基于引文内容挖掘的科技创新路径识别方法与开源工具研究
2018-07-25廖君华陈军营白如江山东理工大学科技信息研究所山东淄博255049
廖君华 陈军营 白如江(山东理工大学科技信息研究所,山东 淄博 255049)
当今社会,科技创新已经成为决定一个国家在复杂的国际竞争环境里取得成功的基础和关键因素。由于历史、经济等原因,中国科技创新事业在世界舞台上一直扮演着“跟跑者”的角色。可喜的是,在科技创新全球化的背景下,国内科技和经济的快速增长给各学科领域科技创新带来新生机。我国逐步从“跟跑者”转变到“并行者”甚至成为“领跑者”。角色的转变更加需要及时、准确把握未来科技创新发展趋势。科技文献是知识的载体,蕴含着科技创新发展的整体脉络。因此,如何利用科技文献,挖掘和提炼出科学创新、技术沿革、知识流动的具体过程,准确高效的描绘出科技创新路径成为情报学研究的热点话题之一。
为应对日益增加的海量学术文献挑战,寻求利用计算机技术自动、准确识别科技创新路径方法,为科技决策者提供基于数据的参考和依据,本文梳理了科技创新路径研究主要相关理论、方法以及相关实现开源工具,分析了科技创新路径识别研究的未来发展趋势。
1 科技创新路径识别主要方法
1.1 基于引文分析的科技创新路径识别方法
1.1.1 利用天然引文网络识别科技创新路径
1964年,Garfield E首次提出了科学引文索引(SCI)[1],并利用文献间的引用关系构建了某研究领域的引文网络(Citation Network)。文献之间的引用关系主要有:直接引用(Direct Citation)、文献耦合(Bibliographic Coupling,M.M.kessler,1963)和同被引(Co-Citation,H.Small,1973)。文献之间3种类型的引用关系既可以反映知识的扩散方向又可以追根溯源识别某研究领域的知识源头,进而构成原始的天然科技创新路径。
随着时间的推移,各类科技文献数量不断增加、知识不断丰富,引文关系网络逐渐复杂,形成了许多需要进一步深入挖掘研究的大样本数据引文网络。为有效判别某领域内科技创新的发展动向,科研工作者希望借助复杂的引文关系网络来预测科技创新热点、前沿和发展趋势。Price D最早提出了“科学前沿”的概念,指出领域科学前沿的瞬时性特征[2]。而后,相关学者进行了相关实证研究,其中代表性研究有:Small H提出一种基于同被引聚类的方法对科技创新发展路径进行了预测,并以某领域高被引论文为实验数据证明了该方法的有效性[3];Morris S等运用文献耦合聚类的方法识别出了学科领域的研究热点[4];借助文献的直接引证关系的直观性,Shibata N等[5]构建了氮化镓(Galliumnitride GaN)领域复杂引文网络;Takeda Y等[6]构建了光学领域相关文献的引文网络,随后分别探测了相关领域的科技创新发展方向。科技创新路径识别研究方法逐步发展并且形成了直接引文分析、同被引聚类和文献耦合聚类3种分析方法,如图1所示。

注:直接引用,ac、ad、ae、bc、cf、ed、ef;文献耦合,acd、ace、ade、edf;同被引,abc、cef、aed。图1 3种引文关系
3种引文分析方法对应构建的引文网络性质不同,国内外有关学者分别针对3种识别方法进行了对比研究,代表性研究成果见表1:

表1 3种识别科技创新路径的引文分析方法对比研究
