并发序列模式挖掘在学生成绩分析中的应用
2018-07-25王翠青杨晓彤陈未如
王翠青, 杨晓彤, 陈未如
(沈阳化工大学 计算机科学与技术学院, 辽宁 沈阳 110142)
序列模式挖掘是数据挖掘研究中的一个重要部分,在许多领域有着广泛的应用,如顾客购物习惯、Web访问模式、科学实验过程分析、自然灾害预测、疾病治疗、药物检验以及DNA分析等[1-4].结构关系模式是以序列模式挖掘为基础,进一步找出序列模式之间关系的一种挖掘方法[5].这种方法将序列模式之间的关系进一步进行分解、细化,整合,形成由并发、互斥、重复及串行关系组成的复合模式[5-7].
目前对并发序列模式的研究已经取得阶段性的成果,文献[8]主要介绍了基于支持向量的序列模式挖掘算法,该算法的主要特点是在时间上效率较高,并且避免了庞大的客户序列数据库对具体序列间关系的影响,不再丢失出现概率较小而相互联系密切的关系模式,保证了挖掘出的结果更完整,但该算法产生的中间结果太多,并且序列长度不合理;文献[9]介绍了应用于生物信息的并发序列模式挖掘算法,该算法主要是寻找蛋白质序列之间的并发关系,并且要求输入项必须是单项的.
当前对于学生成绩的分析,相关工作主要集中在关联规则的挖掘[10-13],一般方法是对学生成绩数据源进行预处理,改进数据的质量,从而帮助提高挖掘的精度和性能;给出最小支持度和最小置信度,采用类Apriori算法进行挖掘,从而发现课程之间的相关性.该类研究的优点是可以从挖掘结果中找出哪些课程适合先开设,哪些课程适合后开设等指导制定教学计划的一些建议.但是对原始数据进行离散化处理,得到的挖掘结果可能会产生误差.本文主要是研究适应于学生成绩挖掘的并发序列模式算法,并且挖掘学生课程学习效果之间的并发关系.
1 并发序列模式挖掘方法
1.1 基本概念
定义1 并发关系.若序列c同时包含序列α1,α2,…,αn,则称各序列α1,α2,…,αn相对于该序列c满足并发关系,表示为[α1+α2+…+αn]c.特别地,对于序列α和β, 若它们相对于序列c满足并发关系,表示为[α+β]c.
数据源由学生每学期科目分级组成,一个学生的成绩为一条序列数据,每个学期的科目成绩构成一个项目.
例1: M、N、O、P、Q、X、Y、Z分别表示不同的科目,a、b分别表示科目对应的等级.表1为科目成绩构成的数据源.

