基于社会化标注的用户兴趣发现及个性化推荐研究
2018-07-25王晓耘徐作宁杭州电子科技大学管理科学与工程浙江杭州310018
王晓耘 赵 菁 徐作宁(杭州电子科技大学管理科学与工程,浙江 杭州 310018)
以用户原创内容为标志的Web2.0的出现和流行,用户角色从被动的消费者转为积极的内容生产者。CiteUlike、YouTube、Delicious、Flickr等社会化标注系统不断涌现,吸引了大量用户兴趣。标签作为社会化标注系统的载体,成为Web2.0时代下一种重要的信息组织形式,越来越多学者对标签展开研究。将标签与协同过滤等个性化推荐技术结合起来,大大提高了推荐效果,同时在一定程度上克服了推荐系统冷启动问题。
1 相关研究
社会化标注系统是Web2.0环境下的典型应用,用户采用标签的方式对自身感兴趣的网络资源进行无约束标注,且所有用户标注互为可见。目前基于标签的用户兴趣研究中,主要基于两种方式:
1.1 基于单个标签与标签对构建用户兴趣模型
Li L等[1]对标签下的用户和字眼聚类,采用关联规则算法寻找频繁共现的标签,最后建立基于标签主题的用户群与资源群;Kim H N等[2]将标签作为用户偏好指标,挖掘出与用户相关及不相关的主题,依据其他相似用户的协同拓展用户个人兴趣模型;Ferrara F等[3]以单一用户标签集提取该用户兴趣主题并产生个性化推荐,该方法可根据用户特定兴趣主题自适应过滤并合并用户反馈;夏宁霞等[4]基于自然法和共现法思想,在用户兴趣模型中引入单个标签和标签对,更全面、准确反映用户兴趣偏好;Tao Z等[5]借鉴数据场理论,通过计算每个标签潜在权值,将权值最大的标签作为代表标签,将以它为中心、权值递减的其他标签划为一类,进行用户兴趣主题提取。
1.2 基于主题方法构建兴趣模型
Wu B X等[6]利用LDA方法提取用户兴趣主题,利用多视点用户相似性方法计算兴趣主题、资源及标签相似性,建立相似形图,最后挖掘该图实现基于用户兴趣的推荐;易明等[7]构建了网站层次和用户层次的社会化标签网络,基于该网络进行社团结构分析,得到社会化标签文档和用户标签网络,计算两者相似度后建立细粒度用户兴趣模型;Yao D等[8]采用CPM识别出用户兴趣并划分兴趣主题,构建资源网络并计算各节点权重,基于此选出每个主题下的权威用户,将权威用户经常使用的标签推荐给普通用户,该方法提高了用户标注的质量。
以上综述可见大量学者利用标签挖掘用户兴趣时,主要从标签数量和结构上入手,但在社会化标注系统中,标签的不可控性导致社会化标签存在语义模糊及数据稀疏性等问题,如果直接使用标签构建用户兴趣,精确度将大打折扣。此外,标签具有随时间变化的动态性,用户兴趣也具有动态性及漂移性,利用主题的方法虽然解决了标签杂乱与冗余问题,但这种静态建模没有刻画出用户兴趣的动态性。因此,将标签主题特征与兴趣漂移性融合,建立更为准确的用户兴趣模型,对实现高效的个性化推荐具有极大的实践意义。
基于社会化标签的个性化推荐研究多基于应用层面,以设计算法为主。Ma T等[9]在协同过滤技术基础上融合用户标签和社会关系,反映用户动态变化的个性化需求;Kim H N等[10]将社会化标签融入到适用于社区推荐的技术中,根据社区内其他用户的标注向目标用户进行推荐;冯勇等[11]分析用户间信任关系,对协同过滤算法加以改进,有效提高推荐准确性;孙甲申等[12]通过在主题模型中引入标签粒度,建立新模型解决主题与文档不一致及部分标签与文档内容无关等问题。目前这些方法都在一定程度上提高了推荐准确率,但各方法都有待深入研究。易明等[13]在分析各类方法优缺点后,提出组合推荐的思想,结合基于社会化网络的内容推荐与协同过滤推荐,构建了个性化知识推荐框架;刘健等[14]利用词汇链的方法构建资源描述向量,并考虑用户动态变化,利用动态邻居重组实现个性化推荐;魏建良等[15]提出主流标签的概念,通过分析标签平均标注率确定主流标签数量,构建用户协同模型,同时结合用户兴趣度改进模型。
本文在相关文献研究基础上,尝试在兴趣模型构建时融入用户社会关系网络,并提出兴趣模型更新策略;然后结合协同过滤产生个性化推荐。该方法缓解了标签语义模糊等问题,并考虑到用户兴趣漂移性,克服了传统方法的局限性,能提高推荐准确率。
2 基于社会化标注的语义主题发现
2.1 社会化标注中用户社会关系研究
社会化标注系统中的用户关系,是指单个用户在社会化标注系统的使用过程中,因自身需求形成了各种活动(如关注、标注、浏览等),随着用户数量增多,具有相似偏好、行为的单个用户聚集成群体,通过用户关系网络分析可进行群体用户的偏好与行为分析。用户关系形成过程如图1所示。