经对比分析,直接引用由于其网络结构内容最丰富、最接近完整的科技创新前沿网络,准确性最好。随后的改进工作使得科技创新路径识别的方法变得更精确有效。但是,庞大而复杂的引文网络蕴含大量信息,仅仅从上述的3种识别方法本身难以有效判断科技创新的重点网络群簇以及网络群簇中突出的个体。
为有效分析和研究科技创新路径形成的网络特征和属性,相关学者在前人的研究基础上将社会网络分析(Social Network Analysis,SNA)法引入到科技创新路径的识别中来。具有代表性的分析方法有结构洞(Structural Holes)分析和凝聚子群(Gathering Subgroup)分析。
1.1.2 利用结构洞分析识别科技创新路径中的关键节点
Burt R S[11]于1992年首先提出了结构洞理论(Structural Holes),即:缺少直接联系的双方,需要通过第三者的帮助来联系彼此,那么第三者就在关系网络中拥有一个结构洞。Burt认为个体在网络的位置比关系的强弱更重要,在网络中的位置越好,个体的信息交流、资源获取与决策能力就越强。显然,在科技创新路径中,结构洞越多的文献或文献集合可以视为其在某科研领域的创新性和代表性越强。情报人员通过对结构洞的分析可以从大量繁杂的文献中快速了解领域科技创新知识聚集体的结构和特征[12]。
在科技创新路径识别研究早期,随着结构洞理论的发展,应用的学科范围(经济学、计算机科学、社会科学等)不断扩大,有关结构洞测度和应用的实际问题亟待解决。结构洞有两种测度方法:一种是根据Burt的结构洞指数进行测算;另一种是利用Freeman的中介中心性理论对结构洞的相关属性进行测算。为评估这两种算法的不同特点,汪丹[13]通过实验对比结构约束算法和中介中心性算法发现,中介中心性大小与结构约束系数以及网络有效规模大小和结构约束性关系存在确定联系,两种算法得到的结果不谋而合。但在算法有效性方面,中介中心性的实验结果更具有说服力。姜鑫[14]结合结构洞指数和中介中心性指数两个方面总结了结构洞的测度方法(见表2),并进行了实验验证。而后,结构洞的理论和方法渐渐成熟,有关学者从不同角度进行了尝试性应用。郭秋萍等[15]以结构洞的视角对人际情报领域进行科技创新路径网络构建,发现了网络中的问题并提出了应对策略。

表2 两种结构洞测度方法
注:结构洞指数中,i、q、j代表行动者个体,t为i的连线数(中心点除外),n和N代表i的个体网规模,C/N代表各节点限制度均值。在中介中心性指数中,N代表网络规模,ni、nj、nk表示节点,gik表示ni与nk之间的测地线数目,gjk(ni)表示nj和nk之间存在的经过ni测地线的数目,CBmax代表最大中介中心性。
结合表3分析可知,在情报学领域结构洞分析在识别科技创新路径中的应用可以剔除掉无关网络,加强对所研究重点网络结构或关键节点的分析,判定重点科技创新演化网络中的重要个体,为科技创新路径识别研究奠定基础。
1.1.3 利用凝聚子群分析识别科技创新路径中的重点主题
凝聚子群(Cohesive Subgroup)分析又被称为“小团体分析”,在社会网络中某些个体联系密切、具有较强关系且交流频繁,就会形成凝聚子群。研究人员通过分析网络中子群个数、子群中个体的特征关系、一个子群中的个体与其他子群的个体之间的关系、子群中个体之间的关系来更好的了解子群聚集的内部属性。凝聚子群的分类方法有两种[16]:第一种是基于距离的分类方法,即以网络中节点的“距离”来划分得到不同的凝聚子群;第二种是基于关联度的分类方法,即以网络节点中的“邻点”个数来划分得到不同凝聚子群(详见表3)。

