多特征混合神经网络模型在ADR分类中的应用
2018-07-24赵鑫李正光吴镝方金朋
赵鑫,李正光,吴镝,方金朋
(大连交通大学 软件学院,辽宁 大连 116028)
0 引言
近年来,特别是社交网络的发展使得用于研究药物不良反应的互联网数据增长迅速,文本分类成为处理大量文本数据的关键技术.文本分类,就是在事先给定的类别标记(label)集合下,根据文本的内容来判断它的类别,这在自然语言处理中有着广泛的运用[1].
目前应用到文本分类中的算法很多,例如KNN分类算法、朴素贝叶斯分类算法、支持向量机(SVM),神经网络、最大熵等,这些方法都是通过浅层神经网络来实现的,在文本分类中取得了很好的效果.但是它们的局限性表现在对复杂函数的表示能力不足,使得对复杂分类问题的泛化能力不足[2-3].
深度神经网络的迅速发展为解决这个问题提供了可能,多层的神经网络模型不但可以克服这一问题,同时非线性映射的深层结构能够利用比较少的传参数来完成较复杂的函数逼近,具备良好的特征学习能力.而在深度神经网络模型中,文本的预处理以及特征的选择在很大程度上影响最终分类器的性能.目前大多数的研究都提取了某一类特征运用于分类任务中.文献[4]使用卷积神经网络和词向量,加入位置特征,其分类性能超越了传统方法.但是,不同类型的特征所表征的信息并不相同,仅使用一种特征不能充分利用文本信息.基于此问题,本文提出了一种混合多特征的神经网络模型,融合词性特征,情感特征和位置特征作为多通道卷积网络的输入,通过CNN和LSTM模型的特征学习,最后利用softmax输出关系类型完成分类.
1 方法
1.1 文本预处理
本文所用的数据来自twitter中与药品相关的帖子共计6773条推文,预处理的过程包括:
(1)获取文档中的文本信息,即去除文档中用户的ID、名称等信息,去除标点符号以及一些特殊符号(如“ , …”),并将所有的单词变为小写;
(2)构建映射表,将每个单词均映射成数字,这样可以将文档表示成特征向量的形式,每个特征向量对应一个单词.例如,单词bloody映射成9.
通过以上处理工作,把文本表示成特征向量形式,结构化数据,以便于后续的处理.另外,模型训练时,数据集中90%作为训练集,为了加快训练速度以及增加精确度,使用5倍平衡将训练集中正例扩充5倍;剩余的10%作为测试集.
1.2 词向量模型
词向量(word vector)也称为词嵌入(word embedding),是词语的一种分布式表示.每个单词被表示成一个连续的实数值向量,并通过训练使得向量空间的相似度可以表示文本语义的相似度[5].同时,相比较于其他的文本表示方法,例如one-hot、概率主题模型等,词向量模型包含的语义信息更加丰富[6].本文选用Google在2013年开源Word2Vec作为词向量训练工具,该工具使用的训练模型是Mikvolov等人[6]在2013年提出的CBOW和skip-gram,并且因为使用简单,而且效果显著被广泛使用.
1.3 特征提取
1.3.1 词性标注(Part-of-Speech tagging)
通过词性标注概括文本,可以保存更多的文本信息,而且利用词性能够代表某一类文本的特征这一特点,以词性序列作为文本的特征表示,相较于N-gram特征提取方法也可达到降低特征表示维度的效果[7].文献[8]提出的词性标注方法在twitter数据上实验得到将近90%的准确率.本文利用NLP工具Word2Vec自动获取词性序列.如图1所示.

图1 本文获取的词性序列
用工具自动获取词性,构建词性-数字映射表,则上述句子被表示为:[1,2,3,1,4].
1.3.2 情感分析(Sentiment Analysis)
对文本感情色彩的判断来自于文本中带有感情色彩的词语,在特定的文本分类任务中,不同的感情色彩也影响着分类的精确度.在ADR文本分类中,带有负面情感的文本属于ADR的概率更大.文献[9]提出一种基于监督学习的方法应用到情感分析中,对影评文本进行情感倾向性分类,该研究对之后的情感分析研究有着深远的影响.