图1 和户关系形成过程图
Liu K等[16]在社会化标注建模中引入了用户社会关系,假设用户间的信任关系是对等的,且信任级别呈平均分布,然后将用户间边权重定义为一种信任级别的函数,采用随机游走的相似度函数计算出用户相似度,最后产生个性化推荐。实验结果表明这种基于用户社会关系的个性化标签推荐算法效率有所提升。刘等人假设用户信任关系是对称的,将用户社会关系构建为一个无向图网络,边权重为用户信任级别函数得出的值。但在现实中,用户在互联网中添加或关注好友时,形成的好友关系可以是单向的,也可以是双向的,因此本文将用户社会关系构建为一个有向图,将其应用到标签主题模型进行聚类[17]。
2.2 融合社会关系的用户标签LDA模型构建
本文构建的用户加权LDA标签主题模型通过提取标签主题刻画用户兴趣,具体思想如图2所示,建模分为3个过程:用户社会关系建模、“用户—标签”关系矩阵构建,LDA建模分析。
第一阶段,用户社会关系建模及链接分析,获取用户影响度分数。
基于社会化标注系统中用户关系的特点,在刘[16]模型基础上,本文构建出一个有向图模型,若用户ui与其他用户uj之间建立了某种链接关系,则在用户ui与uj间添加一条指向uj的有向边,若两个用户间存在互相链接关系,则用↔将两个用户连接起来。将用户社会关系加入到“用户—标签”二元模型中,用虚线连接用户与标签,虚线权重表示用户标注该标签频次。

