斜率/截距算法在猕猴桃可溶性固形物含量便携式检测中的应用
2018-07-24李倩倩刘大洋李伟强郭文川
李倩倩,刘大洋,杨 彪,李伟强,郭文川*
(西北农林科技大学机械与电子工程学院,陕西 杨凌 712100)
中国目前是种植面积第一的猕猴桃生产大国[1]。猕猴桃富含丰富的营养成分,被誉为“水果之王”。糖分是猕猴桃的重要呈味物质,也是影响果实采后食用品质的重要因素。水果果汁的可溶性固形物中81%的成分为糖类[2],因此常用可溶性固形物含量(soluble solids content,SSC)评价水果的糖度。传统检测水果SSC的方法是取部分果肉榨汁、将果汁滴入糖度计中测量。虽然该方法相对精确,但却是有损检测,不利于消费者挑选水果。近红外光谱技术具有稳定性好、操作简单、无污染、无损检测等优点[3],已经被广泛应用在桃、苹果等水果的品质检测中[4-11]。在应用近红外光谱技术检测猕猴桃SSC方面国内外学者也进行了大量研究[12-15]。现有的台式近红外检测设备虽然精度高、稳定性好,但是价格昂贵,体积庞大,操作复杂,不利于大范围推广。此外,猕猴桃品种较多,光谱差异较大。在以往的研究中,大多数研究人员只对单一品种猕猴桃建立模型并预测该品种SSC,当需要预测另一品种猕猴桃SSC时,又需要大量样本重新建立模型,耗时较长,浪费大量人力物力。因此,需要对模型进行校正,提高模型的适用性。目前主要是针对不同仪器之间开展模型传递方法的研究,而对于不同品种间近红外光谱模型传递方法的研究鲜有报道。
本研究以海洋光学微型光谱仪和自制光纤探头为基础,搭建一套猕猴桃SSC近红外光谱检测装置,以‘华优’、‘徐香’和‘西选’为实验对象,在该检测装置下,获取多品种猕猴桃的光谱;基于x-y共生距离(sample set partitioning based on joint x-y distances,SPXY)样本划分方法,选取具有代表性的样本做为校正集,结合多种不同波长优选方法,建立检测猕猴桃SSC的偏最小二乘(partial least squares,PLS)[16]模型,探讨不同波长优选方法对猕猴桃SSC检测模型精度的影响;结合斜率/截距算法,用少量‘徐香’和‘西选’猕猴桃样本对‘华优’猕猴桃SSC检测模型进行校正,提高对目标样品的预测性能,减少实验量,优化猕猴桃SSC检测模型。
1 材料与方法
1.1 材料
实验所用的成熟‘华优’、‘徐香’和‘西选’猕猴桃样品采摘于杨陵区某3 个猕猴桃园,所选样品无缺陷和损伤。为了获取一定变化范围的SSC,将采摘的猕猴桃样品放在室温条件下冷却约6 h后,分别将10~15 个样品装于保鲜袋中,并置于3 ℃的恒温恒湿箱中冷藏。实验前从恒温恒湿箱中取出30 个样品(每个品种各10 个),用面巾纸清理掉样品表皮的杂物后,将样品置于室温((24±2)℃)条件下放置约12 h,以使样品回到室温且保证样品温度均匀。每隔7 d取一次样,共用样品390 个,其中‘华优’130 个、‘徐香’130 个、‘西选’130 个。
1.2 光谱采集装置
