词集合成1个关键词集,并进行了聚类分析。李纲等[12]将两个作者关键词集合的交集称为作者合作关键词集,除去合作关键词集,称为作者私有关键词集。可以看出,关键词集是某一特定时间内,依据检索条件得到的文献全部关键词的集合,反映了该检索条件下得到的文献内容的总和。
目前,学术界对关键词集并没有明确的定义。为了便于讨论,本文将关键词集定义为某一特定检索条件下得到文献的全部关键词的集合。随着检索策略、检索路径、检索时间等的不同,所得到的关键词集也有所区别。为此,本文对该定义作进一步推论,即以某一作者为检索条件,该作者的全部学术论文的关键词集合称为作者关键词集;以某一期刊名称作为检索条件,该期刊的全部学术论文的关键词集合称为期刊关键词集;以某一研究机构作为检索条件,该研究机构的全部学术论文的关键词集合称为该研究机构的关键词集;以某一学科为检索条件,该学科的全部学术论文的关键词集合就是该学科的关键词集。
关键词集对知识发现而言应该具有特别的信息价值。例如,在电子商务活动中,消费者的购物信息关键词可以从某一方面表征该消费者的兴趣特征[13]。此外,在推荐系统应用方面,用户的行为信息关键词有助于发现用户兴趣[14]。同理,表征学科领域信息的关键词集也可以表征该学科的研究热点和发展趋势等。巴志超等[15]在《基于语言网络的研究兴趣相似度量方法》一文中叙述了基于关键词的分析更能直观地反映出文献内容和作者的研究兴趣,利用作者发表文献的关键词集可以揭示作者的研究兴趣。
关键词集比较全面的、客观的揭示出研究领域的微观结构以及研究主题发展的历史脉络、研究热点,知识结构等。在科学研究领域,学者的研究成果在一定程度上揭示了该学者的研究兴趣[16],因此作者关键词集最能代表该作者的主要研究内容,期刊关键词集则能够反映该期刊的载文偏好,机构关键词集可以揭示该研究机构的研究特色,学科关键词集应该可以表征该学科领域研究的总体内容特征、研究内容之间的内在联系、学术研究的发展脉络与发展方向等许多重要课题。因此,开展关键词集知识发现探索研究,对发展文献计量理论和方法及其在知识发现中的应用具有重要意义。
本文按照“学科—期刊—论文—关键词”的逻辑关系采集关键词集。以图书情报学科的18种CSSCI源刊为研究对象,采集近10年以来的数据,每一种期刊每一年的全部载文题录保存为一张Excel表格,共计得到180张表格,这是开展关键词集分析的第一步,采集数据。
第二步,封装数据。在R语言编程环境(RStudio Version 1.1.453)下通过编写R程序自动读取Excel表格,将全部数据封装成数据框(paper.dat),关键代码如下:
library(readxl) #加载贡献包(package)
InFilesPath<-c(″D:/KWSet/Journal/″) #设置输入文件存放路径
OutFilePath<-c(″D:/KWSet/Journal/″) #设置输出文件存放路径
code_Journals<-read_excel(″D:/KWSet/Journal/code_Journals.xlsx″) #数据文件的名称代码表
paper.dat<-data.frame() #定义数据框
for(k in 1:nrow(code_Journals)){ #循环读取数据
infile<-code_Journals$FilesName[k]
infile<-paste(InFilesPath, infile, sep=″″)
infile<-paste(infile,″xlsx″,sep=″.″)
mydata<-read_excel(infile)
mydata<-cbind(mydata,FI=code_Journals$FilesName[k])
paper.dat<-rbind(paper.dat,data.cleaning(mydata))
}