本文使用情感词典,其中有117个负面情感词,将情感词映射为特征向量,与利用语料库所构建词袋(bag-of-words)中的每个词所映射的特征向量通过式(1)计算得到情感特征向量.
(1)
1.3.3 位置特征(Position Features)
文本上下文中词语对关系实例的描述能力与词语和关系实例间相对位置有关.词语距离关系实例越近,其对实例的描述能力越强[10].所以词语的位置特征能够作为文本分类中有用的特征.求词语的位置特征有很多选取方法,文献[11]提出将词语相对位置的信息增益作为位置特征.
本文使用一种简单的提取位置特征的计算方法,假设目标实体(即文本中的药品名称)的位置为a,则该实体所在的句子中其余词相对于实体的位置信息表达为:
(2)
其中,c表示该词语当前位置,sum表示句子长度.例如:“My doc is going to up my fluoxetine dosages.”,句子中药品实体为“fluoxetine”,则通过式(2)计算其余词相对实体的位置,最终句子表示为: [-0.78,-0.67,-0.56, -0.44,-0.33,-0.22,-0.11,0.0,0.11]
2 混合神经网络模型
2.1 模型搭建
本文提出的多特征混合神经网络模型结构如图2所示,不同的特征向量通过不同的CNN模型通道输入到模型中,经过CNN训练之后的结果经过池化层以及merge层的融合连接作为LSTM模型的输入,最终运用softmax分类器计算输出向量在类别空间中的置信度分布.
图2 多通道卷积神经网络
2.1.1 卷积层
卷积层接收嵌入层输出的特征向量r,
r=WwdV
其中:Wwd=[W1,W2,…,Wi]∈Rc×v×d是训练好的词向量矩阵,Wi表示输入第i通道的特征向量,c为通道,υ为词典大小,d为词向量的维度;V∈Rc×n×d表示输入矩阵,用于之后的卷积层提取特征,n表示输入句子的最大长度.
卷积核D∈Rc×h×d,h表示卷积核的高度.设Di×Rh×d表示第i通道卷积核,大小为h×d,Vi[k:k+h-1]表示第i通道第k到k+h-1的向量,b为偏置,f为非线性激活函数,则卷积mk表示为:
mk=f(Vi[k:k+h-1]·Di+b)
(4)
输入层矩阵通过式(4)得到卷积后得到一个新的特征C:
C=[m1,m2,m3,…,mn-h+1]
(5)
卷积层提取窗口大小为h的输入层句子特征,由于输入层特征不同,可以提取更多新的特征.
2.1.2 Bi-LSTM层
长短时间记忆网络(Long Short Term Memory Net-works, LSTM),一种特殊的循环神经网络(RNN),该网络能够解决深度学习中RNN梯度消失的问题.CNN模型的输出经过池化层和merge层融合连接之后作为LSTM模型的输入.LSTM 的模型由专门的记忆存储单元组成,经过精心设计的输入门、遗忘门和输出门来控制各个记忆存储单元的状态,通过门的控制保证了随着隐藏层在新的时间状态下不断叠加输入序列,前面的信息能够继续向后传播而不消失.
利用形式化语言,LSTM可以表述为:
其中,δ表示激活函数sigmod;W*,U*,V*,b*分别表示系数矩阵和偏置向量;it,ft,ot分别表示t时刻输入门、遗忘门和输出门的计算方法,ct表示t时刻记忆单元计算方法,表示t时刻LSTM单元的输出.
另外,单向LSTM只能参考输入序列的上文信息,而对下文信息并无涉及为了解决这一缺点,充分利用上下文信息,所以构建了双向的LSTM(简称Bi-LSTM),对每个训练序列分别训练一个正向LSMT网络和一个反向LSTM网络,并且在同一个输出层输出,这样能够充分捕获输入序列每个点的上下文信息.
