计算机检索技术的研究与分析
2018-07-23河北农业大学信息学院赵晓卓
河北农业大学信息学院 徐 琳 尹 悦 赵晓卓
1.文献检索原理及技术
1.1 概述
随着当今社会的发展,被计算机存储设备携带的电子类的信息越来越多。专利文献特征:1.明显的知识产权特性2.实用性非常强3.著录格式规范4.将科技与法律融为一体。5.有很多重复信息,而且数量巨大。
从狭义上理解信息检索,就是说从信息集合中寻找所需信息的过程,即我们经常说的信息搜索。
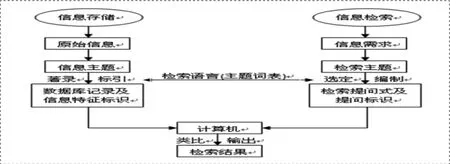
检索大致过程如下图所示:
用户任务——信息需求——问题——问题提炼——搜索引擎——结果——数据库
1.2 原理
1.2.1 原理示意图
为了满足检索的需要,需要收集大量的数据并对其进行处理,以满足检索者快速准确检索的需要。下面是信息检索原理的示意图:
1.2.2 检索模型
(1)检索模型引出:
所有索引基本上分为三个部分:文档表示部分、查询表示部分和匹配功能部分。文献表示部分体现的是文献的存储形式,文献表示部分可以是一些关键词或者标引词,它也可以是一些数据;查询表示部分是指用户表达信息的愿望。匹配功能部分用于将处理后的文档表示部分和查询表示部分放入系统中进行匹配,并通过使用不同的匹配函数获得不同的输出结果。
(2)标引词权重
标引词的权重,用于描述标引词和文献内容相关程度。
(3)三种模型及其简单函数
A.布尔模型
检索X由逻辑运算符和/或非逻辑运算组成。检索系统的索引系统中的每个索引在文档中只有两种状态:出现和不出现。索引字的权重是q_ij属于{0,1}。
B.向量空间模型
对于向量空间模型,二元组(Di,Kj)的权值是正非二值数。文件Kj的向量可以表示为。其中,表示第i标引词Di在文档Kj中权重。的取值范围是[0,1],这样某文档就可转为高维空间中一点。
标引词权值主要由于标引词的频率统计,即:局部权值和全局权值。
全局权值(IDFi):是指第i个标引词在整个系统中文档集的权值,IDFi=log(N / ni)。
N——系统中文档总数;ni——系统含标引词Ki的文档数;FREqij为标引词Ki在文档Dj中的出现的次数; MAXTfj表示文档Dj中所用标引词出现次数最大的值。
C模糊模型
用模糊数学语言描述标引词的权重和其他关系而建立的模型。
1.3 技术中文分词技术
1.3.1 分词意义
无论是文档还是查询,都要变成标引项的某种形式,文档可以用多个标引项的集合来表示,一般用词来表示,还可以用其他形式的语言单位表示,还有一种特殊的标引词就是关键词。这就需要我们将文档进行分词来找到标引词及其数目来作为每篇文章的特性。
1.3.2 中文词法分析
1.3.3 停用词消除
1.3.4 中文重叠词还原
1.4 使用方法
检索的使用方法分成单项检索和组合检索两种
1.4.1 单项检索
单项检索将需要检索的检索词输入即可
如:想了解金银花,检索“金银花”
1.4.2 多项检索技术
多个检索技术有两种方式,第一种是单个检索中的一些单词或单词的组合,第二种是一些检索点的组合检索,也就是说在同一搜索点中设置多个检索词,或者同时设置多个不同的检索点再加以不同的条件,在这之后再执行检索。
如:关键词=(磁流体and(密闭or泄露))not(华东理工大学or华东化工学院)
2.搜索引擎技术
搜索引擎。说起搜索引擎,都清楚它需要具备内容全面、查询内容准确、查找速度快等作用。此外,搜索引擎需要对各种文本进行分类。
2.1 内容全面信息采集概述
信息采集。
下载从因特网收集的信息通常被称为机器人、蜘蛛和爬虫,它们被下载、预先组织和在线。
投入大规模硬件进行采集和存储
2.2 保证准确性的技术
2.2.1 相似度计算
将查询转换为向量,将文档转换为向量,将其更改为向量,然后求向量的相似性。相似性的计算被认为是三个因素:文档中出现的单词的数量,出现在单词中的文档的数量,以及接近度的比较。
2.2.2 链接分析
被越多网页指向,而且被越重要的网页指向,它就越重要。PageRank较大的网页才会被检索,保证了结果。
2.3 保证速度快的技术
2.3.1 倒排索引
建立倒排文件、使用倒排表搜索,使检索速度更快。
2.3.2 计算剪枝技术
由于很多用户只会看前两页,所以并不是所有网页都会参与运算,因此,根据某种规则预先刷掉很多网页或者分级。通过减少数量来加快速度。
2.3.3 缓存技术
将常用的放在内存,如检索结果、索引等,加快检索速度。
3.文本分类技术
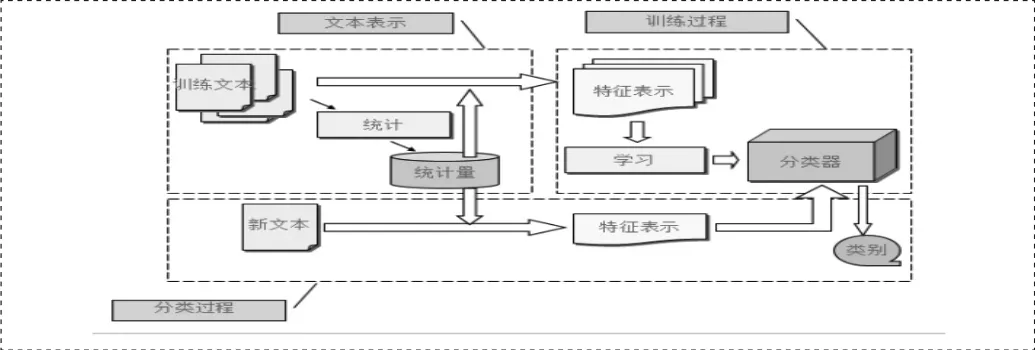
3.1 统计学习法的流程
大量的按人力分类的文件作为学习资料(称为训练集),由人力分类的一批文件的成本远远低于从这些文件中总结准确规则的成本。
计算机主动从原来给出的大量人力分类资料中(即训练集),提取有效的分类规则。这个过程称为训练,而这个总结出来的规则集就叫做分类器。
训练完成之后,用分类器对未知文档进行分类。
3.2 统计学习法流程图