表1 数据源示例Table 1 The example of data source
由表1可以看出,序列(Ma)(Oa)(Xa)和(Na)(Qb)(Yb)同时出现在序列1中,所以有:[(Ma)(Oa)(Xa)+(Na)(Qb)(Yb)]1.
定义2并发度.序列模式集SP中的序列模式α与β的并发度可以定义为所有包含α或β的客户序列中使α与β满足并发关系的客户序列的频度,即:
Concurrence(α,β)=
定义3并发序列模式.如果α和β是序列模式并且Concurrence(α,β) ≤mincon,其中mincon是客户指定的最小并发度,则称α和β组成并发序列模式.并发序列模式可以表示为[α+β].
例1中,序列模式最小支持度为70 %时,挖掘序列模式得到的长度≥2的序列模式结果如表2所示.若客户给定最小并发度mincon=50 %,sp3出现在客户序列2、3、4中,sp4出现在客户序列1、2、3中,则Concurrence(sp3,sp4)=2/4=50 %≥mincon,所以[sp3+sp4].序列模式结果如表2所示.
设CSDB={c1,c2,…,cn} 为客户序列数据库,SP={sp1,sp2,…,spm}是序列模式挖掘阶段在给定的最小支持度minsup下得到的序列模式集合.
定义4分支向量.每个客户序列cj的分支向量BVj的定义为:
其中:1≤j≤n,1≤i≤m,(这里n为客户序列个数,m为满足一定支持度的序列模式个数),若编号为i的序列模式在客户序列cj中出现,则bvij=1,否则bvij=0.
若两个客户序列的分支向量同一位置k都为1,则表示序列模式spk同时出现在这两个客户序列中.因此,通过对分支向量进行“与”运算,便可方便得到序列模式同时出现次数.
例1中,在最小并发度mincon=75 %时,每个客户序列的分支向量如表3所示.
1.2 并发序列模式挖掘的改进算法
文献[12]中的并发序列模式挖掘算法以支持向量为基础进行,为每个序列模式计算支持向量,此算法适用于数据源规模巨大,序列模式集规模相对较少时的并发序列模式挖掘.本研究中将每个学生的科目成绩作为数据源,数据源规模较小,而首先进行的序列模式挖掘得到结果较大.因此,为每个数据源计算其分支向量,进一步挖掘并发序列模式.
算法描述:
输入:学生科目成绩数据源CSDB={c1,c2,…,cn},序列模式最小支持度minsup,最小并发度mincon.
输出:并发序列模式全集.
(1) 用传统的PrefixSpan算法对数据源进行序列模式挖掘,得到学生成绩的序列模式全集SP={sp1,sp2,…,spm}.
(2) 计算每个客户序列的ck(1≤k≤n)的分支向量CBVk.
(3) 调用BVCON(1),求得并发集.若Count(BV)表示计算分支向量BV中1的个数,BVCON算法:
void BVCON(intk)
{
if(c>=n*mincon)
{
newCon(BV);//产生新的并发集
return;
}
BV=BV&BVk;
//当前分支向量与第k条客户序列分支向量求与
c++;
if(Count(BV)>=2)
//若同时存在两个序列模式
BVCON(k+1);
c--;
if(c+n-k>=n*mincon)
BVCON(k+1);
}
(4) 对得到的并发集进行分析整理,去除冗余信息.
例1中mincon=50 %时,根据算法得到的并发集如表4所示.
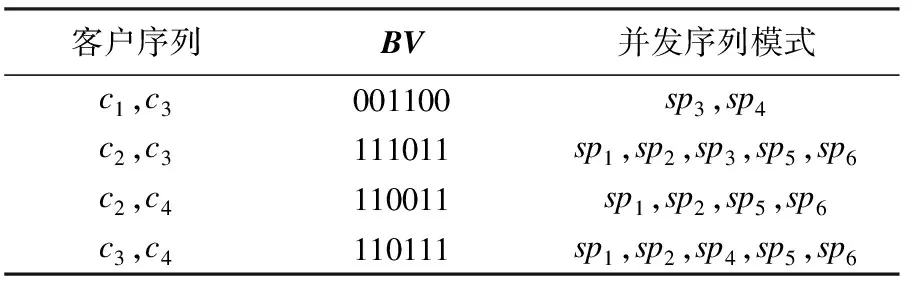
表4 并发集(mincon=50 %)Table 4 The set of concurrence(mincon=50 %)
客户序列c1,c2的分支向量BV1&BV2=001000,其中仅共同包含一个序列模式,所以不予考虑.c1,c4同理.
根据序列模式的包含特征,经过分析整理,例1客户序列当minsup=50 %,mincon=70 %时,得到并发集如表5所示.从该例可以看出:在科目M得a级,科目N得b,科目Z得b的同时也伴随着科目O得a以及科目Q得b.通过并发序列模式挖掘可以发现学生在学习过程中各科目成绩间的内在联系,对分析预测学生学习效果有很大的帮助.

表5 并发集(minsup=50 %,mincon=70 %)Table 5 The set of concurrence(minsup=50 %, mincon=70 %)
1.3 算法验证
为了验证算法的正确性,使用Visual Studio工具,在内存为8 GB,CPU 为2.40 GHz Core i7,操作系统为Windows10的PC机上实现了该算法.实验数据由IBM数据生成器生成数据源,用该数据源生成程序,以产生实验所需的测试数据,测试数据源的有关参数如表6所示.

表6 参数描述Table 6 The description of parameter
鉴于成绩数据的特点,将生成数据参数设置如下:|C|=20,|T|=30,|S|=4,|N|=1 000,|D|=1 000.在不同最小支持度minsup和最小并发度mincon下,采用相同数据源,BV算法与支持向量的并发序列模式挖掘算法[12]的时间效率进行对比,结果如图1所示.从实验结果可以看出,BV算法消耗的时间相对较少,效率优于支持向量算法.