2.2 模型训练
在训练过程中有几个参数需要调整:多通道词向量矩阵Wwd,多通道卷积核D,转移矩阵W,以及偏移量b,有θ=(Wwd,D,W,b), 使用式(11)作为损失函数:
(11)
yi为输入xi的标签,L表示每次训练的样本数量.在训练参数时使用梯度下降最小化损失函数,使用式(12)更新梯度:
另一方面,为了减少固定学习率λ造成的不稳定的损失,使用adam算法改进每个训练步骤中梯度下降参数.
3 实验结果及分析
模型训练各个超参数设置如下:卷积核个数为128;卷积核高度为3,4,5;步长为1;激活函数为Relu;池化窗口大小为5.为了验证多通道模型可以提高关系抽取的性能,进行对比试验,实验分别设置为只使用位置特征,只使用词性特征,只使用情感特征以及同时使用三通道,其他参数保持一致.

图3 迭代次数对比
图3所示为四种模型迭代次数的对比,从图中可以看出多通道模型(Muti)迭代次数明显少于词性模型(POS)和情感特征模型(Sentiment)的迭代次数,而与位置特征(Position)的迭代次数相差不大,说明多通道模型可以加快收敛,使训练速度大大提升.
表1为单个特征模型和多通道模型结果,通过对比得出:
(1)不同的特征向量训练得出的结果有差别,说明不同的特征带有不同的信息;
(2)使用多通道将各个特征向量融合后训练结果优于使用单一特征向量的训练结果.

表1 模型训练结果
为了证明本文所提出的模型有较好的识别效果,表2列举了几个分类模型作为对比.
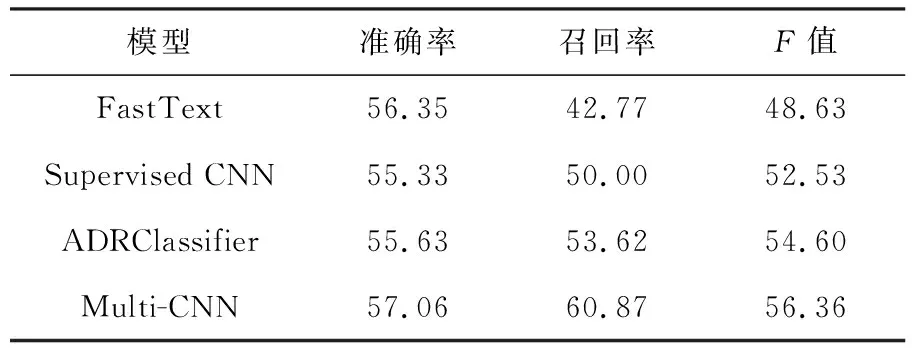
表2 模型对比
其中,FastText模型利用n元组(bag-of-n-gram)将特征转化为低维向量空间,这样可以通过分类算法实现不同特征共享[13];Supervised CNN使用上下文语境作为默认参数训练CNN模型;ADR Classifier是一个较先进的二分类模型,识别短文本是否为药物不良反应(ADR)文本[14];而Multi-CNN为本文提出的模型,通过对比可知,本文所提模型无论从准确率,召回率还是F值上都略高于其余模型,证明本文所提模型的有效性与先进性.
4 结论
本文提出一种多通道网络模型,该模型用于生物医学的实体关系抽取中,使用word2vec训练工具提取特征向量并应用到多通道模型中,从而可以增加表征信息.通过实验对比得知,多通道模型在生物医学的实体关系抽取中表现突出.在未来的工作中,可以尝试更多的特征融合到多通道中,比如依存句法树等.另外可以使用GloVe作为词向量提取特征向量.GloVe是由斯坦福大学Pennington等人[15]提出的,模型构造了一个全局的词共现矩阵,是基于计数的方法,从而可以利用全局统计信息,更多的考虑了全局的信息.所以使用GloVe在多通道模型关系抽取中有很大的研究价值.