表3 凝聚子群分类
运用凝聚子群的方法对网络(社会网络、合著网络、共词网络等)进行分类,通过调节子网络的范围,可以识别出科技创新路径中的焦点网络,揭示热点研究群体。韩毅等[17]利用主路径分析方法和凝聚子群分析方法将WOS数据库中引文网络领域的引文数据以“主题岛”的形式进行了演化可视化呈现,使情报人员可以更直接的了解不同时期不同维度下的科技创新路径的表现形式。k-核分析方法在共词网络中的应用,为研究主题的确定提供了帮助。姜鑫[18]利用Ucinet软件的k-核凝聚子群分析功能,通过调节k的取值识别出了以“微博”为研究主题科技创新路径中的核心关键词和次级核心关键词。李纲等[19]利用万方数据库中的31种期刊论文数据结合度数中心度分析方法和k-核分析方法识别出了肿瘤学科的科技创新路径研究主题。
基于引文网络分析法、结构洞分析和凝聚子群分析方法都为科技创新路径识别提供了很好的研究思路,研究人员据此取得了大量研究成果。但是,基于引文分析的识别方法在操作过程中需要一定的时间周期来等待引文网络的形成,在识别科技创新路径时不可避免的存在时滞性问题。而且,在对科技创新路径进行识别分析时,引文方法忽略了文献的文本内容本身。因此,相关研究人员开辟了直接深入文本内容中识别科技创新路径的方法。
1.2 基于文本内容分析的科技创新路径识别方法
基于文本内容分析的科技创新路径识别方法可以对文献题名、关键词、摘要和正文等进行挖掘分析,使处在引文网络节点上文献的具体创新内容得以显现。随着时间轴的引入,还可以将科技创新内容在时间维度进行演化展示。弥补了单凭引文信息数据进行聚类分析的不足,使得科技创新路径更加的丰富、饱满。
研究人员往往用关键词或者主题词来描述一篇文献所带有的特征,表示某文献所研究的具体内容,进而进行科技创新演化预测研究。1997年,美国海军研究所(ONR)的Kostoff R N[20]博士提出数据库内容结构分析技术(Database Tomography,简称DT),用来发现科技创新主题并预测演化趋势。2004年,Mane KK[21]首先运用Kleinberg突破检测算法提取高频词做共词分析,然后通过绘制知识图谱来判定科技创新主题的发展变化趋势。为更准确有效的识别科技创新主题,社区发现算法被引入到共词分析中来。2009年,Wallace M L等[22]研究发现社区发现算法在科技创新主题识别上具有天然的优势。2013年,程齐凯等[23]研究了关键词共词网络的社区现象,利用网络社区表征学科研究主题,研究表明共词网络中社区的演化揭示了科技创新主题的演化过程。同年,白如江等[24]的研究也验证了社区演化方法的科学性。
由于关键词与文档之间的语义关系不明确,仅仅以关键词代表整篇论文的研究主题存在语义模糊、主题不准确性等问题。因此,叶春蕾等[25]对关键词共词分析的方法提出质疑,认为基于词频、共词分析的主题演化识别分析方法欠缺语义关系,提出运用LDA模型的进行科技创新路径主题识别。2006年,Blei D M[26]利用LDA模型处理具有时间戳记的文档数据集,实现了科技创新路径动态主题的识别与追踪。2011年,单斌等[27]基于LDA模型提出了一种演化识别方法,避免了同类话题之间的重复演化计算。为增强对文本内容的语义理解,2015年,祝娜等[28]提出了利用改进LDA模型进行科技创新主题演化路径识别方法,并分析了3D打印领域创新主题的动态演化过程。为解决将不同属性的关键词等同看待的问题,识别出关键词所代表的语义角色(理论、方法和研究对象等),2016年,刘自强等[29]利用LDA模型结合社区算法对我国图情领域大数据的科技创新主题进行识别和演化分析。