names(paper.dat)<-c(″TI″,″AU″,″OR″,″JN″,″KY″,″FD″,″YE″,″FI″)
save(paper.dat,file=″paper_dat.RData″)
第三步,提取数据子集。根据分析目的,可以从数据集paper.dat当中方便地提取作者关键词集、期刊关键词集、机构关键词集或主题关键词集,R代码如下:
retrieve<-c(″中国图书馆学报″)
mydata<-subset(paper.dat,grepl(retrieve,(paper.dat$JN)))
第四步,拆分关键词。题录数据包含Title-题名、Author-作者、Organ-单位、Source-文献来源、Keyword-关键词、Fund-基金、Year-年7个字段,其中关键词字段中的多个词由“;”区分开来,因此,需要通过如下代码将其拆分。
kws<-data.frame(unlist(strsplit(mydata$KY,″;″,fixed=TRUE)))
第五步,创建网络。将关键词视为网络节点,同一篇论文当中的多个关键词视为共现关系,使用igraph package当中的函数可以十分方便地创建网络,在此基础上开展网络分析。
本文分析的数据集概况如表1所示。

表1 CSSCI收录的图书情报学科的18种期刊载文情况
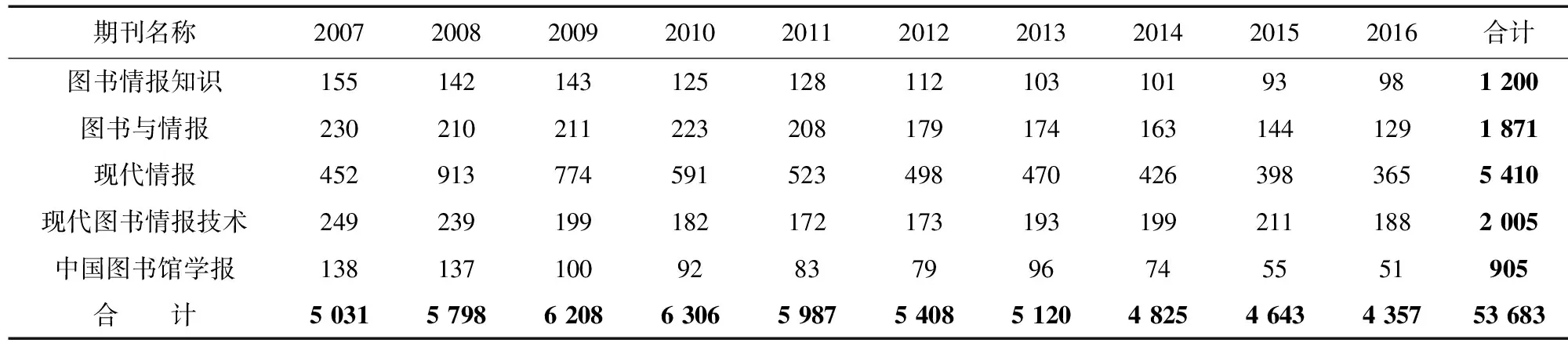
表1(续)
2 创建关键词集共现网络
igraph是一个特别有用的网络分析的R语言扩展包(Package),包含了一系列数据类型和函数,能够方便地创建网络,执行各种算法并实现网络数据可视化。在igraph中,可以用邻接列表、边列表、邻接矩阵3种方法创建网络。
边列表(Edge List)是一个简单的两列列表,给出了所有的边连接的节点对。关键词节点对通过拆分关键词再两两配对生成。
除了边列表创建网络之外,本文还尝试了另外一种关键词共现网络的创建方式,称之为增量式创建网络,该方法的基本思路是,将一篇学术论文中的若干关键词用graph.full()函数创建一个全网络,不限制3~8个关键词,这也是与边列表创建网络的最大区别。接下来,通过for循环执行graph.union(g1,g2)指令处理n篇论文的关键词。用该方法创建网络最大的优势是可以动态观察网络图的变化。
为了便于开展研究工作,本文将创建关键词共现网络及其可视化功能用R语言编写成函数,取名make.keyword.igraph()和plot.keyword.igraph()(限于篇幅,代码省略)。
创建关键词共现网络使用函数graph_from_data_frame(d,directed=TRUE,vertices=NULL),该函数需要给出边列表(d)和网络节点(vertices)。
为了不失一般性,本文将数据集定义为R语言的数据框结构,包括题名(TI)、作者(AU)、单位(OR)、期刊(JN)、关键词(KY)、基金(FD)、年份(YE)等字段内容。其中,关键词字段(KY)包含若干个(3~8)关键词,由“;”分隔,因此,需要将这些关键词拆分,拆分结果用矩阵保存,再将矩阵的列两两配对构成边列表。
函数make.keyword.igraph()在创建网络的同时,还完成了相关计算,例如,计算了全部关键词(节点)的词频、词长、点度中心度、中介中心度、接近中心度、网络密度、网络直径、网络平均路径长度、网络聚集系数等,这些参数作为网络属性被保存下来,再通过函数plot.keyword.igraph()绘制网络图时一同输出。
函数make.keyword.igraph()需要提供4个参数,其中,参数mydata是包含关键词字段的数据框,也就是分析对象(数据集),参数pos=5表示取数据框第5列数据(关键词),参数main=c(″Graph Titel″)是关键词共现网络的图名(变量),myfile=c(″Graph File name″)是关键词共现网络的图文件名(变量)。
