机器学习聚类组合算法及其应用
2018-07-23四川大学魏烨敏蒋子元
四川大学 魏烨敏 蒋子元
前言
在机器学习中,系统聚类算法和K-means聚类算法是两种常用的聚类算法,并具有各自的特征,将两者特征结合到一起设计的组合聚类算法,可以发挥两种算法的优势作用,提高机器学习聚类算法的分析和判断能力。目前关于机器学习聚类组合算法的研究已经得到了广泛关注,比如在电力工业中,可以利用机器学习聚类算法实现用户负荷类型分析,完成电价制定和负荷预测等工作。
1.机器学习聚类算法
1.1 系统聚类算法
系统聚类算法通过将样品划分成若干类,选择各类中距离最小的类进行合并,指导将所有类合并成一个类,完成机器学习过程。系统聚类算法的主要步骤包括:(1)构建M个初始模式样本类,用Y1(0)、Y2(0)、…Ym(0)表示,并对类与类间的距离进行计算;(2)根据类与类间的距离计算结构,构建距离矩阵D(m),求取D(m)中的最小元素,根据最小元素建立新的分类,比如最小元素是Yi(m)和Yj(m)之间的距离,则根据Yi(m)与Yj(m)间距建立新分类Y1(m+1)、Y2(m+1)、…Ym(m+1);(3)计算合并新类之间的距离,得到距离矩阵D(m+1),再对Yij(m+1)与其它未合并类Y1(m+1)、Y2(m+1)、…Ym(m+1)之间的距离进行计算;(4)如果经过上述计算和合并没有得到预期聚类结果,则返回第二步进行迭代计算,直到得到预期聚类结果。该聚类算法的主要优点是可以由系统根据数据间距离自动列出类别[1]。
1.2 K-means聚类算法
K-means聚类算法法即最小最大聚类算法,通过综合考虑各簇之间的簇内方差值关系,确定聚类目标函数,在最小化K各簇中的最大簇内方差值下进行聚类。具体是对公式:
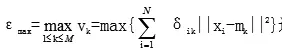
进行聚类最小化,通过迭代方式,得到松弛化公式:
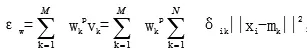
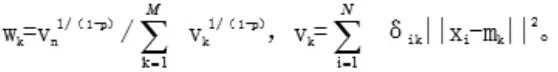
可以将其聚类过程看作簇与聚类中心的迭代更新过程,在权重增加下,可以将接近中心的样本划分到簇k中。由于0≤p≤1,1/(1-p)>0,方差越大则权重越高[2]。
2.机器学习聚类算法的组合应用
2.1 聚类算法组合设计
在机器学习过程中,如果负荷样本数量过高,特征向量的维数往往也较多,单独采用任意一种聚类方法,都难以获得理想的聚类效果。为了得到更加可靠的聚类分析结果,客观描述样本类型,准确识别样本并提高分类效率,可以通过聚类算法组合设计,找到适合对大数量和高维度样本进行聚类分析的方法,实现负荷特性的有效聚类。
通过对上述两种聚类算法进行分析可以看出,初始聚类中心设计对聚类算法的应用效果有重要影响,如果初始聚类中心的设计不合理,将导致聚类结果出现不稳定现象。而且在处理大数量样本数据时,聚类算法的重复性步骤非常多,但其整体流程较为简单,原理较为直观和清晰,能够在计算机软件的辅助下,实现快速分类。采用组合算法的优势是不需要初始设定经典聚类算法,解决传统单一聚类算法在应用过程中容易出现局部最优解的问题。
基于上述考虑,设计系统聚类算法和K-means聚类算法的组合算法,通过二次组合,对机器学习过程中的负荷特性进行进一步的计算分析。将系统聚类算法作为一次聚类算法,利用其对负荷特性进行分类,然后在采用K-means聚类算法进行二次聚类分析,将一次聚类计算结果直接作为二次聚类分析的聚类中心,解决传统聚类算法的初始参数敏感性问题,同时为二次聚类分析结果的客观性和准确性提供保障。
聚类组合算法的关键步骤包括平滑处理、量纲差别判断、归一化处理、加权处理、系统聚类、相关系数判断、最优系统聚类、最小最大聚类、有效性验证、矩阵还原及加权、最优分类数确定、质控特殊数据、加权矩阵还原等。
2.2 聚类算法应用流程
根据上述聚类组合算法设计方式,及其学习聚类组合算法的应用流程可以分为三大步骤,一是对初始数据进行处理,并完成特征向量设置,二是应用组合聚类算法,三是对聚类分析结果进行展示。基于这一基本流程,聚类组合算法的详细应用流程如下:(1)在第一阶段,完成数据导入和坏数处理工作,并对导入的数据样本进行归一化处理,得到样本特征向量;(2)在第二阶段的聚类组合算法应用过程中,首先对分类数进行初始化,然后由系统执行聚类算法,确定初始化聚类中心,完成最小最大k均值聚类,利用有效性函数对聚类结果进行检验,如果不满足聚类分析要求,则返回初始分类数步骤进行迭代计算,直到得到预期的聚类计算分析结果;(3)在第三阶段,将得到的满意聚类结果导出,并由计算机软件辅助绘制聚类效果图,对聚类结果进行展示。
2.3 机器学习算例分析
本次选取的算例为某工业园电子元件制造企业的每日负荷数据聚类组合算法应用。在数据搜集过程中,选取该电子元件制造企业在近5个月内每日24时的负荷数据,经过处理后得到聚类特征向量,共得到152组数据,将非正常数据剔除后,剩余130组有效数据。将130组有效数据制作成分析样本,共分为6类,提取出三组特殊数据,基于上述聚类组合算法对其进行聚类分析。从本次算例分析结果来看,根据聚类组合算法最终得到的负荷曲线,负荷高峰值分别出现在8~11时和14~16时,部分为迎峰负荷。通过对各类别情况进行分析可以看出,第一类和第二类是减产或停产的特殊情况,得到的聚类分析曲线也较为特殊,其他负荷曲线形态则较为相似。通过进行聚类组合分析和计算,可以确定负荷高峰为1200kW,最低时也可达到800kW,平时基本稳定在1000kW左右,而且没有随季节变化出现较大波动。基于上述分析结果,该企业通过在高峰时采取减产等措施,可以使负荷峰值下降约200~300kW。聚类组合算法的应用可以完成负荷分析人物,为移峰填谷、优化系统运行提供支持。
3.结束语
综上所述,单一的聚类算法难以完成大数量和高维度样本的聚类分析任务,通过设计和应用聚类组合算法,可以发挥不同聚类算法的优势,同时解决初始聚类中心设置问题,从而得到更加可靠的聚类分析结果。通过对系统聚类算法与K-means聚类算法的组合设计和应用进行研究,可以为相关机器学习聚类算法的改进提供参考。