虽然基于文本内容分析的科技创新路径识别方法对科技论文的内容进行了深入和有效挖掘,揭示了科技文本内容中包含的科技创新的主题和语义关联信息。但是该方法脱离了科技文献之间的天然引文关系,不能精确地深入到施引文献引用原文献的具体句子中揭示科技创新的角色、作者施引情感倾向等。因此,有关专家对基于引文内容分析的科技创新路径研究方法重视起来。
1.3 基于引文内容分析的科技创新路径识别方法
基于引文内容分析的识别方法比基于科技文献文本内容挖掘的识别方法在研究内容上主题粒度更加细化。区别于基于文本内容(运用基于全文本的LDA模型等处理方法)的识别方法,基于引文内容的识别方法侧重于深入到施引文献引用被引文献的具体内容来进行挖掘分析。该方法首先通过信息抽取技术将引文内容从整篇文档中抽取出来。然后,对抽取出的内容进行语义标注(语义角色标注、事件抽取等)、主题识别(主题模型LDA、特征词提取技术、C-Value等)、动机分析(情感分析技术)等一系列挖掘分析,进而准确、深入地揭示科技创新路径的具体内容。
1.3.1 基于引文内容分析识别科技创新路径研究进展
引文内容分析(Citation Content Analysis,CCA)的方法是以引文分析方法为基础发展而来,区别于传统的引文著录分析(见表4),引文内容分析强调运用数据挖掘、自然语言处理和可视化等技术方法,结合施引文献的引用内容(施引文献引用被引文献的句子和上下文),对作者的引用行为、动机等进行探测、归纳和分析的一种情报分析方法。
20世纪50年代,Berelson在其著作《内容分析:传播研究的一种工具》中首次将内容分析作为一种工具方法进行应用。由于早期的期刊数据库以PDF格式文本居多并且计算机技术相对落后,相关学者只能采用人工判读的方法对施引文献中引用该引文的具体语句信息及其上下文内容进行经验性的归纳总结。例如:1962年,Garfield E[30]详细阅读了某领域文献全文,对作者的引用行为进行了分类。1975年,Moravcsik M J等[31]通过对引文内容进行人工判读,解释了作者的引用情感倾向、被引文献的引用作用和重要程度。随着计算机技术的发展,利用自然语言处理技术可以实现对PDF格式的文本数据进行内容抽取。2012年,Zhang G等[32]设计了一个引用内容分析(Citation Content Analysis,CCA)的研究框架,指出引文内容分析是下一代引文分析的方向。2014年,祝青松等[33]以碳纳米管领域的高被引论文(PDF格式)为研究对象,利用C-value算法识别出引文内容中的研究主题,研究表明基于引文内容分析的主题识别结果比基于关键词、摘要等题录数据的识别方法准确性更高。

表4 引文内容分析和引文著录分析区别
1.3.2 引文内容数据源