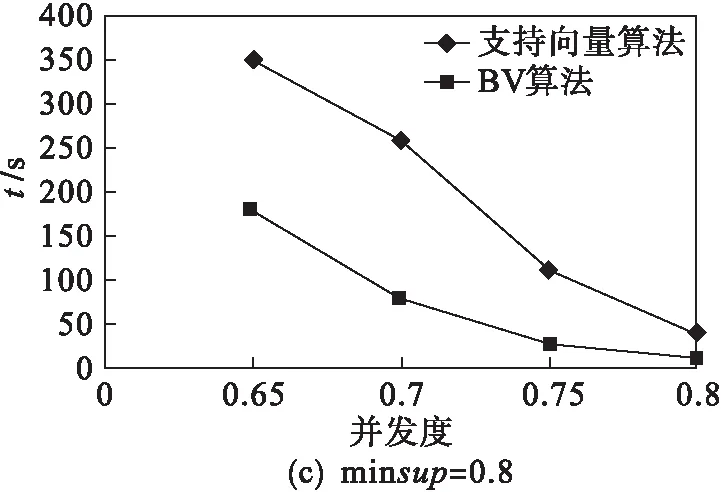
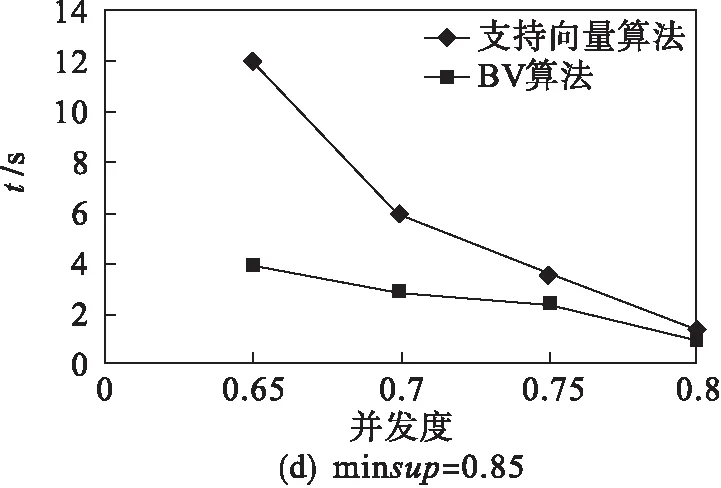
图1 BV算法与支持向量算法的时间效率对比Fig.1 The chart of time comparison between convect and BV with different minsup
2 学生成绩的挖掘实验
2.1 数据的预处理
2.1.1 数据采集
实验选择沈阳化工大学计算机科学与技术学院2011级全体学生4个学年的学业成绩作为数据源,将不同专业分别考虑.
2.1.2 数据标准化
数据标准化是预处理工作中最重要的部分,因为绝对成绩并不能准确说明整体数据的特点,并且各个学科考试题的题量、难度和区别度是不相同的或者不完全相同的,评分标准也不统一,因而会出现有的科目考分偏高,有的科目考分又偏低.只有把绝对成绩转换成相对成绩,以各学科相对成绩总分或均分排序才是合理的.相对成绩的科学性、合理性已经逐渐被大多数人认可.
正态分布:学生成绩是否符合正态分布规律是考试中比较科学的参考指标.本文中每班每科目的学生成绩呈正态分布,可使数据分布更合理,更科学,挖掘结果更具说服力.
每个专业的学生成绩按照不同的班级进行等级划分,等级划分如表7所示.

表7 成绩等级划分Table 7 The hierarchy of results
源数据:1条源数据由1个学生每个学期所修课程成绩组成.即1条记录有8个元素.每一列数据代表1个同学8个学期的所有课程.
2.2 算法应用与结果分析
不同专业的学生在不同的最小支持度minsup和最小并发度mincon下(本实验中minsup=mincon),挖掘不同成绩等级下的并发序列模式结果曲线如图2所示.从图2可以看出:不同专业的学生,在不同的并发度和支持度下,挖掘得到的课程成绩并发序列模式的并发趋势大体相同,随着并发度和支持度的不断增大,在某一取值处达到峰值,然后逐渐减少.在并发度较小时,序列模式挖掘得到的序列模式数比较多;当并发度较大时,由于序列模式挖掘阶段得到序列模式数相对减少,变化趋势减弱.从图2(d)可以看出,信息专业的学生成绩按三级制分级时,在并发度为0.2处取得峰值,在并发度为0.4处再次取得峰值.这是因为在此支持度下,序列模式挖掘得到的序列模式数比较多,从而导致再次出现峰值.
软件专业共111人,在最小支持度minsup=0.2,最小并发度 mincon=0.2,成绩等级五级制时,挖掘得到的并发序列模式数相对较多,结果比较有代表性,挖掘结果如图3所示,这些并发序列模式揭示了不同科目取得成绩之间的关系.



图2 不同专业的并发序列模式数变化曲线Fig.2 The CPS chart of different specialty

图3 软件专业成绩并发关系Fig.3 The concurrent relation of software
上述实验结果说明,日常教学活动中BV算法在学生成绩中的应用可以得到有指导意义的结论,即提高学生成绩应该采用以下教学措施:
(1) 计算机网络和操作系统安排在同一学期,计算机组成原理安排在二者之后,或者计算机网络和计算机组成原理安排在前,操作系统安排在后.这是因为在计算机网络得B,操作系统得B时,会同时出现计算机组成原理得B.
(2) 同理可知,数据结构、C语言程序设计和C语言实践应该安排在同一学期,JAVA语言和J2EE安排在后面的学期,或者数据结构、JAVA语言和J2EE安排在同一学期,C语言程序设计安排在后一学期.
(3) 大学外语3和编译原理安排在同一学期,离散数学安排在后一学期,或者大学外语3和离散数学安排在同一学期,编译原理安排在后一学期.
(4) 高数2和离散数学安排在同一学期,组件技术安排在后一学期,或者高数2和组件技术安排在同一学期,离散数学安排在后一学期.
(5) 高数2和计算机科学导论安排在同一学期,C语言程序设计和C语言实践安排在后一学期,或者C语言程序设计和C语言实践安排在同一学期,高数2和计算机科学导论后一学期.
3 结束语
并发性是研究系统行为的重要特性,本研究将并发序列模式挖掘应用于高校学生成绩分析,有助于发现学生成绩背后所隐藏的有价值信息,从而进一步深化教学改革.同时,研究出了BV并发算法,与现有算法相比,在算法效率上有了更进一步的提高,并且找到学生课程学习效果之间的并发关系,更加完善了成绩预测模型.