图2 建模思路
通过链接分析获取用户影响度分数。若一个用户被其他影响度高的用户建立链接,则该用户也具备较高的影响度。每一条链接边都视作一个互增强关系,并且用户影响度可以通过所有的链接边传播,采用随机游走算法计算用户影响度。
首先设定G=(U,E,W)为用户的社会关系图,其中U={u1,u2,…,uU}为用户集合,E⊆U*U为链接关系集合,W为U邻接矩阵,定义公式(1),表示对于两个顶点ui、uj,若存在1条ui→uj的边,则wi,j=1,否则为0。
(1)
对于已建立的用户社会关系图G,根据邻接矩阵W建立转移概率矩阵P。定义公式(2)表示节点ui跳转到uj的转移概率。图3展示了用户关系链接分析过程。
(2)
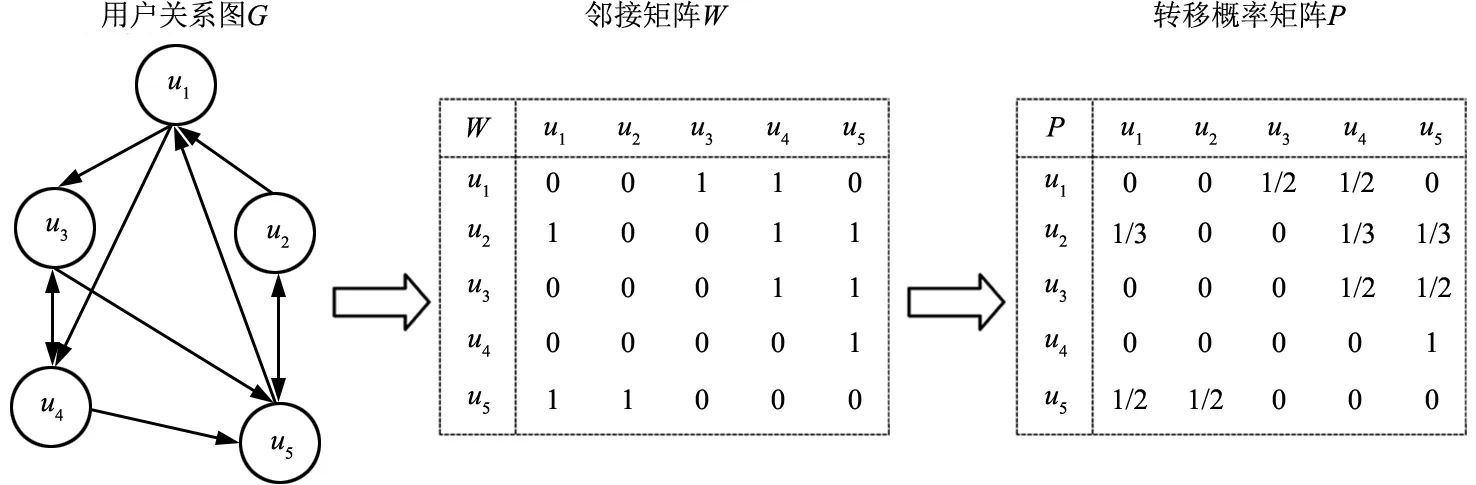
图3 用户联系链接分析

(3)

τ(n)=ζPτ(n-1)+(1-ζ)π
(4)
τ(∞)=(1-ζ)(1-ζP)-1π
(5)
本文设定参数ζ值为0.85,π服从均匀分布,迭代终止条件为:用户影响度向量τ(n+1)与τ(n)符合=τ(n+1)-τ(n)=2/=τ(n)=2≤ψ,其中ψ指预先设定的阈值,取0.001。
第二阶段,基于用户加权的“用户—标签”关系矩阵构建。
假定U={u1,u2,…,um}为社会化标注系统中m个用户集合,R={r1,r2,…,rk}为k个被标注的资源集合,T={t1,t2,…,tn}为用户标注的n个标签集合,u∈U,r∈R,t∈T,a=(u,r,t)∈A表示一次标注行为,则社会化标注行为可定义为四元组P=(U,T,R,A)。根据系统中用户标注行为可分解统计出用户—标签二元关系矩阵Y。
根据Y,将每一个用户的标注行为表示为1个文本文档,将其转换为向量形式:
YT(u)=[t1,y(t1,u);t2,y(t2,u)…;ti,y(ti,u)…tT,y(tT,u)]
y(ti,u)表示为用户u标注过标签ti的次数。设用户u的影响度分数为τu,则基于标注行为的用户加权表示形式为:
g_YT(u)=[t1,gy(t1,u);t2,gy(t2,u)…;ti,gy(ti,u)…tT,gy(tT,u)]
gy(ti,u)表示标签ti在用户u中的加权标注频次。可由公式(6)计算得出。
(6)
由于上文基于随机游走的用户影响度排序以均匀分布为初始分数,在迭代学习过后各节点的影响度分数较小,若直接将其加权到用户标注行为上,则无法保证加权后的用户标注频次为整数且总出现频次降低。因此在不改变影响度分数权重比例的情况下,将影响度分数最小值对每个用户的影响度分数进行定制,定制后的用户影响度分数与标签频次值加权取整,这样能提高高影响用户低频次标签在主题分配上的能力,降低低影响用户高频次标签在主题表达上的占比。
将“加权的用户—标签语料库”导入R中进行LDA建模处理时,需转换成矩阵格式,如图4所示。
第三阶段:LDA建模分析。
根据上述加权的用户—标签矩阵进行LDA潜在语义主题建模,如图5所示。