早期数据库文献数据的格式大都是非结构化数据(例如:CAJ、PDF等),由于数据机读性差,引文内容分析(Citation Content Analysis,CCA)最早是通过人工判读的方法对文献不同章节的引文内容进行抽取标记,来解释文献引用的各种现象。Moravcsik M J[31]作为先行者首先调研了高能物理领域的30篇文献,并归纳总结了作者的引用动机。随后,许多研究者用该方法进行了引文内容的科研研究。但人工判读的方法效率低、主观性强、调研文献量少,不久便受到有关专家的质疑。随着自然语言处理技术的发展,1998年,结构化格式数据XML问世,XML是一种标识语言,可以标记引文位置和相关的引文内容,机读性优越,弥补了人工判读的缺陷。随着近几年开放获取(Open Access,OA)运动的发展,越来越多的数据库提供XML全文格式,表5列出了部分提供XML全文格式的数据库。

表5 提供XML全文数据库
PubMed、Springe Open和Springer BioMed数据库的XML的全文数据均可以免费获得。随着数据挖掘和自然语言处理技术的发展,使得从文献内容中抽取出不同结构层次(引文位置)的引文内容信息进行引用动机识别、情感分析和可视化分析等成为可能,能够解决引文分析存在的将所有引文等同看待的问题。
由上所述,从方法和数据源的角度看来,通过获取全文数据抽取引文内容,利用引文网络分析方法、文本内容分析方法和引文内容分析方法,可以达到结合文献天然引文路径识别出创新性的理论、方法、技术等并揭示其在相应载体上随时间变化而演化发展的目的。因此,基于引文内容挖掘的科技创新路径识别研究在方法和数据源方面前景广阔。
2 实现基于引文内容挖掘的科技创新路径识别开源工具
科技创新路径识别过程中少不了集成了各种算法的软件工具的支持,在数据预处理、数据分析、可视化等数据处理过程中,有时一款软件就能胜任(如:综合平台Knime),有时则需要几款软件的配合才能完成,例如:利用Python中的Jieba分词包对文档数据进行分词,然后用Knime进行数据预处理,最后运用Gephi实现关键词共现网络可视化呈现。因此,本文将基于引文内容挖掘的科技创新路径实现开源工具分为文本挖掘和科技创新路径可视化两类。
2.1 文本挖掘开源工具
在数据挖掘领域里,文本挖掘工具主要功能首先是对目标数据文本进行有效抓取、存储;其次是对文本数据进行特征词(主题模型识别和句法分析)的识别或标注等。文本挖掘方法应用广泛,是对文本数据进行深入挖掘的基础步骤。通过文本挖掘开源工具可以实现抽取科技文献全文中的引文内容,对抽取出的引文内容进行关键词识别、主题识别、关系抽取等一系列挖掘工作,达到识别引用动机、引用意图等目的。通过前期长时间的调研,常用的文本挖掘开源工具主要有:Mallet、Knime、NLTK(基于Python语言的自言语言工具包)等,见表6。
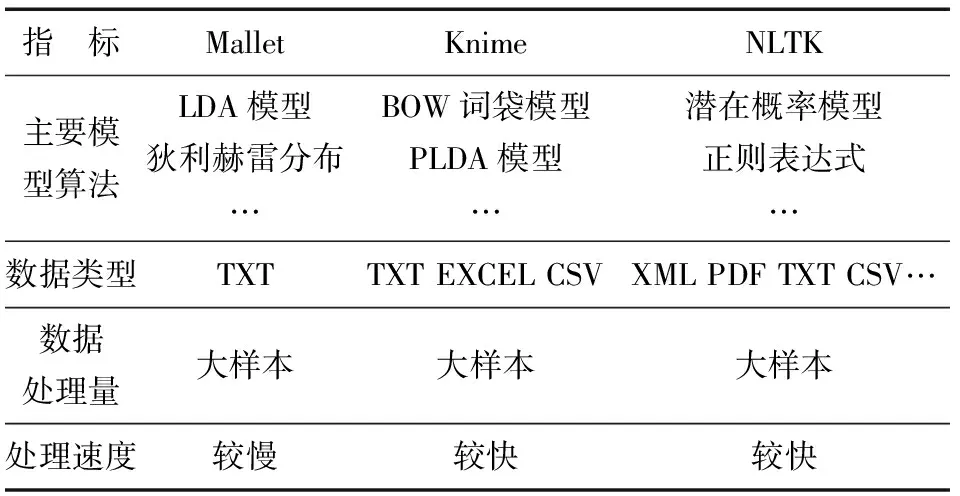
表6 文本挖掘工具对比
Mallet[34]是一款基于java语言的工具包,需要JDK环境的支持,专门用于机器学习。通过Mallet工具,可以进行自然语言处理、文本分类、主题建模、文本聚类、信息抽取等操作。通过下达具体指令语言不但可以对文本数据进行分词、除去停用词等数据预处理工作,还可以通过主题建模的功能(基于分层LDA模型、基于采样的狄利赫雷分布等)分析大量未知属性文本,提取出具有一定特征的主题。