绘图函数plot.keyword.igraph()用jpeg()指令将关键词共现网络图以JPEG格式输出到指定文件夹目录,这样,循环调用该函数可以批量输出图文件。
3 运行结果
运行结果如图1和图2所示。图中信息分为以下7个部分:1)图名信息,位于图的中间顶部;2)以不同大小和颜色表示节点及其聚类分布的网络关系图,位于图的中央;3)带有标号的节点信息位于图的左边;4)节点中心性参数位于图的右边;5)节点缩放比例、网络密度和网络聚集系数位于图的左上角;6)R语言版本、硬件环境和计算时间等信息位于图的右上角;7)关键词聚类信息位于图的底部。
图1实现了关键词集的主题聚类,反映了期刊载文的主题信息。类似地,还可以创建作者关键词集网络(如图2所示)、机构关键词集网络、主题关键词集网络等。
4 结果分析
从图1中可以清晰地发现,“数据分析”是2016年度《中国图书馆学报》载文的主题。该年度共计刊载论文52篇,涉及数据分析的大约有12篇,主要关键词有开放数据、大数据、关联数据、科研数据、数据管理、数据共享、数据馆员、数据获取、数据加值服务、数据治理数据重用等,这些关键词相互之间关联形成了一个聚类,反映了研究内容的相关性。
点度中心度较大的节点有术语服务、图书馆等,这两个关键词的接近中心度和中介中心度也比较大。术语服务并非是一个常用的关键词,为什么具有如此高的中心性?分析发现,涉及该关键词的论文有2篇,这两篇论文分别设置了7和8个关键词,它们两两结合导致其具有了较高的中心度。
从图2中可以发现一些更有价值的信息,即那些连接两个或多个聚类的节点关键词,由于其词频不高,所以通常的词频分析方法很难发现这类关键词。例如,图2当中的19号节点(公共文化服务),26号节点(公共数字文化资源整合)等,表明肖希明教授在多个研究方向涉及该主题。深入研究表明,这一现象具有一定的普遍性,本文将这类关键词称为核心关键词,这是关键词集共现网络分析的一个重要结论,对发展中频关键词计量分析理论具有一定的学术价值。
虽然图1的网络密度较低,但其聚类系数较高,且不同年度的期刊关键词网络呈现出一定的规律。表2是按年度计算的18种期刊关键词集网络密度,可以看出,有些期刊的关键词集网络密度和聚类系数呈现逐年增长的趋势,反映期刊论文主题更为集中或者更为突出,这一点也许可以表明学术期刊的"核心期刊"特征,但尚需进一步作较大样本的深入研究。

表2 按年度计算的期刊关键词集网络密度
表3是按年度计算的18种期刊关键词集聚类系数,可以反映期刊载文主题的聚类情况。一般而言,主题越突出,聚类系数越大。

表3 按年度计算的期刊关键词集聚类系数

表3(续)
5 结 论
关键词共现分析的思想来源于文献计量学的引文耦合与共被引,当两个或两个以上的关键词同时出现在同一篇文献中时,则称这两个或两个以上的关键词之间存在共现关系。
本文将逻辑上相关的若干文献的全部关键词的集合称为关键词集。关键词集在时空域上具有封闭特征,也就是说,研究对象是某一学科领域(空间域)在某一段时间范围(时间域)内的全体,这一点有别于传统的文献计量分析。根据这一思路,本文按照"学科-期刊-论文-关键词"的逻辑关系收集整理数据集,研究步骤主要包括:采集期刊论文题录数据、封装数据集、提取数据子集、分析数据子集、可视化分析结果、对分析结果做必要的讨论。
关键词集共现网络分析是一件非常复杂的工作,本文采用R语言编程实现了关键词集网络的创建和可视化,相较于常用的文献分析工具而言更加灵活,能满足多种算法的数据挖掘、知识发现、文献计量、网络计量等分析研究工作的需要。
关键词集网络揭示了关键词集的分布、聚类和关系特征,可以更为直观的揭示分析对象的主题内容及其关联关系,量化的网络特征参数对进一步的数据挖掘和知识发现具有一定的参考价值,这一点尚有待更为深入和系统的研究。