图5 融合用户加权的标签LDA模型
采用吉布斯采样算法迭代学习出用户标签的潜在主题,吉布斯采样公式如公式(7)所示。
(7)

3 用户兴趣模型构建及个性化推荐
3.1 基于标签主题的用户多兴趣建模
根据获取到的用户标签主题及主题概率分布,将用户兴趣模型抽象为若干主题分量,且每个主题由若干标签来描述。用户兴趣模型分为两层:第一层兴趣主题层——由LDA模型迭代学习出的标签语义主题及其权重构成;第二层特征标签层——由相关语义主题下的标签及其权重构成,如图6所示。
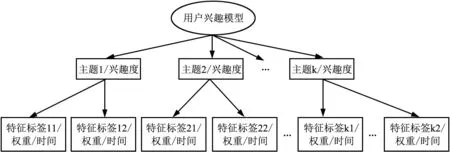
图6 用户兴趣模型简化
定义用户多兴趣模型由五元组表示:U={Z,T,W,F,P},其中Z为用户兴趣主题集合;T为各个兴趣主题下对应的标签集合;W为主题下各标签权值p(ti|zi=n);F为各标签遗忘因子,更新用户兴趣变化;P指用户对兴趣主题感兴趣程度,即偏好程度p(zi=n|ui)。
3.2 用户兴趣模型更新
(8)
式中,F(ti,j)表示兴趣模型中第i个主题Topici下第j个标签的遗忘因子;cur代表当前日期;tagged为标签最近被标注的日期;hl指用户兴趣半衰期(由大量数据训练得到)。
本文通过调整用户兴趣主题及特征标签权值来反映用户兴趣变化,实现兴趣模型更新。如图7所示,模型更新流程如下:
2)针对用户新添加标签情况,分以下3种情形对各主题与标签权重值重新调整:
a)用户新添加标签tα可归于兴趣模型原来主题中,且该主题已包含该标签,则重新计算标签tα权重wi,j及该标签所在主题权重wi,同时将tα的遗忘因子中tagged日期改为当前标注日期;
b)用户新添加标签tα可归于兴趣模型原来主题中,当该主题没有标签tα,则将该标签加入主题模型中,计算tα遗忘因子,将tagged日期改为当前标注日期,重新计算tα所在主题权重;
c)用户新添加标签tα不能归于兴趣模型原来主题中,则将tα作为新主题加入主题模型中,计算tα的遗忘因子,将tagged日期改为当前标注日期,tα以权重作为新主题权重。

图7 用户兴趣模型动态更新流程图
3)删减旧标签:对用户兴趣模型中各主题下的所有标签按权重值降序排序,设定权重阈值δ,将小于δ的标签删减并对各主题权重重新调整。
4)删减旧主题:对用户兴趣模型中各主题按权重降序排序,设定主题权重阈值ξ,删减小于ξ的主题。
由图6可以看出,随着砂粒含量的增大,砂质黄土的黏聚力减小,砂粒含量从30%增长至45%,黏聚力从6.08减至3.28,降幅为46%。曲线形态表现为先缓后陡,即当砂粒含量小于35%时黏聚力随砂粒含量的增加缓慢降低,当砂粒含量大于35%时黏聚力随砂粒含量的增加其降低趋势增大。
3.3 基于用户兴趣模型的协同过滤推荐算法
传统协同过滤算法依赖“用户—资源评分”矩阵,系统中巨大的资源数量容易产生矩阵稀疏性问题,并且仅根据用户对资源的评分并不能完全刻画用户兴趣偏好。基于此,本文引入社会化标注改进传统协同过滤算法,具体算法流程如图(8)所示。
Step1:邻居用户发现
用户相似度计算:结合多层、多维用户兴趣模型,构建用户—标签语义主题的相关性矩阵,将用户相似性转换为兴趣模型主题层向量的相似性计算。
采用修正的余弦相似度计算相似性,公式如下:
(9)