Knime[35](Konstanz Information Miner)数据挖掘工具是一款基于Eclipse开发环境的开源数据分析平台,可以扩展使用Weka中的挖掘算法。采用类似数据流(Data Flow)的方式来建立数据分析流程。数据流程由一系列功能节点(Node)组成,节点之间的连接线需要用鼠标拖拽进行连接,每个节点有输入或输出端口(Port)用来接收数据或导出结果。直接用鼠标拖拽连接端口来进行节点之问的连接。其中每个节点都带有交通信号灯,用于指示该节点的状态(未连接、未配置、缺乏输入数据时为红灯,准备执行为黄灯,执行完毕后为绿灯)。PLDA的主题识别功能对文档进行并行式处理,效率高、准确性好。同时,Knime还具有相似度计算功能,用以测算不同时期主题间的相似程度,判断演化趋势。在句法分析方面有TF-IDF算法功能,可以进行引文内容中语句特征词的提取。
NLTK[36](Natural Language Toolit,简称NLTK)是一种基于Python编程语言的开源库,包含了大量的软件、数据和文档,在文本挖掘和自然语言处理中有很好的应用。它定义了使用Python进行自然语言处理编程的基础工具,提供了相关数据表示的基本类,词性标注、文法分析、文本分类等任务接口,通过这些接口可以访问超过50个语料库和词汇资源(如WordNet),以及用于分类、标记化、词干标记、解析和语义推理的文本处理库,可以自由组合以解决复杂问题。
在科技创新路径识别研究中,离不开上述文本挖掘工具的支持。基于引文内容挖掘的科技创新路径识别具体流程如图2所示。首先,利用文本挖掘工具将关键信息(施引文献ID、被引文献ID、引用位置、引文内容等)从XML全文数据中抽取出来。此部分工作可以利用NLTK工具通过正则表达式实现抽取。然后,将抽取出的数据导入到数据挖掘工具中,进行相关的挖掘分析工作。通过词性标注、命名实体识别、关系抽取、句法分析、语义角色标注等方法挖掘出引文内容中蕴含的主题特征等内容,进而实现引用情感分析。此部分工作可以利用Mallet或Knime主题模型工具实现。
2.2 科技创新路径可视化开源工具
经过对引文内容抽取挖掘后,通过可视化的手段将科技创新路径展示出来就离不开可视化开源工具的帮助。可视化开源工具不仅能实现关键词、作者合作网络的构建,还能对科技创新路径中的关键节点进行标记、展示,从而对某学科领域的研究追根溯源。目前运用较多的工具有Pajek、Ucinet、Gephi、D3.js、VOSViewer等,几种工具的对比见表7。

表7 社会网络和可视化工具对比
Pajek[37]是一款基于windows的免费社会网络分析工具,拥有出色的大型网络处理能力。该工具拥有17个菜单按钮,网络分析功能全面,在大型网络进行分类划区之后,还可以从不同区域入手,缩小研究的网络范围实现小网络细致研究,同时具有结构洞探测分析以及凝聚子群的K-核分析功能,因其强大的网络分析功能,普遍被网络分析研究人员所看好,其部分功能被集成到Ucinet中。

图2 文本挖掘工具应用流程示意图
Ucinet[38]是由加州大学的相关研究人员研发的一款社会网络分析软件。该工具集成了NetDraw(进行一维、二维数据分析)等程序来实现数据处理和可视化功能。Ucinet在5 000节点以下分析速度较快,否之则运行缓慢。该工具可以对社会网络数据进行密度分析(路径:网络→凝聚力→密度→密度)、中心性分析(Path:Analysis→Centrality Measures)、结构洞分析(Path:网络→个体中心网络→结构洞)、凝聚子群分析(Path:网络→角色&位置→结构→CONCOR)等。