基于微型光谱仪的猕猴桃SSC近红外光谱检测系统主要由微型光谱仪、计算机、光纤探头、光源和USB数据线组成,如图1所示。其中微型光谱仪为美国Ocean Optics公司生产的NIRQuest512型微型光谱仪,该光谱仪采用稳定性高的滨松铟镓砷化物(InGaAs)作为阵列探测器,其探测范围为898.27~1 719.61 nm。光源为功率6.5 W的卤素灯(HL-900-P7,如海光电科技有限公司)。光纤探头(自制)包含2 组单独的光纤,一组是位于光纤探头处的环形光纤负责将光源发出的光照射到猕猴桃上,另一组负责将光纤探头处检测到的含有猕猴桃内部品质信息的光传递到光谱仪中。计算机通过USB数据线与微型光谱仪相连接,负责整个光谱数据的采集、存储和处理。
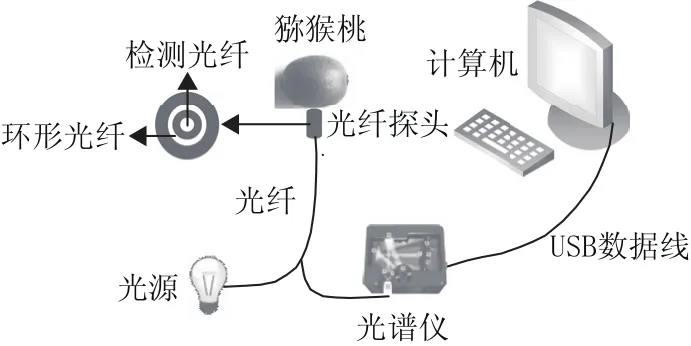
图1 猕猴桃光谱采集系统结构图Fig.1 Schematic diagram of the spectral acquisition system for kiwifruits
1.3 方法
1.3.1 光谱数据的采集
以猕猴桃赤道上间隔180°的2 个点作为光谱采集区域。采集猕猴桃光谱时,将光纤探头与猕猴桃表面紧密接触,使用SpectraSuite软件(Ocean Optics,美国)实现光谱数据的采集和存储。猕猴桃光谱采集的参数为积分时间3 000 ms,平均次数3,平滑度3。按公式(1)计算光谱反射率:

式中:Rλ和Sλ分别为波长λ条件下猕猴桃样品的反射率和光谱强度;Dλ和RDλ分别为波长λ条件下的暗光谱强度和参考光谱强度。
由于每个样品间隔180°的2 个点的SSC和光谱均有一定的差异,因此以每个点获得的光谱作为一个独立的光谱,共获得光谱780 条。
1.3.2 SSC测定
光谱采集完成后,在光谱采集位置取适量果肉,用家用压蒜器压汁,然后用PR-101α型数字式折射计测量果汁的SSC。每个点测量2 次,2 次测量结果的平均值作为该点SSC的测量结果。每个点的SSC与该点的光谱一一对应。
1.4 数据分析与处理
1.4.1 光谱数据预处理
采集到的原始光谱不仅包含了被测样品内部结构和化学组分的综合信息,同时也包含了背景噪声等其他无关变量。在全光谱范围内比较了全光谱、Savitzky-Golay卷积平滑、基线校正、多元散射校正、标准正态变量变换(standard normalized variate,SNV)、一阶及二阶微分光谱预处理方法对PLS模型性能的影响,发现经SNV预处理后的光谱能有效地提高PLS模型对猕猴桃SSC的检测性能,因此,本实验以SNV预处理后的光谱作为后续分析的基础。
1.4.2 SPXY样本划分方法
SPXY样本划分方法是由Galvao等[17]首先提出的,它以Kennard-Stone算法为基础,在计算样品间距离时,同时考虑了x变量和y变量。该方法可以很好地覆盖多维空间,从而能提高模型的预测效果。
1.4.3 特征波长的选取
采用连续投影算法(successive projections algorithm,SPA)、无信息变量消除(uninformative variable elimination,UVE)法和竞争性自适应重加权(competitive adaptive reweighted sampling,CARS)法从全光谱中提取特征波长。