图8 个性化推荐流程
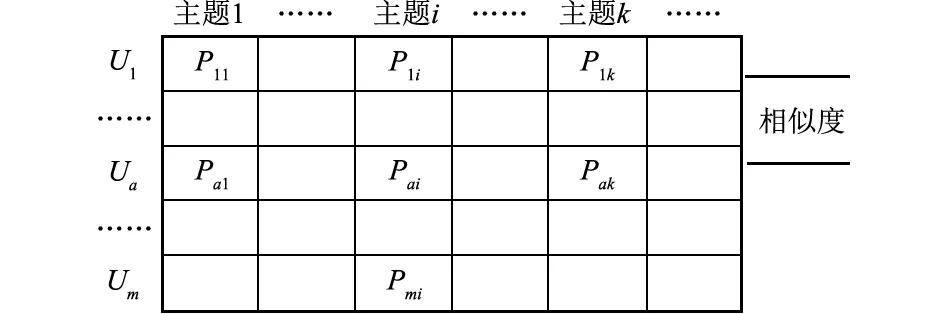
图9 用户—主题矩阵
邻居用户选取:根据用户相似度计算,采用阈值设置方法选取邻居用户集合。设定阈值δ,当sim(u,v)大于δ时,该用户归入邻居用户集合中。
Step2:资源集确定与特征表示
通过获取邻居用户集合中用户标注、收藏或浏览过的资源,过滤目标用户已标注和已收藏的资源。得到这类资源集的资源—标签关系矩阵X,矩阵X中的Xrt元素表示资源r被标注过标签t的次数,然后进行LDA潜在语义主题建模,计算得到标签潜在语义主题及主题分布概率,基于此构建资源—标签语义主题矩阵,如图10所示,其主题分布概率p(zi=n|ri)为资源与标签语义主题相关度。

=图10 资源—标签主题矩阵
Step3:个性化推荐产生
用户对资源兴趣度通过公式(10)计算,最后按照兴趣度大小排序,采用Top-N方法推荐给目标用户。
(10)
4 实验及算法评价
4.1 数据集
本实验数据来源于CiteUlike站点(http://www.citeulike.org/)。CiteUlike属于经典的社会化标注系统,是一个免费协助注册用户存储、管理及分析学术文章的论文书签网站,允许用户自由收藏个人喜欢的论文、分享自身论文库并可用添加标签的方式进行标注。当用户浏览其他用户标注的标签而对该用户产生兴趣时,可通过“Connect”控件,建立与该用户的链接关系。
本文使用Jsoup工具通过“Connections”接口抓取用户间链接关系,采集到用户相关标注信息,包括用户名、论文、标签、标注时间等,如果用户使用多个标签标注同一篇文章,这些标签将存入多条数据记录中。
抓取数据后,利用R语言对采集到的初步数据集做相关预处理,删除不完整数据,对某些用户标签进行中文分词、对分词后的标签去停用词等操作。最后得到的实验数据集包括5 124个用户,8 245个标签,12 574篇论文,以及88 132个链接关系。示例数据如表1所示。

表1 标注数据示例
4.2 实验评估指标
本文希望从实用性、准确性、完整性等方面考查改进算法的性能,因此采用准确率和召回率两个指标。
召回率(查全率)衡量所使用算法推荐了多少应该被推荐的项目或资源,该值越高推荐系统性能越好。设n为用户个数,用户i的测试集为Ti,正确推荐的资源集为Pi,则召回率计算公式为:
(11)
准确率考量推荐结果的准确性,随着推荐数量的增加准确率会下降。设N为推荐资源的个数,其计算公式为:
(12)
由于召回率和准确率在一定程度上相互制衡,一般采用综合评价指标F-measure来衡量两者关系,计算公式为:
(13)
4.3 结果和分析
为验证本文提出的个性化推荐方法有效性,设计两部分实验进行验证:用户兴趣模型及模型更新方法验证、基于用户兴趣模型的个性化推荐算法验证。采用5层交叉验证将数据集分为5分,并依次选取一份作为测试集,其余4份为训练集,得到5个不同的测试集和训练集用于实验分析,各评估指标依次得到5个测试结果,取其算数平均值为各指标最终评估结果。
用户兴趣模型验证
该部分通过本文算法(MCF)与传统协同过滤算法(CF)对比实验,用召回率验证本文构建兴趣模型的有效性。由于邻居用户个数M取值大小对算法精度有一定影响,M取值过小则无法得到足够的待推荐资源集合,取值过大会使算法搜索成本加大。实验选择的M值从10增加到100,间隔为10,对比分析不同用户模型对召回率的影响,实验结果如图11所示:

=图11 不同用户模型对召回率影响
从图11中可知,当M值为35左右时,两种算法的召回率基本持平,当邻居用户个数高于35时,MCF召回率高于CF算法,这是由于CF算法是基于用户共同关注资源的评分进行相似度计算,而MCF是基于用户兴趣模型计算相似度,这里相似度的值与用户共同标注资源没有绝对的关系,即存在相似度很大的用户之间评价相同资源情况较少的现象。随着M取值增大,召回率增大,当邻居个数在60左后,算法召回率趋于稳定,故在后续实验中邻居个数取60。
模型更新算法验证
该部分通过MCF与本文提出的基于遗忘因子更新的用户兴趣模型个性化推荐算法(UMCF)对比实验,采用准确率(Precision)指标验证更新的用户兴趣模型是否能更准确表达用户兴趣。
实验数据按照资源被标注时间取训练集前80%,剩余20%为模型更新数据集,将训练数据集最后一条标注时间设为建模时间,更新数据集最后一条标注时间设为当前时间,采用Top-N推荐方法,实验结果如图12所示:

图12 用户兴趣模型的更新对准确率影响
UMCF算法相较于MCF推荐准确率较高,由此说明更新的用户兴趣模型对用户兴趣权值计算更为准确,更加准确表达用户的兴趣偏好。
推荐算法验证
将UMCF与传统的标签协同过滤推荐(TCF)、标签关联关系推荐算法(LC)对比实验,推荐长度从5逐渐增大,计算在此推荐长度下的F-measure值,对其取算术平均值为最终评估结果。如图13所示:

图13 不同N值下的F-measure
由图13可知,当N取20时,3种算法F-measure值最高,说明在此推荐长度下推荐综合效果达到最好,MCF相较于LC、TCF,评估指标F-measure值有所提高,这进一步论证了本文提出的算法达到了更佳的推荐效果。
5 结束语
互联网飞速发展为人们生活带来诸多方便的同时,信息过载等问题也随之而来,个性化推荐技术的应用在一定程度上使人们需求得到满足,因此围绕个性化推荐展开的研究越来越多。本文基于社会化标注系统,从影响个性化推荐质量的两个核心——用户兴趣建模和个性化推荐算法切入展开相关研究。
在社会化标注系统中,用户的标注行为体现了其兴趣偏好,标签也表达了资源特征及潜在属性。然而由于标签存在语义模糊、歧义等问题,制约着其在个性化推荐领域上的应用。当前众多研究者仅从数量和结构上考虑用户与标签的关系,同时标签的时序动态性也影响着用户兴趣模型的准确率,限制着推荐模型的质量。针对上述问题,本文在已有研究基础上进行改进和创新,提出基于社会化标注的用户兴趣挖掘,构建了个性化推荐算法,并通过实验对文中提出的改进算法进行验证分析。
但是本文尚有一些不足之处:例如在构建用户兴趣模型时,前提假设用户只对感兴趣的资源进行标注,对于某些用户喜欢标注不感兴趣资源的情况未作考虑,因此在实际应用中,可以进一步研究“负面标签”识别问题。用户兴趣建模时个性化推荐技术的核心,在建模过程中会涉及用户隐私问题,如何采用有效的隐私保护机制将是未来个性化推荐服务的研究方向之一。