Gephi[39]是由法国研究机构合作研发的一款开源的社会网络分析工具,在Netbeans平台上开发,其可视化引擎OpenGL确保了Gephi运行的高效性,支持CSV、GDF、GML等多种数据格式,能够实现关键词共现网络、人际关系网络等多种网络结构的分析,另外还可以进行路径标记,使得网络的演化走向更加清晰的呈现出来。
D3[40](Data-Driven Documents,简称D3)是一种数据驱动下的可视化JavaScript的函数库,由于其本质是JavaScript(文件后缀为.js),所以也称D3为D3.js。D3之所以可视化功能强大,受到各行业可视化工作人员的亲睐,是因为D3简化了复杂的函数框架,使得操作者只需要输入简单的数据,借助浏览器就能够将数据完美表达成图形。D3支持多种数据格式,如JSON、XML、CSV、HTML等,其功能的实现机制是将数据库中的数据与HTML、SVG、CSS结合起来,让原本的二维数据在立体展示空间内形成紧密连接的立体数据体系,能够揭示出数据信息之间的深层次结构关联,使数据信息拥有具象的可视化效果[41]。D3可以实现对社会网络数据(网络关系图)以及主题演化数据(桑吉图等)的可视化呈现。
VOSViewer[42]是雷登大学的研究人员开发的一款免费知识图谱可视化工具。该软件使用Java程序语言编写,运行VOSviewer前,要安装最新的Java环境。VOSviewer可下载安装,也可直接点击launch在线运行。VOSViewer只能对map和network进行直接处理,因此,在处理CNKI或者WOS数据的时候,需要借助SAINT Toolkit等软件进行格式的转化。VOSViewer主要运用于文献计量网络的分析(如共引网络、关键词网络图),构建的网络图清晰且能够通过节点大小、距离、颜色等彰显不同的网络关系(被引次数、密度、学科领域),简单明了。
图3给出了一个利用D3实现的科技创新路径主题演化示意图,图中每一个Node代表一个主题,圆圈的大小代表主题的强度,数据流的宽度代表路径演化的强度(相似度)。通过该图可以清晰的展示出某一研究领域的科技创新主题演化过程。
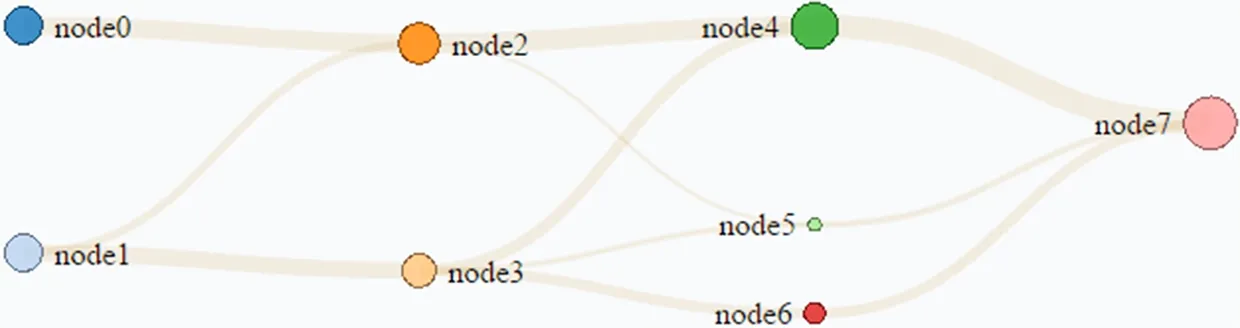
图3 科技创新路径主题演化示意图
图4给出了一个利用Gephi制作的科技创新过程中引用动机网络,图中每个节点代表一篇文献,节点的大小表示被引用次数的多少,节点间的连线,不同颜色表示不同引用动机,比如红色表示正向积极引用,黄色代表中立引用等。通过该图可以展示出科技创新过程中哪些论文起到积极作用,哪些论文可能起到负面引用效果。

图4 科技创新路径情感演化示意图
通过对文本挖掘开源工具和科技创新路径可视化展示开源工具的分析,结合对数据源格式和挖掘方法的研究,可以发现基于引文内容挖掘的科技创新路径识别研究具有广阔的发展空间。通过基于引文内容挖掘的科技创新路径识别可以更加充分的展示领域科技创新的轨迹,反映根本创新内容,为决策者研判领域发展趋势和制定科技计划时提供决策支持。
3 结束语
本文调研分析了科技创新路径识别研究的主要方法以及实现开源工具。指出了基于引文内容挖掘的科技创新路径识别研究是结合引文网络分析方法、文本内容分析方法以及引文内容分析方法,运用自然语言处理技术和可视化技术,对科技文本进行的一系列准确、高效的分析和处理,以求透视出科技创新路径中蕴含的具有科学价值的内容。