SPA[18-19]是一种利用向量投影分析的前向循环特征波长提取算法。从一个波长变量开始,每循环一次都计算这个波长变量在剩余波长变量上的投影,并将投影向量最大的波长引入到波长组合,直到达到设定的波长数为止,每个新选择的波长都与前一个波长的冗余度最低、共线性关系最小。本研究中采用交互验证均方根误差(root mean square error of cross validation,RMSECV)评价SPA中每一步所得到的波长组合,最小RMSECV对应的波长组合及波长数既是最终提取的结果。
UVE[20-21]是以PLS回归系数为基础的特征波长提取方法。它是把随机产生的与自身光谱矩阵变量数目相同的噪声矩阵作为伴随矩阵添加到光谱矩阵中建立PLS模型,利用交叉验证,剔除原始变量中的无信息波长,得到回归系数矩阵,然后计算回归系数向量的平均值与标准偏差的商的稳定性,根据稳定性判定是否把该波长用于最终的模型中。
CARS[22-24]是基于简单而有效的达尔文“适者生存”进化理论提出的一种新的特征波长提取方法。它是利用自适应加权采样技术保留PLS模型中回归系数绝对值大的波长变量,利用交互验证,计算并比较每次采样产生的特征变量集所对应的RMSECV值,根据RMSECV最小值选取最佳特征波长子集,该子集所包含的变量即为最优变量组合。
1.4.4 斜率/截距模型传递方法
斜率/截距算法[25-26]是通过校正主品种模型来实现模型传递的。
其主要步骤为:建立主品种校正模型K,选择n 个目标样品构成标准样品集X1,利用模型K直接预测X1,得到目标样品矩阵C1,采用一元线性回归方程对C1和预测的目标样品真值矩阵C0进行拟合,式(2)为拟合方程:

式中:a和b为该拟合方程的斜率和截距。
以残差平方最小为原则,根据PLS法求解该线性方程,得到a和b,按公式(3)、(4)计算:

利用公式(3)、(4)求出a和b后,采集未知目标待测样品光谱矩阵X2,采用模型K得到预测值C2,再利用公式(5)求出未知目标待测样品修正后的预测值C3。

1.4.5 模型的建立及评价
以校正集样品的均方根误差(root mean square error of calibration,RMSEC)和相关系数(Rc)以及预测集样品的均方根误差(root mean square error of prediction,RMSEP)和相关系数(Rp)分别反应模型的校正性能和预测性能。Rc和Rp越高,RMSEC和RMSEP越低,模型的性能越好。此外,以剩余预测偏差(residual predictive deviation,DRPD)评价模型的预测性能。Nicolaï等[27]指出,当DRPD<1.5,表示该模型的预测精度很差;当1.5<DRPD<2.0,表示该模型预测性能相对较弱;当2.0<DRPD<2.5,表示该模型可用于粗略地预测;当DRPD>2.5,表示该模型具有良好的预测能力;当DRPD>3.0,表示该模型具有极好的预测能力。
1.4.6 软件处理
利用Unscrambler9.8(CAMO,Norway)完成光谱数据的SNV预处理,利用Matlab2010a(Mathworks,USA)软件完成光谱特征波长变量提取及猕猴桃SSC模型的建立。
2 结果与分析
2.1 猕猴桃近红外光谱特征分析
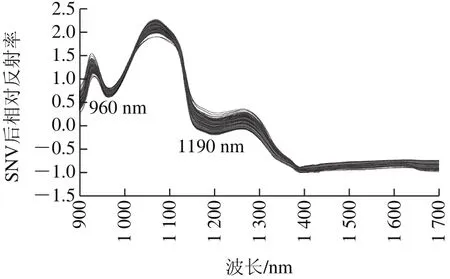
图2 经SNV处理后的猕猴桃光谱图Fig.2 Spectra of kiwifruits after SNV pretreatment
如图2所示,所有猕猴桃样品在898.27~1 719.61 nm波长范围内经SNV预处理后的反射光谱。在整个光谱测试范围内,各样品的光谱变化趋势相同,且有2 个主要的吸收峰,分别出现在960 nm和1 190 nm附近。960 nm处强的吸收峰可能是由于碳水化合物和水的O—H键的二级倍频吸收共同作用所致[28],而1 190 nm处的吸收峰很可能是由于碳水化合物(果糖、蔗糖和葡萄糖)的C—H键的二级倍频吸收引起的[29-30]。
2.2 校正集和预测集样本划分
采用SPXY算法分别对3 个品种的猕猴桃样本进行划分,按照校正集与预测集样本数3∶1的比例将每个品种的猕猴桃分别划分为195 个校正集样品和65 个预测集样品。从表1可以看出,每个品种校正集SSC的分布范围覆盖了预测集的分布范围,这有助于构建稳定的检测模型。
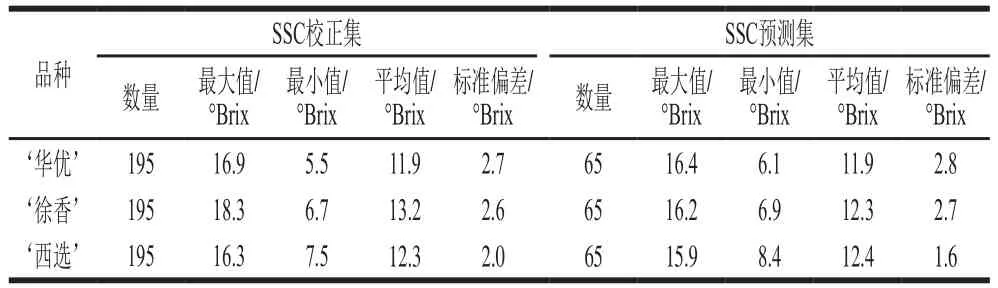
表1 各品种猕猴桃SSC测量值的分布Table1 SSC distribution of kiwifruits from three varieties
2.3 特征波长选取及模型的建立
SPA算法提取特征波长:设定SPA算法中各品种猕猴桃的特征波长变量数为3~50 个,分别计算不同特征波长数条件下各品种猕猴桃的RMSECV,根据RMSECV的最小值确定最佳的特征波长变量数。本实验中,对于‘华优’、‘徐香’和‘西选’猕猴桃所确定的最佳特征波长数分别为14、29和18。
UVE算法提取特征波长:在应用UVE算法提取特征波长时,设定随机变量个数为512 个,将随机变量稳定性最大绝对值的99%作为变量筛选的阈值,阈值以外的稳定性值所对应的波长变量被用于建模,其余波长则被剔除。本研究中用UVE算法提取的‘华优’、‘徐香’和‘西选’猕猴桃的特征波长数分别为241、234 nm和154 nm。
CARS算法提取特征波长:本研究中将蒙特卡罗采样次数设定为100。由于蒙特卡罗采样法是从校正集样品中随机选取一定数量的样品建立PLS模型,因此每次CARS算法的结果不会完全相同,这使得挑选出来的特征波长略有差异。为此,本实验运行CARS算法20 次,根据RMSECV最小一次的结果选择特征波长。本研究中,对于‘华优’、‘徐香’和‘西选’猕猴桃,经过CARS算法最终提取的特征波长数分别为24、34和37。
模型建立及预测:基于各品种校正集样品的全光谱以及SPA、UVE和CARS提取的特征波长,建立预测各品种猕猴桃SSC的PLS模型,并用所建模型对预测集样品的SSC进行预测,如表2所示。
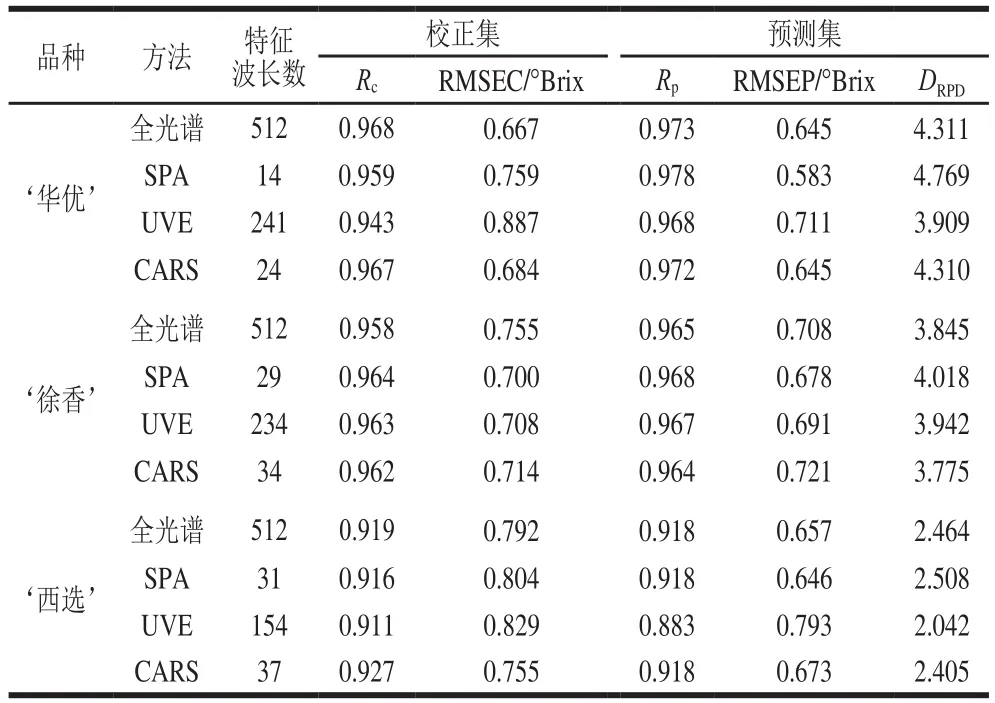
表2 不同特征波长选择方法下各品种猕猴桃SSC的建模结果Table2 SSC modeling of different kiwifruit varieties with different effective wavelengths selection methods
对于‘华优’猕猴桃,经SPA提取的特征波长所建PLS模型的预测结果最好,RMSEP为0.583 °Brix;对于‘徐香’和‘西选’猕猴桃,同样也是经SPA提取的特征波长所建PLS模型具有最小的RMSEP(0.678 °Brix和0.646 °Brix)。3 个品种中,对于‘华优’和‘徐香’,4 种不同波长提取方法所建PLS模型的DRPD均大于3.0,说明该套系统能获取到稳定且准确的猕猴桃光谱信息,对这2 个品种猕猴桃的SSC具有极好的预测准确性;而对于‘西选’4 种不同波长选取方法所建PLS模型的预测能力相比‘华优’和‘徐香’较差,可能是由于其SSC范围较窄,但应用SPA方法筛选出的31 个特征波长所建模型的DRPD在2.5和3.0之间,说明该模型对‘西选’猕猴桃SSC的预测也具有良好的预测能力。
2.4 基于斜率/截距算法的模型传递及预测结果
本研究中所用‘华优’猕猴桃SSC的范围覆盖了‘徐香’和‘西选’SSC的范围,代表性较强,故以‘华优’作为主品种,以‘徐香’和‘西选’为目标品种,使用斜率/截距算法,研究基于‘华优’猕猴桃SSC建立的SPA-PLS模型预测‘徐香’和‘西选’猕猴桃SSC的准确性。在使用斜率/截距算法进行模型传递时,需要选取一定数量的标准化样本,用以计算模型传递参数——斜率和截距。用SPXY算法分别从‘徐香’和‘西选’的校正集选取0、10、20、30、40、50、60、70、80、90 个样本作为标准化样本,用以计算模型传递的斜率和截距。从图3可以看出,对于‘徐香’和‘西选’经过斜率/截距算法修正后,RMSEP均在一定程度上有所降低。对于‘徐香’,当标准化样本个数为10时,其RMSEP(0.966 °Brix)值最小。对于‘西选’,当标准化样本个数为50时,RMSEP(0.875 °Brix)值最小。为此,本实验在采用斜率/截距算法进行模型传递时,将‘徐香’和‘西选’目标品种的标准化样本个数分别设为10和50。
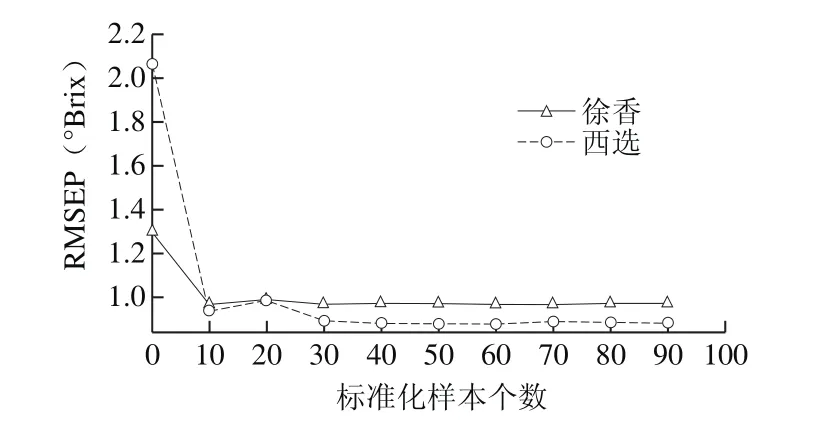
图3 ‘徐香’和‘西选’的RMSEP随标准化样本个数的变化趋势图Fig.3 Changes in RMSEP of ‘Xuxiang’and ‘Xixuan’ kiwifruits with different numbers of standard samples
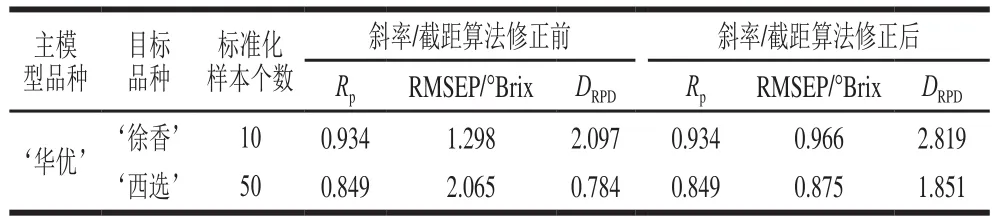
表3 斜率/截距法修正前后的模型检测效果Table3 Prediction results of the model before and after S/B algorithm correction
从表3可以看出,当对‘华优’的SPA-PLS模型进行斜率/截距算法修正前,即直接采用‘华优’模型预测‘徐香’和‘西选’的SSC时,其RMSEP分别为1.298 °Brix和2.065 °Brix,而采用斜率/截距算法修正后,该模型对‘徐香’和‘西选’SSC预测的RMSEP分别降为0.966 °Brix和0.875 °Brix,较使用前分别下降了0.332 °Brix和1.190 °Brix,说明斜率/截距算法能有效改善主品种(‘华优’)模型对目标品种(‘徐香’和‘西选’)SSC的预测性能。
2.5 少量‘徐香’和‘西选’猕猴桃模型建立
为了客观地评价斜率/截距算法的模型传递效果,分别用2.4节中挑选出的10 个‘徐香’和50 个‘西选’建立预测‘徐香’和‘西选’猕猴桃SSC的SPA-PLS模型。设定特征波长变量数分别为1~9 个和1~49 个,根据不同变量数条件下‘徐香’和‘西选’RMSECV的最小值确定最佳特征波长数分别为3和15,进而分别建立预测‘徐香’和‘西选’猕猴桃SSC的PLS模型。为了验证模型的预测效果,用所建的模型对预测集的65 个‘徐香’和65 个‘西选’分别进行预测,各模型的建模及预测结果见表4。

表4 少量‘徐香’和‘西选’猕猴桃所建PLS模型对其SSC预测结果Table4 SSC prediction results using PLS method with small samples of ‘Xuxiang’ and ‘Xixuan’ kiwifruits
由表4可以看出,仅用10 个‘徐香’猕猴桃样本所建模型的RMSEP为1.883 °Brix,DRPD为1.446,同表3中斜率/截距算法修正后对‘徐香’猕猴桃样本的RMSEP(0.966 °Brix)和DRPD(2.819)相比,RMSEP增加了0.917 °Brix,DRPD减少了1.373。对于‘西选’猕猴桃,用50 个样本作为校正集建模后得到的RMSEP为0.902 °Brix,DRPD为1.796,同表3中斜率/截距算法修正后对‘西选’猕猴桃样本的RMSEP(0.875 °Brix)和DRPD(1.851)相比,RMSEP增加了0.027 °Brix,DRPD减少了0.055。结果说明,当目标样品数比较少时,基于小样本所建模型的预测性能较差,而采用斜率/截距算法进行模型传递能够有效地提高对目标样品的预测性能。
而对表2和表3的结果进行比较,可以发现不管是哪种波长提取方法,相同品种条件下,表2中的RMSEP均小于表3中的RMSEP。该结果说明,当目标品种的样本数较大时,基于较大样本所建立的目标参数的预测性能优于利用斜率/截距算法模型传递的结果。
3 结 论
本实验基于自搭建的猕猴桃SSC便携式无损检测系统获取的光谱,结合PLS模型,研究不同特征波长提取方法对猕猴桃SSC检测模型的影响,并用斜率/截距算法研究了不同品种猕猴桃间SSC模型的传递。结果说明,该套系统结合SPA-PLS方法建立的‘华优’、‘徐香’和‘西选’猕猴桃SSC检测模型可以用于猕猴桃SSC的快速无损检测,其RMSEP分别为0.583、0.678 °Brix和0.646 °Brix;用斜率/截距算法对‘华优’猕猴桃SSC模型进行校正时,仅用10 个‘徐香’和50 个‘西选’猕猴桃能够有效地提高对目标样品的预测性能,其RMSEP分别为0.966 °Brix和0.875 °Brix,同仅用少量‘徐香’和‘西选’猕猴桃所建小样本模型相比,其RMSEP分别降低了0.917 °Brix和0.027 °Brix。本研究为进一步构建精度更高、更便捷的微型集成式猕猴桃SSC检测设备提供理论依据。
